 夜雨聆风
夜雨聆风
公司的产品需求、售前资料、市场部文档,全在飞书上。
目录结构倒是挺清晰,但新人进来还是找不到。问了一圈,有人说"在飞书文档里",有人说"我发过群里"。找了半天,打开发现是三个月前的旧版本。
这不是某一个人的问题,是知识管理的问题。
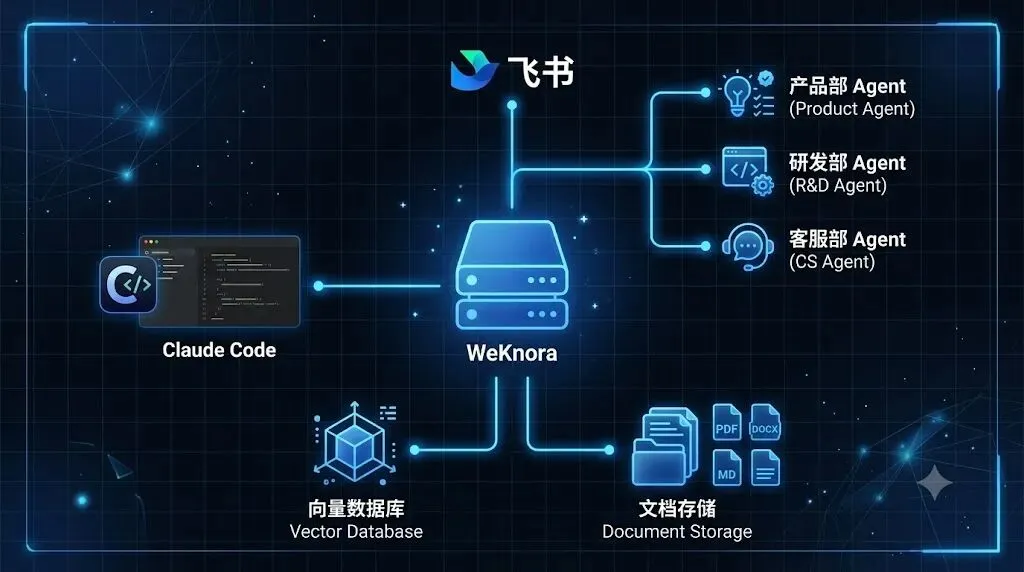
找了好几个方案,最后用了一个叫 WeKnora 的开源项目——腾讯做的,RAG 架构的知识库平台。用公司闲置的 Ubuntu 服务器部署了一套,效果比预期好。
先说结果:
• 各部门有自己的知识库,飞书文档更新自动同步 • 每个部门有自己的 AI Agent,在飞书上直接提问 • 研发团队用 Claude Code 写代码时,自动获取公司技术文档作为上下文 • 零软件订阅费,服务器是现成的,模型 API 走按量付费,用多少花多少
服务器是公司已有的:Ubuntu 24.04.3 LTS,8 核 32G,200G 磁盘。
我用本地 Mac 的终端 SSH 上去操作:
ssh deploy@公司服务器IPWeKnora 全部容器化部署,只需要 Docker 和 Docker Compose。部署前确认一下环境:
docker --versiondocker compose version二、部署
拉代码
git clone https://github.com/Tencent/WeKnora.gitcd WeKnora配环境变量
cp .env.example .env有几个地方必须改:
# 数据库密码,别用默认值DB_USER=weknoraDB_PASSWORD=自己设# JWT密钥,生产环境必须改JWT_SECRET=自己设# 单机部署用local就行STORAGE_TYPE=local# 生产环境关闭注册DISABLE_REGISTRATION=true# 时区TZ=Asia/Shanghai启动
docker compose up -d核心服务只启动这几个就够了:
docker compose up -d app frontend postgres redis minio qdrant docreader启动后等 30 秒左右数据库 migration 完成,然后访问 http://服务器IP:8080。
看到登录页面就说明部署成功了。
三、模型配置——踩了一整天的坑
这是最需要认真对待的一步。
WeKnora 需要两类模型:LLM 负责对话和总结,Embedding 负责文档向量化。在管理后台的"系统设置 > 模型设置"里配,用 OpenAI 兼容格式。
LLM 选在线 API
我们用的 SiliconFlow,模型选 deepseek-chat(DeepSeek V3),中文场景够用了,性价比高。
Embedding——最大的坑
这是整个部署过程中代价最深的教训。
一开始想着本地跑省事,装了 Ollama 配了 nomic-embed-text。文档上传后 parse_status 显示 completed,一切看起来正常。
但搜索永远返回空结果。
排查了半天搜索接口、知识库配置、向量数据库,最后才发现是 Embedding 的问题。换了 SiliconFlow 的 BAAI/bge-m3 在线 API,立竿见影。
为什么不行?三个原因:
第一,Ollama 的 /v1/embeddings 接口和 OpenAI 标准不完全兼容,响应格式有差异。第二,本地模型在中文场景的精度远不如 BAAI/bge-m3。第三,批量处理几十个文档时 CPU 慢到无法接受。
结论:在 WeKnora 项目中,Embedding 用在线 API 更省心。
模型名称必须精确
又一个容易翻车的细节。在 SiliconFlow 上配 Embedding 模型,模型名必须一字不差:
• ❌ bge-m3—— 报 "Model does not exist"• ❌ BAAI/bge-M3—— 同样报错• ✅ BAAI/bge-m3—— 正确
切换 Embedding 模型后,Qdrant 的 collection 需要重建,因为向量维度变了。
四、对接飞书
这是最有价值的部分。
在 WeKnora 后台 → IM 设置 → 新增飞书 Channel,选 WebSocket 模式,填入飞书应用的 App ID 和 App Secret。
WebSocket 模式的好处是不需要公网 IP 和回调地址,内网就能跑。但踩了两个坑:
第一,删除旧 Channel 后必须重启 app 容器。不然旧的 WebSocket 连接会残留,导致消息路由错乱。
第二,飞书 SDK 有自动重连机制,容器重启后会建立新连接。日志里会看到同一个 app_id 出现多次连接记录,这时候再重启一次容器清理就行。
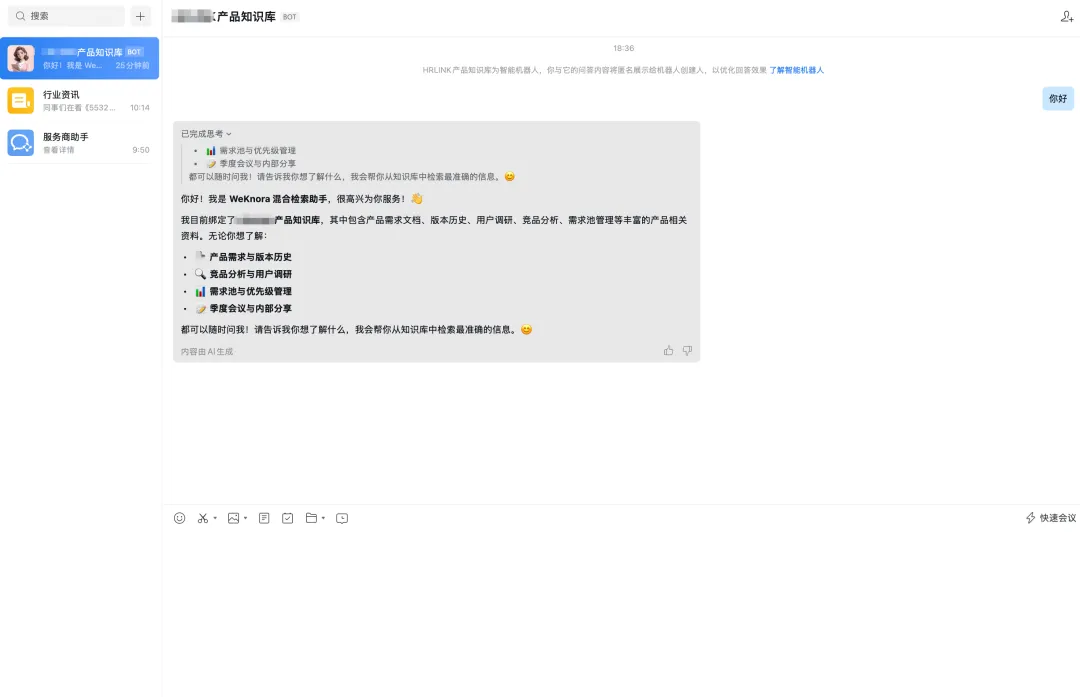
配好之后,每个部门一个 Agent,绑定各自的知识库。部门的人在飞书上直接给 Agent 发消息提问,Agent 从知识库检索回答。
我们给产品部绑了产品文档,研发部绑了技术文档,客服部绑了 FAQ。飞书知识库更新后自动同步到 WeKnora,不需要手动维护。
五、Claude Code 集成
研发团队用 Claude Code 写代码和文档时,经常需要参考公司的技术规范、API 文档、架构决策。以前是人工把这些文档内容复制粘贴到对话里,现在通过 WeKnora 的 MCP(Model Context Protocol)服务器,Claude Code 可以直接搜索知识库。
在项目的 .mcp.json 里加上:
{ "mcpServers": { "weknora-knowledge-base": { "command": "python3", "args": ["scripts/weknora_mcp_server.py"] } }}Claude Code 启动时自动加载,写代码时自动调用 search_knowledge 获取背景知识。
WeKnora 自身也提供了 Web 对话界面,员工可以直接在浏览器里向知识库提问。
六、批量上传文档的注意事项
文档多了之后会遇到几个实际问题。
限流。SiliconFlow 等在线 API 有 TPM(每分钟 token 数)限制。一次上传 30 多个文档时,并发 Embedding 请求可能触发 429。表现是部分文档成功,部分卡在 processing 状态。解决方式是降低并发数,或者手动分批上传,每次 5 到 10 个。
搜索词。中英文混合搜索效果比纯英文好。比如搜 paycode 工资项 比只搜 paycode 准确得多。
文档状态排查。搜索返回空结果时,按顺序检查:文档是否启用、知识库 ID 是否正确、文档解析是否完成、Embedding 是否成功、查询词是否匹配。
七、日常运维
几个常用命令:
# 查看容器状态docker compose ps# 看后端日志docker compose logs -f app# 看飞书连接日志docker compose logs app | grep "\[IM\]"# 查 Embedding 错误docker compose logs app | grep -E "EmbedBatch|embedding|Error"定期检查文档解析状态,发现失败的及时重新解析。MinIO 存储长期运行后 /data/files 会膨胀,记得留意磁盘空间。
总结
部署 WeKnora 本身不复杂,一行 docker compose up -d 搞定。真正花时间的是踩坑和调优。
经验浓缩成一句话:Embedding 用在线 API,模型名写全称,改配置后重启容器,文档分批上传。
好的知识库不是 AI 多聪明,而是公司里每个人踩过的坑,都不会让第二个人再踩一遍。
