 夜雨聆风
夜雨聆风导语:
昨天我们聊了一个问题:什么是大语言模型?
先快速回顾一下:
大语言模型就像一个读过海量文字的"超级语言学霸",通过学习大量文本掌握语言规律,能写文章、做总结、翻译、写代码、陪人聊天。
但很多人可能会继续好奇:
人工智能是突然火起来的吗?
ChatGPT、大语言模型是凭空冒出来的吗?
AI 到底经历了怎样的发展过程?
人工智能不是新事物,它已经走过了几十年
早在上世纪 50 年代,科学家们就已经开始思考:
机器能不能像人一样思考?
1950 年,英国数学家艾伦·图灵提出了著名的"图灵测试"。
简单来说,就是让一个人同时和机器、真人聊天。
如果这个人分不清哪个是机器,哪个是真人,那么这台机器就可以被认为具有某种智能。
这听起来是不是很像今天我们和 AI 助手聊天?
只不过在当时,计算机还非常笨重,算力也很有限。
人们虽然提出了伟大的想法,但真正实现起来,还需要漫长的等待。

第一阶段:规则时代——让机器照着"说明书"办事
早期的人工智能,主要依靠人类提前写好的规则。
比如:
如果用户问"天气怎么样",机器就去调用天气信息; 如果病人出现某些症状,系统就根据规则判断可能的疾病; 如果棋盘上出现某种局面,程序就按照预设策略走下一步。
这个时期的 AI,就像一个特别听话的员工。
你给它写好规则,它就按规则执行。
规则越详细,它表现越好。
但问题也很明显:
现实世界太复杂了,光靠人写规则根本写不完。
比如你想让机器理解一句话:
"这家餐厅味道真绝了。"
这里的"绝了",是夸奖,还是吐槽?
如果没有语境,机器很难判断。
所以,早期规则型 AI 虽然在特定任务上有用,但很难真正理解复杂的人类语言。
第二阶段:机器学习时代——让机器从数据里自己找规律
后来,科学家们发现:
与其一条条写规则,不如让机器自己从数据中学习。
这就是机器学习。
举个简单例子:
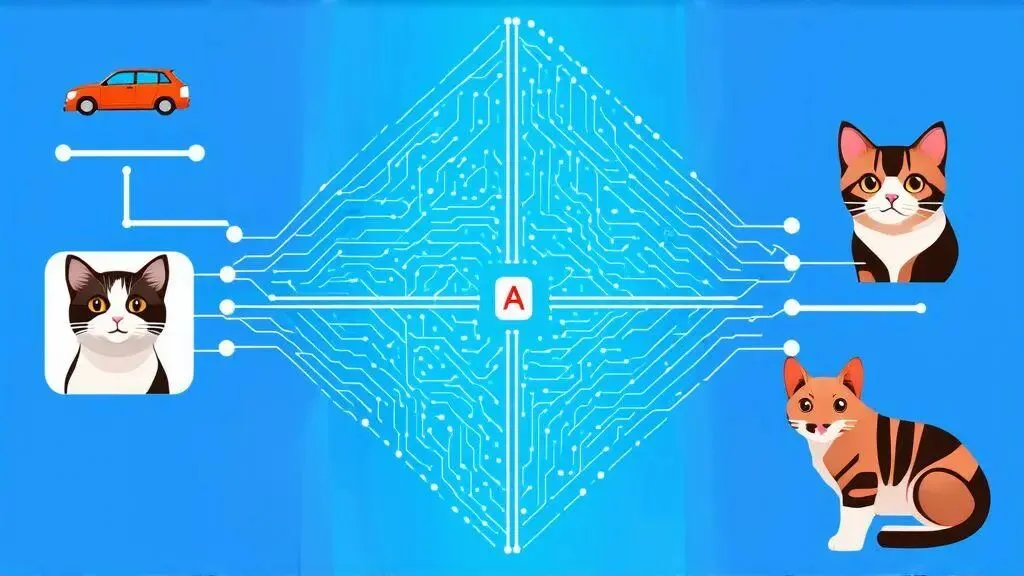
如果我们想让机器识别猫。
以前的做法可能是告诉它:
猫有耳朵; 猫有胡须; 猫有尾巴; 猫的眼睛通常比较圆。
但机器学习的做法是:
给机器看成千上万张猫的照片。
然后再给它看成千上万张不是猫的照片。
经过大量训练后,机器会慢慢学会:
哪些特征更像猫,哪些特征不像猫。
这个变化很关键:AI 从"人告诉它规则",变成了"它自己从数据中总结规律"。
这也是今天大语言模型能够出现的重要基础。
第三阶段:深度学习时代——AI 开始看图、听音、读文字
进入 2010 年之后,人工智能迎来了一个重要转折:深度学习。
深度学习可以理解为更强大的机器学习方法。
它借鉴了人脑神经网络的思想,通过一层又一层的计算结构,去处理复杂信息。
为什么这个阶段很重要?
因为 AI 开始在很多任务上取得突破:
- 图像识别:能识别照片里是什么;
- 语音识别:能把语音转成文字;
- 机器翻译:能把一种语言翻译成另一种语言;
- 推荐系统:能根据你的兴趣推荐内容;
- 自动驾驶:能识别道路、车辆、行人。
今天我们刷短视频、用语音输入、看电商推荐,背后都有深度学习的影子。
不过,这个阶段的 AI 虽然已经很强,但很多系统仍然是"专才型"的。
也就是说,一个 AI 可能很会识别人脸,但不会写文章;
另一个 AI 可能会翻译,但不会画图;
它们大多只能完成特定任务。
第四阶段:大模型时代——AI 从"专才"走向"通才"
让大众真正感受到 AI 冲击的,是近几年的大模型时代。
这里的"大",主要体现在三个方面:
- 数据大
:训练时阅读了海量文本、代码、图片等数据; - 参数大
:模型内部有极其庞大的计算参数; - 算力大
:需要大量高性能芯片和服务器进行训练。
大模型和以前很多 AI 最大的不同在于:
它不再只会做一个固定任务,而是能处理很多任务。
比如一个大语言模型可以:
写文章; 做总结; 翻译; 写代码; 分析表格; 制定计划; 扮演不同角色; 解释复杂概念。
这就像过去的 AI 是"单项冠军",而大语言模型更像是"综合型选手"。
它不一定在每件事上都完美,但它的通用能力明显更强。

大语言模型是怎么一步步发展起来的?
现在我们再把焦点放到"大语言模型"本身。
大语言模型的发展,大致经历了这样几个阶段:
第一阶段:统计语言模型
早期机器处理语言时,主要靠统计。
比如系统会统计:
"我爱" 后面最常出现什么词?
如果大量文本里"我爱你""我爱学习""我爱北京"出现频率很高,系统就会根据概率判断下一个词。
这有点像早期输入法的联想功能。
第二阶段:神经网络语言模型
后来,研究者开始用神经网络处理语言。
机器不再只是统计词频,而是试图理解词和词之间的关系。
比如:
"国王"和"王后"有关; "北京"和"中国"有关; "医生"和"医院"有关。
这让机器对语言的理解更进一步。
第三阶段:Transformer 架构出现
2017 年,人工智能发展史上出现了一个非常重要的技术:Transformer。
它的厉害之处在于,能够更高效地理解一句话中不同词语之间的关系。
比如这句话:
"小明把书借给小红,因为她明天要考试。"
这里的"她"指的是谁?
人类一看就知道是小红。
而 Transformer 的优势,就是更擅长捕捉这种上下文关系。
今天很多主流大语言模型,都和 Transformer 技术有关。
第四阶段:预训练大模型
后来,人们发现:
可以先让模型在海量文本上进行"预训练",让它先学会通用语言能力。
然后再通过进一步训练,让它更会回答问题、遵循指令、与人对话。
这就像一个学生:
先读很多书,打好基础;
再接受专门训练,学会如何考试、如何表达、如何解决问题。
于是,大语言模型的能力开始快速提升。
为什么大语言模型最近几年突然爆发?
你可能会问:
既然人工智能研究了这么久,为什么偏偏最近几年大语言模型突然火了?
主要有三个原因。
第一,数据足够多了
互联网几十年的发展,积累了大量文本、图片、代码、视频等数据。
这些数据就像 AI 的"教材"。
教材越丰富,模型越有机会学到更多知识和表达方式。
第二,算力足够强了
训练大模型需要强大的计算能力。
过去计算机不够快,很多想法只能停留在论文里。
现在 GPU、AI 芯片、云计算快速发展,大规模训练成为可能。
第三,算法更成熟了
Transformer、预训练、指令微调、人类反馈强化学习等方法,让模型不仅能"接话",还能更好地理解人的意图。
所以,大语言模型的爆发不是一夜之间发生的。
它是数据、算力、算法长期积累后的集中爆发。

回头看:人工智能的发展,是一条"越来越会学习"的路
如果用一句话概括人工智能的发展历程,那就是:
AI 从"按规则执行",逐渐走向"从数据中学习",再走向"理解和生成复杂内容"。
我们可以把它简单梳理成一条线:
规则型 AI↓机器学习↓深度学习↓大模型↓大语言模型与多模态 AI
这条路背后,是人类不断把知识、数据和计算能力交给机器,让机器一点点学会处理更复杂的问题。
当然,今天的大语言模型依然不是万能的。
它可能会:
说错事实; 编造不存在的信息; 理解复杂现实问题时出现偏差; 缺少真正的人类经验和情感。
但它已经成为人工智能发展史上的一个重要节点。
结语:理解历史,才能看懂未来
今天我们从人工智能的起点,一路讲到了大语言模型的爆发。
你会发现,今天的 AI 并不是突然出现的奇迹。
它背后有几十年的技术积累,也有无数次失败、低谷和突破。
从规则型 AI,到机器学习;
从深度学习,到大语言模型;
AI 的每一次进步,都在让机器更接近理解人类语言、辅助人类工作的目标。
但更重要的是:
AI 的价值,不在于替代人,而在于放大人的能力。
未来,会使用 AI 的人,可能会拥有更强的学习能力、表达能力、创造能力和解决问题的能力。

今日互动
你第一次听说人工智能,是什么时候?
是科幻电影里的机器人,还是现在手机里的 AI 助手?
欢迎在评论区聊聊你的 AI 初印象。
