 夜雨聆风
夜雨聆风5 月底,慧荣科技(Silicon Motion)在 Computex 前夕发布了一款有点"反常识"的产品:SM2524XT,专门为 AI PC 优化的 PCIe Gen5 DRAM-less SSD 控制器。
反常识在哪?DRAM-less 在存储行业通常意味着"性价比选择"——成本优先,性能靠边站。但慧荣这次声称能做到 250 万 IOPS 随机性能、14GB/s 顺序读取、功耗还不到 5W。这些数字放在带 DRAM 的高端控制器上都不算寒酸。
更关键的是定位:慧荣明确把 SM2524XT 瞄准"KV Cache 密集型负载"。这背后藏着一个判断——AI PC 的存储瓶颈正在从顺序速度转向随机 I/O 和低延迟,而这恰好是 DRAM-less 架构通过聪明设计能补上的短板。
问题是,这个判断站得住脚吗?AI PC 真的需要为 KV Cache 专门优化存储?还是说这只是一场提前押注的豪赌?
KV Cache:从 GPU 内存溢出到本地存储的新战场
要理解慧荣在赌什么,得先搞清楚 KV Cache 到底是什么,以及它为什么会变成存储问题。
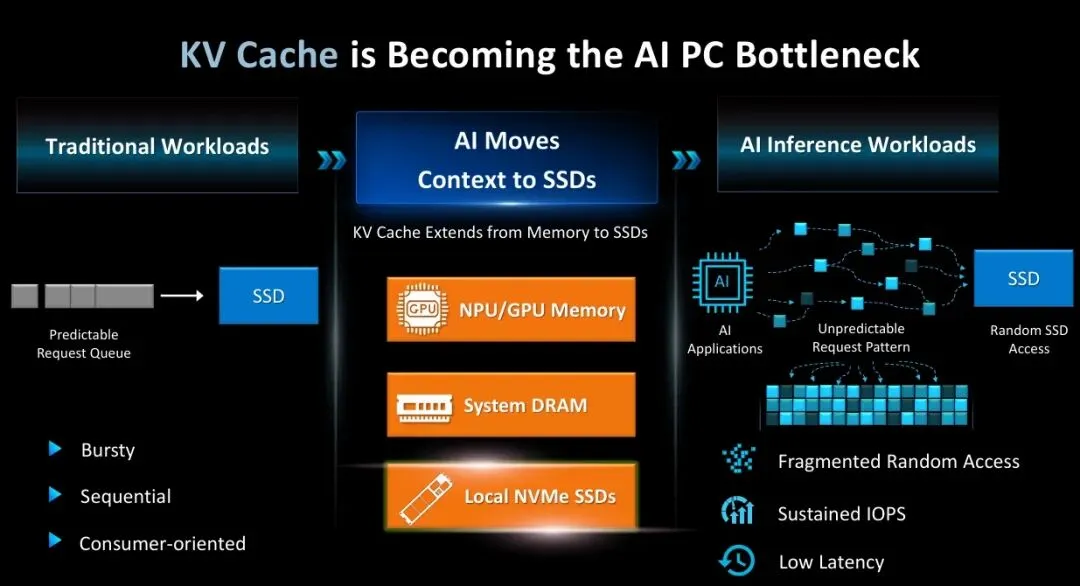
在大语言模型推理过程中,每生成一个新 token,模型都需要回顾之前所有 token 的 Key 和 Value——这就是 KV Cache。早期模型的上下文窗口只有几千 token,KV Cache 占的内存还算可控。但当上下文窗口从几千扩到几万、几十万甚至百万 token 时,KV Cache 的内存占用就变成了线性增长的噩梦。
arXiv 2603.20397 号论文把 KV Cache 叫做 LLM 部署的"一阶挑战"。它不仅吃掉 GPU 内存容量,还占用内存带宽,直接拖累推理吞吐量。更麻烦的是,随着 AI 应用从云端往边缘跑,越来越多的推理任务开始在本地执行——企业 AI Agent、机器人系统、AI 编程环境,这些场景下的 GPU 内存更是捉襟见肘。
于是,行业开始探索一个权衡方案:把部分 KV Cache 从 GPU 内存"溢出"到本地 NVMe SSD。这不新鲜,CPU 和内存之间早就有 Swap 机制。但传统 SSD 是为"偶尔的大文件读写"设计的,KV Cache 的访问模式完全不是这么回事。
慧荣在产品资料里描述得很清楚:KV Cache 负载是"持续的碎片化随机读写流",高度依赖持续 IOPS 吞吐和低延迟访问。换句话说,传统 SSD 评测最爱看的顺序读写速度(那些 7GB/s、14GB/s 的大数字),在 KV Cache 场景下几乎没用。真正重要的是随机 IOPS 和延迟稳定性。
这就是慧荣押注的第一个逻辑:AI PC 的存储需求正在从顺序速度转向随机性能。
DRAM-less 的逆袭:250 万 IOPS 怎么炼成的
DRAM-less SSD 控制器在存储行业一直是"二等公民"。没有板载 DRAM 缓存,地址映射表(FTL)只能存在 NAND 闪存里,每次随机访问都可能触发额外读取。结果就是:顺序读写还凑合,随机 IOPS 一塌糊涂。
但慧荣这次声称 SM2524XT 能做到 250 万 IOPS。这数字有多夸张?ServeTheHome 报道里给了个对比:多年前,他们用 24 个 SATA SSD 才堆出 100 万 IOPS。现在一个 DRAM-less 控制器就能做到 2.5 倍。
慧荣怎么做到的?答案是"用计算换存储"。
SM2524XT 用了四核 Arm Cortex-R8 处理器,配合四个 NAND 通道并行跑。每个通道支持 16 个 chip select,接口速度最高 4,800 MT/s。核心思路是:既然没 DRAM 缓存来加速地址查找,那就用更多计算核心和更快 NAND 接口来并行处理 FTL 调度和纠错。
技术细节上,SM2524XT 集成了几个关键技术:
SCA(Separated Command Address):ONFI 5.1 引入的技术,把命令和地址信号分开处理,降低 NAND 访问延迟。慧荣是第二代主流控制器实现这个,说明他们在 NAND 接口优化上确实下了功夫。
NANDXtend 第 8 代纠错技术:支持 4KB LDPC ECC,还有磁盘训练机制。这对 QLC NAND 很重要——QLC 的耐久性和数据完整性本来就是短板,AI 推理又是持续负载,没有强纠错能力根本撑不住。
PI-LTT 低电压优化:通过降低 NAND I/O 电压减少功耗。慧荣给的数据是:SM2524XT 在 4.689W 功耗下跑出 14,800 MB/s 顺序读取,前代 SM2504XT 在 4.67W 功耗下只有 11,511 MB/s。功耗几乎不变,吞吐量提升 29%。
但这里有个问题:慧荣只给了顺序读取的功耗数据,没给 250 万 IOPS 随机负载下的功耗和热表现。对笔记本和小型 AI PC 来说,持续随机 I/O 的热管理可能才是真正挑战。ServeTheHome 也提到,"SSD 热管理在持续负载下可能成为真正限制"。
还有个更根本的问题:DRAM-less 设计意味着持续随机 IOPS 对 NAND 质量和 FTL 实现极度敏感。慧荣不直接卖 SSD,只供应控制器给 SSD 制造商。最终产品性能高度依赖 NAND 闪存合作伙伴的选择和固件调优的激进程度。换句话说,250 万 IOPS 是理论上限,实际产品能做到多少,还得看下游厂商的良心。
竞争维度重构:顺序速度不再是唯一战场
慧荣的押注,本质上是在赌一个趋势:客户端 SSD 的竞争维度正在从顺序速度扩展到随机性能、低延迟和能效的多维竞争。
这判断有多激进?看看过去十年的 SSD 评测就知道了。从 SATA 到 NVMe,从 PCIe Gen3 到 Gen4 再到 Gen5,整个行业的营销话术都围着一个数字转:顺序读写速度。3GB/s、5GB/s、7GB/s、14GB/s……数字越大越好。至于随机 IOPS?那是数据中心 SSD 才需要关心的指标。
但 AI PC 可能会打破这个惯性。如果 KV Cache 真成了本地存储的主要负载,随机 IOPS 和延迟稳定性就会从"锦上添花"变成"刚需"。这对整个客户端 SSD 市场是个结构性变化。
问题在于:这个"如果"有多大概率成立?
目前看,KV Cache 溢出到本地存储还是个相对小众的场景。主流 AI PC 应用——Copilot、文档智能摘要、实时翻译——不需要几十万 token 的上下文窗口,GPU 内存够用。真正需要 KV Cache 溢出的,是那些跑本地大模型、长上下文推理、多轮对话的场景。
这个市场有多大?不好说。但慧荣显然在赌它会快速增长。
更有意思的是成本因素。当前 DRAM 和 NAND 价格环境下,行业对 DRAM-less SSD 的关注度在上升——不是因为性能,而是因为成本控制。如果 DRAM-less 设计恰好能在 AI 负载下发挥优势,那就是歪打正着的完美组合。
行业影响:一场提前到来的洗牌?
如果慧荣的押注成立,整个客户端 SSD 控制器市场可能会迎来一次洗牌。
首先是竞争对手的反应。群联(Phison)、江波龙、联芸这些主流控制器厂商会跟进 AI 优化吗?如果跟进,是做 DRAM-less 路线还是高端带 DRAM 路线?如果不跟进,会不会被慧荣抢走 OEM 订单?
其次是 NAND 厂商的策略调整。三星、美光、铠侠、长江存储这些供应商,可能需要调整产品规格来适配 AI 负载——比如优化 QLC NAND 的随机读写性能,或者针对 KV Cache 场景设计专门的 NAND 颗粒。
第三是 OEM 厂商的选择。联想、戴尔、惠普这些 PC 大厂推 AI PC 时,会不会把存储子系统当差异化卖点?"针对 AI 优化的 SSD"能不能成为有说服力的营销话术?
最关键的是:AI PC 的定义可能会从"NPU 算力"扩展到"存储子系统"。如果 KV Cache 真成了瓶颈,一台 AI PC 的好坏,就不只取决于有多少 TOPS 的 NPU 算力,还要看存储子系统能不能撑住持续的随机 I/O 负载。
从芯片设计到系统优化,AI 时代的竞争正在变成全栈能力的比拼。这不只是存储控制器的事,也关系到整个 AI 基础设施的协同设计——从算力芯片、存储子系统到 EDA 工具链,每个环节都需要针对 AI 负载重新优化。IC Agent Hub 这类针对芯片设计流程的 AI 工具平台,也在尝试从设计侧解决类似问题:通过私有化部署确保数据安全,通过 AI Agent 提升设计效率。存储优化和设计优化,本质上都在解决 AI 时代的系统级瓶颈。
未来展望:押注还是豪赌?
慧荣的 SM2524XT 本质上是场"提前量"押注。问题是,这个提前量有多大?
乐观情况:AI PC 的本地推理需求快速增长,上下文窗口持续扩大,KV Cache 溢出到本地存储成为普遍现象。这种情况下,慧荣会成为先行者,占据 AI PC 存储市场的先发优势。竞争对手要么跟进要么被甩开,整个客户端 SSD 市场的竞争规则会被重写。
悲观情况:AI PC 的主流应用仍然是轻量级推理,KV Cache 溢出只是极少数场景的需求。这种情况下,SM2524XT 的"AI 优化"就成了营销噱头,实际市场需求撑不起产品溢价。OEM 厂商不会为小众场景买单,慧荣的研发投入打了水漂。
更可能的情况是介于两者之间:AI PC 市场确实在增长,但增长速度没想象中那么快。KV Cache 优化会成为"加分项",但不是"必选项"。这种情况下,慧荣的策略是否正确,取决于两个关键变量:
第一,DRAM-less 设计在实际产品中的表现能否接近宣传数据。250 万 IOPS 是实验室数据,下游厂商的固件调优、NAND 颗粒选择、热管理方案,都会影响最终用户体验。如果实际产品大幅缩水,OEM 厂商不会买账。
第二,AI 应用的演化速度。如果大语言模型的推理效率持续优化,KV Cache 的内存占用得到有效压缩(比如通过量化、剪枝、稀疏化技术),那么"溢出到本地存储"的需求可能会被推迟甚至消失。反过来,如果多模态 AI、长上下文对话成为主流,慧荣的押注就会提前兑现。
目前看,慧荣至少做对了一件事:在成本可控的前提下(DRAM-less 本身就有成本优势),为一个可能爆发的市场提前布局。即使 AI PC 的 KV Cache 需求没预期那么大,SM2524XT 作为一款主流 PCIe Gen5 控制器,也不至于完全没市场。
但如果 AI PC 真的爆发,慧荣可能会成为这场变革中的最大赢家——不是因为技术有多领先,而是因为他们比别人更早看到了存储瓶颈的迁移。
写在最后
慧荣的 SM2524XT 提出了一个有意思的问题:AI PC 的存储瓶颈在哪里?
过去十年,存储行业的答案是"顺序速度"。但 AI 时代的答案可能是"随机性能和延迟稳定性"。如果这个判断成立,整个客户端 SSD 市场的竞争规则都会改写。
问题是,这个"如果"有多大概率成立?现在下结论还太早。但至少慧荣做了一件对的事:在别人还在堆顺序带宽时,他们开始关注 AI 负载的真实需求。
至于 DRAM-less 架构能不能在 AI 负载下真正发挥优势,还得等实际产品出来、第三方测试跑完,才能见分晓。但有一点是确定的:存储行业的竞争维度,已经开始从"数字大小"转向"场景适配"。
这可能是 AI 时代带给存储行业的第一个真正改变。
作者:麒芯
参考来源:StorageReview, ServeTheHome, arXiv 2603.20397
本文仅代表作者观点,不构成投资建议
💬 加入 IC Agent 技术交流群
群里聚集了芯片设计工程师、IT/CAD 负责人和 AI+EDA 从业者,聊技术、聊工具、聊行业趋势。

👉 关注回复「加群」,拉你进群一起聊
👉 关注回复「合作」,如果你在做 AI+ 芯片/EDA 相关,欢迎来聊
后续会持续更新这个系列,关注不迷路。
