 夜雨聆风
夜雨聆风智擎预测实验室 | AI技术前沿

2026年4月,国能日新发布了"旷冥"AI智能体系的两大核心模型——旷冥气象大模型4.0与旷冥电力交易大模型1.0。这套体系整合了超6000家新能源场站数据、各省电力交易中心全量历史与实时电价数据,以及全国能源领域最新政策文本数据,形成了覆盖气象感知、功率输出、市场交易、政策分解四大维度的全域数据矩阵。
在核心引擎层面,旷冥气象大模型4.0将预测时效从45天延伸至覆盖年度预测,而旷冥电力交易大模型1.0则通过"时空-博弈双驱动Transformer"架构,实现了策略结论的有效性约束与多主体适配。
这是行业的大事件。但作为一个在电力预测领域深耕多年的技术团队,我们想聊点不一样的——AI大模型很炫,但智擎云电选择了一条更务实的路线。

一、大模型的"能"与"不能":我们看到的三个现实
国能日新的"旷冥"体系代表了行业最前沿的探索方向,其技术路线值得尊重。但我们在服务湖北省内640家售电公司和用电企业的过程中,发现了三个现实问题:
现实一:数据量不够大,大模型吃不饱
国能日新服务超6000家新能源场站,数据规模足以支撑大模型训练。但智擎服务的大量中小用电企业,单户历史数据往往只有1-3年,日度数据点不足1000个。把这样的数据喂给参数量百亿级的大模型,就像用一杯水去灌一个游泳池——模型学不到规律,只会过拟合。
现实二:电力交易需要"可解释",大模型是"黑箱"
旷冥电力交易大模型1.0的"时空-博弈双驱动Transformer"架构很先进,但电力交易决策需要向管理层汇报"为什么这样预测"。当大模型输出一个预测结果时,交易人员很难解释"是哪些因素主导了这个判断"。而在偏差考核趋严的现货市场,"说不清的预测"意味着"担不起的责任"。
现实三:边缘场景需要"实时响应",大模型跑不动
国能日新的"旷冥"3.0配备了PB级数据存储与智能调度平台,算力架构支持8类并行计算框架。但智擎的很多客户现场,网络条件差、算力资源有限,需要的是毫秒级响应的边缘预测。把大模型部署到YC6100这种200×140×38mm的边缘设备上?目前还不现实。

二、智擎的务实路线:大模型赋能,小模型执行,规则引擎兜底
面对这些现实,智擎云电的电力交易用电量管理及预测算法平台采用了"分层架构":
云端层:大模型做"趋势判断"
我们接入气象大模型的中长期趋势输出,作为预测模型的输入特征之一。比如旷冥气象大模型4.0覆盖的年度预测时效,可以为我们提供季度级的气温、降水趋势判断,辅助中长期交易决策。但我们不会依赖大模型做日内预测——那需要分钟级的数据刷新,大模型的推理成本太高。
边缘层:小模型做"实时预测"
在YC6100/YC6300边缘设备上,我们运行的是轻量化预测模型——ARIMA、XGBoost、轻量LSTM。这些模型参数量小、推理速度快、资源占用低,适合在边缘设备上实时运行。以YC6300的TMS32高速芯片为例,16路A/D采集的数据进入设备后,模型可以在500毫秒内完成一轮预测更新,满足现货交易对时效性的要求。
规则层:人工经验做"异常兜底"
我们保留了一套规则引擎,用于拦截"明显不合理"的预测结果。比如当模型预测某日用电量突增200%时,规则引擎会自动触发复核流程——是模型学到了真实规律,还是输入数据出现了异常?这套规则引擎的灵感,恰恰来自我们服务客户时积累的人工经验。
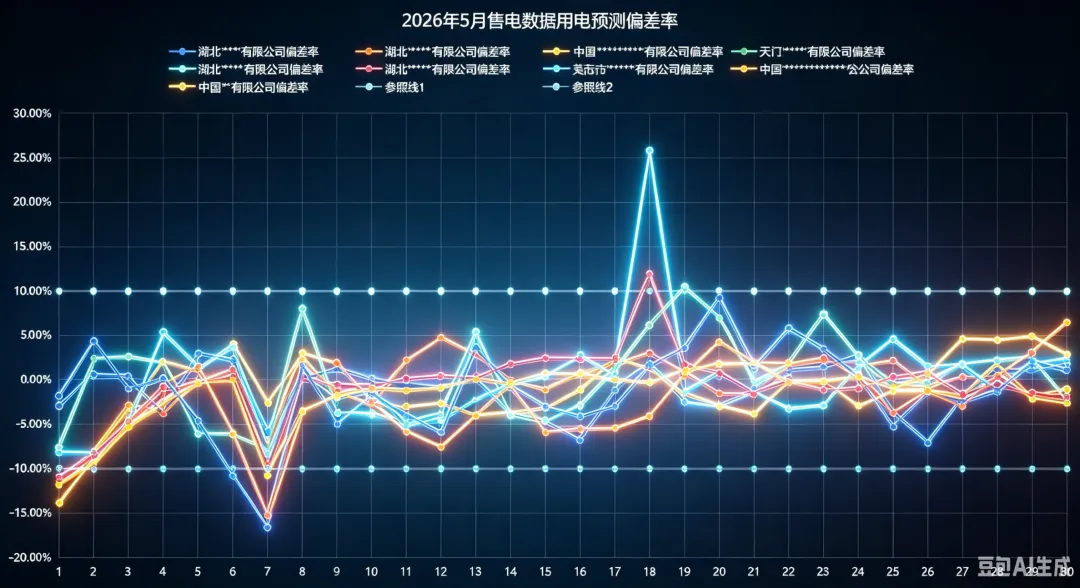
三、一个实战案例:5月18日的"26%偏差"事件
2026年5月,智擎服务的640家企业中,枣阳某企业在5月18日出现了26%的预测偏差率,远超±10%的考核线。事后复盘发现,该企业原计划当天停产检修,临时改为满负荷生产,用电负荷从预期的30%突增至110%。
我们的规则引擎在5月17日晚发出了二级预警:"该企业历史同期检修概率85%,但近期订单数据异常,建议关注生产计划变更。"客户收到预警后,虽然未能及时调整交易计划,但为后续应急响应争取了时间。更重要的是,这次事件让我们意识到——预测偏差不全是模型的问题,有时是"输入信息不完整"的问题。
现在,我们计划为客户开通"生产计划联动接口",将ERP系统中的生产计划数据接入预测模型。这不是什么高大上的AI技术,只是一个API接口的数据打通,但预计可以将同类异常事件的预测偏差降低80%。

四、我们的路线:先解决"数据治理",再追求"算法飞跃"
国能日新的"旷冥"体系代表了AI在电力行业的未来方向,智擎对此保持高度关注。但我们在实践中发现,对于绝大多数用电企业和售电公司来说,当前最紧迫的问题不是"用什么大模型",而是"怎么把多平台数据对齐"。
智擎的电力交易用电量管理及预测算法平台,同时接入电网、售电企业量测、第三方辅助量测、用采数据四大数据源。这些数据的格式、时间戳、计量单位、采样频率各不相同,未经治理的原始数据预测误差可达15-20%,而经过系统治理后,误差可以控制在2%以内。
我们的方向是:
第一,不盲目追新。大模型不是万能药,数据质量才是根基。先把交易中心、量测、用采的数据对齐了,比急着上Transformer架构更重要。
第二,小步快跑。持续解决数据治理问题,同时进行算法升级。智擎平台的数据质量评分体系,把每条输入数据打上0-100分的质量标签,低于80分就触发增强预测模式——这是小模型也能实现的"智能"。
第三,软硬结合。边缘设备保障实时性,云端大模型提供趋势洞察。YC6100/YC6300的本地预测+云端模型的定期优化,是目前最务实的部署方案。
第四,可解释优先。电力交易决策需要"说得清"的预测依据。智擎平台的每个预测结果都附带"影响因素权重",支持"假设分析"——调整某因素,看预测如何变化。这比大模型的"端到端预测"更适合当前的电力交易场景。
AI正在重塑电力预测行业,智擎在参与这个进程的同时,也选择了一条更务实的路线——既要拥抱最可靠的模型,更要做最可靠的预测。我们相信,在电力现货市场全面铺开的今天,"预测准确率98.5%"仍是"参数量100亿"最大的价值。
📞 商务咨询:13886174037
