 夜雨聆风
夜雨聆风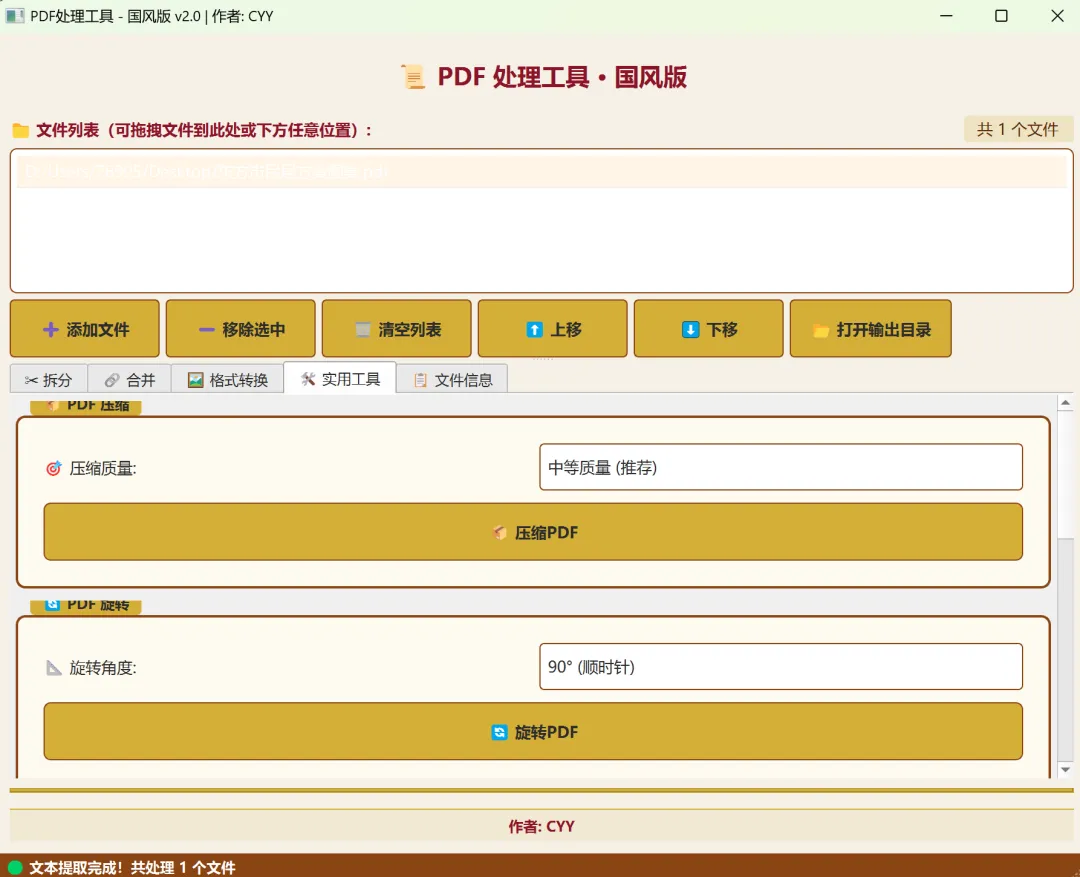
PDF处理工具
国风版 v2.0
功能说明文档
完整功能详解· 实现步骤 · 架构说明
━━━━━━━━━━━━━━━━━━━━━━
作者: CYY
1. 软件概述
1.1 软件简介
PDF处理工具 - 国风版 v2.0 是一款基于 PyQt5 开发的桌面级 PDF 文档处理软件,采用中国传统国风美学设计界面,提供包括拆分、合并、格式转换、压缩、旋转、水印、加密等十余种实用功能。
1.2 技术栈
•GUI框架: PyQt5
•PDF处理: PyPDF2, PyMuPDF (fitz)
•图片处理: Pillow (PIL)
•格式转换: pdf2docx
•Python版本: 3.x
1.3 界面特色
•采用中国传统国风配色:朱红(#C41E3A)、金色(#D4AF37)、棕色(#8B4513)
•使用 QTabWidget 实现分页布局,每个功能模块独立一个标签页
•支持文件拖拽添加、批量处理
•实时进度显示、异步任务处理
2. 功能模块总览
本软件包含以下五大功能模块,通过标签页进行组织:
功能模块 | 核心类/文件 | 主要依赖 |
拆分功能 | SplitThread | PyPDF2 |
合并功能 | MergeThread | PyPDF2 + Pillow |
格式转换 | PdfToImageThread / ImageToPdfThread / PdfToWordThread / PdfToOFDThread | PyMuPDF + pdf2docx |
实用工具 | CompressPdfThread / RotatePdfThread / WatermarkPdfThread / ExtractTextThread / EncryptPdfThread | PyMuPDF + PyPDF2 |
文件信息 | PdfInfoThread | PyMuPDF |
2.1 模块架构图
┌─────────────────────────────────────────────────────────────┐
│ PDF处理工具 - 国风版 │
└─────────────────────────────────────────────────────────────┘
│
┌───────────┬───────────┬───────────┬───────────┬───────────┐
│ ✂️ 拆分 │ �� 合并 │ �� 转换 │ �� 工具 │ �� 信息 │
└───────────┴───────────┴───────────┴───────────┴───────────┘
│ │ │ │ │
┌─────┴─────┐ ┌─────┴─────┐ ┌─────┴─────┐ ┌─────┴─────┐ ┌─────┴─────┐
│SplitThread│ │MergeThread│ │Pdf2Img │ │Compress │ │PdfInfo │
│Rotate │ │ │ │Img2Pdf │ │Rotate │ │ │
│Watermark │ │ │ │Pdf2Word │ │Watermark │ │ │
│Extract │ │ │ │Pdf2OFD │ │Extract │ │ │
│Encrypt │ │ │ │ │ │Encrypt │ │ │
└───────────┘ └───────────┘ └───────────┘ └───────────┘ └───────────┘
3. 核心功能详解
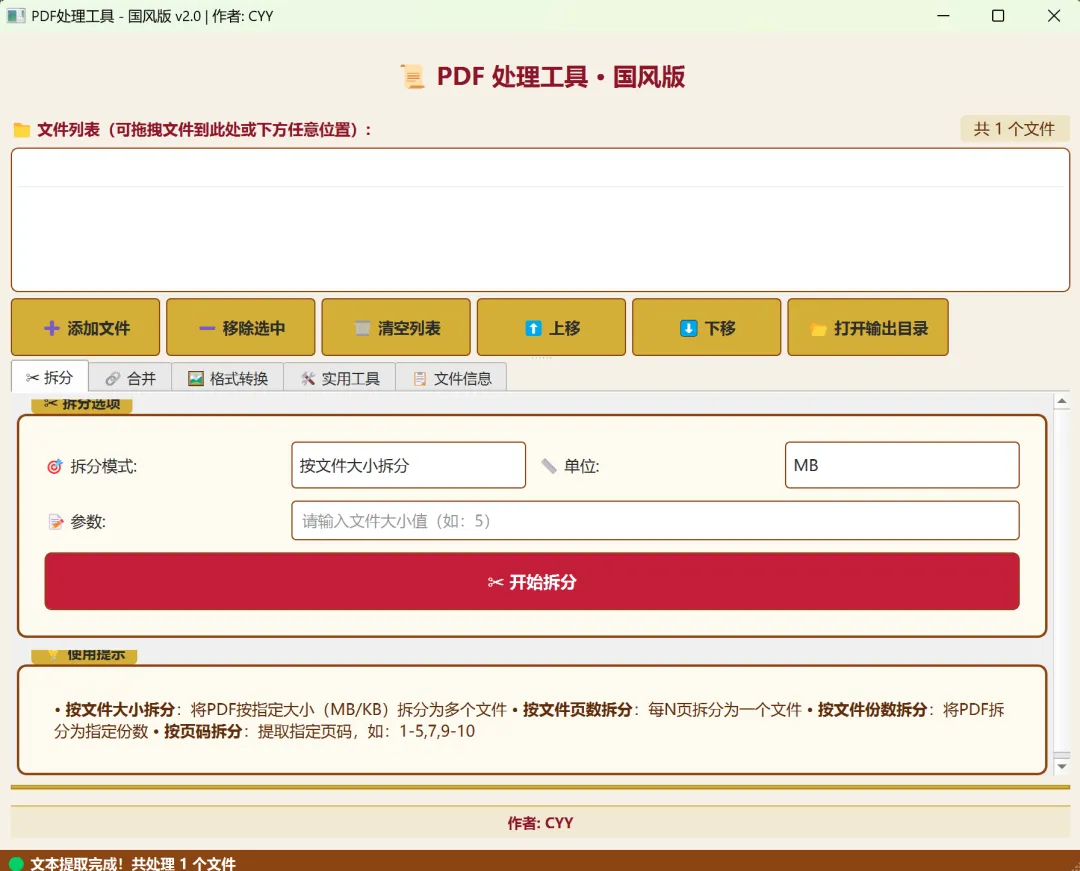
3.1 PDF拆分功能
PDF拆分功能支持四种不同的拆分模式,可满足各种文档分割需求。
3.1.1 按文件大小拆分
功能说明:
将PDF文档按照指定的目标文件大小进行拆分,自动计算每份的页数,确保每份文件大小不超过设定值。
实现步骤:
1 | 用户设置 用户输入目标文件大小(如5MB)和单位(MB/KB) |
2 | 文件扫描 程序获取PDF文件的总大小和总页数,计算平均每页大小 |
3 | 估算页数 使用目标字节数÷ 平均页大小 估算每份的大致页数 |
4 | 二分查找 使用二分查找算法精确定位最佳拆分点 |
5 | 分批写入 创建PdfWriter,将每批页面写入独立的PDF文件 |
6 | 完成输出 生成 part001.pdf, part002.pdf, ... 等文件 |
核心算法:
① 估算阶段: avg_page_size = file_size / total_pages
② 二分查找: 找到最大的 end,使得 pages[start:end] 的大小 ≤ target_bytes
3.1.2 按文件页数拆分
功能说明:
将PDF按照固定页数拆分为多个文件,例如每10页一个文件。
实现步骤:
1 | 输入参数 用户输入每份的页数(如10页) |
2 | 循环拆分 使用 for 循环,从第0页开始,每 chunk_size 页拆分为一个文件 |
3 | 写入文件 创建 PdfWriter,添加对应范围的页面并保存 |
4 | 循环处理 重复直到处理完所有页面 |
3.1.3 按文件份数拆分
功能说明:
将PDF均匀拆分为指定份数,例如拆分为3份,每份约相等。
实现步骤:
1 | 输入份数 用户输入要拆分的份数 |
2 | 计算分配 base_size = total_pages // num_chunks(基本页数) remainder = total_pages % num_chunks(前 remainder 份多1页) |
3 | 循环分配 第 i 份的页数 = base_size + (1 if i < remainder else 0) |
4 | 批量写入 将计算出的页面范围写入各子文件 |
3.1.4 按页码拆分
功能说明:
根据用户指定的页码范围提取页面,支持多种格式输入。
支持的页码格式:
•单页: 1, 3, 5
•连续页: 1-5 (第1页到第5页)
•混合: 1-5, 7, 9-15
•支持中文标点: 1-5,7(中文逗号)
实现步骤:
1 | 解析输入 _parse_page_ranges() 方法解析页码字符串 |
2 | 转换格式 将 1-based 页码转换为 0-based 索引 |
3 | 去重排序 使用 set 去重,sorted() 排序 |
4 | 单文件输出 将所有指定页面写入一个PDF文件 |
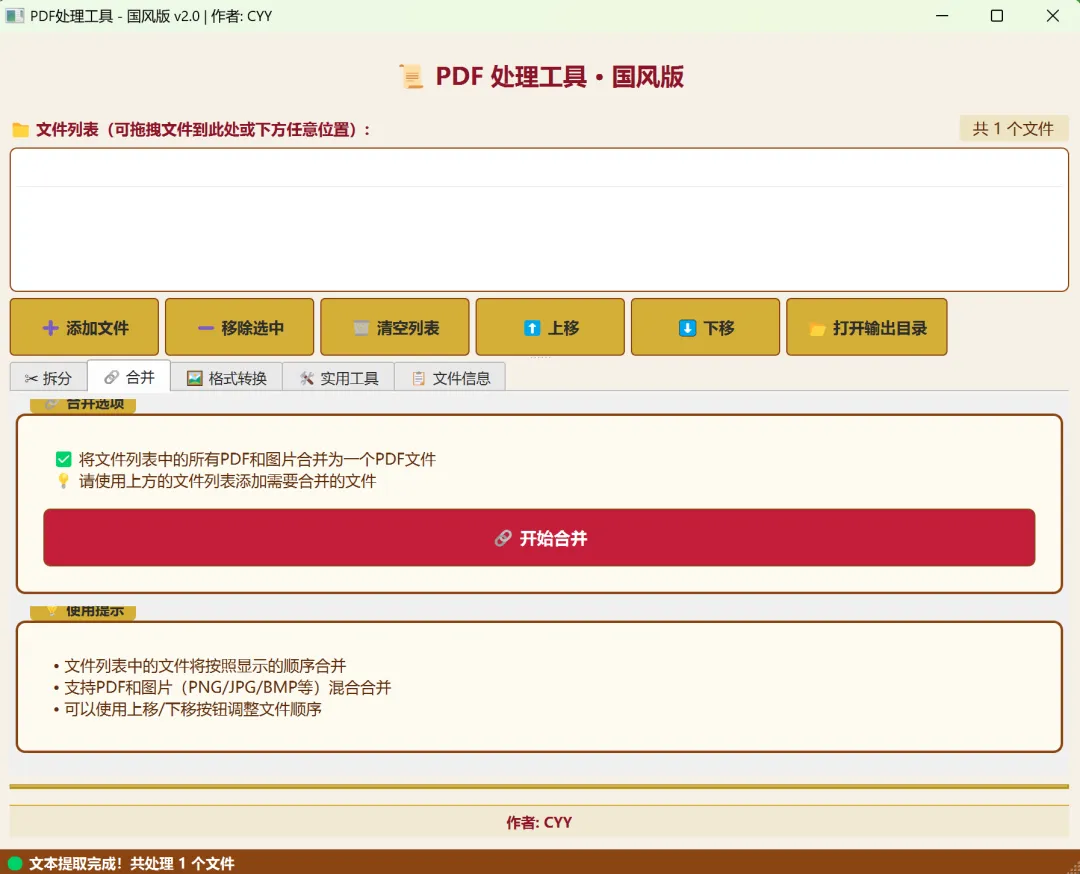
3.2 PDF合并功能
功能说明:
将多个PDF文件或图片文件合并为一个PDF文件,保持原始顺序。
支持的输入格式:
•PDF文件 (*.pdf)
•PNG图片 (*.png)
•JPEG图片 (*.jpg, *.jpeg)
•BMP图片 (*.bmp)
•TIFF图片 (*.tiff)
•GIF图片 (*.gif)
实现步骤:
1 | 获取文件列表 从共享文件列表获取所有文件,按显示顺序处理 |
2 | 图片预处理 对于图片文件,使用 Pillow 转换为 RGB 模式 (RGBA图片需要白色背景合成) |
3 | 内存转换 使用 io.BytesIO 在内存中将图片转为PDF |
4 | 顺序合并 使用 PyPDF2.PdfMerger 按顺序 append 所有文件 |
5 | 保存输出 调用 merger.write() 保存合并后的PDF |
核心代码逻辑:
for file in file_list:
if 是图片: 转换为RGB → 存入BytesIO → merger.append(buffer)
else: merger.append(pdf_file)
3.3 格式转换功能
格式转换模块包含四种转换功能,覆盖主流文档格式互转需求。
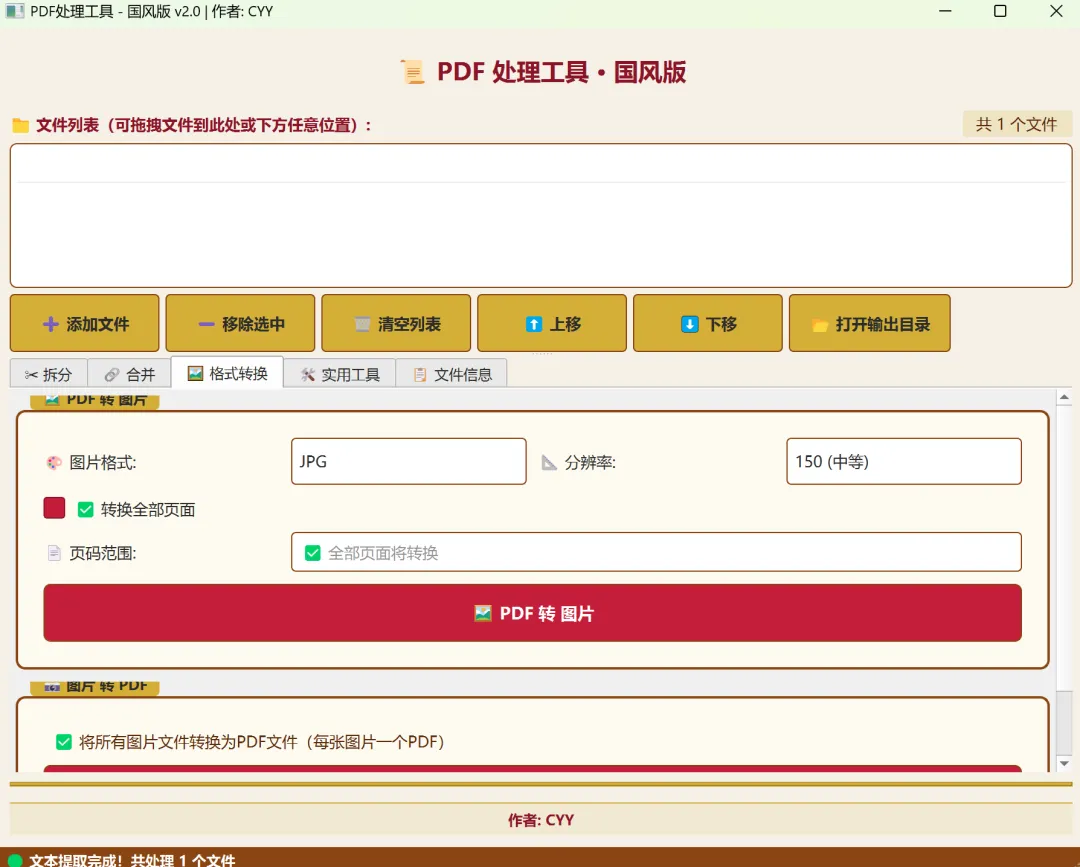
3.3.1 PDF转图片
功能说明:
将PDF的每一页转换为图片,支持选择页面范围和图片格式。
支持的图片格式:
•JPG: 适合照片类内容
•PNG: 适合需要透明背景或无损质量
•BMP: 适合需要原始位图数据
支持的分辨率:
•72 DPI: 低质量,文件小
•150 DPI: 中等质量(默认)
•200 DPI: 高质量
•300 DPI: 超清,适合打印
实现步骤:
1 | 打开PDF 使用 PyMuPDF (fitz) 打开PDF文件 |
2 | 解析页码 如果用户指定范围,解析页码;否则处理全部页面 |
3 | 计算矩阵 根据 DPI 计算缩放矩阵: matrix = fitz.Matrix(dpi/72, dpi/72) |
4 | 逐页渲染 page.get_pixmap(matrix=matrix) 渲染页面为图片 |
5 | 保存图片 pix.save(output_path) 保存为指定格式 |
6 | 命名规则 原文件名_page1.jpg, 原文件名_page2.jpg, ... |
3.3.2 图片转PDF
功能说明:
将图片文件转换为PDF,每张图片生成一个PDF文件。
实现步骤:
1 | 过滤图片 从文件列表中筛选有效图片格式 |
2 | RGBA处理 如果是 RGBA 模式,创建白色背景并合成 |
3 | RGB转换 确保图片为 RGB 模式(PIL PDF需要RGB) |
4 | 保存PDF img.save(pdf_path, 'PDF', resolution=150.0, quality=95) |
5 | 命名规则 图片名.jpg → 图片名.pdf |
3.3.3 PDF转Word
功能说明:
将PDF文档转换为可编辑的Word (DOCX) 格式。
依赖库:pdf2docx
⚠️ 注意: 需要安装 pdf2docx 库,否则此功能不可用。
实现步骤:
1 | 检查依赖 启动时检查 HAS_PDF2DOCX 标志 |
2 | 创建转换器 cv = DocxConverter(pdf_path) |
3 | 执行转换 cv.convert(output_path) |
4 | 关闭资源 cv.close() |
3.3.4 PDF转OFD
功能说明:
将PDF转换为中国国标版式文档OFD格式 (GB/T 33190-2016),广泛用于电子发票、电子公文。
OFD格式特点:
•中国自主制定的版式文档标准
•基于XML的文档结构
•本质是ZIP压缩包
•每页为独立图片或矢量图形
实现步骤:
1 | 创建目录结构 创建临时目录,包含 Doc_0/Pages/ 和 Doc_0/Res/ |
2 | 渲染页面 将每页PDF渲染为PNG图片 |
3 | 写入XML 生成 OFD.xml, doc.xml, Document.xml, Content.xml, Page_X.xml, PublicRes.xml |
4 | 打包OFD 使用 zipfile 将所有文件打包为 .ofd |
OFD文件结构:
document.ofd (ZIP包)
├── OFD.xml # 主入口文件
├── Doc_0/
│ ├── doc.xml # 文档根信息
│ ├── Document.xml # 文档结构
│ ├── Content.xml # 内容索引
│ ├── Pages/
│ │ └── Page_0.xml # 页面定义
│ └── Res/
│ ├── page_0.png # 页面图片
3.4 实用工具
3.4.1 PDF压缩
功能说明:
通过降低图片分辨率来压缩PDF文件大小。
压缩质量选项:
•低质量 (72 DPI): 压缩比最高,文件最小
•中等质量 (120 DPI): 平衡模式(推荐)
•高质量 (150 DPI): 保持较好清晰度
实现步骤:
1 | 打开原文件 使用 PyMuPDF 打开PDF |
2 | 创建新文档 创建空的输出文档 |
3 | 逐页处理 对每一页渲染为低DPI图片,再插入新页面 |
4 | 设置DPI 低质量=72DPI, 中等=120DPI, 高质量=150DPI |
5 | 保存压缩 doc.save(output, garbage=4, deflate=True) |
3.4.2 PDF旋转
功能说明:
将PDF的每一页按指定角度旋转。
支持的角度:
•90°: 顺时针旋转90度
•180°: 上下颠倒
•270°: 逆时针旋转90度(等价于顺时针270°)
实现步骤:
1 | 读取原文件 使用 PdfReader 读取原PDF |
2 | 创建写入器 创建 PdfWriter 用于输出 |
3 | 旋转页面 对每一页调用 page.rotate(angle) |
4 | 添加页面 writer.add_page(rotated_page) |
5 | 保存文件 writer.write(output_file) |
3.4.3 添加水印
功能说明:
在PDF每一页的中央添加半透明文字水印。
水印特点:
•半透明灰色文字(默认透明度30%)
•45度倾斜排列
•居中显示
•可自定义水印文字和字体大小
实现步骤:
1 | 打开PDF 使用 PyMuPDF 打开PDF |
2 | 逐页处理 遍历每一页 |
3 | 计算位置 使用 fitz.Rect 计算文本框区域 |
4 | 插入文本 page.insert_textbox(rect, text, fontsize=size, color=gray, rotate=45) |
5 | 保存文件 doc.save(output, garbage=4, deflate=True) |
3.4.4 提取文本
功能说明:
将PDF中的文本内容提取为TXT文本文件。
实现步骤:
1 | 打开PDF 使用 PyMuPDF 打开PDF |
2 | 逐页提取 page.get_text() 提取每页文本 |
3 | 格式化输出 添加页码分隔标记: === 第 X 页 === |
4 | 保存TXT 使用 UTF-8 编码保存文本文件 |
输出格式示例:
=== 第 1 页 ===
这是第1页的文本内容...
=== 第 2 页 ===
3.4.5 PDF加密
功能说明:
为PDF文件添加打开密码保护。
安全要求:
•密码长度至少4位
•密码显示/隐藏切换
•使用 PyPDF2 的 encrypt() 方法
实现步骤:
1 | 读取原文件 使用 PdfReader 读取原PDF |
2 | 创建写入器 创建 PdfWriter |
3 | 添加页面 将所有页面添加到 writer |
4 | 加密处理 writer.encrypt(password) |
5 | 保存文件 writer.write(output_file) |
3.5 文件信息查看
功能说明:
查看PDF文件的详细信息,包括文件大小、页数、尺寸、元数据等。
显示的信息:
•文件名
•文件大小(MB和字节)
•总页数
•页面尺寸(宽度×高度)
•是否加密
•是否为有效PDF
•元数据(作者、标题、主题、关键词等)
实现步骤:
1 | 打开PDF 使用 PyMuPDF 打开PDF |
2 | 获取基本信息 doc.page_count, doc.is_encrypted, doc.is_pdf |
3 | 读取元数据 doc.metadata 获取标准PDF元数据 |
4 | 获取首页尺寸 doc[0].rect 获取页面宽高 |
5 | 格式化显示 在 QTextEdit 中展示所有信息 |
4. 架构设计与实现原理
4.1 线程模型
为了保证界面响应性,所有耗时操作都运行在独立的 QThread 子线程中。
线程架构:
┌──────────────────────────────────────────────────────────┐
│ 主线程 (UI) │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │MainWindow│ │ UI事件 │ │ 进度更新 │ │ 结果显示 │ │
│ └────┬─────┘ └──────────┘ └────▲─────┘ └──────────┘ │
└───────┼─────────────────────────────────┼─────────────────┘
│ pyqtSignal ▲ │
┌───────┴─────────────────────────────────┼─────────────────┐
│ 工作线程 │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ XxxThread (继承 QThread) │ │
│ │ - progress_updated 信号 (进度更新) │ │
│ │ - x_finished 信号 (任务完成) │ │
│ │ - error_occurred 信号 (错误信息) │ │
│ │ - run() 方法 (执行任务) │ │
│ │ - cancel() 方法 (取消任务) │ │
│ └──────────────────────────────────────────────────────┘ │
4.2 信号机制
每个工作线程定义三个核心信号:
progress_updated: 进度更新信号,携带0-100的整数值
x_finished: 任务完成信号,携带结果数据
error_occurred: 错误发生信号,携带错误消息
4.3 文件操作流程
统一处理流程:
用户点击按钮
↓
检查文件列表
↓
选择输出目录
↓
禁用按钮 + 启动线程
↓
子线程执行任务→ emit信号
↓
启用按钮 + 显示结果
5. 界面交互设计
5.1 布局结构
主界面采用以下布局层次:
┌──────────────────────────────────────────────────────┐
│ 标题栏: PDF处理工具 · 国风版 │
├──────────────────────────────────────────────────────┤
│ 文件列表区 (可拖拽添加) │
│ [+添加] [-移除] [↑上移] [↓下移] [清空] [打开目录] │
├──────────────────────────────────────────────────────┤
│ [✂️ 拆分] [�� 合并] [�� 转换] [�� 工具] [�� 信息] │
├──────────────────────────────────────────────────────┤
│ 当前标签页的功能界面 │
│ (带 QScrollArea 滚动) │
├──────────────────────────────────────────────────────┤
│ 进度条: [████████████████████░░░░░░░░] 75% (75/100) │
│ 状态: ✅ 正在处理,请稍候... │
├──────────────────────────────────────────────────────┤
│ 作者: CYY │
5.2 交互特性
•文件拖拽: 支持直接将文件拖入窗口
•批量选择: 支持Ctrl/Shift多选文件
•顺序调整: 上移/下移按钮调整合并顺序
•实时进度: 进度条实时更新处理进度
•取消功能: 所有线程支持取消操作
•结果提示: 完成时询问是否打开输出目录
5.3 国风配色方案
配色名称 | 色值 | 用途 |
朱红 | 主按钮背景、标题文字 | |
金色 | 次要按钮、边框装饰、标题栏 | |
棕色 | 边框、状态栏、分组框标题 | |
米白 | 窗口背景色 |
6. 总结
6.1 功能清单
本软件提供以下12项核心功能:
1. 按文件大小拆分 PDF
2. 按文件页数拆分 PDF
3. 按文件份数拆分 PDF
4. 按页码拆分/提取 PDF
5. 合并多个 PDF 或图片文件
6. PDF 转图片(支持多种格式和DPI)
7. 图片转 PDF
8. PDF 转 Word (DOCX)
9. PDF 转 OFD (国标格式)
10. PDF 压缩
11. PDF 旋转
12. PDF 添加水印
13. PDF 提取文本
14. PDF 加密
15. PDF 文件信息查看
6.2 技术亮点
•异步处理: 所有耗操作运行在子线程,界面流畅
•智能拆分: 二分查找算法精确定位最佳拆分点
•格式兼容: 支持多种图片格式自动转换
•内存优化: BytesIO 内存转换避免临时文件
•OFD支持: 完整实现中国国标版式文档格式
•国风UI: 独特的中国传统美学界面设计
6.3 依赖说明
依赖库 | 用途说明 |
PyQt5 | GUI界面框架 |
PyPDF2 | PDF读写、合并、拆分、加密 |
PyMuPDF (fitz) | PDF渲染、图片转换、文本提取、水印 |
Pillow (PIL) | 图片格式转换、处理 |
pdf2docx | PDF转Word(可选依赖) |
━━━━━━━━━━━━━━━━━━━━━━
文档结束
PDF处理工具 - 国风版 v2.0 | 作者: CYY
