 夜雨聆风
夜雨聆风
6月初,Anthropic 发了一篇长文,题目叫《When AI builds itself》。这家公司没有宣布停下模型训练,也没有说自己已经看见了失控的未来。它提出的是一个更现实、也更难的问题:如果某一天,最前沿的模型开始明显加快下一代模型的开发速度,行业有没有一种办法,可以让主要玩家一起慢下来,甚至短暂停一下?
这就是最近技术圈讨论的“刹车机制”。
它听起来像一个很大的公共议题,离普通人很远。但这次的争论之所以值得写,不是因为“暂停”两个字本身,而是因为 Anthropic 给出的理由已经从抽象担忧,转向了一批可观察的工作变化:代码由模型大量生成,实验由模型反复执行,研究人员的角色从亲手完成,越来越多地变成提出目标、判断结果、审核风险。
换句话说,AI 公司内部正在先一步经历未来办公的变化。只是这个变化发生在最敏感的地方:AI 正在帮人开发更强的 AI。
先说清楚:Anthropic 没有喊“立刻停”
很多新闻标题会把这件事简化为“Anthropic 呼吁暂停 AI 发展”。这个说法不算错,但容易让人误解。
Anthropic 原文的表达更谨慎。它说,如果能有效放慢这项技术的发展,让社会结构和安全研究有时间跟上,这“可能是一件好事”。但它也承认,如果只有一家企业单方面放慢,反而可能让不那么谨慎的竞争者追上来,甚至让整个行业更不安全。
所以它主张的不是一家公司自己拉闸,而是建立一种“可协调、可验证”的暂停选项。关键有四点:
第一,多个处在技术前沿、资源充足的实验室要在同样条件下行动。
第二,各方要能确认别人确实停了或慢了下来。
第三,要提前说清楚什么情况会触发暂停,什么情况可以解除暂停。
第四,要有人或某种机制来裁定这些条件是否满足。
这件事难就难在“验证”。导弹发射井、核设施、重型工厂,至少有比较明显的物理痕迹;大型模型训练则更像一项可以藏在数据中心、算力租赁和内部系统里的活动。Anthropic 也直接承认,AI 训练比很多传统军控对象更难被发现,更别说被严格验证。
这也是它的论点里最有现实感的一处:如果“刹车机制”存在,它必须让守规则的人知道别人也在守规则;否则暂停只会变成奖励偷偷前进的人。

为什么偏偏现在讨论刹车
过去几年,AI 安全讨论并不少。可这次 Anthropic 把重点放在一个更具体的变化上:AI 正在进入 AI 开发流程本身。
原文把这叫作 recursive self-improvement,直译是“递归自我改进”。这个词听起来很硬,可以换成更朴素的说法:一个系统不仅能回答问题,还能帮助设计、测试、改进自己的下一代。
Anthropic 明确说,今天还没有到“模型完全自主设计后继模型”的阶段,这也不是必然会发生的未来。但它认为,一些趋势已经足够让人提前准备。
这些趋势里,最直观的是软件任务时间变长。
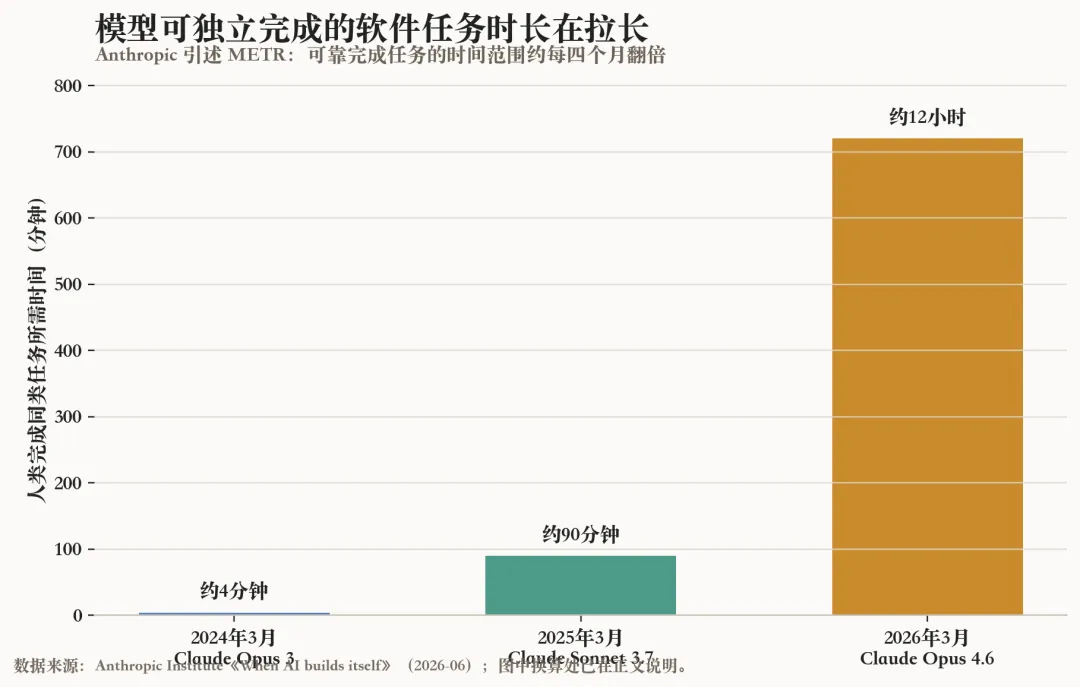
Anthropic 引述 METR 的测试称,模型能够可靠完成的任务时长大约每四个月翻一倍。2024年3月,Claude Opus 3 能完成的,是人类大约4分钟能做完的软件任务;一年后,Claude Sonnet 3.7 能处理大约90分钟级别的任务;再过一年,Claude Opus 4.6 已经能处理约12小时级别的任务。
这不是说模型已经能独立完成所有复杂项目,也不是说它真的“工作了12小时”。更准确的理解是:人类可以给它一个更长、更不碎片化的任务,然后让它自己在一定范围内规划步骤、跑代码、查问题、做修改。
对软件团队来说,这个变化很要紧。因为工程研发中有大量工作并不是天才灵感,而是拆任务、查日志、改代码、跑测试、看报错、再改一轮。以前这些环节消耗的是人的连续注意力,现在越来越多可以交给工具。
一旦这种能力进入开发 AI 的团队,速度提升就不只是“写业务代码更快”。它可能影响模型训练平台、实验工具、评测脚本、数据处理、内部安全检查,最后又反过来影响下一代模型的迭代速度。
Anthropic 内部数据说明了什么
Anthropic 在文中披露了一组内部数据,这也是这篇文章被广泛讨论的原因。
截至2026年5月,Anthropic 表示,公司代码库中合入的代码,超过80%由 Claude 编写。Claude Code 在2025年2月研究预览版推出前,这个比例还只是个位数低段。到2026年第二季度,典型工程师每天合入的代码量约为2024年的8倍。
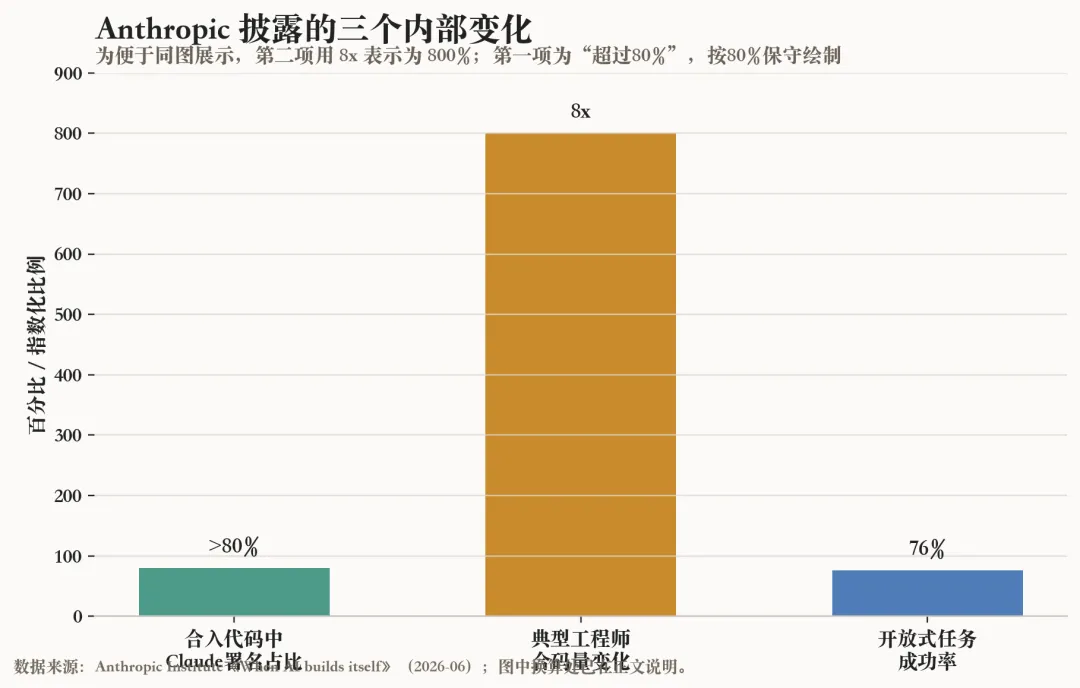
这几个数字很醒目,但也要小心理解。
Anthropic 自己提醒,代码行数不是衡量真实生产力的完美指标。代码多不等于价值高,能合入也不等于长期维护成本低。它把“8倍”称为加速信号,而不是直接等同于工程师效率提升8倍。
这点很重要。AI 写代码的速度再快,系统设计、方向选择、上线判断、事故复盘、团队协作,仍然不是简单的行数问题。一个功能被做出来,不代表它该不该做;一个修复能通过测试,也不代表它不会埋下新的复杂性。
但即便打折,这组数据仍然值得重视。因为它说明最前沿团队的工作重心已经发生迁移:人不是不工作了,而是越来越少承担“从零打字实现”的部分,更多承担目标设定、过程监督和结果审核。
这种迁移会带来一个新瓶颈。Anthropic 在原文里说得很直接:当 Claude 生成代码的速度超过人类审核代码的速度,人工审核就会成为新的限制因素。
这句话放到整个行业里看,含义更大。未来真正稀缺的可能不是“能不能产出”,而是“谁来判断这些产出是否可靠、是否值得、是否应该被部署”。

最容易被忽略的是实验能力
很多人谈 AI 写代码,容易只想到程序员岗位。但 Anthropic 更担心的,其实是研究流程中的自动化。
它举了一个固定实验:给 Claude 一段训练小模型的代码,要求在正确性检查不变的前提下,让这段代码跑得更快。这个任务有明确目标,也能反复测量结果,很适合模型自己尝试、运行、计时、再调整。
2025年5月,Claude Opus 4 在这个实验里平均能把起始代码加速约3倍。到2026年4月,Claude Mythos Preview 达到约52倍。作为对照,熟练的人类研究员需要4到8小时,通常能做到约4倍。
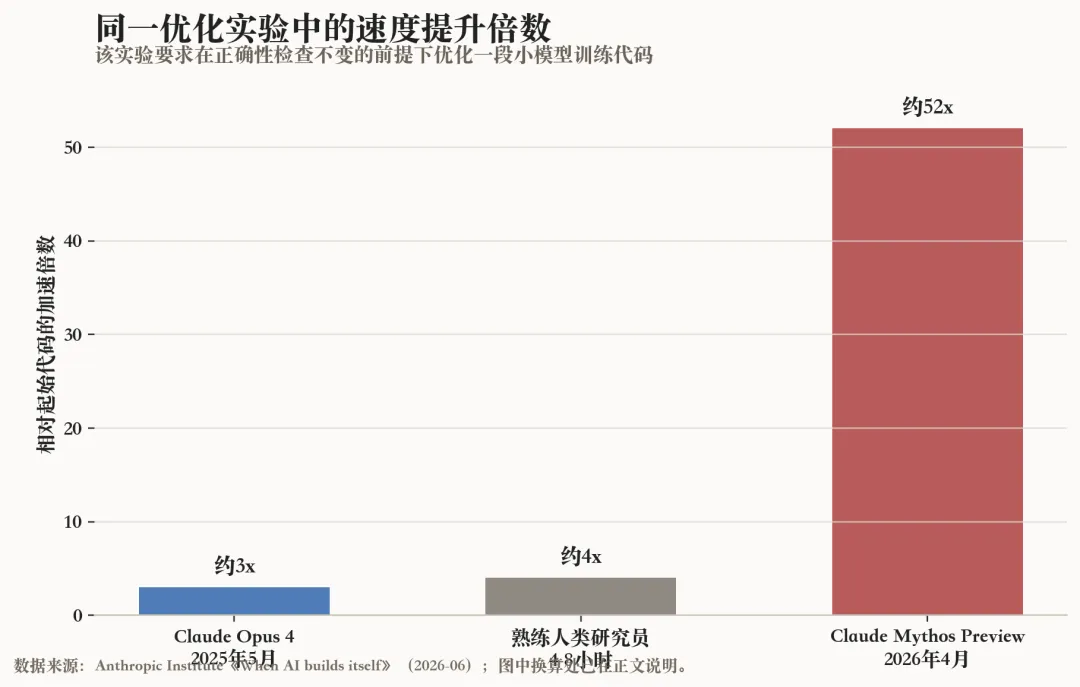
这里也不能把52倍理解成所有训练都能便宜52倍。Anthropic 在脚注里说明,绝对倍数受起始代码可优化空间影响很大,不应当直接外推到真实大模型训练。但这个实验仍然说明一件事:在目标清晰、反馈清晰的任务里,模型已经非常擅长重复试错。
研发的很多进步,并不来自一次惊天动地的新想法,而来自大量小改进:换一种实现,调一个参数,修一个性能瓶颈,多跑几组对照。以前这些工作受限于人的时间、耐心和精力,现在开始受限于算力、工具链和审核能力。
这就是“自我加速”的现实版本。它不是电影里的机器觉醒,而是一个更平淡、也更难察觉的过程:做实验的成本下降,试错的数量上升,迭代周期缩短,下一代工具又让下一轮迭代更快。
争议:刹车机制会不会变成护城河
Anthropic 的提议一出来,质疑声也很快出现。
最常见的质疑是:领先者呼吁暂停,会不会是在固化自己的领先位置?如果一家已经跑在前面的公司要求行业建立更高门槛、更复杂的审核机制,落后者和开源社区自然会怀疑,这到底是公共安全,还是竞争策略。
这个质疑不能简单打掉。技术治理从来不只是一套漂亮原则,也会影响谁能继续投入、谁承担合规成本、谁有资格参与规则制定。越复杂的制度,越可能让资源充足的大公司更能适应,让小团队更难进入。
但反过来说,把所有安全讨论都解释成“护城河”,也会错过真正的问题。模型能力增强后,网络攻击、自动化漏洞发现、虚假内容生成、关键基础设施风险,确实需要更强的外部评估和跨机构协作。AP 报道中也提到,多位安全研究者认为,随着 AI 工具强化漏洞发现和攻击能力,企业、政府和学界之间需要更多合作来建立对策。
所以问题不是“要不要规则”,而是规则由谁制定、如何公开、怎样接受监督,以及会不会把竞争变成少数公司的闭门游戏。
OpenAI 在6月3日发布的公共政策议程里表达了另一种重点:民主政府应在制定规则、保障措施和问责机制上扮演核心角色。AP 对这场争论的报道也提到,OpenAI 的立场是,最终规则不应由私人公司单独决定。
这其实点出了“刹车机制”的核心矛盾:企业最懂技术细节,但企业也有自己的商业利益;政府有公共授权,但未必能跟上技术速度;学界和民间组织能提供外部视角,却往往缺少直接数据和算力条件。
真正可行的机制,恐怕只能是几方共同参与,而不是把方向盘完全交给其中任何一方。
对普通读者来说,这件事意味着什么
很多人看到“暂停前沿 AI 开发”,第一反应可能是:这和我有什么关系?我只是用工具写文案、查资料、做表格,又不训练大模型。
但这场讨论其实关系到未来几年 AI 产品的节奏。
如果行业继续高速推进,普通用户会更快看到能处理长任务的工具:它可以接手更完整的工作流,从写代码、整理资料,到做运营分析、生成报告、协助客服、自动测试产品。好处是效率提高,成本下降,很多小团队能做过去大团队才能做的事。
风险也会随之转移。过去一个人写错一段代码,影响范围可能有限;未来一个高度自动化的系统批量生成、批量执行、批量发布,错误也可能批量扩散。过去一个人制造虚假内容,规模有限;未来自动化工具可以让影响操作变得更便宜。过去安全团队需要花时间发现漏洞,现在发现漏洞可能更快,真正难的是修补速度能不能跟上。
Anthropic 在原文里提到一个例子:Project Glasswing 在最初几周内,Mythos Preview 发现了超过一万个高危和严重级别的软件漏洞。这类能力当然可以用于防御,但也说明瓶颈正在从“找不到问题”转向“修不完问题”。
这就是为什么“刹车”不只是实验室内部问题。它背后讨论的是社会跟不跟得上:法律、审计、企业安全、教育、就业、内容平台、政府采购,所有这些慢系统,要面对越来越快的技术系统。
中国读者可以怎么看
从国内视角看,这个话题还多了一层现实感。
中国的大模型公司也在从“模型参数和榜单”转向应用落地:办公、编程、视频生成、智能体、机器人、行业解决方案。企业用户真正关心的不是技术名词,而是能不能少加班、少出错、少重复劳动,能不能让一个小团队处理更多客户、更多内容、更多代码。
这意味着国内公司也会遇到类似问题:工具越强,管理方式越要改。不是买一个模型接口就结束了,而是要重写流程:哪些任务可以交给模型,哪些必须由人复核,什么结果可以自动发布,什么结果必须留痕,出了问题谁负责。
对企业来说,最务实的“刹车机制”未必是宏大的国际协议,而是日常工作里的几个小开关:
重要代码不能只看生成结果,要有测试、评审和回滚方案。
对外发布内容不能只追求速度,要保留事实核验和责任人。
涉及客户数据、财务、医疗、法律、招聘、教育评价的系统,要明确人工确认边界。
当模型接入更多工具和权限时,要能记录它做过什么、调用过什么、改动过什么。
这些听起来不刺激,却决定了 AI 是提高效率,还是制造新的不可控成本。
“刹车”最终不是反技术
技术行业常常把速度当成美德。快发布、快迭代、快占领市场。这套逻辑在互联网时代很有效,因为大多数产品的错误可以通过版本更新修复,用户迁移成本也相对可控。
但前沿 AI 不完全一样。越强的模型越像基础设施,可能进入企业内部系统、政府服务、网络安全工具、科研流程和教育场景。它不是一个孤立 App,而是一层会被很多系统调用的能力。
在这种情况下,讨论“刹车”不等于反对技术进步。更准确地说,它是在问:当一个系统变得太快时,谁有权要求它慢一点?谁有能力判断它需要慢一点?慢下来之后,谁能确认别人也慢了下来?
Anthropic 的提议未必成熟,也很难马上实现。它自己也承认,类似验证机制可能需要很长时间建立,而行业并没有几十年可以慢慢磨合。但这恰恰说明,这场讨论不该等到风险已经摆在眼前才开始。
这次新闻的价值,不在于给出一个立刻可执行的答案,而在于把一个以前偏理论的问题,拉回到了真实的工作现场:模型已经在写代码、跑实验、做审核、找漏洞。它还没有完全接管方向盘,但它已经踩下了油门。
刹车机制要不要有,怎么设计,谁来监管,都会继续争吵。可至少有一点越来越清楚:未来的 AI 治理不能只靠口号,也不能只靠企业自觉。它需要数据、制度、外部监督和足够具体的工程实践。
真正成熟的技术社会,不是永远不踩油门,也不是永远不刹车,而是知道什么时候该看路。
资料来源
1. Anthropic Institute:《When AI builds itself》,2026-06。https://www.anthropic.com/institute/recursive-self-improvement
2. AP News:《Anthropic urges industry coordination to allow for a “pause” in AI development if risks grow》,2026-06-05。https://apnews.com/article/938c99158e5953601cf3322f1cec12af
3. Reuters 转引:《Anthropic says AI labs need coordinated plan to halt development if risks rise》,2026-06-04。https://www.investing.com/news/stock-market-news/anthropic-says-ai-labs-need-coordinated-plan-to-halt-development-if-risks-rise-4727753
4. OpenAI:《OpenAI public policy agenda》,2026-06-03。https://openai.com/index/public-policy-agenda/
5. TechXplore 转引 AP 报道:《Anthropic urges industry coordination to allow for a “pause” in AI development if risks grow》,2026-06-05。https://techxplore.com/news/2026-06-anthropic-urges-industry-ai.html
