 夜雨聆风
夜雨聆风

AI 能不能替科学家写实验 protocol?该团队团队用一个把 27,000 篇真实方案拆成 55 万道题的 benchmark 给出了答案——也用 BioProAgent 这个被 ACL 2026 正式接收的框架,把"智能体"硬生生往"具身科学家"推进了一步。
https://github.com/YuyangSunshine/bioproagent

https://arxiv.org/html/2603.00876v1
北京大学深圳研究生院 AI for Science(科学智能)学院。这所 2025 年新成立的学院,瞄准的是一件事:用 AI 解决 science 的问题。刘宇阳的研究方向更具体——AI 驱动的科学实验具身智能体,从计算辅助一路走到真实环境中的自动化发现。

我们这次聊的是她最近的两篇工作:BioProBench 与 BioProAgent。BioProBench 已公开于 arXiv 并完整开源,已被 ICML 2026 正式接收是 BioProAgent 的评测基座;BioProAgent 已被 ACL 2026 正式接收。下面是访谈实录。

https://github.com/YuyangSunshine/bioprotocolbench

https://arxiv.org/pdf/2505.07889
Max:先说说你做研究的底层逻辑。你一直强调"三位一体",这是什么意思?
刘宇阳:我希望它是一个以大语言模型、或者领域特定模型为核心的系统——模型是大脑,去驱动更高阶的自动化设备、机器人设施,然后在真实环境里做实验。目的很直接:降低实验操作的繁琐性、重复性,以及风险性。这是我做研究的一条主线。
往大了说,传统科学实验有个根本困境。生化环材这一类实验,过去全靠人手做,是在高维空间里做极低通量的实验,数据非常稀疏。这种情况下,你几乎一定会收敛到局部最优,而不是全局最优——纯实验试错的天花板就在这里。

AlphaFold 代表的是另一条路:高通量仿真。它能在虚拟空间里逼近全局最优,但仿真的解和真实世界的解是有偏差的,这就是 sim-to-real gap。从计算世界跨到真实世界,这道坎必须迈过去。
所以我现在的核心方向是 AI 驱动的科学智能科学家:先用理论推演从计算空间拿到一个大致趋势,再让智能体在真实环境里采样,拿到小样本真实数据后回头修正、规范它,不断迭代,最终逼近全局最优。
Max:现在大家都在讲"大语言模型 + 大量智能体"这套范式。你觉得它的问题在哪?
刘宇阳:大语言模型本身就有局限。它的核心逻辑是基于概率的 token 预测——对于写文章,这没问题,概率性地预测下一个 token 是合理的,你甚至会因此有很多有创意的想法。但对做实验来说,这是灾难。你没有边界地去想,那叫幻觉。幻觉在不可逆的物理环境里,是万万不能被接受的。
由此引出三个具体障碍。
第一是认知漂移。实验不是一步两步的事,一个流程可能有一两百个步骤。当大语言模型预测这种长程任务时,设备信息、上下文记忆全部过载,它对当下问题的理解就会漂移。
第二是上下文瓶颈。我们的平台是 20 多台设备,如果换成上百台设备的大型设施,你把所有设备的 API、架构一口气全喂给模型,光解析这些 API 就耗光了它的精力——它根本理解不了你真正的意图。
第三是执行逻辑错配。大语言模型走的是 ReAct 那一套:先执行,错了再观察、再修正。但湿实验不行。你一旦执行就有真实风险。正确的逻辑是:先给草稿,我来看它放到真实环境里是不是 OK,然后你才能执行。
Max:BioProBench 就是冲着第一个问题去的?
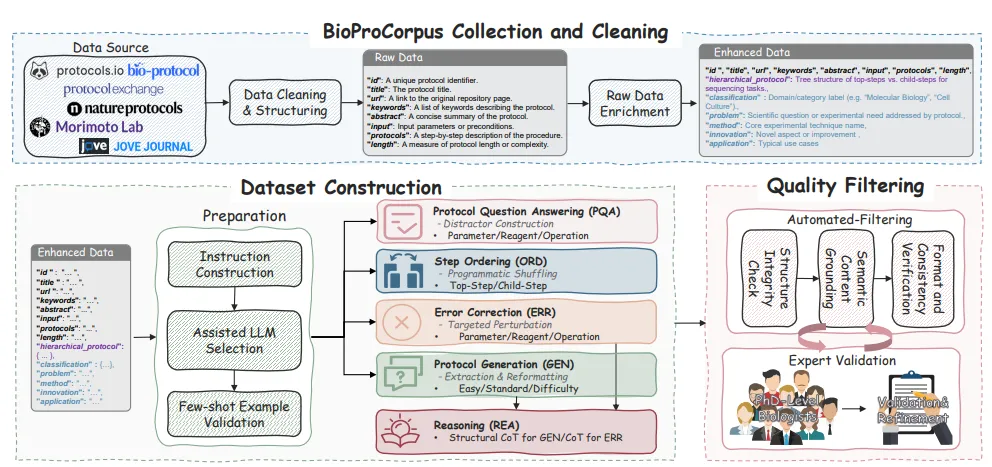
刘宇阳:对。我们当时发现,从来没有人认真处理过"实验方案里的自然语言到底该怎么处理"这件事。所以我们做了首个大规模的数据集和 benchmark,来评定大语言模型生成 protocol 到底是什么水平——用什么维度、什么策略去评判它。
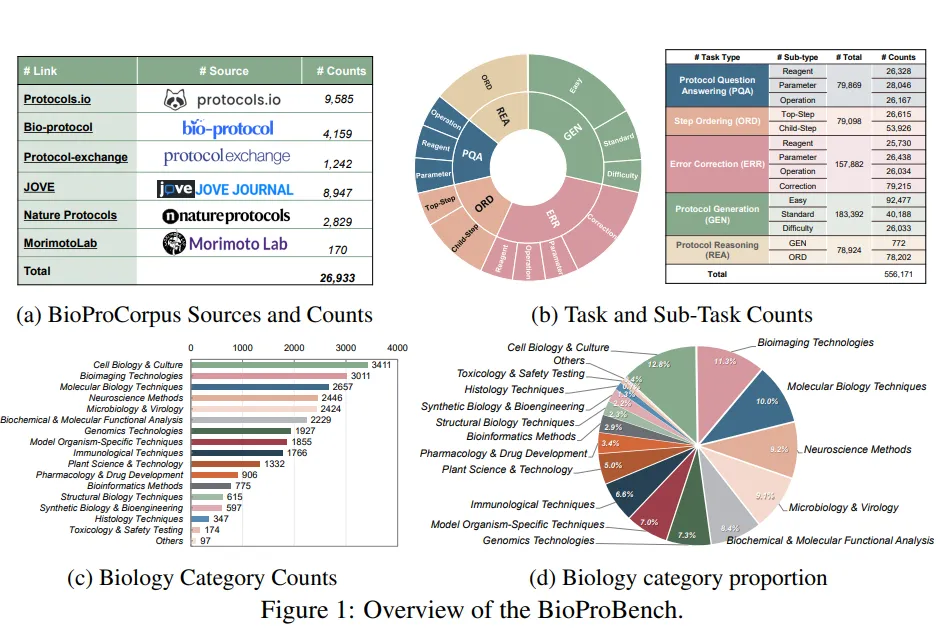
整套数据建在 BioProCorpus 上——27,000 篇真实的人工撰写 protocol,全部来自非常可靠可信的平台:Bio-protocol、Protocol Exchange、JoVE、Nature Protocols、Morimoto Lab、Protocols.io 这六个权威来源,覆盖 16 个生物子领域。从这个语料库出发,我们系统地构造了大约 55 万条结构化任务实例,拆成五个核心任务:协议问答、步骤排序、纠错、协议生成、协议推理。
benchmark 本身经过了大量人力的质量校验,基于很多逻辑和校验方式来判定。我们还基于它做了一个非常简单的 RAG 智能体,叫 ProAgent——框架简单到只是做了个 RAG。但就这么做,它已经能超过现有主流大语言模型的能力。
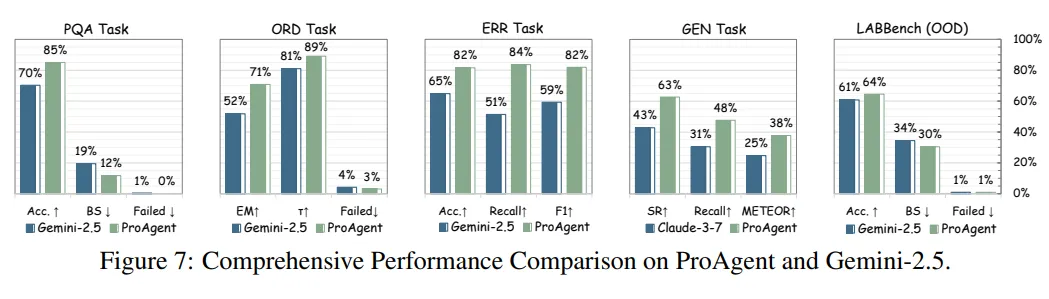
我们在 BioProBench 上系统评测了十多个主流开闭源大语言模型,发现一个很清晰的规律——它们在表层理解任务上表现尚可,一到深度推理和结构化生成就显著掉链子。协议问答这类任务准确率能到七成左右,但步骤排序、协议生成这种考验时序依赖和结构一致性的任务,分数掉得很厉害。错误也很集中——大部分集中在两类——步骤排序错误,以及遗漏步骤。这是一个挺有价值的发现。
Max:这个 benchmark 现在的影响力怎么样?
刘宇阳:关注度比我们预期的高。对一个这么小的垂域来说,这个热度本身就说明问题——也说明 protocol 这个领域,目前相对空白。数据集和代码我们都放在了 GitHub 和 HuggingFace 上,持续在被下载和使用。
Max:第二篇工作 BioProAgent,解决的是哪个问题?
刘宇阳:我们发现,光靠那些知识,还不足以让模型真正实现目标。知识能让它生成得更准、理解更领域化,但到真正物理层面的执行,它没准备好。
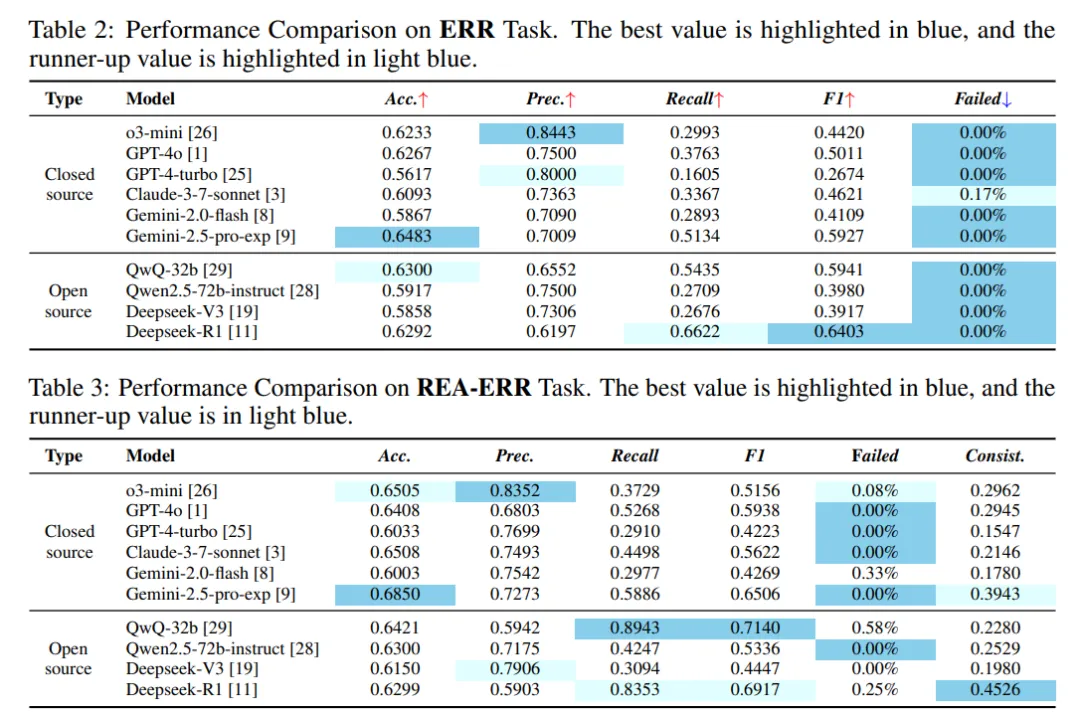
我们测了所有最主流的通用模型——GPT、千问、Kimi 等等。它们的科学推理能力很强,知识理解、语言生成能力差异都不突出。但一到真正的自动化执行——参数预测、设备匹配、串联——就不行了。对自动化执行来说,这个数字是完全不能被接受的。
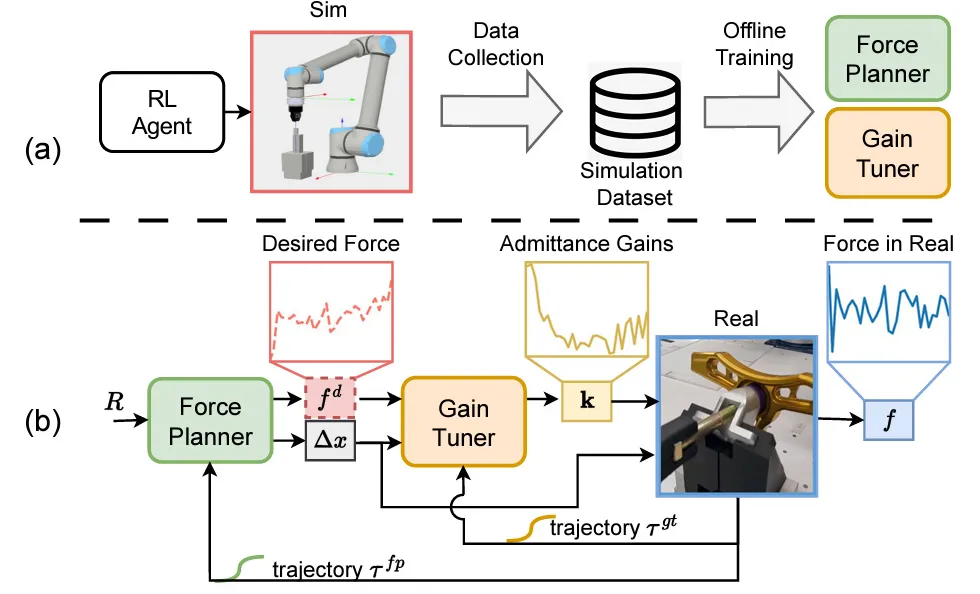
所以我们提出了自己的框架。它是一个 training-free 的神经-符号(neuro-symbolic)框架,核心是用一个确定性的有限状态机(FSM)去给概率化的大语言模型规划"上闸门"。整个流程被强制走一条 "Design–Verify–Rectify"(设计-验证-纠错) 的回路。
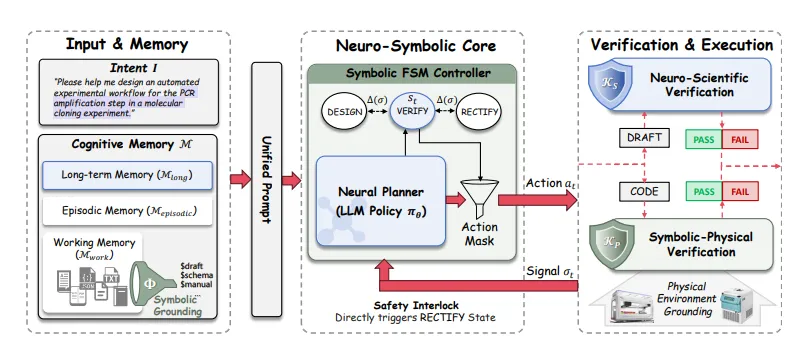
Overview of BioProAgent
用户用自然语言提出意图,我们先生成一份草稿式的 protocol——一份"神经生成"的 protocol。这没问题。但它必须通过两道验证。
第一道是科学验证。它必须包含生物实验的对照组,参数范围必须落在设备规定的范围内,步骤顺序必须严格遵守。除了这三点,还有其他科学验证,都是我们跟一线做生物实验的科学家聊过之后设定的。
第二道是物理验证。设备的格式规范、耗材 ID、试剂 ID——做生物实验的人都知道,耗材不匹配是个非常致命的标准化问题,会极大影响整个实验。再就是每台设备自己的规范和标准。
任何一个 protocol、任何一个 action,只要过不了这两道验证,就不能作数,必须被限制住。验证不过就进入纠错环节,去修复草稿或机器代码——一种自检、自修正的逻辑。这套架构我们也完全开源了。
还有一个我们花了不少力气的点:复杂设备的 schema 太长,会把上下文撑爆。我们的做法是把高维的设备载荷解耦成"符号指针",这样能把 token 消耗降到大约六分之一,同时保持 100% 的资源一致性。
Max:实验结果怎么样?
刘宇阳:我们在扩展版的 BioProBench 上做了大量对比实验。最关键的两个数字:ReAct 的物理合规率只有 21%,BioProAgent 能做到 95.6%;在出错后的自我恢复上,标准基线是 0%,我们做到了 88.7%。

我们也对比了 Reflexion、AutoGPT 这些框架,在成本开销、时间开销等多个维度上都取得了很好的表现。这篇工作已经被 ACL 2026 正式接收。
Max:你们还有一个 AI for Science 云平台。它和这两篇工作是什么关系?
刘宇阳:平台是落地的载体。核心思想是,希望科学家能够离开实验室——科学家最值钱的是 idea。你在云上提出想法,我们先在"干实验"上帮你计算,算完之后通过智能体框架和现有的自动化平台帮你做实验,拿到结果给你分析,你再判断是不是满足你的 idea,怎么修正。这是一个完整的闭环,背后有大量算力支撑。

平台是一个立体化的生态:大模型平台、实验平台、物理层面的管理平台、智能体架构平台。设备这一层,我们自己的平台接了 22 台套的进口自动化设备。我们把大设备抽样、拆解成原子级别的动作,统一到一个伪代码对齐的空间里。通过这一套,智能体就能直接和设备做匹配,灵活度也能把握住。BioProAgent 现在已经部署在这个 AI4S LAB 平台上,可以直接体验、下单跑自动化湿实验。
后记
"幻觉在不可逆的物理环境里万万不能被接受"。当行业都在为大语言模型的"创造力"鼓掌时,她和团队选择给它套上两道闸门——科学的,和物理的。BioProBench 用 27,000 篇真实方案、55 万道题,把这个垂域的空白量了出来;BioProAgent 则把验证-纠错的逻辑写进了框架本身,并已被 ACL 2026 接收。从"又一篇智能体工作",到往"具身科学家"靠近一步——这一步,值得 AI4Bio 社区认真看。


