 夜雨聆风
夜雨聆风你有没有遇到过这种情况:
让AI帮你写一个项目的代码,写到一半,它突然"失忆"了。你重新开一条对话,它像从来没见过这个项目一样,问你"你想做什么?"。或者你明明已经做过的功能,他又重新开始做了。
我上周就经历了这个循环,而且不是一次,是每天一次。
但让我真正崩溃的不是AI忘事,而是我发现——我一直在用错误的方式跟AI协作。
一、问题不是AI不够强,是我的协作方式设计错了
我在做一个选品分析的项目,让AI Agent每天自动采集数据、分析趋势、生成报告。
项目不难,但协作过程极其痛苦:
• 每次新开对话,Agent像失忆一样,之前写的代码逻辑全忘了 • 代码写到一半行为跑偏,频繁找我确认"接下来要做什么" • 需求明明聊过,做着做着就变形了 • 一个分析脚本我讲了3遍,换条对话又要从头讲
我的第一反应跟很多人一样:AI的上下文不够长,记忆力不行。
但当我冷静下来复盘,发现问题根本不在AI的记忆力——在于我把所有状态都存在了AI的脑子里,而不是存在文件里。
LLM没有持久记忆。你关了一条对话,上一个会话的上下文就丢了。即使同一个平台、同一个账号,新开会话也是一张白纸。
这就像你跟一个同事合作,每次见面都换一个人,你不得不在每次见面时把项目背景从头到尾讲一遍。
不是同事不行,是你的交接方式错了。
二、我的解法:用4个文档做"状态持久化"
我把项目状态从AI的上下文里抽出来,落地到4个Markdown文件里:
SPEC.md | ||
AGENTS.md | ||
process.md | ||
tech.md |
本质上,我是用文档做了AI的"外接硬盘"——因为内存不靠谱,所以我把状态写进文件系统。
这跟程序员把数据从内存落盘是一个道理,只不过我落的是Markdown。
三、这四个文件长什么样?
我不需要给你看完整代码,只给你看关键部位——这些是让AI从"失忆"变成"自动驾驶"的核心设计。
1. SPEC.md:先定边界,再动手
SPEC 不是PRD,它只做两件事:定义需求,明确不做的事。
## 核心痛点当前最主要的问题不是缺少单个商品信息,而是不知道每天应该重点看哪些品类。## 明确不做的事- 不登录任何 TikTok 或精选联盟账号- 不使用付费数据源- 不做自动最终选品决策- 不自动联系达人- 不自动创建商品库为什么这个很重要?
因为AI特别擅长"自作主张"。你不告诉它什么不做,它就会替你决定——然后做出你根本不想让它做的事。SPEC 的"明确不做"比"要做什么"更重要,它是给AI画的牢笼。
2. AGENTS.md:定义协作界面
AGENTS.md 是这个系统的灵魂。它回答一个问题:Agent应该怎么跟我配合?
核心设计有三块:
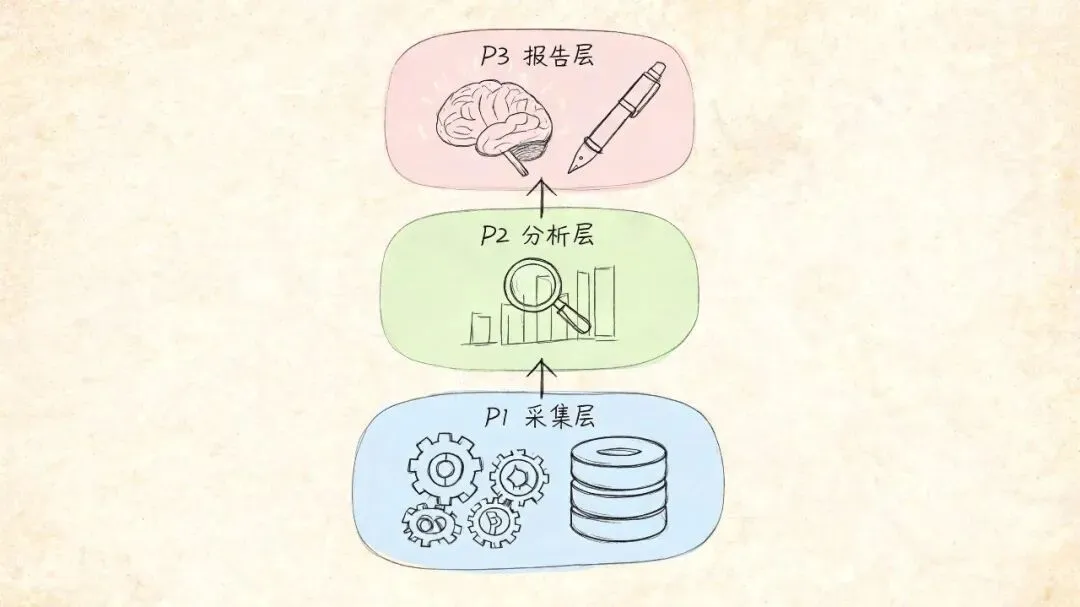
第一,三层架构——让AI知道谁该干什么
| 层次 | 负责方 | 做什么 | 不做什么 ||------|--------|--------|---------|| P1 采集层 | 脚本 | 每天自动采集数据源,落盘 SQLite | 不做报告 || P2 分析层 | 脚本 | 计算飙升/去重/推荐/冲突,输出 JSON | 不写文案 || P3 报告层 | 大模型 | 读取 JSON + 原始数据,翻译、组织、写作 | 不重新计算 |为什么 P3 让大模型做?- 大模型天生会多语言翻译,不需要写 translate.py- 大模型能按实际数据灵活组织报告,不用写死模板- 数据源缺失时大模型能自动降级第二,上下文恢复原则——让新会话立刻上手
## 上下文恢复原则本项目可能从新的 Agent 会话继续执行。不要依赖历史聊天上下文。开始任何工作前,必须先阅读:1. SKILL.md:Skill 入口说明(第一优先级)2. docs/SPEC.md:需求与范围3. docs/tech.md:技术边界、接口限制4. docs/plan.md:实施计划5. docs/process.md:进度与交接记录文档冲突时,优先级为:1. SKILL.md → 2. SPEC.md → 3. tech.md → ...第三,新会话启动清单——AI的"开机自检"
## 新会话启动清单新 Agent 会话开始时:1. 阅读 SKILL.md(第一优先级)2. 阅读 SPEC.md3. 阅读 plan.md4. 阅读 process.md5. 阅读 tech.md6. 检查当前代码和文件状态7. 找到下一个未完成任务8. 从文档记录继续,不要从头重做这个启动清单有多重要?
以前AI开新会话,会问我"你想做什么?"。现在它会自动读取这4个文件,然后告诉我:"根据 process.md,你目前在 P3 报告层,下一步是写 render_report.py,要继续吗?"
从"我要教它"变成了"它自己知道"。
3. process.md:项目进度控制
process.md 按时间倒序记录,每条包含:时间、模块、完成内容、修改文件、执行命令、QA结果、已知问题、下一步。
## 2026-06-08 22:00 — 架构调整:统一输出 MD + P3 改为大模型执行### 背景用户提出三个问题:1. SKILL.md 约定 HTML,但脚本实际输出 MD2. AGENTS.md 没有体现「这是一个 Skill 项目」3. 商品/类目无中译 — 想用大模型翻译### 核心决策方案:脚本做数据,大模型做报告。- P1 + P2 仍由脚本自动执行- P3 改由大模型执行:读取 JSON 摘要 + 原始数据,自动翻译、写作### 完成- SKILL.md 改写:输出格式从 HTML 改回 Markdown- AGENTS.md 改写:新增「三层架构」章节- render_report.py 改写:移除 Jinja2,改为 JSON 输出### QA / 证据- render_report.py 语法检查通过- SKILL.md/AGENTS.md 一致性检查通过为什么process.md比聊天记要靠谱?
因为聊天记录会丢、会被压缩、会截断。但文件在磁盘上,只要你不删,它就一直在。而且按时间倒序的设计让AI每次读的时候,最先看到的就是最新进度。
4. tech.md:把坑位标记在地图上
tech.md 记录所有技术边界——接口限制、付费墙、区域降级、字段缺失。
## Fastmoss 不覆盖xx市场 ⚠️ 重大发现:region=NL 在三个接口上都返回 total=0,而 region=ES/GB/DE/FR 都正常返回 5000 条。不是 captcha,不是写法错误,是 Fastmoss 当前不覆盖xx市场的真实业务边界。证据: region=ES → code=200 total=5000 region=NL → code=200 total=0 region=GB → code=200 total=5000影响:- NL 报告只能用 Echotik + Trends + Amazon 三源- NL 报告要明确标注"Fastmoss 不覆盖"处理建议:- collect_fastmoss.py 在 market=NL 时直接跳过- 后续 Kalodata / Choicetok 探测优先验证 NL 覆盖tech.md 的作用是什么?
它把"踩过的坑"变成"地图上的标记"。AI下次走到这里,不用重新踩一遍,直接看地图就知道:这里有个坑,绕开。
四、重构前后的对比
最核心的变化:我从"指挥AI做事"变成了"设计AI的工作环境"。
五、一个副产品:架构也升级了
在设计这4个文档的过程中,我顺手解决了一个更深层的问题——翻译到底该谁来做?
最初我想写 translate.py,用脚本调用大模型API翻译商品名,然后缓存到SQLite。但写方案的时候我突然意识到:
既然P3报告层本来就是大模型在执行,为什么不让它直接在生成报告的时候翻译?
于是我把架构调整为:"脚本做数据,大模型做报告"。
• P1 采集层:脚本自动跑,落盘 SQLite • P2 分析层:脚本本地计算,输出 JSON • P3 报告层:大模型读取 JSON,自动翻译、组织、写作
不需要 translate.py
脚本干脏活累活,大模型干它最擅长的——理解、翻译、写作。
六、这套方法的可复制性
你可能想问:这是不是你这个项目特殊,换个项目就不灵了?
我觉得恰恰相反。这4个文档的本质是"协作界面设计",跟项目内容无关:
无论你是让AI写代码、做分析、还是生成内容,只要你们需要跨会话协作,这4个文档就有价值。
因为LLM的记忆力是靠不住的,但文件系统是可靠的。
七、最后说一个反直觉的洞察
很多人以为用AI做项目,核心是" prompt 写得好"或者"模型够强"。
但我这两天的体验告诉我:
跟AI协作的核心竞争力,不是你怎么跟它说话,而是你怎么设计它的工作环境。
prompt 是临时的,context 是会丢的,但文档是持久的。
你把协作规则写进文件,AI每次启动都能读到。你把进度写进文件,AI永远不会问"我们现在到哪了"。你把坑位写进文件,AI不会重复犯错。
这不是在驯服AI,这是在给AI建一个"它自己能读懂的办公室"。
我是做AI产品出海的Peter,一个更关注需求价值,而非AI技术的产品人。
