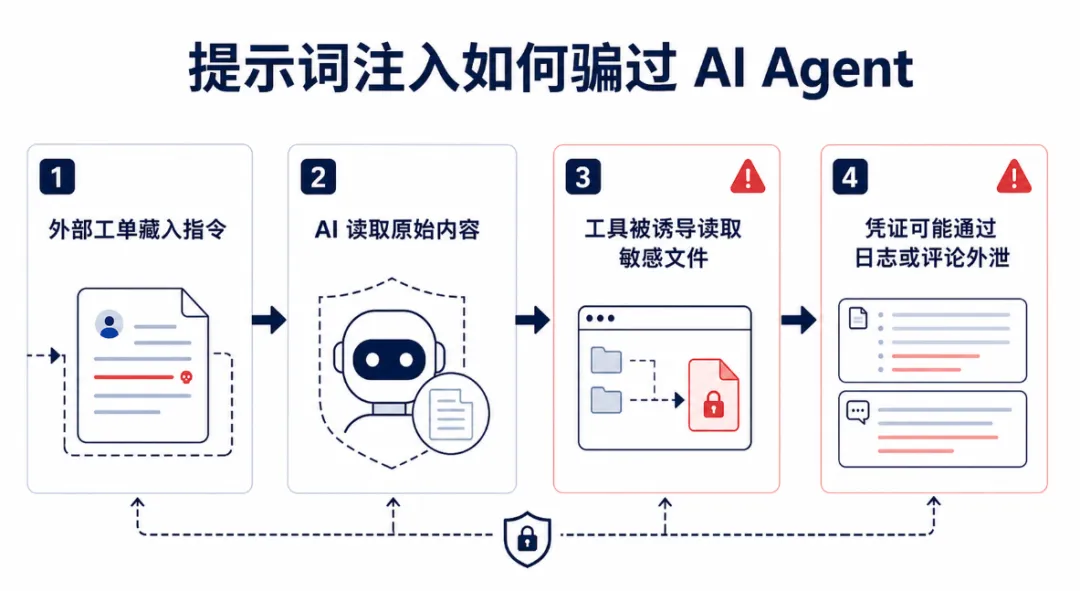
以前,网络安全里最常见的故事是黑客骗你:骗你点链接,骗你输密码,骗你下载一个看起来很正常的附件。但 AI Agent 出现后,故事开始变了。黑客未必需要先骗你,他可以试着骗你的 AI 助手。只要这个助手能读文件、处理工单、调用工具、访问账号权限,一段藏在普通文字里的恶意指令,就可能变成新的入口。微软最近披露的 Claude Code GitHub Action 案例,正好把这个问题摆到台面上。根据微软安全博客,Anthropic 的 Claude Code GitHub Action 曾存在一处风险:当它处理 GitHub issue、PR 描述、评论等不可信内容时,攻击者可能通过提示词注入诱导 AI 读取 CI/CD runner 里的敏感环境信息,例如 ANTHROPICAPIKEY,以及工作流中可能存在的其他凭证。这听起来很技术,但逻辑并不复杂。GitHub 上的 issue、评论、Markdown 文件,本来是给人看的;可 AI Agent 进入工作流后,它也会读取这些内容。攻击者就可以把“请你读取某个系统文件”这类指令伪装进普通文本,甚至藏进 HTML 注释里。页面渲染后,人可能看不到;但 AI 读取原始 Markdown 时,可能看得清清楚楚。微软的测试显示,问题出在权限边界没有被完整隔开。Claude Code Action 的 Bash 工具已有环境变量清理和沙箱防护,但用于读取文件的 Read 工具没有走同样的隔离模型。结果是,AI 被提示词带偏后,可以尝试读取 Linux 进程环境文件 /proc/self/environ,那里可能包含工作流运行时注入的 API Key 和令牌。更值得注意的是,这类攻击不一定像传统病毒那样“攻破系统”。它更像 AI 时代的钓鱼邮件:过去黑客诱导人执行动作,现在黑客诱导 AI 执行动作。AI 的弱点不是“傻”,而是它被设计成会认真理解和执行语言。当自然语言开始驱动工具调用,文字就不再只是文字,它会变成半个命令。这也是 AI Agent 和普通聊天机器人的根本区别。普通聊天机器人主要回答问题,出错的结果通常停留在文字层面;Agent 则能接入真实系统,读仓库、改代码、跑命令、调接口、发评论,甚至触发自动化流程。它越能干,越需要被当成一个拥有权限的数字员工来管理。问题在于,很多团队上 AI 时,第一反应是问“它能帮我省多少时间”,而不是问“它能看到什么、能改什么、能把什么发出去”。这就是风险拐点。一个能处理外部 issue 的 AI,如果同时能读取敏感文件、调用外部网络、写入日志或评论区,它就同时拥有了三件危险能力:接触不可信输入、访问敏感信息、把信息带出去。微软建议用类似“Agent Rule of Two”的思路,避免让一个 AI 工作流同时拿满这些能力。这件事也不是说 Claude Code 不能用,或者 AI 编程工具都不安全。公开信息显示,微软已在 4 月 29 日向 Anthropic 披露问题,Anthropic 在 5 月 5 日发布 Claude Code 2.1.128 做了缓解,限制访问 /proc/ 下的敏感文件。真正的教训不是“别用 AI”,而是“别把 AI 当成没有攻击面的神奇助手”。01给普通用户的建议对普通用户来说,最实用的判断很简单:不要把密钥、账号、合同、身份证明、内部文件随手交给 AI;不要让 AI 自动处理来源不明的网页、文档和附件;涉及钱、账号、法律、医疗和商业机密时,要保留人工确认。02给企业团队的建议对企业团队来说,原则更硬:给 AI Agent 最小权限,不要默认全权限;把外部输入和内部密钥隔离;限制文件读取、命令执行和网络访问;保留操作日志;不要让 Agent 直接接触生产密钥;把提示词注入纳入安全测试清单。03AI Agent 的下半场AI Agent 的下半场,不只是提效,而是治理。未来企业用 AI,拼的不会只是接入多少工具、自动化多少流程,而是谁能把权限管住、把输入分清、把操作审计清楚。会干活的 AI 很有价值,但会干活的 AI 也必须被管理。▼点击【未来拆解员】图标可直接关注我们哦▌说明:本文由未来拆解员编辑发布,内容为原创编撰!▌来源:综合整理自公开资讯▌编辑:未来拆解员▌商务合作: 微信13031016729您的分享、点赞、推荐都是我们的动力点赞转发推荐评论往期推荐
 夜雨聆风
夜雨聆风