 夜雨聆风
夜雨聆风
他们让 Qwen3.7-Max 仅凭一份约 15 万字的产品调研文档,在隔离环境里全自动交付了移动端 + Web 端两套真实应用。没有设计稿,没有后端代码,单端耗时约 4 小时,中途无人工接管。
说实话,"AI 写代码"这事大家已经麻了。但这个实验不太一样——它不是让模型写几个函数、跑个 demo,而是从 0 到 1 交付一个可安装的 APK 和一个能跑通的 Web 应用。中间涉及的任务量、决策量、错误恢复能力,跟"帮我写个快排"完全不是一个量级。
一、它到底做了什么
先说清楚输入和输出。
输入:一份约 15 万字的产品调研文档。不是设计稿,不是技术方案,就是一份调研文档——里面可能有需求描述、竞品分析、用户画像之类的东西。
输出:
移动端:一个可安装的 APK Web 端:typecheck 和构建均通过,34 条路由全部可达
环境:隔离环境,意味着模型不能上网搜答案、不能调外部 API,完全靠自己的能力完成。
4 小时交付一端。这个速度不算快——一个熟练的前端工程师可能一天也能搭个架子出来。但关键是全程无人工接管,模型自己规划、自己编码、自己调试、自己修 bug。
二、技术上怎么做到的
这才是我最关心的部分。
通义实验室采用了一套"分阶段注入约束→逐层验收→带错纠正"的闭环控制系统。听起来有点学术,拆开看其实很工程:
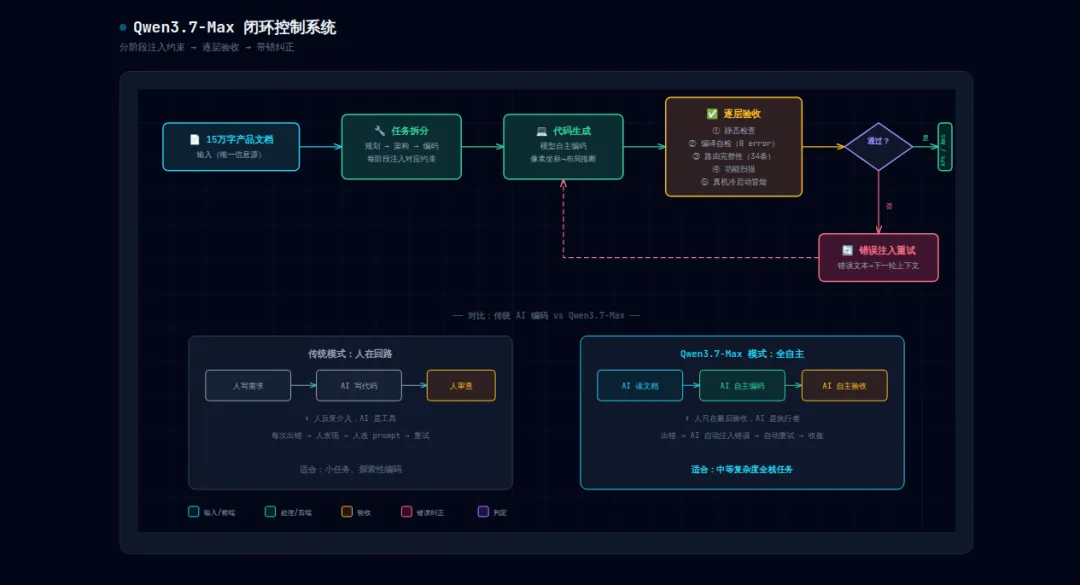
分阶段注入约束:不是把 15 万字文档一股脑丢给模型让它从头写到尾。而是把任务拆成规划、架构、编码等阶段,每个阶段只注入当前需要的约束条件。这样模型不会被信息淹没,每个阶段的目标都很清晰。
逐层验收:每个阶段完成后有一套验收流程——静态检查、编译自检(要求 0 error)、路由完整性检查(Web 端 34 条路由全部可达)、功能扫描、真机冷启动冒烟。这不是"编译通过就算成功",是层层把关。
带错纠正:验收失败时,错误文本会自动注入下一轮重试。模型看到自己的错误,调整策略再试。通义的原话是"使模型数小时内收敛"——这个表述很克制,没说"一次成功",而是承认了中间有反复。
还有一个细节很有意思:模型不具备图像理解能力。也就是说,它看不到设计稿长什么样。那界面怎么还原的?通过像素坐标反推布局约束。说白了就是,模型拿到的是"这个按钮在 (100, 200) 位置,宽 80,高 40"这种数值信息,然后自己推断出布局逻辑。
三、跟其他 Agent 编码方案比怎么样
Claude Code、Cursor、Codex 也能写代码。但这个实验跟它们的区别不在模型能力,在任务的规模和自主性。
Claude Code / Cursor 这类工具,本质上是"人在回路"的编码助手。你给它一个任务,它写一段代码,你看一眼,觉得不对就改。整个过程是人和 AI 协作完成的。
Qwen3.7-Max 这个实验,是模型自己从头干到尾。15 万字的文档,它自己读、自己拆解、自己规划、自己编码、自己测试、自己修 bug。人只在最后验收。
这就像一个是"你指挥、AI 干活",另一个是"AI 自己干、你验收"。后者的难度指数级增长。
从 Agent 开发者的角度看,这个实验真正有价值的地方不是"它写出了一个 App",而是它展示了一套可复用的 Agent 工程范式。
四、三个没回答的问题
第一个:15 万字文档是什么质量的? 通义的原文说是"产品调研文档",但没披露具体内容。一份结构清晰、需求明确的 15 万字文档,和一份含糊其辞、前后矛盾的 15 万字文档,对模型来说是完全不同的挑战。如果文档本身就写得很好,那模型做的事情更像是"把需求文档翻译成代码",而不是"从 0 到 1 创造一个产品"。
第二个:产出质量到底怎么样? "可安装 APK"和"typecheck 通过"是最低标准。真正的问题是:UI 好不好看?交互流不流畅?有没有明显的 bug?用户愿不愿意用?这些通义都没说。我之前跑过类似的长链路 Agent 任务,验收标准定低了,最后产出的东西能跑但根本没法用——按钮能点但布局全乱,路由通了但数据加载不出来。
第三个:4 小时的计算成本是多少? 如果用的是 Qwen3.7-Max 的 API,4 小时不间断调用,token 消耗应该很可观。这个成本跟雇一个初级开发工程师比,哪个更划算?
不过话说回来,这些问题不影响这个实验的核心价值。它证明了一件事:当前最好的模型,已经有能力在无人干预的情况下完成中等复杂度的全栈开发任务。这在一年前是不可想象的。
五、对 Agent 开发者意味着什么
我自己做 Agent 开发,看到这个实验的第一反应不是"哇好厉害",而是"这套工程方法论值得抄"。
具体来说:
任务分阶段 + 约束分层注入这个思路,可以直接用到自己的 Agent 工作流里。很多 Agent 项目失败的原因就是一把梭——把所有信息一次性丢给模型,期望它自己搞定。实际上,分阶段给信息、分阶段验收,效果好得多。
带错纠正的闭环机制也是。Agent 在执行长任务时一定会出错,关键是出错之后怎么恢复。最简单的方案就是把错误信息塞回上下文让模型重试,但通义这个方案更精细——它区分了不同类型的错误(编译错误、路由错误、功能错误),针对性地注入不同的纠正信息。
像素坐标反推布局这个 trick 也挺有意思。当模型没有视觉能力时,用结构化的坐标数据代替截图,让它推断布局逻辑。本质上是把视觉问题转化成数值问题——模型不需要"看",只需要"算"。
总结
Qwen3.7-Max 这个实验,技术上的亮点不在于"它写了一个 App",而在于它展示了一套完整的 Agent 全自动开发范式。分阶段约束注入、多层验收、带错纠正——这些工程方法论比模型本身更有参考价值。
作为 Agent 开发者,我更关心的是这套范式能不能复用到自己的项目里。答案是可以的,而且不一定要用 Qwen3.7-Max。核心思路是通用的:把大任务拆小、把约束分层给、把错误喂回去、把验收做扎实。
方向是对的,进展比大多数人预期的快。至于能走多远,得看下一个实验。
参考来源:
