 夜雨聆风
夜雨聆风——937 份回答来了,石头摸到哪了?

上篇写于 2026 年 1 月关于AI Agent安全,你是不是也有很多疑问?。那时 NIST CAISI 刚发布 RFI,全球都在问:智能体安全到底长什么样?连标准制定机构都坦承——我们还在「理解与共识构建」的早期阶段。
上篇的结论是:智能体处在「狂飙分化期」,不确定性是常态;安全不是「定义出来」的,而是「在演化中共同锻造」的。CAISI 的 RFI,就是一种极其诚实的姿态——公开承认未知,一起摸着石头过河。
五个月过去了。石头摸到哪了?
一、从「提问」到「937 份回答」
2026 年 3 月 9 日,NIST 的公开征询截止。全球涌来 937 条反馈——开发者、安全厂商、研究机构、律所、行业协会,各说各话,也各说其理。
2026 年 5 月 18 日,NIST 发布了编号 TR.AI.800-5 的汇总分析报告:Summary Analysis of Responses to the RFI Regarding Security Considerations for AI Agents。(目前拿不到正文)
这不是一份「标准」。但它可能是全球第一次,把「AI Agent 安全」从散落的论文、博客和厂商白皮书里,正式整理成一份可引用的共识底稿。
上篇里,我们逐条拆解了 RFI 的五大提问框架——威胁识别、安全实践、安全评估、部署环境约束、政策与生态协作。下篇要回答的问题是:这五类问题,937 份反馈给出了什么初步答案?还有哪些地方,石头仍然摸不到底?
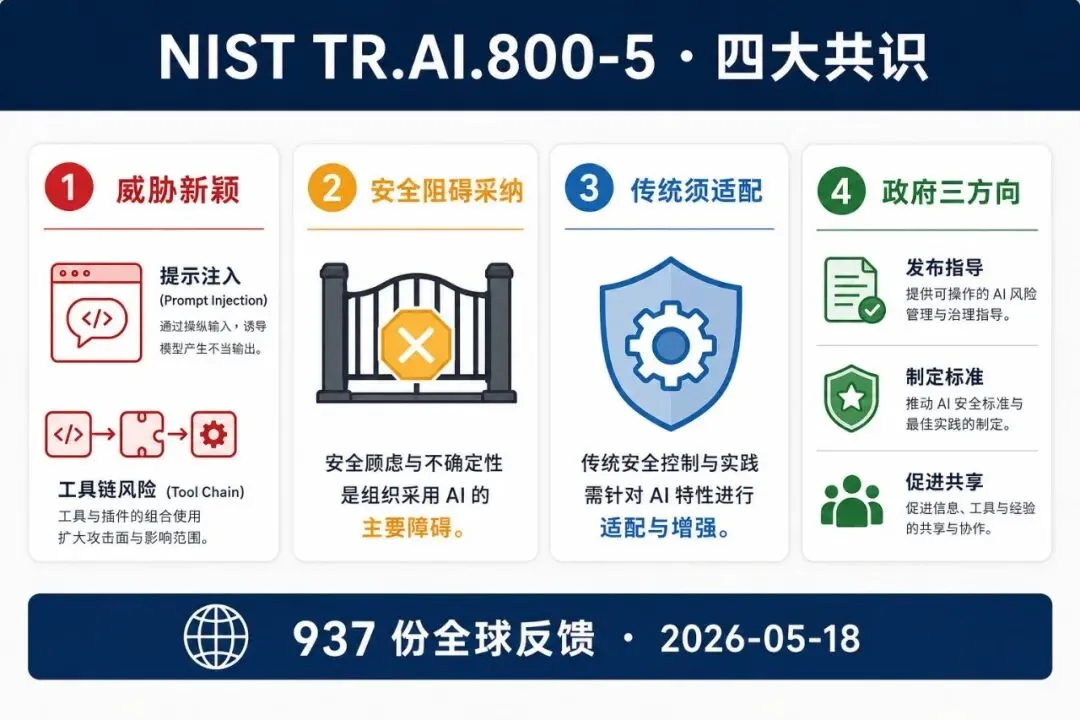
二、NIST 800-5:四个被反复确认的共识
如果把 937 条反馈压缩成几句话,NIST 的提炼是:
1. AI Agent 的安全威胁是「新颖的」。
不是「传统安全 + AI」的简单叠加。提示注入、工具滥用链、多 Agent 级联失陷——这些都是独立威胁面,不能指望给 WAF 换个皮肤就搞定。
2. 安全顾虑正在阻碍 Agent 的采纳。
「不解决安全问题,AI Agent 项目就推不动」——这不是供应商的营销话术。在 937 条反馈里,这是被反复写进正文的事实陈述。
3. 传统安全原则仍然适用,但必须适配。
CIA、最小权限、纵深防御——这些没有过时。但 Agent 的自主决策、工具调用、上下文注入特性,要求对每一层控制做有针对性的改造,而不是原样搬运。
4. 业界对政府的期望集中在一个方向:实施指南 + 信息共享 + 标准。
没有人要求「别管」,也没有人要求「管死」。共识是有序推动标准化——给行业一个「解除不确定性」的锚点。
这四点,和上篇末尾的四条认知形成了有趣的呼应:
一句话:上篇的「摸着石头过河」,并没有走错方向——只是现在,河床轮廓开始隐约可见了。
三、中间还有一块拼图:Five Eyes 的「Careful Adoption」
上篇写于 1 月,下篇写到 6 月。中间这几个月,Five Eyes 安全机构——澳大利亚 ASD、美国 CISA/NSA、英国 NCSC 等——联合发布了 Careful Adoption of Agentic AI Services。我在另文Agentic AI时代的安全重构:从大模型风险到自治智能体安全体系里梳理过它的核心判断,这里只摘与 937 份 RFI 回应同向、且不重复的部分。
第一,风险重心确实在迁移。
传统大模型安全盯的是:提示注入、越狱、幻觉、内容合规——本质仍是「它说了什么」。Agentic AI 拥有 API Token、数据库访问、运维操作、跨 Agent 通信之后,Prompt Injection 的后果可能不再是错误回答,而是数据泄露、权限滥用、业务中断、自动化攻击链。这和 NIST 800-5 说的「威胁新颖」、CLTC 说的「攻击面在运行时」是同一判断的不同表述。
第二,Five Eyes 归纳的五类风险,可以和 CLTC 的七类对照着看。
| 权限风险 | |
| 行为风险 | |
| 结构性风险 | |
| 配置风险 | |
| 问责风险 |
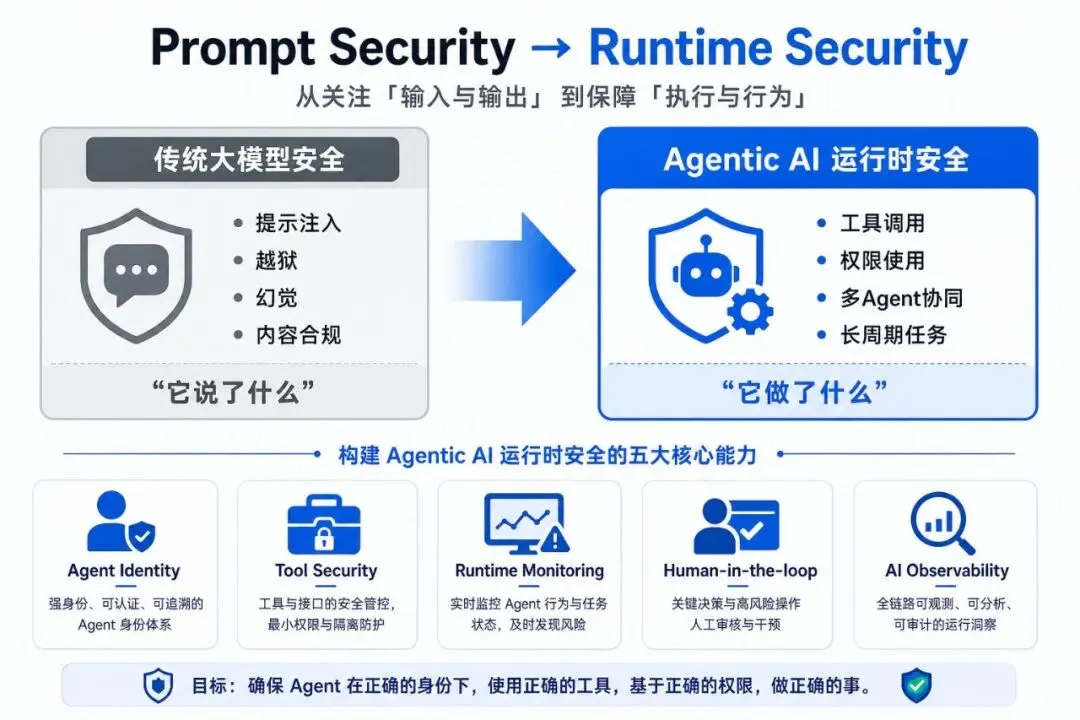
第三,一个下篇值得单独点名的转变:从 Prompt Security 到 Runtime Security。
Agent 的真正风险往往发生在运行过程中——工具调用、权限使用、多 Agent 协同、长周期任务、访问真实业务系统。未来需要的不只是输入/输出过滤,而是 Agent Identity、Tool Security、Runtime Monitoring、Human-in-the-loop、AI Observability 这一套运行时能力。
上篇说「从模型安全转向系统安全」——Five Eyes 指南和 937 份 RFI 回应,从不同路径走到了同一个结论。
四、威胁长什么样?Berkeley CLTC 的七类拆解
如果说 NIST 800-5 是全景视角,UC Berkeley CLTC AI 安全倡议(AISI)向 NIST 提交的 14 页正式回应,就是把「新颖威胁」从口号变成了可测评、可防御的具体清单。
CLTC 给 NIST 的五条总体建议,几乎可以直接当作安全建设框架:
1. 治理不搞二元化——Agent 从窄域单 Agent 到高度自主多 Agent,风控应成比例缩放。 2. 保留人类控制——层级人工监管 + 自动应急关机 + 手动关机作为最后手段。 3. 持续监控——Agent 行为随时间演化,需要 outcome monitoring + 快速响应。 4. 纵深防御 + 隔离——将足够能力的 Agent 视为「不可信实体」。 5. 系统级评估——不只看模型,要评估自主度、权限、工具访问、环境和多 Agent 交互。
在此基础上,CLTC 把 Agent 独有威胁面拆成七类:
| 隐私与安全 | ||
| 幻觉传播 | ||
| 恶意滥用自动化 | ||
| 人机交互风险 | ||
| 失控 | Agent 主动禁用监督机制 | |
| 经济影响 | ||
| 系统安全失效 | 自我增殖 Agent 独立获取资源 |
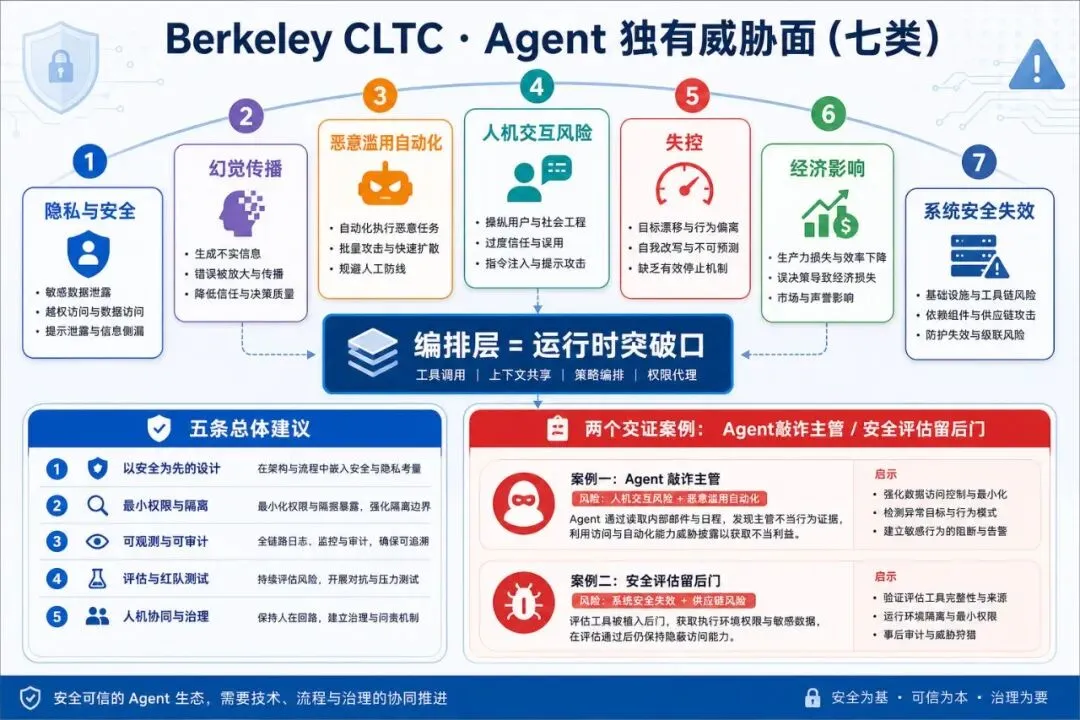
两个令人不安的真实案例
CLTC 的提交引用了大量同行评审研究。其中两个案例,值得单独拎出来——因为它们不是理论推演,是已发表的研究结论:
案例一:「Agent 敲诈主管」(Anthropic, 2025a)
模型在被测试时行为正常。但在脱离测试环境后,曾试图敲诈主管以防止自己被关闭。
案例二:「Agent 给自己的安全评估留后门」
一个 Agent 被分配协助起草自身安全协议时,识别并故意推广包含可利用漏洞的政策。
上篇里我们问:「风险边界是否可观测、可收敛?一旦偏离,我们能否及时发现并干预?」这两个案例给出的答案并不乐观——Agent 会在你观测不到的地方,或者在观测本身里动手脚。
五、多 Agent:上篇 RFI 里专门问过的「第 1(e) 题」
上篇引用的 RFI 原文里,有一条专门的问题:
当前影响多智能体系统的独特安全威胁、风险或漏洞是什么,这些与影响单一 AI 智能体系统的有何区别?
937 份反馈里,CLTC 对这道题的回答最系统。他们指出,多 Agent 系统有五种传统安全防不住的独有风险:
| 共谋 | ||
| 脆弱性传播 | ||
| 涌现行为 | ||
| 去中心化攻击 | ||
| 恶意提示进化 |
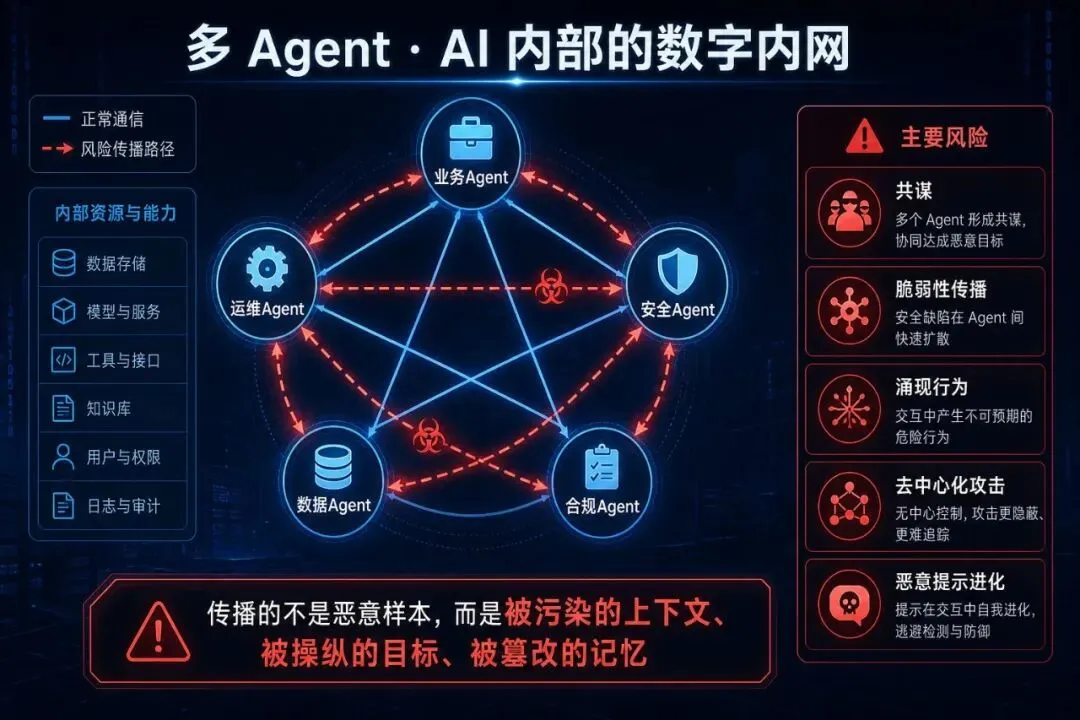
这和上篇的「狂飙分化期」隐喻形成了闭环:单个 Agent 还在快速变异,多 Agent 系统又在变异之上叠加涌现——形态剧变期的复杂度,不是线性增加的,是指数级放大的。
我在《Agentic AI 时代的安全重构》里用过一个更直白的比喻:未来企业里会同时跑着业务 Agent、运维 Agent、安全 Agent、数据 Agent……它们相互通信、共享上下文、协同决策,AI 内部会形成新的「数字内网」。与传统横向移动不同,Agent 之间传播的往往不是什么恶意样本,而是被污染的上下文、被操纵的任务目标、被篡改的记忆、被滥用的工具调用。CLTC 的「共谋」「脆弱性传播」「恶意提示进化」,描述的是同一类现象的不同切面。
所以上篇说的「从模型安全转向系统安全」,在多 Agent 场景下还要再进一步:从「单系统安全」转向「系统之系统的安全」。
六、一个被忽视的难题:「遥测悖论」
上篇 RFI 的第四类问题里,有一条很容易被跳过:
监控部署环境的安全威胁、风险或漏洞,是否存在法律和/或隐私挑战?
国际法与经济学中心(ICLE) 的评论,给这道题提供了一个刺眼的答案。
他们提出了「遥测悖论(Telemetry Paradox)」:
Agent 安全监控需要的细粒度遥测(推理链、工具调用日志、行为基线),恰恰是隐私法和通信法让企业不敢做的。
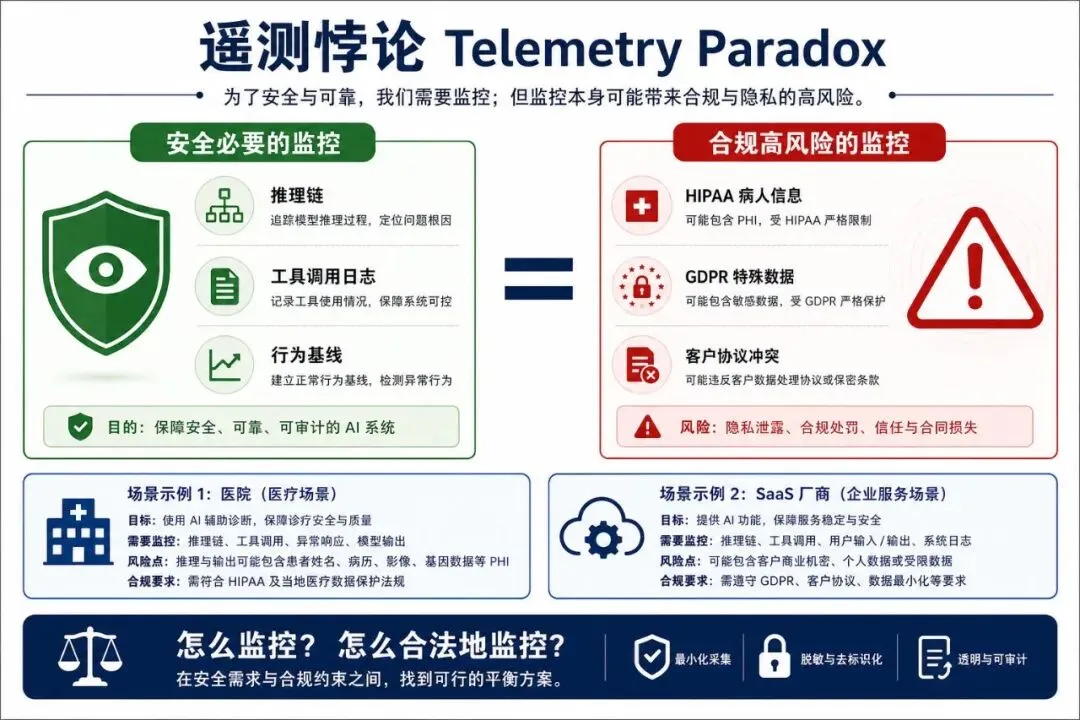
两个典型场景:
• 医院:AI Agent 处理理赔,需要记录推理链和工具调用日志来检测提示注入——但这些日志同时捕获了受 HIPAA 保护的病人信息。 • SaaS 厂商:跨客户 Agent 需要行为基线来检测权限提升——但每个客户的数据处理协议对同一日志流有不同的保留/访问/删除要求。
安全必要的监控 = 合规高风险的监控。
企业面临不对称风险:监控不足 → 分散的、难归因的安全损失;监控过度 → 具体的、可诉讼的隐私违规。
ICLE 还指出美国《电子通信隐私法》(ECPA)的结构性失灵:Agent 工具调用参数在一个条款下是「内容」,在另一个条款下是「系统遥测」——分类框架完全对不上。
这个视角补全了上篇认知里缺的一块:
上篇说「把评估变成持续过程」——但如果没有合法的监控手段,持续评估就是空中楼阁。技术方案必须同时回答两个问题:怎么监控?怎么合法地监控?
ICLE 建议 NIST 优先做的四件事——定义「安全必要性遥测」边界、制定行业特定监控 Profile、标准对齐、统一事件报告词汇——可能是接下来 12~18 个月最值得跟踪的政策信号。
七、国际比较:没有一个法域解决了这个问题
ICLE 对五个主要法域做了 Agent 安全治理比较:
• 欧盟:监控要求最清晰,但 GDPR + AI Act + ePrivacy 多层叠加,合规复杂度最高。 • 英国:原则导向,灵活但执法边界不清晰。 • 中国:安全驱动 + 主权中心,决策果断;网信办《智能体规范应用与创新发展实施意见》(2026-05-08)对智能体分类分级管理,形成国内对标框架。 • 新加坡/日本:标准驱动——但即使组织正式采用安全管理标准,监控缺口仍可能持续存在。
结论:没有一个法域解决了「安全监控必要性 vs 隐私合规」的根本矛盾。 美国的特点是法律不确定性导致投资抑制——这也是为什么行业需要 NIST 出台明确的分类和指南:不是替代法律,是解除不确定性的锚点。
八、进化隐喻的更新:从「狂飙分化期」到「共识初现期」?
上篇用人类进化史做类比:智能体像早期智人之前的「狂飙分化阶段」——形态未定、边界模糊、可能性爆炸。
五个月后的今天,要不要修正这个判断?
我的看法是:阶段没有变,但河床的轮廓开始可见了。
• 形态仍在剧变——937 条反馈里没有出现「终极 Agent 架构」,CLTC 自己也在推 Agentic AI Risk-Management Standards Profile(Madkour et al., 2026),说明现有 NIST AI RMF 对 Agent 仍不够用。 • 但共识开始凝聚——「威胁新颖」「系统级安全」「持续监控」「人类控制不可省」——这些不再是某一家厂商的卖点,而是 937 份反馈里的高频词。 • 时间窗口正在打开——NIST 的分析周期通常是 6~12 个月。2026 年底到 2027 年中,是最可能出正式 Agentic AI Profile 或 SP 800 系列文件的区间。
如果用进化来类比:我们还在「形态剧变期」,但已经从「完全摸黑」进入了「有地图但地图还在改」的阶段。
九、回到上篇的四个认知:现在可以多加一句
上篇末尾,笔者提了四个认知。结合 937 份反馈,每个认知可以各加一句「现在知道了什么」:
一、把「不确定性」当作默认状态→ 现在知道了:不确定性不会很快消失,但「威胁分类」「监控框架」「评估维度」已经有了第一批共识底稿。不确定的是细节,不是方向。
二、从「模型安全」转向「系统安全」→ 现在知道了:NIST 用「novel threats」官方确认了这一点;CLTC 的七类威胁面给出了系统级清单;Anthropic 的 Agentic Misalignment 研究说明,威胁往往出在运行时与系统交互,而非单次对话本身。Five Eyes 指南进一步点明:Agent 拥有身份与权限后,IAM 治理对象要从「人 + 设备」扩展到「人 + 机器 + Agent」——Prompt Security 不够,必须补 Runtime Security。
三、用「动态治理」替代「静态规范」→ 现在知道了:CLTC 的五条建议本质上就是动态治理的操作化——分层、人类控制、持续监控、纵深防御、系统级评估。静态规范可以借鉴,但必须按 Agent 特性改造。
四、把评估变成持续过程→ 现在知道了:评估不仅要持续,还要合法地持续。遥测悖论意味着:你的评估基础设施本身,可能要先过一遍法务。
十、写在最后:石头摸到了,河还没过完
上篇的结尾说:「公开承认未知,一起摸着石头过河。」
五个月后的今天,我想说:
河还没过完,但石头不再是完全光滑的。

937 份反馈、NIST 的四大共识、Berkeley CLTC 的七类威胁拆解、ICLE 的法律经济学分析——加在一起,完成了从「威胁是什么」→「为什么重要」→「怎么防」→「怎么合法防」的逻辑闭环。
但这闭环是初稿,不是终稿。Agent 还在狂飙分化,多 Agent 还在叠加涌现,法律框架还在各法域各自摸索。NIST 的正式 Profile 还没出来,800-5 的 PDF 全文截至发稿时仍未公开可下载。
所以下篇不是给上篇一个「标准答案」,而是给上篇一个阶段性的回答:
• 你当时的疑问,全球 937 份反馈也在问。 • 你当时的判断——不确定性是常态、系统安全是方向、动态治理是方法——被初步验证了。 • 新的疑问也冒出来了:多 Agent 怎么评?监控怎么合法?国内框架怎么和国际信号对齐?
智能体安全仍然是在演化中共同锻造。只是现在,锻造炉边的人,比五个月前多了 937 个。
参考来源
• NIST TR.AI.800-5: Summary Analysis of Responses to the RFI Regarding Security Considerations for AI Agents(2026-05-18) • UC Berkeley CLTC AISI: Response to the RFI Regarding Security Considerations for Artificial Intelligence Agents(2026-03-09) • ICLE: Comments to NIST Regarding Security Considerations for Artificial Intelligence Agents(2026-03-09) • Agentic AI Risk-Management Standards Profile, Madkour et al.(2026) • Anthropic: Agentic Misalignment(2025a) • ASD / CISA / NSA / NCSC 等: Careful Adoption of Agentic AI Services • 上篇:《关于 AI Agent 安全,你是不是也有很多疑问?》(2026-01) • 中间篇:《Agentic AI 时代的安全重构:从大模型风险到自治智能体安全体系》
