 夜雨聆风
夜雨聆风
大家好,我是 Ai 学习的老章
谷歌这次又把油门踩到底,Gemma 4 QAT 检查点直接发了——E2B 内存压到 1GB 以内,26B MoE 用 16GB 就能在自己电脑上跑起来,本地部署党直接起立鼓掌
简介
先说背景,Gemma 4 系列(之前老章也水过几篇)发布两个月,谷歌持续在加料:先有 MTP(多 token 预测)做推理加速,几天前刚补了 12B 这个尺寸,把 E4B 和 26B MoE 之间的窟窿堵上
LM Studio 终于支持 MTP 了, Qwen3.6-35B 跑出 ~130 token 每秒
这次发的 QAT(Quantization-Aware Training,量化感知训练)才是真正给「跑在自己电脑上」这件事打开了大门
QAT 的玩法和大家熟悉的 PTQ(训练后量化)不一样,它是把量化过程直接揉进训练里,让模型从一开始就为压缩而生,最后压完精度损失比 PTQ 小一大截
谷歌这次放出了两套权重:
Q4_0 通用版:给 llama.cpp 全家桶用,Hugging Face 上直接拉 Mobile 移动专用版:专门为手机/平板/嵌入式芯片设计,E2B 文本版可以塞进 1GB 以内
核心亮点:
E2B 1GB 跑动:纯文本(去掉 Per-Layer Embeddings)只要不到 1GB,手机端推理彻底松绑 26B MoE 进笔记本:以前要工作站才能伺候的 26B-A4B,现在 16GB 内存的 MacBook 也行(Unsloth 实测 15GB 就够) 质量基本不掉:QAT 的核心卖点不是省内存,是省内存的同时保住质量,比简单 PTQ 强一截
移动端专用量化方案,到底搞了啥
这部分是这次发布最有意思的地方,谷歌为移动端单独定制了一套量化 schema,不是简单把 Q4_0 套上,而是从 4 个维度重新设计:
下面这张图把 4 个维度的协同关系画清楚了:
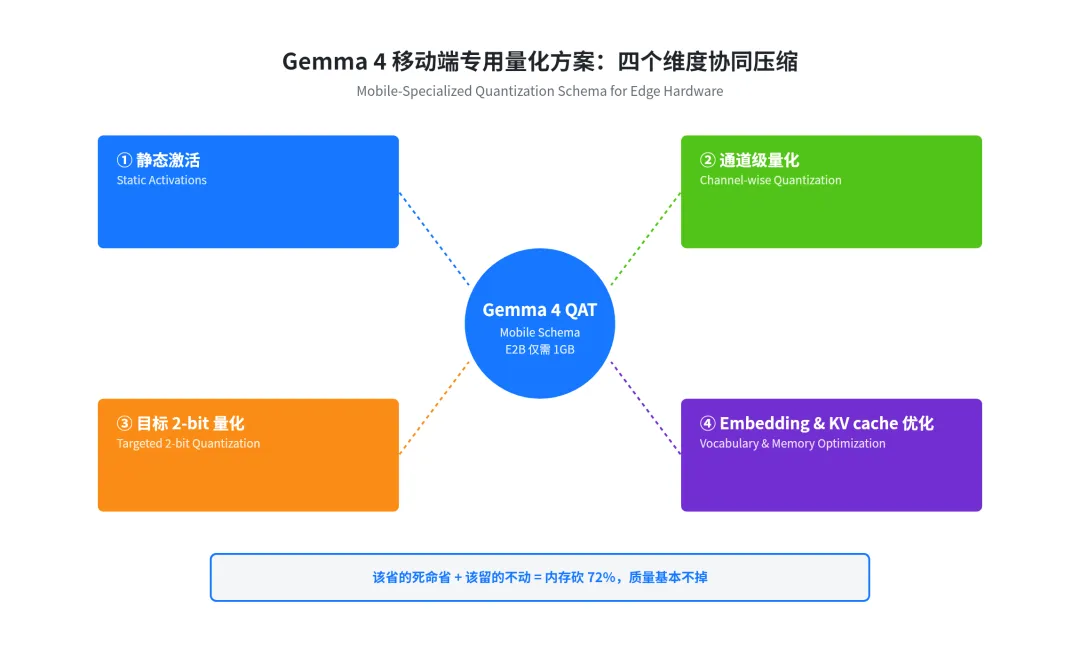
静态激活(Static activations):常规模型推理时还要现场算 scale 参数,浪费算力,谷歌干脆在训练阶段就把这些值预先算好,跑在手机芯片上直接省一道工序 通道级量化(Channel-wise quantization):把压缩数据结构跟移动加速器的硬件设计对齐,手机原生算法直接吃,不用走慢的兼容路径 目标 2-bit 量化(Targeted 2-bit):把生成 token 的那部分层激进压到 2-bit,但核心推理层保留更高精度——舍存储不舍智商 Embedding 和 KV cache 优化:词表和短期记忆这俩内存大头单独压,让长对话不至于撑爆内存
简单说就是:该省的死命省,该留的不动,手机芯片跑得动还跑得快
如果你只用文本,把视觉/音频编码器关掉,E2B 直接 1GB 以内启动,这事在两个月前还属于「想都别想」级别
安装
最快的玩法依然是 Ollama,命令照着抄就行:
# 边缘小模型(笔记本/手机)ollama run gemma4:e2bollama run gemma4:e4b# 工作站本地推理ollama run gemma4:12bollama run gemma4:26bollama run gemma4:31bLM Studio 也已经第一时间支持,点几下就能下载
GGUF 拿来给 llama.cpp 直接吃,compressed tensors 给 vLLM 直接吃,剩下的不带量化的 checkpoint 自己转想要的格式
使用
参数三件套(官方推荐):
temperature = 1.0top_p = 0.95top_k = 64上下文长度看模型规格:
E2B、E4B:128K 12B、26B-A4B、31B:256K
硬件门槛 Unsloth 那边给了张更接地气的表(RAM + VRAM 总和或统一内存):
| Gemma 4 E2B QAT | |
| Gemma 4 E4B QAT | |
| Gemma 4 12B QAT | |
| Gemma 4 26B-A4B QAT | |
| Gemma 4 31B QAT |
也就是说:
16GB MacBook → 26B MoE 跑得动 24GB 显卡 → 31B Dense 也能上 普通 Mac mini M4 16GB → 12B 还能留出余量做别的事
开发工具栈一览
谷歌这次直接把生态打包给齐了,等于发布即生产可用:
One More Thing:Unsloth 把 QAT 又往前推了一步
Unsloth 这帮哥们儿不让谷歌一个人嗨,他们发现一个很反直觉的事:
❝把官方 QAT BF16 直接转成 llama.cpp 的 Q4_0 格式,精度反而会掉一截——因为 llama.cpp 用 F16 scale,而 QAT 训练时用的是 BF16 scale,两边对齐不上
举个具体的例子,26B-A4B 直接转 Q4_0 拿到的 top-1 准确率只有 70.2%,Unsloth 用动态量化方法手动对齐后做到了 85.6%(提升 15.6 个点),而且文件还小了 200MB
下面这张图是 Unsloth 的可视化,我看了之后只能说他们是真在抠细节:
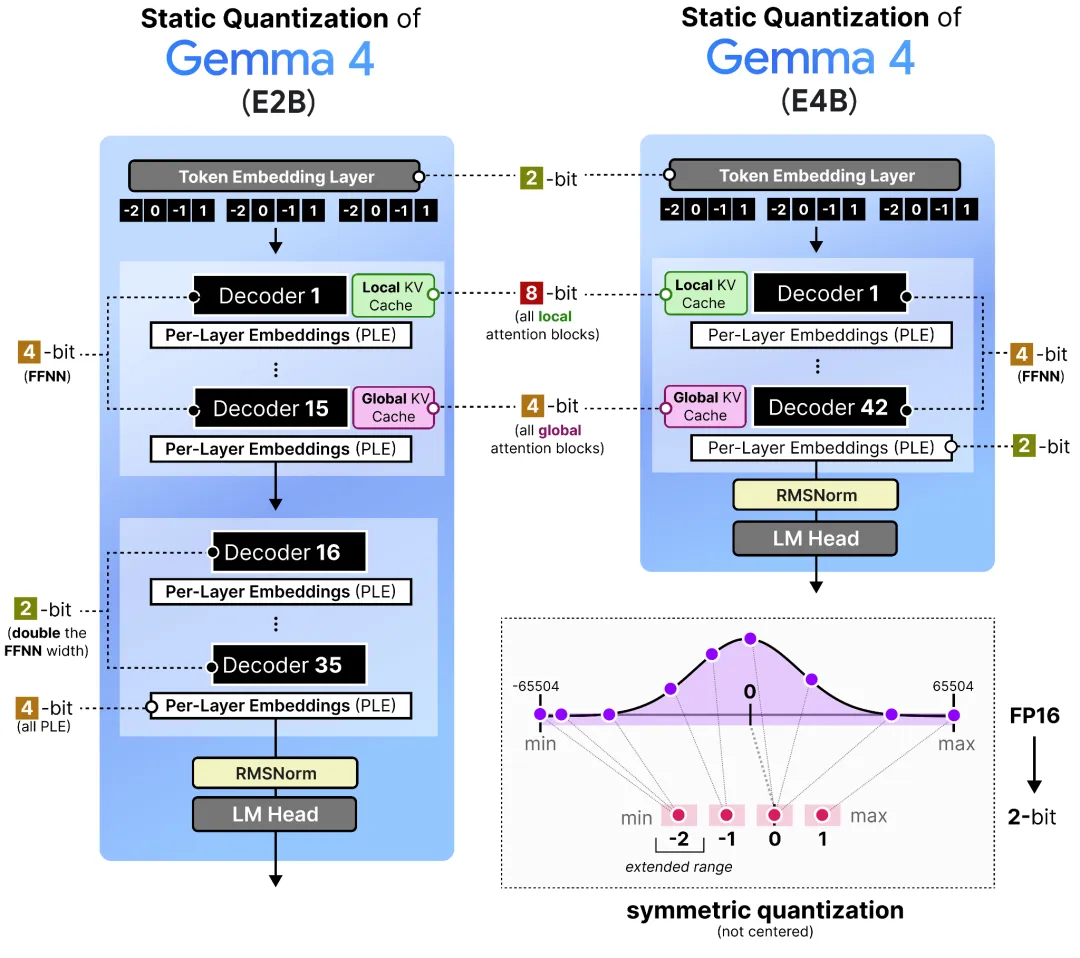
体积对比也很猛,拿原始 BF16 当基线看:
| 71.86% | |||
| 72.05% | |||
| 71.76% | |||
| 71.88% | |||
| 71.82% |
整整砍了 72%,还想要更稳,Unsloth 的命名是 UD-Q4_K_XL,比单纯 q4_0 更值得收
总结
实测心得:
本地大模型部署党:这次必须升级,特别是 16GB 内存机器上以前根本碰不动 26B 级别,现在 MoE 帮你把活的参数控制在 4B,体感速度也跟上来了 手机端开发者:移动 QAT 把内存压到 1GB,配 LiteRT-LM,能跑出真正端侧能用的体验 二次量化别裸转:直接把 QAT 权重转成 llama.cpp Q4_0 会丢精度,要么用谷歌官方放的 GGUF,要么直接拉 Unsloth 的 UD 系列
不太满意的地方也得说:
Mobile 专用格式目前主要绑 LiteRT-LM 这套,想用 llama.cpp 那一系还是得走 Q4_0 通用版 E2B、E4B 的强项在低内存场景,硬要拼分数它们打不过 12B/26B/31B,选模型时别被 1GB 的噱头冲昏头
总的来说,这是 Gemma 4 这波最有诚意的一次更新,把「小模型能跑」变成了「大模型也能在你电脑上跑」,配合 MTP 和 12B 那两次更新看,谷歌在「Gemma 落地到每个开发者电脑上」这件事上是真上心了
老章给这次发布打 95 分,扣的 5 分留给以后看 mobile 格式生态铺得快不快
