2026·AI测试工具全景:测试平台篇89%的技术团队在进行AI测试,只有15%真正落地?
其实:差距不在技术,在工具和人的匹配!
我们见过太多的测试工具都是"雷声大雨点小"。
如今进入AI大模型时代,AI不只是在帮我们写测试脚本,而是在重新定义测试工程师该干什么:从维护定位器里解放出来,把精力放回测试设计本身。今天给大家介绍几款国外的AI测试工具平台/服务,看看在测试领域,在AI时代,别人是如何做的?
国外的AI 测试平台
今天介绍的几款基本都是SaaS平台,部分开源,但都有收费模式,我们可以在这些平台产品中体验和学习目前业界比较主流的技术和方案!
|
|---|
https://www.tricentis.com/products/automate-continuous-testing-tosca |
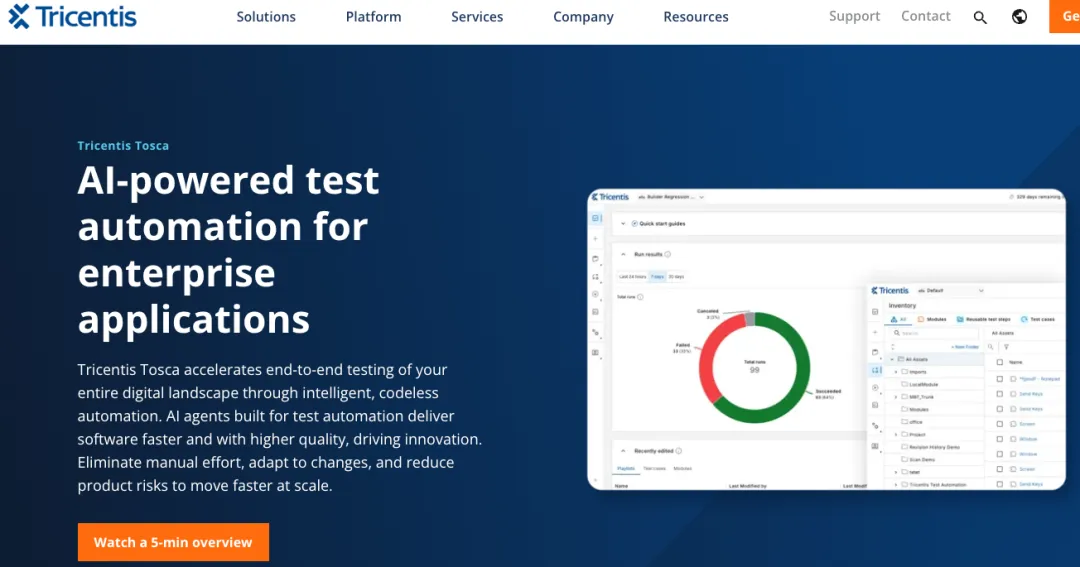
| 早期AI测试先驱,多策略定位器自愈(text/CSS/XPath/accessibility加权),UI变化自动切换。支持用户故事测试生成(beta),维护成本降低80%。 |
| Testim是最早将ML引入自动化测试的商业工具之一,2022年被Tricentis收购。其自愈系统的核心是多策略定位器引擎:对每个UI元素维护text、CSS、accessibility、XPath等多套定位策略,按历史稳定性加权排序。当应用UI发生变化导致首选定位器失效时,系统自动切换到次优策略,无需人工介入。支持低代码创作模式,测试人员可通过录制或拖拽创建测试用例。2026年beta版新增基于用户故事的AI测试生成:输入用户故事文本,AI自动推导出对应的测试场景和断言。CI/CD集成覆盖GitHub、GitLab、Jira、Azure DevOps、Jenkins。官方称定位器维护成本可降低80%。 |
|
|---|
| Mabl |
https://www.mabl.com/ |
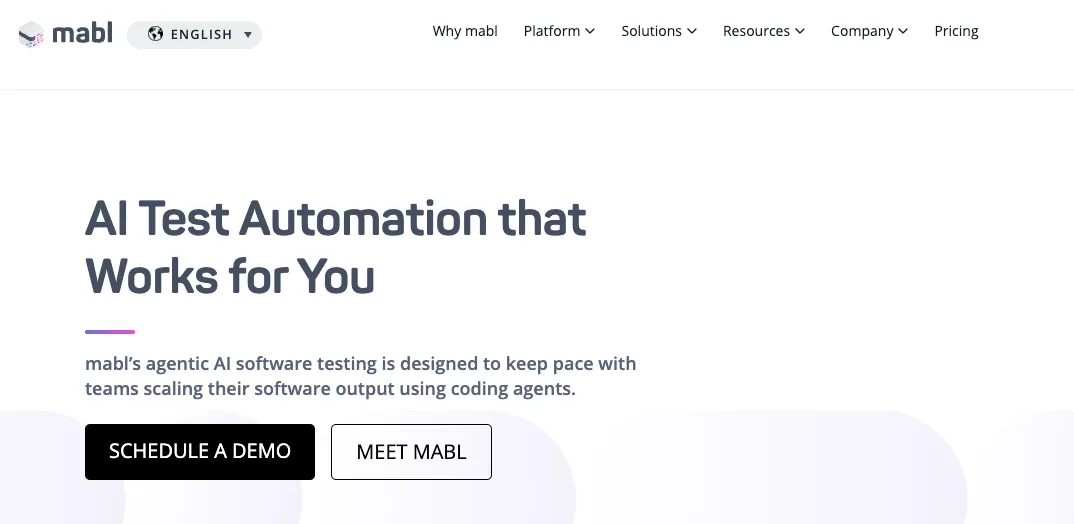
| AI-native SaaS平台,统一Web+API+性能+无障碍测试。Agentic Testing从自然语言生成测试,双指纹自愈(DOM+visual),Insights异常检测识别flaky和性能回归。 |
| Mabl是AI-native测试自动化平台,由前Google产品经理Dan Belcher和Izzy Azeri于2017年创立。2026年核心升级是Agentic Testing:AI代理可自主从自然语言要求(如"验证用户能用Google账号登录")生成结构化测试用例并执行。自愈引擎采用双指纹策略——同时使用DOM fingerprinting和visual fingerprinting,当按钮移动但外观不变时,visual指纹确保仍能定位。内置Insights异常检测引擎可在测试运行中自动识别flaky tests、性能回归和视觉变化,按严重程度排序推送给团队。提供MCP Server,开发者可在Cursor/Claude Code等IDE中直接触发测试运行和获取失败分析。统一覆盖Web UI、API、性能、无障碍四个维度。客户包括Workday、Vivid Seats、JetBlue。 |
|
|---|
| Functionize |
|
| AI-native企业平台,NLP+ML Engine双引擎驱动。自然语言测试计划→可执行测试,多维指纹元素识别准确率99.97%。适合大型企业从手动测试向AI测试过渡。 |
| Functionize自称首个AI-native测试平台,2026年发布Agentic Platform 6.0。架构分为两层:NLP引擎可将非结构化的自然语言测试计划(如PRD文档、用户故事)直接解析为可执行的测试步骤序列;ML Engine则使用计算机视觉、NLP和机器学习三者融合的方式,为整个应用构建UI行为模型,每次测试运行都通过强化学习反馈更新模型。元素识别采用多维指纹技术——每个元素从30K+维度(位置、颜色、字体、相邻元素关系、DOM路径等)提取特征,声称元素识别准确率达到99.97%。自愈系统在测试失败时会自动进行根因分析,区分"UI变更""数据问题""环境问题"三类失败原因,并排序推荐修复方案。支持跨浏览器并行执行。 |
|
|---|
| Katalon |
| github.com/katalon-studio |
| 全终端AI QA平台,社区版可用。AI Assistant双模式(Ask+Agent)加MCP Server驱动。LLM自愈定位器和AI根因分析,TrueTest捕获用户行为映射回归。定价低于Testim/Mabl。 |
| Katalon Studio在11.x版本中完成了重大AI架构升级。内置的Katalon AI Assistant(原名StudioAssist)支持两种工作模式:Ask Mode用于问答和代码片段生成,Agent Mode可自主在项目中创建/编辑测试用例、分析失败并建议修复方案。Agent Mode的底层基于MCP协议,集成了三个MCP Server——Katalon MCP(连接官方文档库)、Katalon Studio MCP(操作当前项目中的测试对象)、Katalon True Platform MCP(连接TestOps进行需求-测试关联)。AI Self-Healing使用LLM而非传统规则来动态生成替换定位器。AI Root Cause Analysis自动将测试失败归因到自动化脚本问题、测试数据问题、环境问题或产品Bug四类。TrueTest功能可捕获生产环境的真实用户交互行为,自动映射到回归测试套件中。2026年新增对GitHub Copilot的原生集成,开发者可在Katalon Studio中同时使用两个AI助手。 |
|
|---|
| Cypress Cloud(含AI功能) |
| github.com/cypress-io/cypress |
| Cypress Cloud AI套件。cy.prompt()自然语言生成测试+自愈缓存,Studio AI录制断言推荐,UI Coverage从缺口生成测试。免费Starter每月100次AI调用。 |
| Cypress Cloud在2026年集中推出了AI功能矩阵。核心是cy.prompt()命令——测试人员用自然语言描述操作步骤(如"点击登录按钮,输入用户名密码,验证跳转到首页"),AI自动生成对应的Cypress代码。生成结果支持跨机器缓存:同一prompt在CI中再次执行时不会重复调用AI模型,除非DOM发生变化。当选择器因UI变更失效时,cy.prompt()自动自愈——重新分析DOM并更新定位器。Studio AI在录制交互时会观察DOM变化并自动推荐断言(可见性变更、文本更新、URL变化等)。UI Coverage Test Generation可从覆盖率报告中识别出未覆盖的元素,一键生成测试骨架。Cloud MCP(Model Context Protocol)服务将Cypress Cloud中的运行数据暴露给外部AI编码助手。Error Summaries和Test Intent Summaries分别用AI生成失败原因和测试意图描述。 |
|
|---|
| Reflect |
|
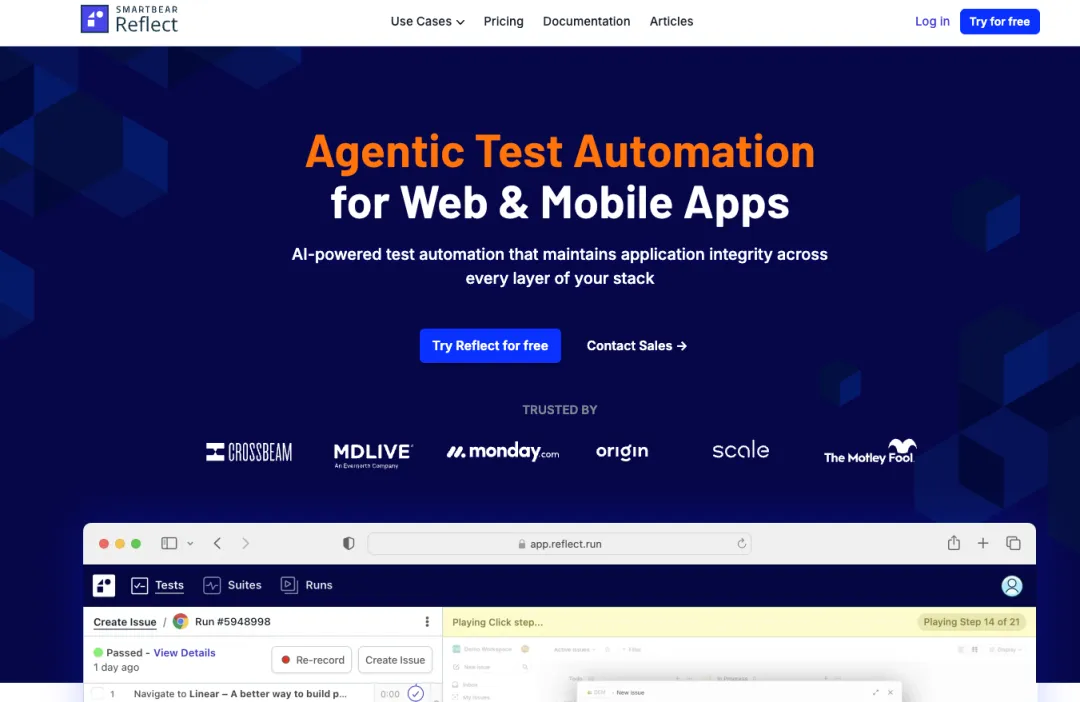
| 低代码AI测试平台,录屏+自然语言创建测试,AI自动生成稳定定位器,UI变化时自愈引擎自动修复。适合无编程背景的QA团队做Web E2E测试。 |
| Reflect是低代码E2E测试平台,核心卖点是AI驱动的测试创建和维护。测试人员可以通过两种方式创建测试:一种是录制模式,在浏览器中操作一遍应用,AI自动记录交互并生成稳定定位器;另一种是自然语言描述,直接输入你想要验证的场景。定位器策略上,Reflect的AI会综合分析元素的多个属性(ID、class、text内容、相邻元素、ARIA角色等),选择最可能长期稳定的组合。当应用UI更新导致元素定位器失效时,自愈引擎会自动检测并修复,无需人工编辑测试脚本。支持跨浏览器测试(Chrome/Firefox/Safari/Edge)和主流CI/CD集成。定价低于同类产品,适合预算有限但希望引入自动化测试的非工程团队。 |
|
|---|
| ACCELQ |
|
| 流程驱动自动化平台,QGPT纯英语逻辑生成测试。覆盖Web/API/Mobile/SAP,CI/CD嵌入式执行。适合企业内部端到端流程自动化场景。 |
| ACCELQ提供流程驱动的自动化测试框架,核心理念是将测试组织为业务流程图而非脚本。2026年推出的QGPT Logic Builder支持用户用纯英语描述业务规则和验证逻辑,AI自动将其转换为可执行测试步骤。平台覆盖范围广泛——Web应用、API接口、移动端(iOS/Android)和SAP系统均可统一管理。ACCELQ-Live是一个测试资产市场,团队可发布和复用标准化的测试模块。测试执行可嵌入CI/CD流水线,支持计划式执行和事件触发式执行。适合需要在多个系统之间编排复杂业务流程验证的企业团队。 |
|
|---|
| Virtuoso QA |
|
| 自然语言无代码测试平台。autonomous waits自动等待元素就绪减少flaky,AI生成测试场景和跨浏览器回归,基于CV的视觉验证。适合非技术QA团队。 |
| Virtuoso QA专注于自然语言驱动的无代码测试自动化。测试人员直接用自然语言定义测试步骤(如"在搜索框输入'Paris',点击搜索按钮,验证结果列表中出现'Eiffel Tower'"),平台自动解析意图并定位对应UI元素。autonomous waits是其减少flaky测试的关键——AI自动判断页面何时加载完成、元素何时可交互,无需人工配置显式等待时间。支持跨浏览器回归测试和一键扩缩容执行。2026年升级了AI测试场景生成能力,可根据应用的类型和功能自动推荐测试场景和边界条件。内置基于计算机视觉的视觉验证,可检测布局偏移和样式异常。 |
|
|---|
| Leapwork |
|
| 可视化无代码测试建模,拖拽流程块构建跨系统流程。AI辅助元素识别与自愈,hypervisual debugging可视化调试。适合多系统间复用测试流程的企业。 |
| Leapwork提供可视化无代码测试建模环境,测试人员通过拖拽预定义的流程块来构建跨系统测试流程。每个流程块封装了一个操作(如"点击按钮""读取数据库""调用API"),块与块之间通过连线定义执行顺序和数据传递。2026年强化了AI辅助的元素识别能力——在录制模式中,AI可自动识别应用中的可交互元素并推荐合适的操作块。自愈引擎在UI变化时自动更新元素定位信息。hypervisual debugging功能通过截图和状态快照的可视化对比,帮助快速定位测试失败原因。适合需要在ERP、CRM、Web、桌面等多个系统间编排和复用测试流程的企业。 |
|
|---|
| Checksum |
|
| AI从生产用户会话自动生成E2E测试,输出Playwright/Cypress标准代码。UI变化时AI自动修复。适合快速迭代、不想手动维护测试脚本的SaaS团队。 |
| Checksum采用"测试即服务"模式,核心差异在于测试不是由人编写的,而是AI通过分析生产环境的真实用户行为自动生成的。接入Checksum后,它会录制生产环境中的匿名用户会话,从中提取出用户的实际操作路径,包括happy path和边缘场景,然后自动生成对应的E2E测试。测试输出为标准Playwright或Cypress代码,用户可以查看、修改和版本控制。当应用的UI发生变化导致测试失败时,Checksum的AI代理会自动分析失败原因并修复测试代码。对于快速迭代、每周发布多次的SaaS团队来说,这大幅降低了测试脚本的维护成本。 |
|
|---|
| QA Wolf |
|
| 托管QA服务,AI Agent全流程生成测试代码。覆盖Web+API+Mobile,按结果付费,企业客户月增35%。适合无自建测试团队或不想维护测试基础设施的企业。 |
| QA Wolf提供的是托管QA服务而非纯软件工具。用户定义测试范围和验收标准后,QA Wolf的AI Agent全流程负责测试代码的生成、执行和维护,背后有真人测试工程师团队做质量兜底和策略决策。覆盖Web、API和Mobile三端。2026年企业客户月增长35%,典型客户是那些不想自建测试团队或不想维护测试基础设施的中型企业。收费模式是按结果付费——客户只为通过验收的测试覆盖付费,而非按工具座位或许可证收费。 |
如何选型决策矩阵?
| | |
|---|
| AI Coding Agents + Playwright | |
| AI Coding Agents + Playwright + Applitools | |
| Mabl/Testim + AI Coding Agents | |
| Tricentis Tosca/Functionize + AI Coding Agents + Applitools | |
| | |
| | |
测试工具/平台的选型最难的其实不是功能对比,而是认清自己团队的阶段与目前实力。
如果你的公司/团队开发能力,且资金有限,那可以自研,可以寻找开源替代或者二次开发等,不差钱的公司当然有更多选择。
就没有花钱的不是~
 夜雨聆风
夜雨聆风