 夜雨聆风
夜雨聆风6月9日,小米把 MiMo-V2.5-Pro UltraSpeed 拿了出来,最抓眼的是 1000 TPS。公开材料写得很直,1T 参数模型,单台 8 卡通用 GPU 节点,解码速度冲到每秒约 1000 个 token,演示峰值还能到 1200 左右。
我更愿意把它翻译成一句人话,AI 助手终于可以少让人等一会了。你让手机写一段话,多卡几秒还行;你坐在车里说打开空调,系统停两三秒才动,体感马上变差;你让代码助手补一个页面,屏幕半天挤出几行字,思路也会被拖住。大模型变快,落到手边就是少等、少断片、少烦躁。
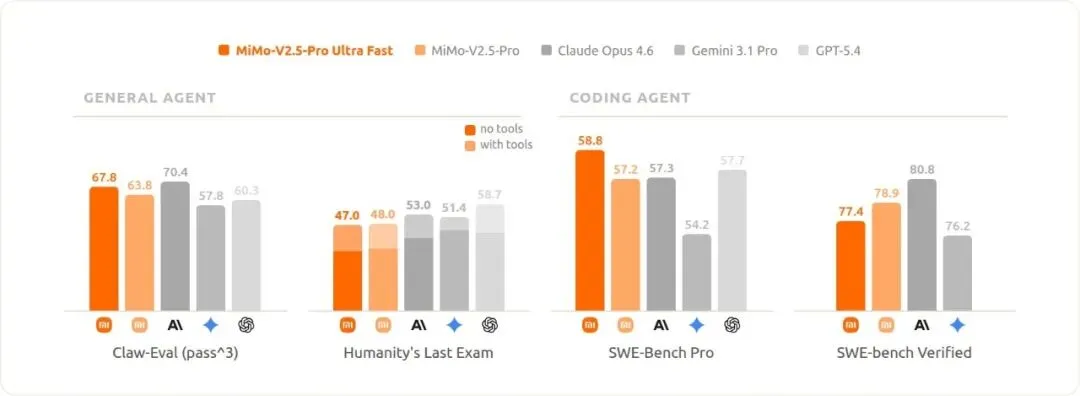
1000TPS先解决的是等待
很多技术发布爱讲参数、榜单和缩写,普通用户很难产生体感。1T 参数有多大,MoE 怎么分专家,FP4 又压了多少显存,大多数人不会天天拿这些词过日子。
大家能感受到的,是一句话说出去以后,机器有没有马上接住。
我用 AI 工具时很在意这个瞬间。回答质量差一点,我还会换问法;但如果它一直卡在那里,我会下意识把手伸回键盘,自己做。等待时间一长,AI 就从助手变成了需要哄着用的工具。
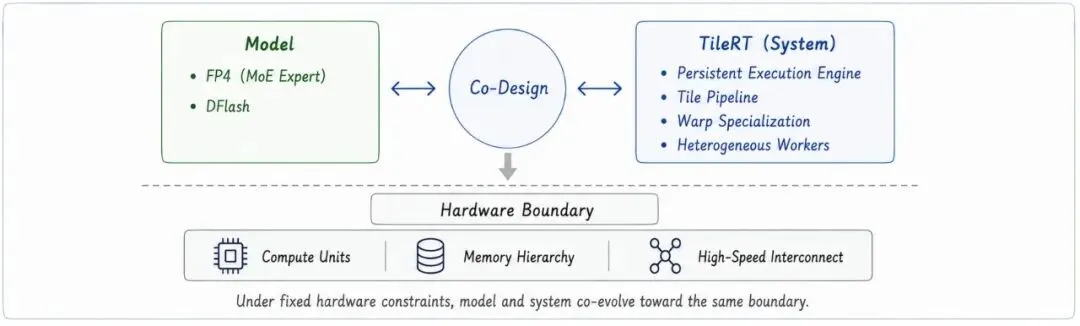
万亿参数跑快,靠的是链路一起抠
小米没有把故事讲成砍小模型换速度。
公开材料里提到三块,FP4 量化主要压 MoE 里的专家层,把体积和计算压力降下来;DFlash 推测解码,让轻量草稿模型先往前写几步,大模型再成块确认;TileRT 则把 GPU 执行里的零碎交接时间继续往下压。
换个说法,原来像老师盯着学生一个字一个字写,现在先让助教写一小段草稿,老师一眼看一整块,能过的放行,不能过的再改。与此同时,门口排队、叫号、换班的空档,也被压短了。
AI助手快一截,人才愿意继续打开
AI 进入日常生活,拦路的经常不在聪明程度上,反倒在顺手程度上。
智能家居就是典型场景。你说关灯,灯晚几秒才灭,你不会去想模型参数,只会觉得这玩意不灵。车机也是一样,语音指令慢半拍,驾驶时的耐心会被迅速磨掉。
代码助手更明显。开发者写一个函数、改一段样式、起一个前端原型,靠的就是边想边试。模型如果能在几秒内吐出可运行的草稿,人就愿意继续跟它来回磨;如果每一步都要盯着进度条,工具的存在感反而变重。
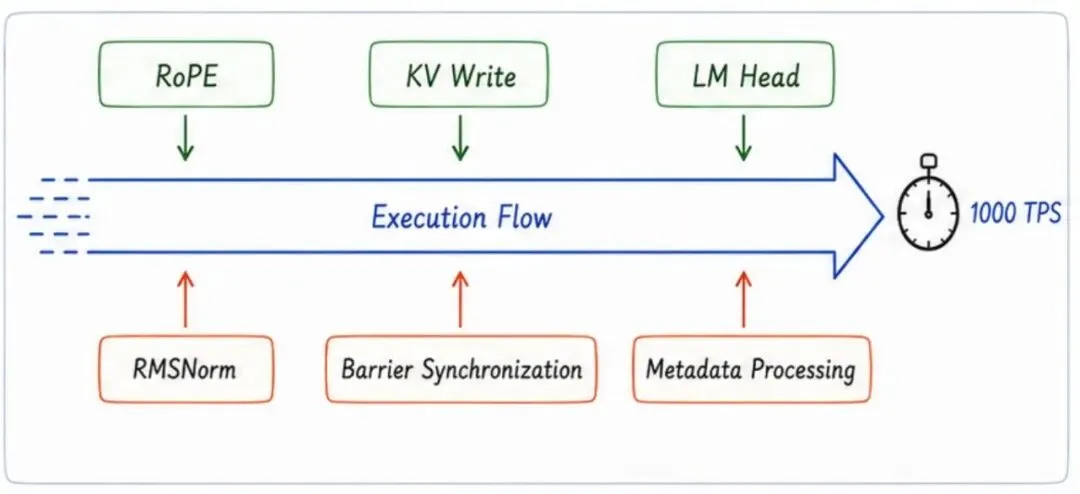
数字漂亮,还得放进产品里
1000 TPS 不能理解成所有任务都会立刻飞起来。
自然语言、代码生成、复杂推理的速度表现会有差异。更复杂的 AI 助手也不只是吐字,它还要理解上下文、调用工具、处理文件、连接设备、做权限确认。回答快了以后,后面那些环节如果跟不上,用户仍然会卡在流程里。
还有一个问题也绕不开,快错了没有意义。模型回答不准,生成再快也是把错误更快送到你面前。工具调用不稳,用户还是要自己收拾残局。接入车和家居设备时,安全确认、误触发、权限边界,这些环节更不能因为追速度被压掉。
小米要把这几秒还给用户
MiMo 对小米的价值,不该停在技术博客里。
如果它要服务小米的人车家生态,考题会非常朴素。用户坐进车里,语音助手能不能更快理解意图;手机处理照片、文件、行程时,能不能少卡几秒;家里的灯、空调、扫地机,能不能像反应正常的人一样接话。
我对这次发布的判断很简单。MiMo UltraSpeed 让小米的大模型路线多了一点可信度,因为它盯住了等待时间这个真实痛点。接下来,小米需要把这个速度放进更多真实产品里,让用户少等、少点、少改、少被工具打断。
大模型公司都爱讲智力,普通人每天先感受到的却是手边那几秒。小米这次把速度抬上去了,后面就看它能不能把这几秒,稳稳还给用户。
