 夜雨聆风
夜雨聆风抽象地讲大模型,很难理解。
大部分科普文章一上来就是各种比喻、类比,然后那些类比又让人更懵——等下你就能看到了。
听完之后好像懂了,实际上更一头雾水,啥也没记住。
不如我们直接下一个最简单的大语言模型,Qwen3-0.6B,边跑边看,到底是咋回事。
它很小,性能也很差,随便一台电脑都能跑起来。
但麻雀虽小,五脏俱全,大模型该有的东西它全有,最适合用来学习。
如果你手头有电脑,再有个 Claude Code、codex 之类能直接操作电脑的 AI agent,就可以跟着我一步步来。我这边就以 Claude Code(下面简称 cc)作为例子。
新建个文件夹,我要学习 AI 的基础知识。你先下载安装 ollama,然后装上 Qwen3-0.6B,要求能在我电脑上跑起来。告诉我到底下载了哪些东西,里面每个文件分别是干嘛的。
(ollama 是个能在本地一键跑开源大模型的工具,可以理解成模型的「应用商店 + 播放器」。)
其实这篇文章到这里就可以结束了。
接下来 cc 就是你最好的老师。任何一个地方你看不懂,都可以让它详细跟你解释一下。
因为我电脑上下了两个模型,所以一共十个文件:

一个大模型,其实就是这么几样东西拼起来的:
- • 权重本体(那个几百 M 到几个 G 的大文件,GGUF 格式):模型的所谓大脑几亿个数字全在这里面
- • 对话模板 / config / 默认参数:几 K 到几十字节的小文件,规定它怎么跟你对话、默认怎么发挥
- • license:开源协议
剩下的都是配角。真正吃显存、装着「智能」的,就那个权重大文件。
然后就让它从小到大,一个个拆解、讲给我听。
120B 跟 68B 那两个文件里装的是啥?你帮我打开看看。
(这里的 B 是字节。120B = 120 个字节,小得可怜。)
cc 告诉我:120B 里是一些默认参数,68B 那个其实就是一句系统提示词。
params 默认参数(120B 那个),那些参数分别是啥意思?
它先给我讲了个底层前提——这块正好跟上一篇《token》接上了:

模型不是「想好答案」,而是一个字一个字地猜。每生成一个字,它心里都算出一张概率表;至于「到底挑哪个字」,就由下面这几个参数说了算:
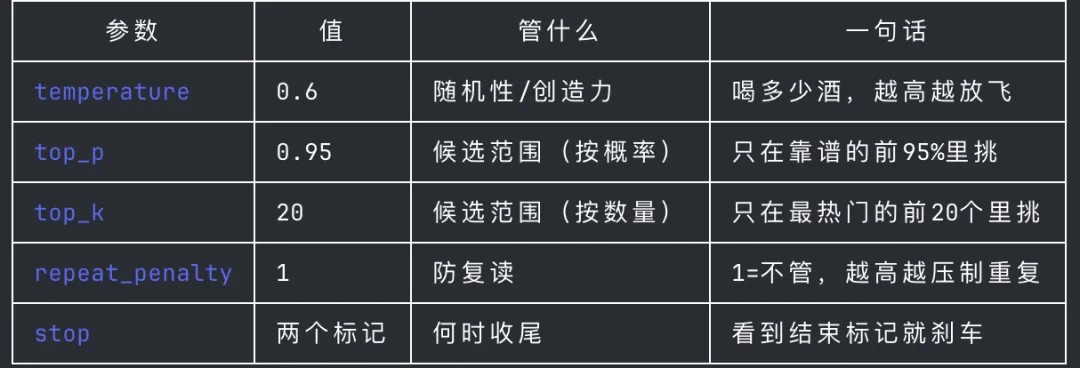
吐槽一句,我现在真的非常讨厌 AI 动不动给的什么「一句话总结」「一句话比喻」……蠢得一批
这一部分(参数)比较复杂,我们后面再详细看。先看看对话模板那块,里面都包含哪些内容。

听完 cc 这段解释,会发现一件挺有意思的事——
我们平时用 Claude Code、GPT,看到里面那些复杂的「模式」切换,默认会觉得:背后肯定加了一大堆复杂设定。
结果在前端传给大模型的时候,本质上只是加了个 /think 而已。
真的就是让它「多想想」。
就这么简单。但这点,太牛了。
明天继续看这些文件里是啥,
Y1D18 · 2026-06-09
10 年后再见
