 夜雨聆风
夜雨聆风
Ideogram 4 的真正张力不在“能不能画”,而在“能不能按设计约束交付”;但越接近工作流,本地硬件门槛也越无法回避。
摘要:Ideogram 4 是一次值得重视的开权重图像模型发布。它强在文字渲染、结构化提示词和设计控制,但公开权重是非商业许可,本地运行门槛高,Mac 与普通 Windows 电脑目前都不适合被宣传成“开箱即用”。
如果一个图像模型发布后,大家最关心的不是“它画得像不像”,而是“它到底能不能在我电脑上跑”,这件事本身就很说明问题。
2026 年 6 月 3 日,Ideogram 发布了 Ideogram 4。官方给它贴了几个很有分量的标签:第一款开权重模型、从零训练、9.3B 参数、原生 2K、结构化 JSON 提示词、多语言文字渲染、显式 bbox 布局控制、颜色调色板控制。
听起来像一份设计模型的成绩单。很漂亮,也很容易让人手一滑就想下载。
但网络反响很激烈,不完全是因为它强。更准确地说,是因为它同时踩中了三根神经:
图像模型终于又有人把“文字生成”当主菜了;
开权重这件事给了开发者新的想象空间;
可真正下载回家后,许可证、依赖、显存、MPS、WSL2、安全过滤,又把热情拽回了地面。
嗯,落地这件事,总是比发布页诚实一点。
所以今天不写发布会式赞美。我们做一次冷静验货:Ideogram.ai 到底发布了什么?Ideogram 4 值不值得关注?普通 Windows 和 Mac 电脑,能不能把它本地跑起来?
先说判断:这是一个“设计型图像模型”的开权重展示
Ideogram 过去最容易被记住的能力,是把字写进图里。
这件事看似小,其实长期是文生图模型的硬骨头。很多模型可以画出很漂亮的海报、包装、广告场景,但一旦要求它在画面里写准确的单词、排版清楚的标题、可读的标牌,就开始像喝多了墨水。
Ideogram 4 继续押这个方向,但它的野心不只是“会写字”。
官方 README 里最值得看的,不是那些榜单图,而是这几个设计选择:
模型参数:9.3B 架构:单流 DiT,文本 token 和图像 latent token 放进同一个 transformer 序列里处理 文本编码器:Qwen3-VL-8B-Instruct,抽取 13 个中间层 hidden states 提示词格式:训练时使用结构化 JSON caption 控制能力:bbox 坐标、颜色 palette、构图层级、风格描述 分辨率:支持 256 到 2048,长宽为 16 的倍数,宽高比最高到 6:1 推理预设:12 步、20 步、48 步三个档位
说白了,它不是把一句 prompt 当许愿池,而是试图把图像生成变成一张“设计施工图”。
这也是 Ideogram 4 最值得关注的地方:图像模型正在从“看起来好看”,走向“能不能按布局、按文字、按颜色、按商业画面需求交付”。
审美很重要,但设计不是只有审美。设计还有约束。
它强在哪里:文字、布局、结构化控制
官方性能部分给了几组很漂亮的结果。
在 Design Arena 这类偏设计生成的榜单里,Ideogram 4 被官方描述为排名最高的开权重模型,仅落后于 GPT、Gemini 等闭源大厂模型。在 ContraLabs 的盲测里,10 位职业设计师对四个模型做 typography 评估,Ideogram 4 的第一名选择率是 47.9%,高于官方列出的 Nano Banana 2、FLUX.2 [max] 和 Grok Imagine 1.0。
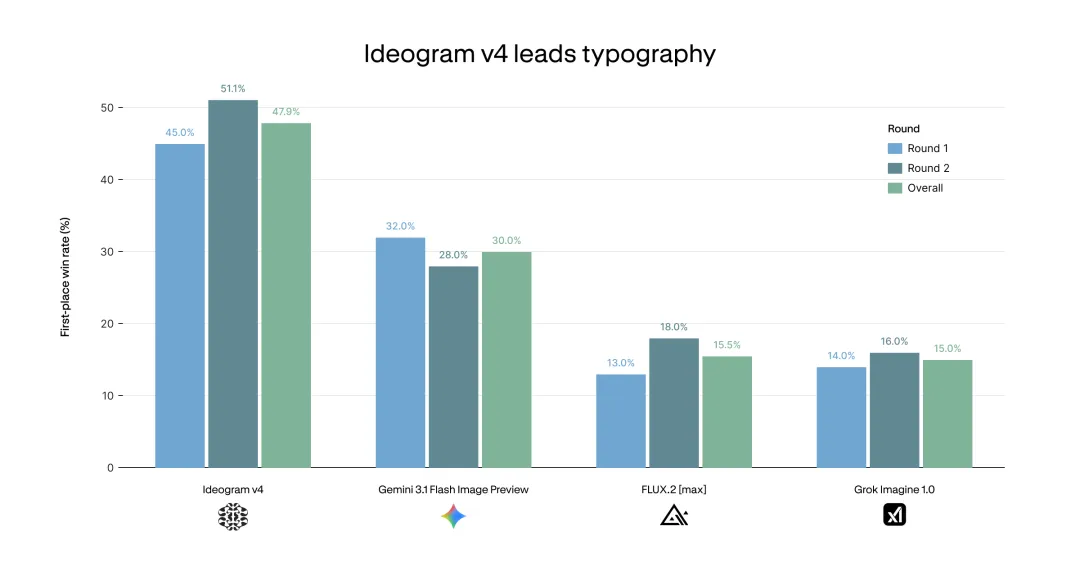
47.9% 这个数字不是“神迹”,但它说明 Ideogram 4 的强项确实压在设计和文字渲染这条线上。
这些数字值得看,但也要留一分清醒。
榜单不是使用体验的全部。尤其图像模型的评测,受提示词、审美偏好、任务类型影响很大。一个模型在海报字效上赢,不等于它在所有摄影、产品图、角色一致性、编辑工作流里都赢。
真正更稳定的信号,是它的技术选择和产品方向一致。
Ideogram 4 用 JSON prompt 训练。普通用户输入一句话时,官方 CLI 默认会调用 magic prompt,把普通 prompt 扩展成结构化 caption。你也可以自己写 JSON,明确主体、背景、文字、颜色、空间位置。
这会带来一个很现实的变化:
以前用文生图,很多人像在跟一个情绪不稳定的画师沟通,“你帮我画一个高级一点的、科技感一点的、不要太花”。结果出来以后只能抽盲盒。
Ideogram 4 更像在说:你把画面元素、层级、位置、颜色和文字讲清楚,我再生成。
这不浪漫,但很有用。甚至有点像把甲方需求表塞进模型嘴里:别自由发挥,照单施工。:)

结构化提示词的意义,是把“抽盲盒式生成”往“带约束的设计执行”推近一步。
开权重,不等于随便商用
这次最容易被误读的词,是 open。
GitHub 仓库本身采用 Apache-2.0 许可证,推理代码是开放的;但模型权重不是 Apache-2.0。官方 model zoo 里写得很清楚:nf4 和 fp8 两个权重版本都是 Ideogram 4 Non-Commercial。
这意味着什么?
个人研究、实验、非生产环境测试,可以玩。
公司内部评估、研发原型,可以看。
但如果你要把它放进客户可访问的产品、商业广告生产链路、收费服务、或者用它生成营收产品的素材,公开权重许可并不覆盖。官方另有商业授权入口。
这不是细枝末节。

开权重不是一个二元开关:代码、权重、生产商用,分别落在不同的许可边界里。
因为很多人一看到“开权重”,脑子里会自动翻译成“我可以拿来做产品”。Ideogram 4 这里不能这么理解。更准确的说法应该是:它给研究者和开发者开放了模型研究与非商业实验入口,但没有把生产商用权限一并放出来。
对创作者来说,还有一个边界:许可文本中写明,Ideogram 不主张你用模型生成输出的权利;但同时要求用户对输出负责,并限制用输出去训练、微调或蒸馏竞争性模型。
这是 2026 年 AI 模型开放里越来越常见的状态:开放不是一个二元词,而是一组条款拼出来的使用边界。
本地能不能跑:先看你是哪种电脑
很多人最关心的是这张表。
下面不是官方硬件表,而是基于公开 README、代码依赖、模型权重体积、GitHub issue 和社区 PR 反馈做出的部署判断。截至 2026 年 6 月 9 日,我不建议把 Ideogram 4 描述成“普通电脑可流畅本地部署”。
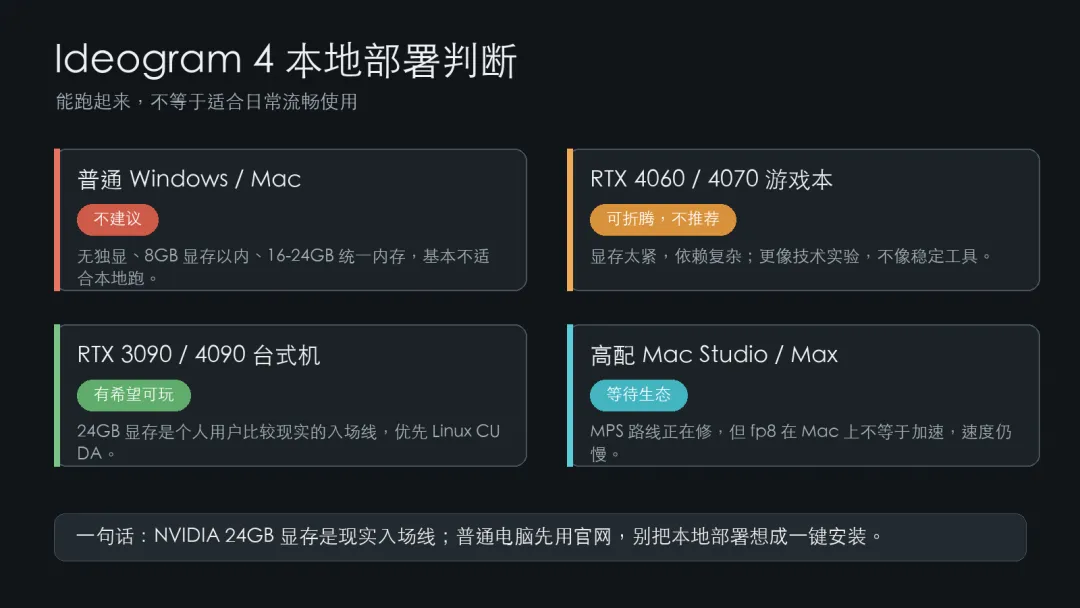
本地部署最容易被误读:能在某些设备上跑起来,不等于能在普通电脑上稳定、流畅、低成本使用。
我整理了一下不同设备的的情况:
一句话版:
普通 Windows 和普通 Mac,不适合。NVIDIA 24GB 显存是个人用户比较现实的入场线;想把它当稳定生产工具,最好是 Linux + 高显存 NVIDIA。Mac 目前更像“等待生态修复”的路线,不是稳妥路线。

本地部署的真实阻力,往往不在“参数表”里,而在 torch、CUDA、bitsandbytes、MPS 这些细碎但致命的组合里。
这也是我最想提醒的地方。
你能看到官方 README 里写 fp8 “All”,代码里也会自动选择 cuda、mps、cpu。但 GitHub issue 里已经有人报告 MPS 失败,PR 里也解释了原因:PyTorch 的 MPS 后端不能直接存储 float8_e4m3fn,所以需要把 FP8 权重解量化到 bf16 执行。这样做能让下载体积小一些,但在 Mac 上并不会获得 FP8 的计算加速。
换句话说,Mac 上的 fp8 更像“磁盘上的压缩包”,不是“GPU 上的加速器”。
这句话对普通用户很关键。
还有几个隐藏门槛
本地部署不是只有显卡。
Ideogram 4 的权重托管在 Hugging Face,而且是 gated。你需要打开模型页面,同意条款,再用 Hugging Face token 登录,代码才能下载权重。
普通 prompt 默认还会走 magic prompt。官方 CLI 默认启用 magic prompt,它会调用 Ideogram 的托管服务,把自然语言 prompt 扩写成结构化 JSON caption。没有 IDEOGRAM_API_KEY 或 MAGIC_PROMPT_API_KEY,默认路径会直接报错。当然你可以关掉 magic prompt,自己写 JSON。
安全筛查也不是完全本地。官方示例里提示使用 Hive 的文本和视觉审核 key;没有配置时,CLI 会警告安全筛查被禁用。
这三件事叠在一起,就能看出 Ideogram 4 当前的定位:
它可以本地推理,但不是完全离线的一键工具。
它可以非商业研究,但不是随手拿来商用的素材工厂。
它可以接进开发者工作流,但不是给普通创作者准备的安装包。
为什么社区反应这么尖锐
GitHub issue 区很有现场感。
有人问 ComfyUI 支持,有人追 CUDA 安装说明,有人报告 WSL2 崩溃,有人吐槽 MPS 失败,也有人直接把矛头指向安全过滤:普通 prompt 会触发误杀,生成含文字的图片也可能被挡掉。
最刺耳的一类反馈,是对“安全过滤”的不满。
有 issue 提到,“a 1950s oil painting of a deckchair in the sun” 这类看起来很无害的 prompt 也会被拦截。评论区里有人说,如果正常提示词也会随机被挡,这个模型进入规模化生产链路就很困难。
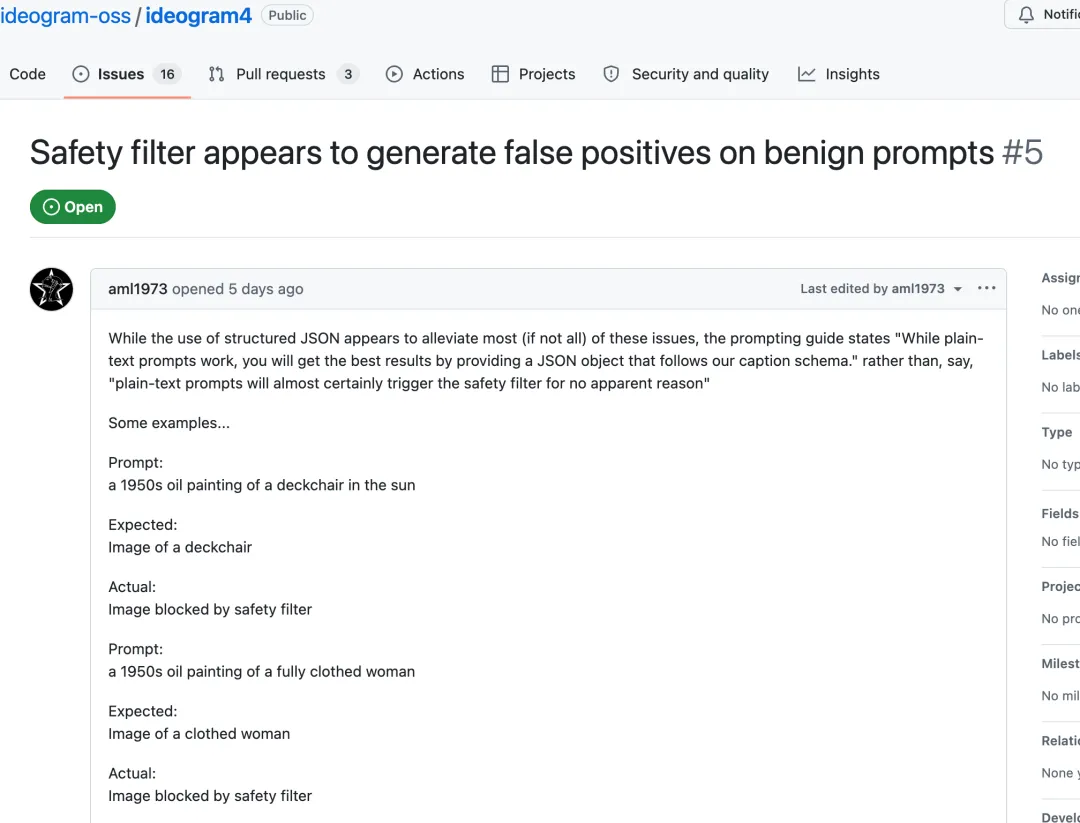
争议不是“要不要安全过滤”,而是当正常 prompt 也被拦下时,创作链路会不会被频繁打断。
这些评论当然带情绪,但问题本身不是无理取闹。
图像模型的安全过滤要做,这是基本责任;但如果过滤标准不透明、误杀率高、用户不知道该怎么改 prompt,创作体验会被直接打断。尤其 Ideogram 4 又把文字和设计作为主能力,安全过滤一旦和文字生成冲突,影响会更明显。
这里需要中立一点看。
Ideogram 作为公司,不可能把一个强文字渲染模型完全裸奔放出来。文字生成能力越强,越容易触碰品牌仿冒、政治宣传、诈骗素材、侵权商标、色情暴力等风险。它加安全过滤是合理的。
但开发者的不满也成立:如果一个开权重模型的本地体验仍被外部 key、魔法扩写和过滤链路强烈影响,那么“本地可控”的想象就会打折。
这不是谁坏的问题,是开放模型商业化时代的典型张力:公司要控制风险,社区要控制工具。
两边都不是空气。这个地方,别急着站队,先把张力看清楚。
Ideogram.ai 真正想做的,不只是模型
如果只看 GitHub,很容易把 Ideogram 4 理解成一个开源模型项目。
但 Ideogram.ai 的真正业务形态,仍然是在线图像生成产品和 API 服务。官网让普通用户直接在线试用;开发者文档提供 API;商业授权页面则面向需要本地部署、私有化、商业使用或版权责任边界更清楚的团队。
这就解释了为什么它会开放权重,又不完全放开商业使用。
对 Ideogram 来说,开权重有几个好处:
它能让研究社区验证模型;
它能让 ComfyUI、Diffusers、工作流开发者开始适配;
它能把“设计型图像模型”这个标签钉进开发者心里;
同时,真正高频、稳定、商用的需求,仍然可以回到云端产品、API 或商业授权。
这不是矛盾,反而是一种越来越成熟的模型公司打法。
开权重负责建立技术信誉和生态入口,商业授权负责承接生产需求。
你可以不喜欢这种边界,但要看懂它。
跟 Flux、Qwen-Image、HunyuanImage 放在一起看
Ideogram 4 的有意思之处,在于它没有选择和最大模型硬拼参数。
官方对比里提到,Ideogram 4 只有 9.3B 参数,却在文字渲染方向领先很多更大的开权重模型,比如 Qwen-Image 20B、FLUX.2 [dev] 32B、HunyuanImage 3.0 80B MoE。
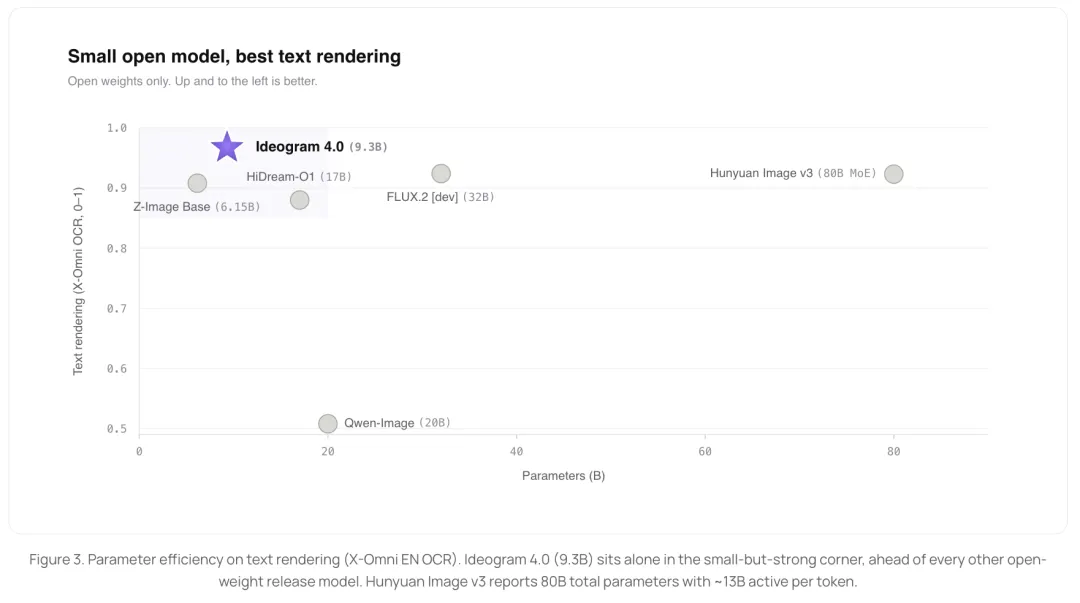
这张图真正值得看的,是参数规模和文字渲染能力之间的错位:更大不必然等于更会按文字约束交付。
这类对比要谨慎,因为“领先”取决于评测任务。但方向值得注意:
图像模型正在分化。
有的模型追求摄影真实感;
有的模型追求角色一致性;
有的模型追求编辑能力;
有的模型追求高分辨率商业图;
Ideogram 4 下注的是设计场景里最硬的一块:文字和布局。
这条路线很聪明。
因为在真实商业设计里,最让 AI 露馅的往往不是“画得不美”,而是“字错了、位置乱了、品牌色跑了、海报比例不对”。这些问题看起来细,实际决定能不能从玩具进入工作流。
模型行业的下一步,可能不是谁更会画梦境,而是谁更能遵守约束。
给普通用户的建议
如果你只是想试试 Ideogram 4 的效果,最省心的方法仍然是官网。
如果你是创作者,想做海报、封面、带文字的设计稿,优先在线试,不要一上来折腾本地权重。你真正需要评估的是:它对中文、英文、混排、多行文字、品牌色、构图指令的稳定性。
如果你是开发者,有 NVIDIA 24GB 显存以上设备,可以尝试 nf4。建议优先 Linux CUDA 环境,先跑 1024、12 步或 20 步,再评估 48 步高质量模式。不要一开始就 2K + 48 步 + 批量生成,那很容易把机器折腾到怀疑人生。
如果你是 Mac 用户,尤其是 16GB、24GB 统一内存,不建议现在花太多时间。等官方或社区把 MPS 路径合并、文档稳定、ComfyUI 工作流成熟之后再看。高配 Max 或 Studio 用户可以当技术实验,但不要期待“像云端一样快”。先喝口水,别让笔记本替你燃烧斗志。
如果你是公司,想把它用于商业设计生产,第一步不是部署,而是看许可证。公开权重的非商业条款不覆盖生产使用,应该联系官方商业授权。
它真正打开的问题
Ideogram 4 不是一个完美发布。
它的本地部署门槛高,许可证边界复杂,Mac 支持还不稳,Windows 依赖也有坑,安全过滤正在招来不小的反弹。
但它仍然值得被认真看。
因为它把图像生成的一条关键路线推到了台前:不是更会幻想,而是更会执行设计约束。
过去我们评价图像模型,经常问一句:“它画得真实吗?”
接下来可能要多问几句:
它能不能把字写对?
它能不能按位置放元素?
它能不能理解配色?
它能不能把一张随口说出的图,变成一张能交付的设计稿?
这才是 Ideogram 4 的真正信号。
不是普通电脑终于能白嫖一个顶级设计模型了。
而是图像模型的竞争,正在从“谁更会画”进入“谁更听得懂设计任务”的阶段。
湍流不是混乱,而是被理解的复杂性。放在 Ideogram 4 身上,这句话刚好有点贴切:当生成模型开始理解文字、版式、颜色和约束,图像不再只是被生成出来,它开始被组织出来。
这一步,还不够平民。
但方向已经很清楚。
它不是一个“装上就起飞”的故事。
它更像一枚坐标钉:告诉我们,下一轮图像模型的竞争,会越来越接近真实设计工作的硬约束。
这就够值得盯一眼了。
—— Lyra Celeste @ 湍流 τ
当 AI 学会"不偷懒":agent-skills 如何把 Google 工程纪律塞进 Markdown 文件
被拔掉刹车的 284B 模型:DeepSeek-V4-Flash-JANG-CRACK 不是炫技,而是一次安全警钟
MemPalace 日增 870+ 星 — Agent「长期记忆」赛道,终于等来了自己的 GitHub 时刻
