 夜雨聆风
夜雨聆风Macaron-A2UI: A Model for Generative UI in Personal Agents
当你让AI助手订一张跨城市机票,面对它返回的一大段包含航司、时间、价格、中转信息的纯文本时,是否感到头晕?信息淹没在字里行间,你得反复阅读、手动比较,甚至开启另一个App来确认细节。纯文本交互,正在成为高级个人助手的体验瓶颈。 这篇来自Mind Lab的论文Macaron-A2UI,直面这个问题,它不再让AI只会“说话”,而是教它“造界面”——在对话中实时生成轻量、可执行的UI组件,把信息收集、偏好确认、决策支持这些交互任务,变得像点击按钮一样直观高效。
当“说话”不够用:生成式UI为何势在必行
当前的AI助手,无论是聊天还是执行任务,核心交互通道依然是自然语言。这在处理简单问答时没问题,但一旦涉及结构化交互,比如填写表单、从多个选项中选择、确认复杂信息或同时处理多个子目标时,纯文本的弊端就暴露无遗:冗长、容易误解、增加用户认知负荷。用户需要的不是一个“话痨”,而是一个能在合适时机递上“智能表格”或“决策卡片”的贴心助手。
生成式UI(Generative UI)的理念应运而生:让AI模型根据当前对话上下文,动态生成包含控件、选项和状态的可执行界面。然而,这个方向面临三大挑战。第一,缺乏系统化的学习问题定义:UI应该何时触发?生成什么结构?如何保证合规且有用?第二,缺少大规模、带UI标注的对话监督数据。第三,没有分离“协议正确性”与“交互质量”的评估基准。之前的尝试要么聚焦于无约束的网页/代码生成,要么局限于操控已有界面,而Macaron-A2UI要解决的是助手侧、回合级、基于固定声明式协议的UI生成这个完整问题。
A2UI:一套让AI学会“造界面”的声明式语法
为了让AI生成的UI安全、可移植且易于验证,论文引入了A2UI(Assistant-to-UI)协议。它不像让模型直接写HTML/JS那样危险和难以控制,而是让模型输出一个结构化的JSON消息序列,客户端用一个受信任的组件库来渲染。这好比AI不是直接去砌墙,而是画出一份标准的施工图纸,由指定的施工队(客户端渲染器)来执行。
A2UI协议通过四种消息类型组织交互:beginRendering(创建一个UI表面)、surfaceUpdate(更新表面的组件树)、dataModelUpdate(更新应用状态)、deleteSurface(删除表面)。生成这样的UI面临三重挑战:1. 协议有效性:输出必须语法正确且符合消息、引用、类型和可渲染性约束。2. 交互构建:即使协议正确,也可能用了错误的组件,或未能在文本中清晰解释UI选项。3. 用户体验质量:结构正确且功能合理的UI,也可能比纯文本多不了多少价值,或者显得突兀、增加认知负担。这个分解直接指导了后续的数据构建、评估和训练。
数据引擎:从异质对话中构建14,000条UI监督
没有数据,一切学习都是空谈。Macaron-A2UI的核心贡献之一,就是构建了一个大规模的A2UI语料库。数据来源覆盖任务型对话(MultiWOZ, SGD)、情感支持(ESConv)和动机访谈(AnnoMI),总计4,306个基础对话,生成了14,245条助手回合的训练样本,其中71.7%包含UI。
构建过程采用了一个混合规则与LLM的流水线。对于任务型数据,因为源数据已有丰富的标注(如意图、槽位),主要用规则驱动的生成器,像一条精密的生产线,根据对话状态自动装配出合适的UI控件。对于开放域数据(如情感支持),标注不直接指定UI,则采用两阶段LLM过程:先由“编辑”全局规划,决定哪些回合需要UI;再由“作者”具体生成组件内容。这好比先有总编辑确定选题方向,再有责任编辑撰写具体内容。
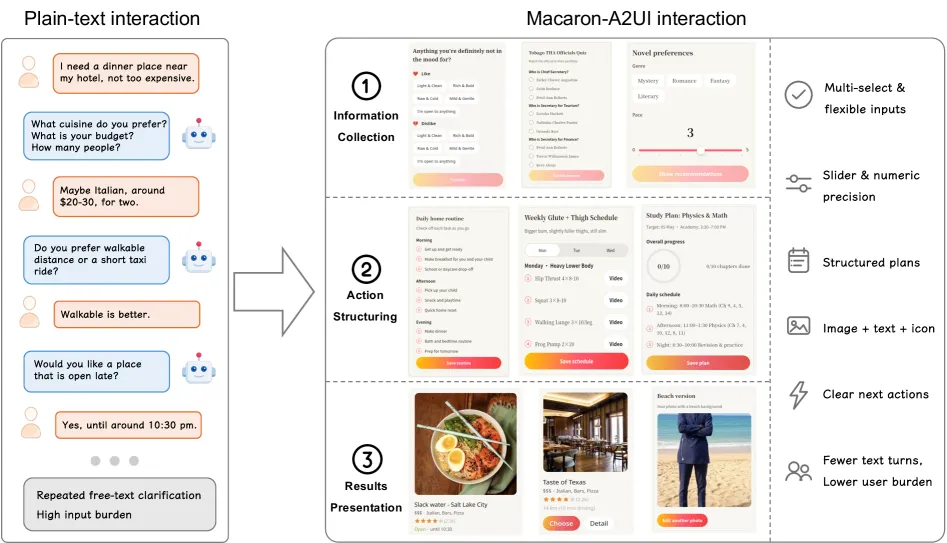
图1: 纯文本中繁琐的对话回合,借助助手生成的轻量结构化界面后,交互效率显著提升。
如上图所示,左侧展示了当用户询问多个航班选项时,纯文本回复的冗长与低效;而右侧的生成式UI方案,将关键信息(航班、时间、价格)提炼为可直接点击选择的卡片,并附带清晰的确认按钮。这种对比直观地体现了生成式UI的核心价值:降低用户的信息获取与决策成本。论文强调,UI的目标不是把文字搬上屏幕,而是提供纯文本无法实现的交互价值。
此外,为了覆盖低频组件,他们还进行了组件定向增强,增加了约29.2%的样本,重点补充了滑块、日期选择、模态框等布局和交互组件。所有生成的数据都要经过严格的四层验证:格式、结构、数据绑定和语义验证。首次通过率91.3%,经过三次错误反馈重试后,最终可渲染率高达99.2%。
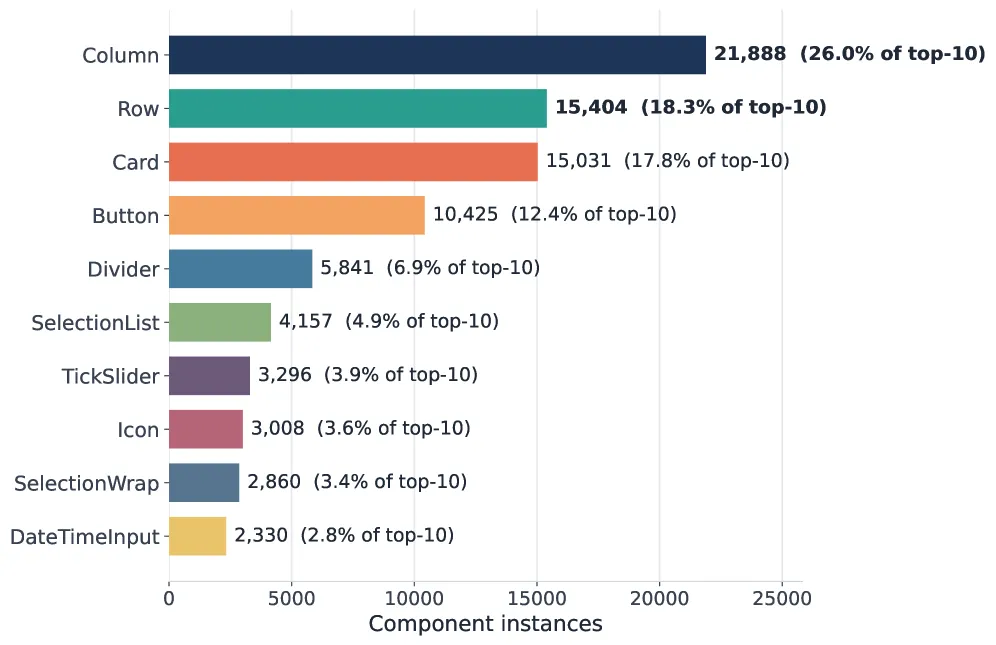
图2: 训练语料库中Top-10组件频率统计。
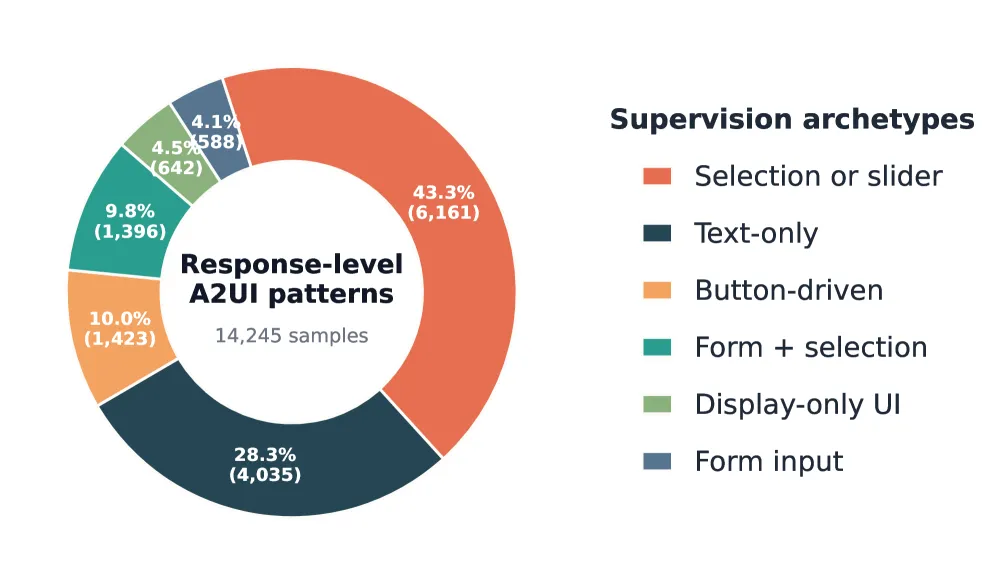
图3: 训练语料库中响应级别的监督原型分布。
上面这两张图揭示了语料库的构成细节。图2显示,Label、Column、Row、Card等结构性组件是UI的骨架,而Button、SelectionList等交互组件则提供了执行动作的监督信号。图3则展示了响应级别的多样性,不仅包含纯文本回合,还广泛覆盖了基于选择、滑块、按钮、表单等不同交互模式的UI响应。这确保了模型学到的不是表面的JSON语法,而是从布局组合到交互决策支持的丰富A2UI结构。
A2UI-Bench:三层评估,区分“能用”和“好用”
有了数据,如何科学地评估模型?论文提出了A2UI-Bench,一个包含300个任务的专用基准,涵盖三种任务结构:原子任务(单回合)、深度任务(多回合一致性)、宽度任务(单回合多目标)。评估框架分为三个层次,这设计得相当精巧,能把模型的能力拆解得明明白白。
L1(语言侧-协议正确性):像语法检查器,评估JSON是否可解析、是否符合协议、引用是否完整等。它是一道硬门槛,输出格式都错了,后面就没法看了。L2(语言侧-任务构建质量):由LLM担任“产品设计师”来评判,评估UI触发是否恰当、组件类型是否匹配意图、UI内容是否与文本描述一致、数据模型利用是否合理、交互动作是否完整。L3(语言侧-用户体验质量):由LLM担任“用户体验研究员”来评判,评估UI是否比纯文本更有价值、文本到UI的过渡是否自然、信息量和交互复杂度是否在用户认知负荷之内。
此外,还有V1-V3(视觉侧)评估,将模型输出的A2UI通过真实的Flutter渲染器生成截图,再用视觉语言模型(VLM)来检查视觉完整性、任务对齐度和操作清晰度。这确保了评估的是用户最终看到的“成品”,而不仅仅是中间的JSON。
训练配方:轻量微调 + 强化学习,内化UI能力
论文采用了一个参数高效的两阶段训练方案。第一阶段是基于LoRA的监督微调(SFT),使用构建好的A2UI语料库,直接教模型学会“看对话上下文,输出自然语言+结构化UI”的联合格式。这一步主要是打基础,让模型知道UI长什么样、该怎么输出。
第二阶段是基于奖励驱动的强化学习(GRPO)。这里的关键在于奖励函数的设计,它精准对应了A2UI-Bench的评估层次:
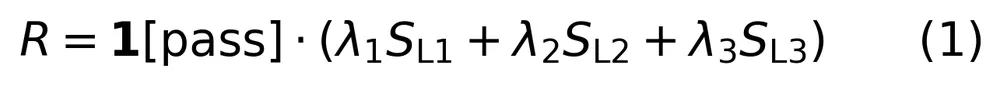
其中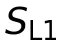 、
、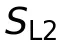 、
、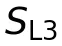 分别对应协议、任务构建和用户体验的质量分数。如果输出过不了最基本的协议检查(比如JSON格式错误),奖励直接为0。这个设计让强化学习的目标与最终评估目标高度对齐。
分别对应协议、任务构建和用户体验的质量分数。如果输出过不了最基本的协议检查(比如JSON格式错误),奖励直接为0。这个设计让强化学习的目标与最终评估目标高度对齐。
训练在Qwen3-30B和Qwen3-235B等多个基座模型上进行。SFT用标准的自回归损失,GRPO则采样一组候选回复,根据奖励计算组内相对优势,优化策略。整个过程只需要轻量的LoRA适配,不更新全部参数。
实验结果:内化能力超越“说明书”
实验结果非常说明问题。论文对比了两类模型:1) 前沿基线模型:如GPT-5.4、Gemini-3.1-Pro等,但评估时在prompt中给它们提供完整的A2UI协议说明书(schema)。2) Macaron-A2UI模型:经过本文训练,但评估时不提供说明书,完全依赖内化能力。
主要结果汇总如下表所示:
| Macaron-A2UI-Grande | w/o schema | 3.66 |
| Macaron-A2UI-Venti | w/o schema | 3.72 |
解读:
• 内化能力是王道:Macaron-A2UI-Venti(基于GLM-5.1训练)在不提供说明书的情况下,取得了3.72的综合分,超过了GPT-5.4在有说明书时的3.54分。这证明通过精心设计的数据和训练,模型可以将复杂的UI生成规则内化,无需在推理时塞入冗长的提示词。
• 训练效果显著:以Qwen3-235B为例,未经训练的基座得分仅21.6,经过SFT后跃升至63.6,再经GRPO优化后达到74.2,提升巨大。SFT解决了“怎么输出格式”的问题,GRPO则解决了“输出什么内容更好”的问题。
• 前沿模型离谱地弱:没有说明书加持,GPT-4o-mini、DeepSeek-V3.1等得分极低(25.5左右),说明通用模型对这种需要严格结构化输出的任务几乎无能为力。
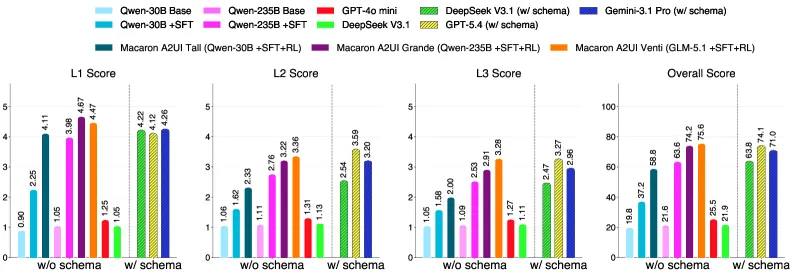
图4: 训练流程消融实验及与完整提示上界的对比。
上面这张图清晰地展示了SFT和GRPO两个阶段带来的阶梯式提升。尤其值得注意的是,即使对于较小的30B模型,GRPO也将其整体分从37.2拉升至58.8。而对于235B大模型,SFT已经打下很好基础(63.6),GRPO则将其推向更优(74.2),且L1(协议)分数增长最快,L2和L3随后稳步提升。
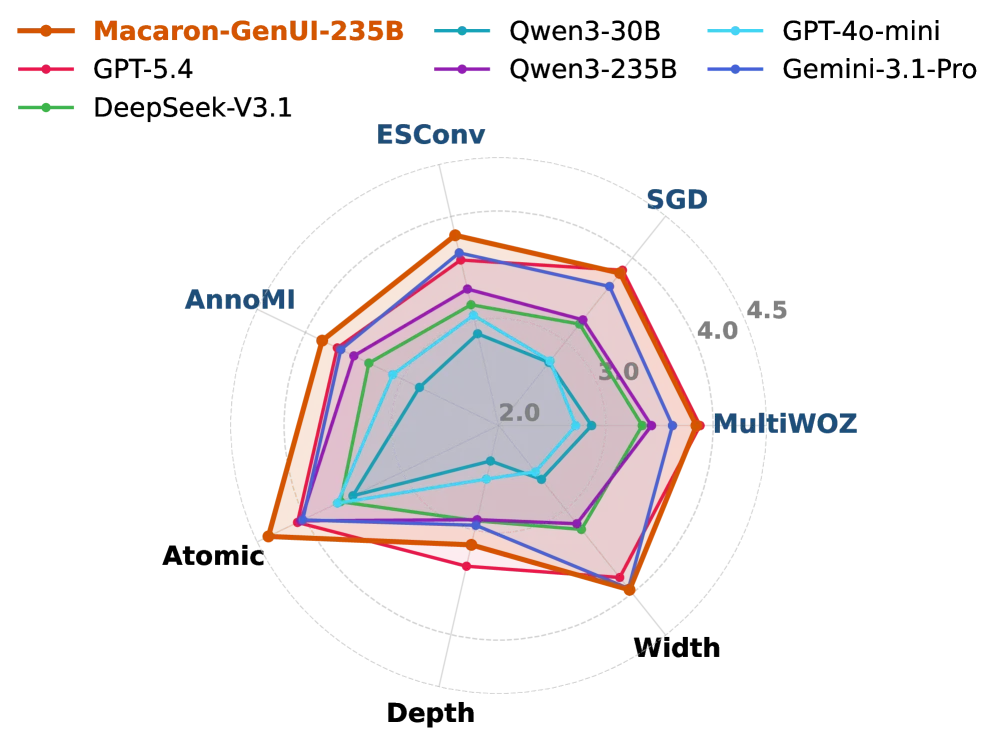
图5: 模型在A2UI-Bench上按数据集和任务类型的性能细分。
如上图所示,Macaron-A2UI-235B在所有四个源数据集和三种任务类型上都表现出色且稳健,得分范围很窄(3.82-3.84)。它在原子任务和宽度任务上是最强的,表明RL主要强化了模型将对话意图转化为简洁、结构良好、交互就绪的UI决策的能力。
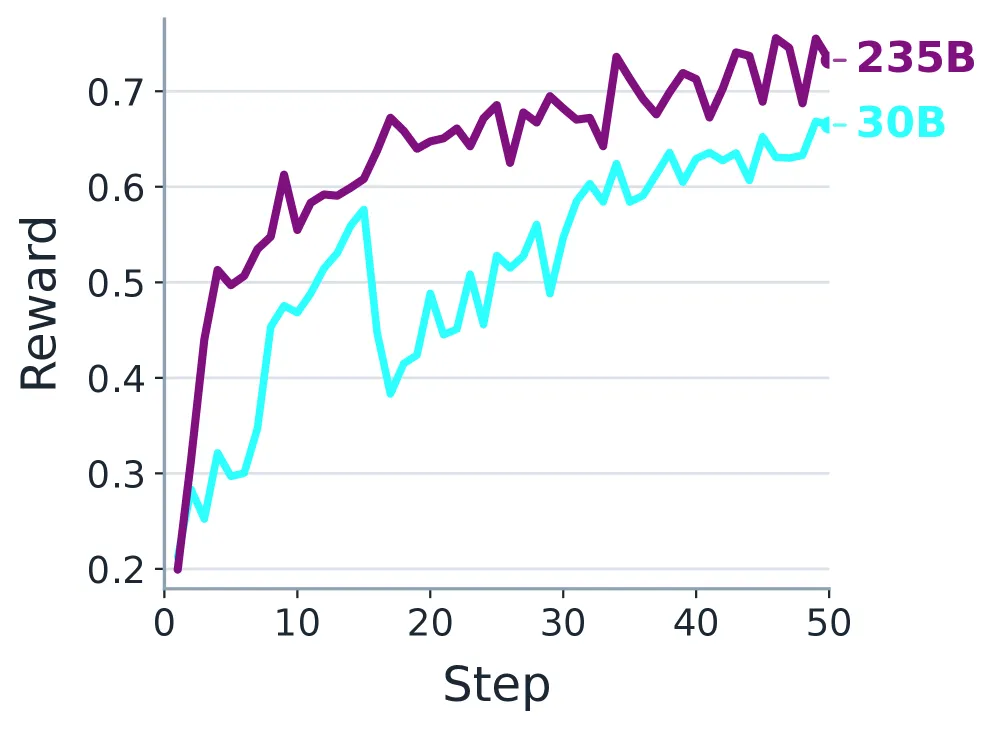
图6: GRPO训练过程中的总奖励轨迹。
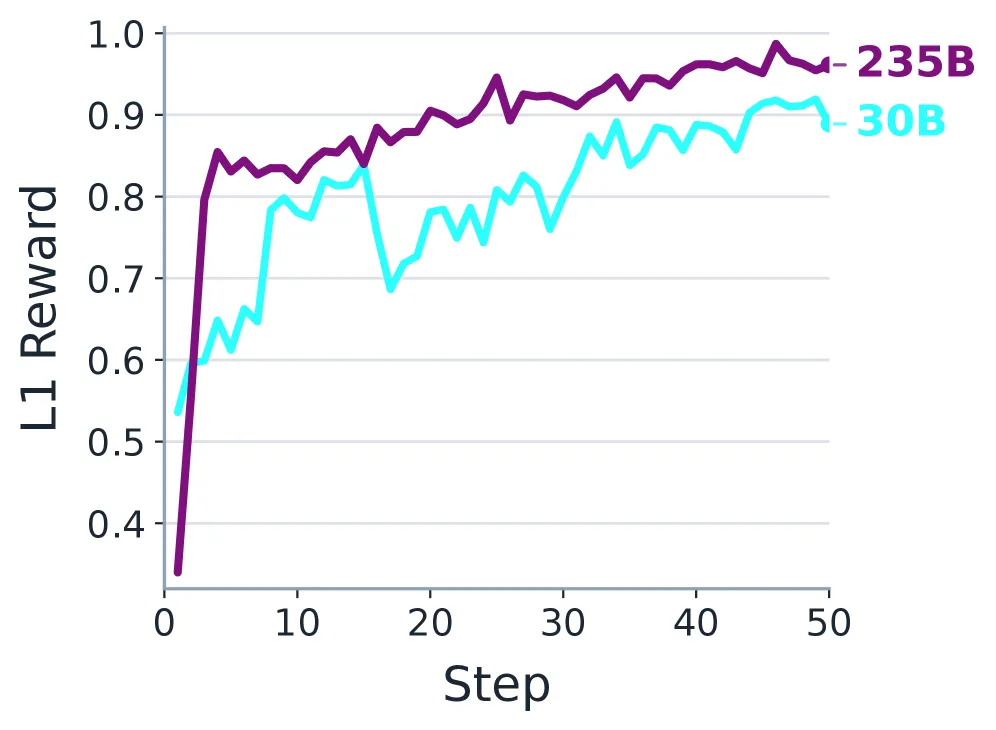
图7: GRPO训练过程中L1奖励轨迹。
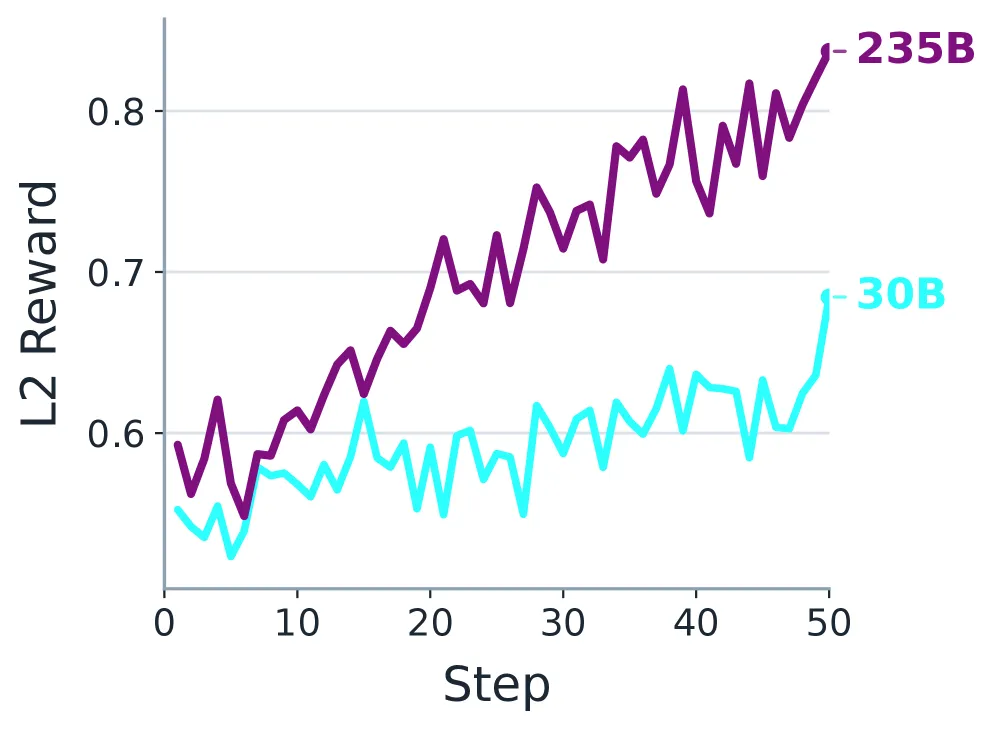
图8: GRPO训练过程中L2奖励轨迹。
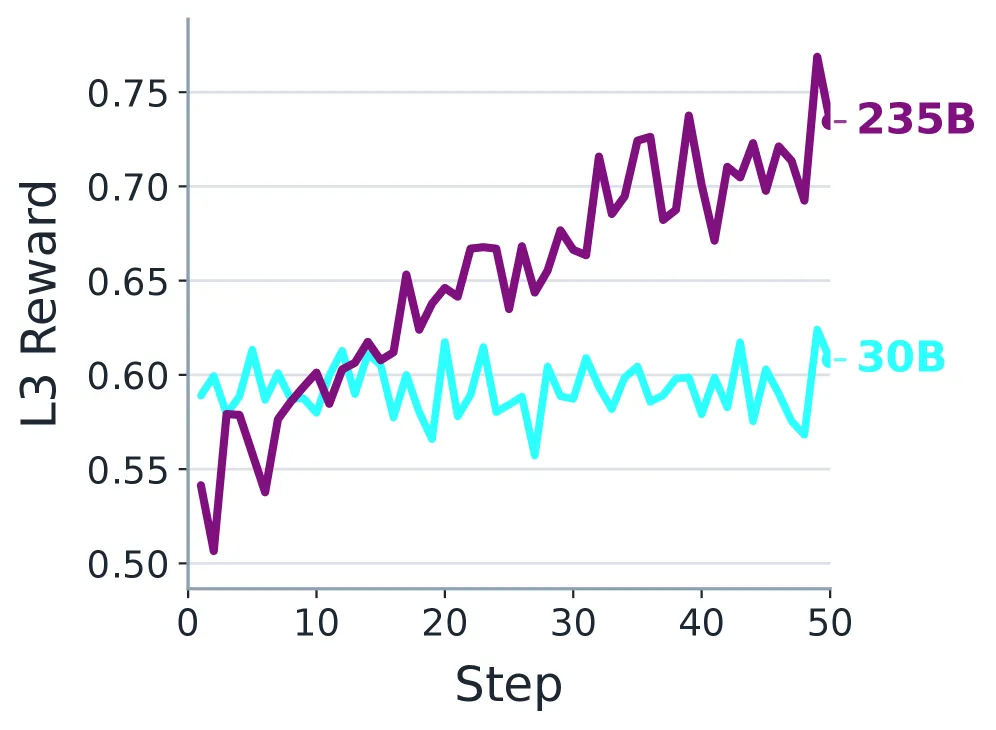
图9: GRPO训练过程中L3奖励轨迹。
上面这组奖励轨迹图揭示了强化学习的优化动态。一个非常一致的模式是:L1(协议正确性)奖励最先、最快地上升。这是最合理的,因为格式错误、协议违规等硬伤会被直接惩罚,学习信号最稳定。L2和L3(任务构建与用户体验)的提升则更渐进。对于235B大模型,L2和L3在整个训练过程中持续稳步提升,说明一旦协议能力稳定,大模型能更均衡地优化交互质量。而对于30B小模型,L3奖励曲线明显更平缓,是最难优化的部分,这可能与小模型对复杂交互意图的理解和表达能力受限有关。
个人视角:系统化的起点,而非终点
真正的贡献:Macaron-A2UI最大的价值,是将生成式UI从一个模糊的概念,系统化为一个定义清晰、可学习、可评估的研究问题。它没有停留在“让AI写网页”的层面,而是聚焦于助手在对话回合中生成的、基于声明式协议的轻量UI。配套的14K样本数据集、A2UI-Bench评估基准和两阶段训练配方,构成了一个完整的研究闭环。此外,他们开源了模型、基准和评估协议,为社区提供了坚实的起点。
业内潜台词:这项工作暗示了AI交互范式的一种演进:从“文本填空”到“行动规划”。助手的能力正从生成答案,向规划并呈现交互流程转变。A2UI协议是一种结构化“行动语言”的雏形。论文中基于LoRA的轻量训练方式,也表明这种新能力可以以较低的成本“注入”现有大模型,而不是从头训练一个巨型多模态模型。
不足与后续:论文也坦诚指出了局限。A2UI协议仍在演进(v0.8),模型处理复杂多回合交互和用户体验的能力仍是瓶颈,且实时生成、验证和渲染结构化UI可能带来延迟问题。未来方向可能包括:1) 更通用、灵活、Token高效的UI生成机制,不局限于当前协议。2) 深度个性化,UI不仅要符合任务,还要匹配用户习惯和偏好。3) 多模态融合,UI的生成和渲染与语音、视觉等通道更紧密地结合。4) 安全与可控性,在生成动态界面时,如何确保内容安全和符合伦理,将是长期课题。
总的来说,Macaron-A2UI为我们描绘了一幅未来交互的蓝图:AI助手不再只是滔滔不绝的应答机,而是懂得在恰当时机递上合适交互界面的智能伙伴。虽然离完美体验还有距离,但这项工作无疑为生成式UI的产业化应用铺下了一块关键的技术基石。
❤️❤️❤️如果这篇内容对你有帮助,欢迎点个赞、点个在看,也欢迎转发给更多有需要的朋友。你的每一次互动,都是我持续更新的动力。❤️❤️❤️
论文原文: https://arxiv.org/abs/2605.24830
