 夜雨聆风
夜雨聆风这两年开源模型从 Llama 到 Qwen,再到 Gemma,能力一点点逼近闭源模型。
于是不少人开始动心思,想要在自己电脑上本地部署模型,试图解决高昂的 Token 费用。
但在 HuggingFace 上有上百多万个开源模型,参数量从 1B 到 100B,该如何选择。
对于大部分人来说,光搞清楚自己的电脑能跑哪些模型,可能就得折腾大半天。
更惨的是,当我们把模型权重下载到本地并部署了,才发现输出一句话得等半分钟。
根本无法使用,然后再卸载删除,重新找模型,重新下载部署,可以说试错成本极高。
最近找到一个开源的命令行工具 whichllm,能帮我们解决本地部署,模型选择这个痛点。

它能根据电脑的硬件配置,给我们推荐哪个模型能跑起来又快又好。
与其他检测工具有所区别,它不止关注模型能不能跑,还会判断跑哪个模型更划算,把性能拉满。
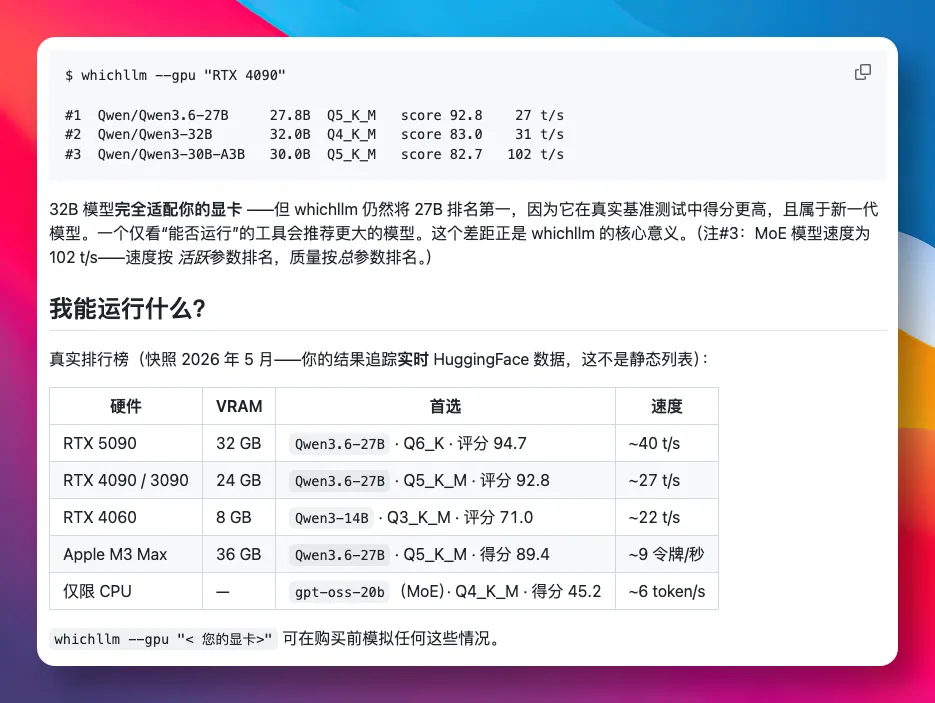
简单举个例子。一张 24GB 显存的 RTX 4090,理论上能跑得下 32B 的模型。
但它会将 27B 模型排在第一推荐位置,理由各项基准测试评分更高,而且是最新模型。
也就是说,它不止告诉我们哪些模型能跑,还会考虑到哪些模型体验更好、性价比更高。
下面再来看下如何使用。
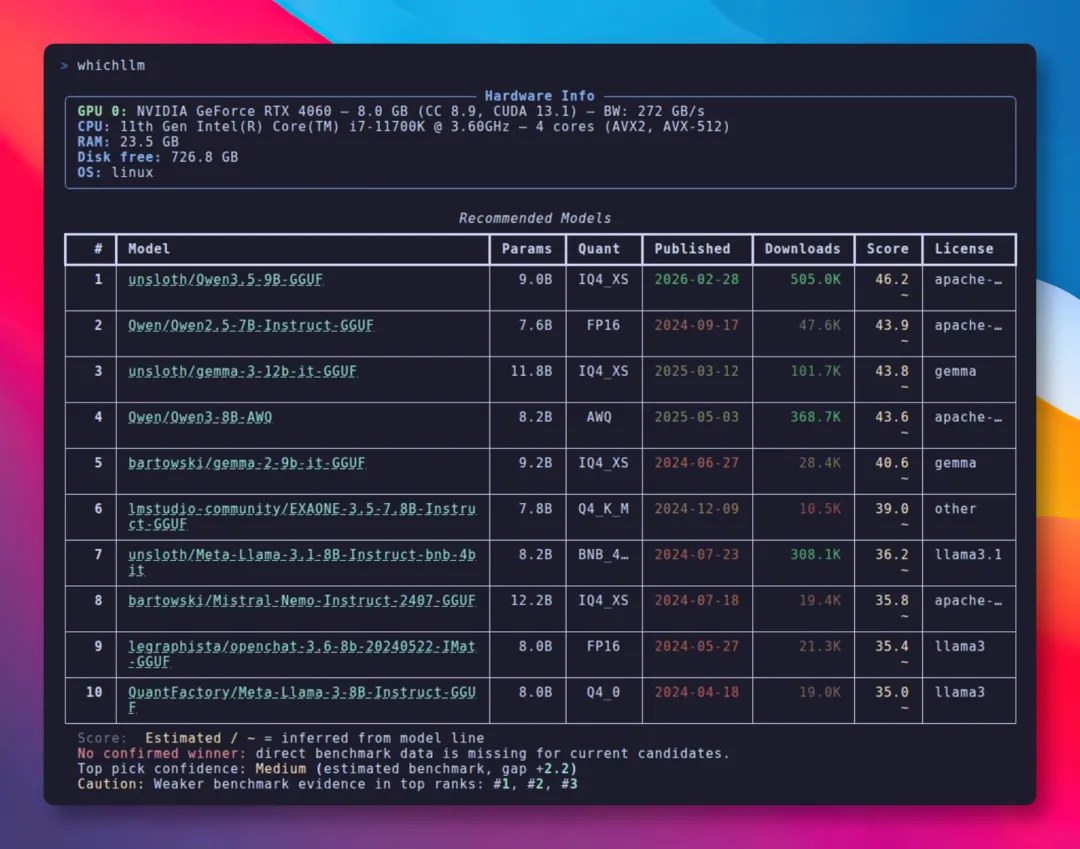
安装之后,只需打开终端,输入whichllm命令行,它就会自动检测我们硬件配置。
市面上主流的 N 卡、A 卡、Apple 芯片,甚至纯 CPU 的机器,都能识别出来。
接着就会基于我们的配置信息,计算清楚每个模型大概能跑多少 tok/s。
表格里会显示出模型名称、参数量、量化方式、综合评分还有下载量,所有信息一目了然。
另外,工具还有几个实用的命令,也值得说一说。
想要直接上手体验,只需一条命令 whichllm run 就能下载、部署模型并开启对话。
如果在纠结购买哪张显卡,可以先跑一下 whichllm --gpu "RTX 4090",模拟看看可以跑哪些模型。
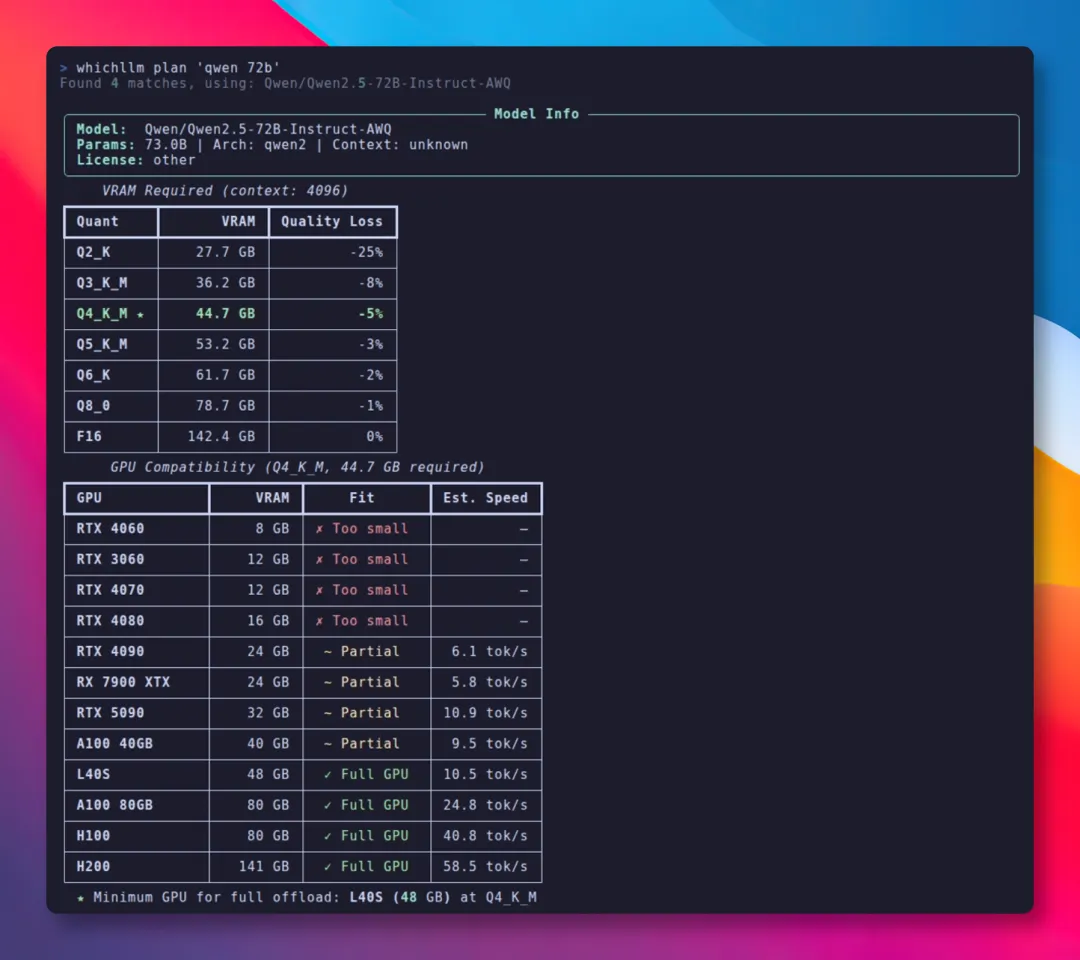
反过来,想知道某个模型需要什么级别的显卡才能跑,则可以用whichllm plan 这条命令。
至于如果安装使用 whichllm,只需一行 pip 命令就能搞定。
pip install whichllm装好之后敲 whichllm 命令即可开始,它会自动检测硬件并给出推荐列表。
不过也有几个缺点,也跟大家客观说一下。
它的速度计算是基于显存带宽和参数量推算的,可能会跟实测有些出入。
对于 Windows 上的 A 卡检测,精度也不如 Linux,需要靠系统接口去补全信息。
另外就是在 Apple 芯片和纯 CPU 环境下,为了稳定,它只推荐 GGUF 格式。
写在最后
关于本地跑模型这件事,后面肯定有越来越多的人会去尝试。
那么前提比较关键的是,不要只顾着「能跑多大模型」,而是要选择好模型。
whichllm 的出现,便帮我们把试错的成本降下来了,剩下的精力花在真正有意思的事情上。
GitHub 项目地址:https://github.com/Andyyyy64/whichllm
今天的分享到此结束,感谢大家抽空阅读,我们下期再见,Respect!
