 夜雨聆风
夜雨聆风从提示词到上下文工程,再到驾驭工程
很多人对 AI 的理解,还停留在“提示词写得好不好”。
这不奇怪。ChatGPT 刚进入大众视野时,最容易被看见的能力就是对话。你输入一句话,它返回一段答案。于是最自然的问题就是:我该怎么问,它才会答得更好?
Prompt Engineering 最初在大众层面流行起来,大概就是因为这个。
但到了今天,只懂提示词已经不够了。因为 AI 的使用方式正在一层一层向外扩展:从写好 prompt,到组织好 context,再到设计 harness。换句话说,问题已经从“怎么命令模型”,变成“怎么给模型安排一个能工作的世界”。
我更愿意把这三层理解成:
Prompt Engineering:把任务说清楚
Context Engineering:把信息摆清楚
Harness Engineering:把系统驾驭住
这三层更像套在一起的三个圈。prompt 仍然重要,只是它在最里面;context 决定模型能看到什么;harness 决定模型能做什么、在哪里做、怎么被约束、怎么被验证、怎么从失败中修正。
第一阶段:提示词工程,核心问题是“怎么对模型说”
Prompt Engineering 的起点,可以追溯到大模型开始展现 in-context learning 能力的时期。
2020 年 GPT-3 论文 Language Models are Few-Shot Learners 让很多人意识到:模型不一定每次都要重新训练,只要在输入里给任务描述和少量示例,它就能在上下文里临时学会某种模式。于是 prompt 不再只是“提问”,而变成一种轻量编程接口。
到了 2022 年,Chain-of-Thought Prompting、ReAct 这类方法进一步把 prompt 推向方法论化。CoT 关心的是:能不能通过示例让模型显式展开中间推理步骤。ReAct 关心的是:能不能让模型在推理和行动之间交替,边想边查、边做边修正。
ChatGPT 在 2022 年 11 月发布后,Prompt Engineering 从研究圈和开发者圈进入普通用户世界。大量用户第一次发现,同一个模型,问法不同,结果差别巨大。
这一阶段的方法论很像“提问术 + 任务说明书”:
明确角色:你是谁? 明确任务:你要做什么? 明确背景:你需要知道什么? 明确格式:你要以什么形式输出? 提供示例:什么是好答案? 反复迭代:哪里不对,继续改 prompt。
对应产品形态也很清楚:ChatGPT、Claude、Gemini 这类聊天机器人;OpenAI Playground、Claude Console 这类开发者控制台;以及各种提示词模板、提示词市场、提示词管理工具。
这一阶段的核心假设是:模型能力已经在里面了,关键是你怎么把它“叫出来”。
但 prompt 有一个天然边界:它只能处理你当下放进去的东西。任务一复杂,材料一多,历史一长,单靠一段好提示词就开始吃力。
于是第二层出现了。
第二阶段:上下文工程,核心问题是“让模型看见什么”
Context Engineering 的出现,意味着 AI 使用方法论从“写好一句话”转向“组织好一整个信息环境”。
Anthropic 在 2025 年的 Effective context engineering for AI agents 中,把 context engineering 定义为:在模型推理时,策划和维护最优 token 集合的策略。它强调,context 不只是 system prompt,而是推理时进入模型的全部信息:系统指令、工具定义、外部数据、历史消息、文件、记忆、MCP、环境状态。
这一步把问题换了个位置。
Prompt Engineering 问的是:“我怎么说,模型才懂?”
Context Engineering 问的是:“模型到底应该看见哪些信息,才可能做对?”
这里有个很容易被忽略的事实:上下文窗口变大,不等于效果线性变好。context 是有限资源。越长的上下文越容易产生噪音、污染和注意力分散。难点在于挑出那一小撮高信号材料,而不是继续往窗口里塞东西。
RAG、向量数据库、文件检索、prompt cache、compaction、memory、sub-agent、MCP 这些东西,就是在这个阶段变得重要的。它们都在处理同一个麻烦:怎样在需要的时候,把正确的信息送到模型面前。
这一阶段的代表方法包括:
RAG:让模型在回答前检索事先准备好的向量数据库里的知识。 tool calling / function calling:让模型调用外部工具,而不是只在文本里猜。 memory:把长期偏好、项目状态和历史决策保存下来。 compaction:把长对话压缩成可继续工作的摘要。 MCP:把 AI 助手和数据源、工具、业务系统连接起来。 sub-agent:让不同 agent 分担搜索、分析、执行,再把结果压缩回主上下文。
对应产品也开始变化。
从 ChatGPT 这种“一个对话框”,发展到带文件、项目、记忆、插件、工具调用、企业知识库连接的 AI 工作台。开发者生态里,LangChain、LlamaIndex、向量数据库、OpenAI Assistants/Responses API、Anthropic MCP、Cursor、Claude Code、Codex 这类产品,都把“上下文组织”变成了核心能力。
如果 Prompt Engineering 是写一封清楚的信,那么 Context Engineering 就是给模型准备一个资料齐全、标注清楚、没有垃圾信息的办公桌。
但这还不是终点。
因为当 AI 从“回答问题”变成“执行任务”,只给资料仍然不够。你还要给它工具、边界、权限、测试、观察方式、纠错机制和持续清理机制。
问题于是推到第三层:Harness Engineering。
第三阶段:驾驭工程,核心问题是“如何驾驭 agent”
Harness 原意是马具、挽具。这个词比“工具链”更准确。它强调的是把一股越来越强的力量接入一个可控系统。
这里先把 Harness Engineering 暂译为“驾驭工程”。
到这里,问题从“模型怎样理解任务”“模型怎样获得信息”,继续推到“模型怎样在真实环境里可靠行动”。换句话说,在智能体系统里,除了模型,剩下的一切都是 harness 。
Harness 是指除模型本身之外的所有代码、配置和执行逻辑。一个单纯的模型并不能称之为智能体。只有当 Harness 为其赋予了诸如状态、工具执行能力、反馈循环以及强制性约束等特性时,它才真正成为一个智能体。
OpenAI 在 2026 年 2 月发布的 Harness engineering: leveraging Codex in an agent-first world,可以作为一个源头案例。文章描述了一个内部产品实验:团队用 Codex 从空仓库开始构建一个真实软件产品,约五个月后形成了百万行级别的代码库;应用逻辑、测试、CI、文档、可观测性、内部工具,都由 Codex 生成。人类不再主要手写代码,更多是在设计环境、表达意图、建立反馈循环,让 agent 能可靠工作。
这已经超过了“把 prompt 写得更长”的范畴。更像工程角色的迁移。
在 OpenAI 的案例里,团队一开始遇到的瓶颈并不是 Codex 不会写代码。更麻烦的是环境欠定义:工具、抽象、内部结构、反馈路径,都还不够清楚。agent 卡住时,人不能只催它“再努力一点”。人要回头看系统缺了什么能力,再把这个能力做成 agent 可见、可用、可验证的东西。
第一层是 执行环境。
Agent 不是漂浮在聊天框里的文本生成器。它需要工作目录、沙箱、测试命令、浏览器、日志、指标、trace、PR 流程、权限边界。OpenAI 文章里提到,他们让应用可以按 git worktree 启动,让 Codex 能通过 Chrome DevTools 驱动界面、截图、导航、复现 bug、验证修复;也把 logs、metrics、traces 暴露给 Codex,让它能用观测信号判断系统是否真的变好。
这意味着,harness 要处理的是工作现场本身。一个工具当然有用,但更关键的是让整个现场变得可读、可操作、可验证。
第二层是 agent legibility,也就是让系统对 agent 可读。
人类团队里,很多知识存在于 Slack、Google Docs、会议、老员工脑子里。但对 agent 来说,看不见就等于不存在。OpenAI 的做法是把仓库知识变成 system of record:短小的 AGENTS.md 只是地图,设计文档、执行计划、产品规格、质量标准、可靠性要求、参考资料,都结构化地放进仓库。Agent 不用吞下一本巨大的说明书,它可以以 AGENTS.md 为目录,按需要逐层发现信息。这也和 Anthropic 在提出 SKILL 时的“渐进式披露”方法一致。
Context Engineering 关心“这一次推理要给模型什么信息”。Harness Engineering 关心“怎样改造组织知识和工程资产,让 agent 每一次运行都能自己找到正确上下文”。
第三层是 机械化约束。
当代码越来越多、agent 吞吐越来越高,只靠文档已经不够。文档会过期,偏好会漂移,局部模式会被 agent 复制放大。所以 OpenAI 把架构边界、依赖方向、命名规则、schema/type 约束、文件大小限制、平台可靠性要求等,尽量变成 lint、结构测试和自动检查。
这里的重点,比继续写更多说明书更硬。harness 要把不能发生的事情机械地编码进环境。
在 Prompt 阶段,你会写:“请保持代码整洁。”
在 Context 阶段,你会给它看团队代码规范。
在 Harness 阶段,你会把规范变成 lint、test、CI、review bot、错误提示和自动修复任务。这样 agent 不需要每次靠记忆和自觉,它会在系统边界里被持续校准。
第四层是 反馈闭环。
OpenAI 的案例里,Codex 后来可以从一个 prompt 出发,验证代码库当前状态,复现 bug,录制失败视频,修复问题,再录制成功视频,开 PR,响应人类和 agent 反馈,处理构建失败,只有在需要判断时才升级给人。
这个循环说明,harness 的重点已经从“执行”延伸到“带验证的执行”。
普通自动化脚本是:输入 -> 输出。
Agent harness 更像:输入 -> 行动 -> 观察 -> 验证 -> 修复 -> 再观察 -> 交付 -> 反馈写回。
没有这个闭环,agent 只是更快地产生不确定输出。有了闭环,agent 才开始接近可托付的工作单元。
第五层是 熵管理和垃圾回收。
第三阶段还有一个常被忽视的部分:熵管理。Agent 生成速度越快,系统越容易积累坏模式:重复抽象、局部补丁、过期文档、漂移的架构、未经验证的“看起来能跑”。OpenAI 文章里把这种问题称为 entropy,并提到用 golden principles、定期清理任务、质量评分、针对性重构 PR 来持续回收系统垃圾。
这和传统工程里的技术债很像,但在 agent 时代更紧迫。因为 agent 的产出速度远高于人类注意力,坏模式如果不被机械清理,会被更快复制。
成熟的 Harness Engineering,会让 agent 在一个能自我整理的环境里干活。
这也是它比前两个阶段更难、更有价值的地方。
Prompt Engineering 可以是个人技能。
Context Engineering 可以是项目技能。
Harness Engineering 更像组织能力。
它要求你把目标、环境、知识、工具、权限、约束、验证、反馈和清理机制放在一起设计。AI 越强,这套马具越重要。因为越强的 agent,越不能只靠一句话来驱动。
三者的层级关系:工程对象逐层外扩
这三个概念最容易被误解成时代替换:提示词工程结束了,上下文工程来了,接着又轮到驾驭工程。这个说法只能解释时间顺序,解释不了它们之间的关系。更准确的关系是嵌套:
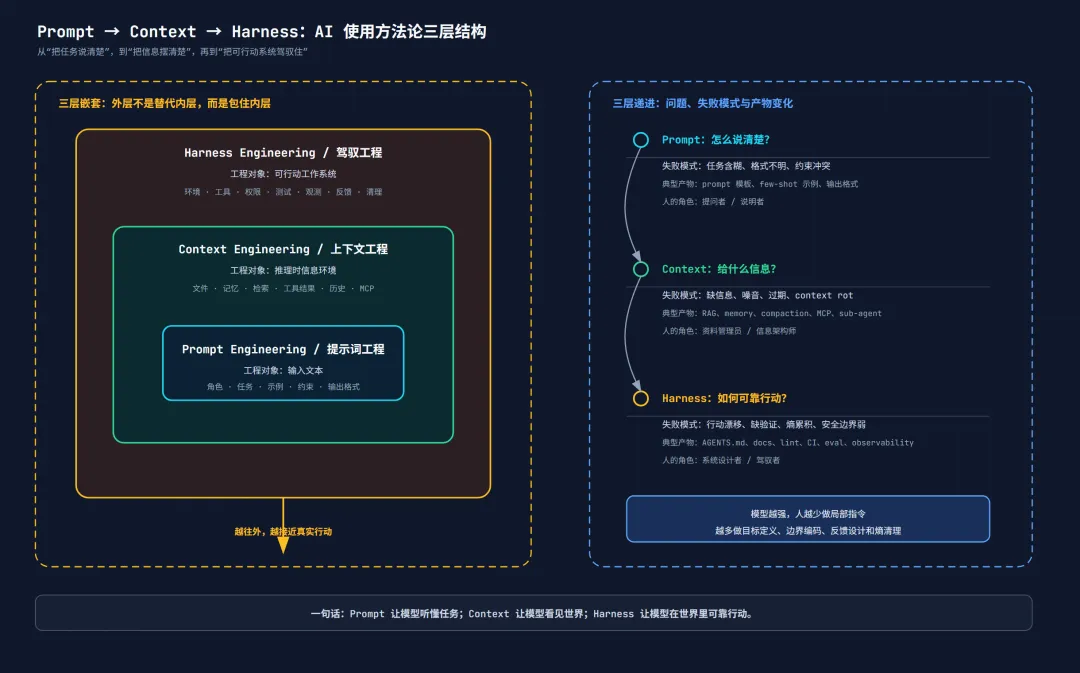
但只说“嵌套”还不够。三者面对的工程对象不同。
Prompt Engineering 的工程对象是 输入文本。
它把人的意图翻译成模型容易预测的 token 序列。你调的是角色、任务、约束、示例、格式。它解决的是表达不清的问题。
这一层最常见的失败是:任务含糊、格式不明、示例不够、约束冲突。解决方法通常是改 prompt。
Context Engineering 的工程对象是 推理时可见的信息环境。
它不只关心 prompt 这段文本,还关心文件、工具结果、检索材料、历史消息、记忆、MCP、环境状态。它解决的是信息不对的问题。
这一层最常见的失败是:上下文太少,模型缺关键信息;上下文太多,模型被噪音淹没;上下文过期,模型依据旧事实行动;上下文结构混乱,模型不知道什么重要。解决方法不能停在改 prompt 上,还要改检索、压缩、记忆、工具返回、文档结构。
Harness Engineering 的工程对象是 可行动的工作系统。
它把 prompt 和 context 都放进一个更大的执行结构里:环境、工具、权限、测试、lint、CI、日志、指标、review、回滚、升级、人类判断、定期清理。它解决的是行动不可靠的问题。
这一层最常见的失败是:agent 会写,但不会验证;会局部修,但破坏整体架构;能完成一次任务,但长期积累漂移;看似自动化,实际把 QA 压力转移给人。解决方法不能继续塞上下文,需要把检查、边界、反馈和清理机制编码进系统。
可以用四个维度来看三者的递进:
这张表里最重要的一行是“人的角色”。
在 Prompt 阶段,人要学会表达。
在 Context 阶段,人要学会整理。
在 Harness 阶段,人要学会设计系统。
这组关系讨论的重点不在术语新旧。它描述的是 AI 能力提升后,人类工作从内层操作向外层设计迁移。
模型弱的时候,人要在 prompt 里手把手指导。模型强起来之后,人要设计它能行动的世界。
Harness Engineering 会出现,是因为 agent 已经能连续执行复杂任务。这个时候,稀缺的东西不再只是 token,也不只是上下文窗口。更稀缺的是人的注意力、组织判断和系统边界。
未来的几个 insight
第一,提示词会变得普通,但不会消失。
模型越强,普通人越不需要背一堆提示词公式。很多以前要靠 prompt 技巧才能做出来的效果,会慢慢变成产品默认能力。但在高价值任务里,清楚的指令、边界、例子和验收标准仍然重要。
第二,上下文会成为 AI 产品的护城河。
同一个模型,接入不同资料、工具、业务系统和历史记忆,表现会完全不一样。未来很多 AI 产品的差别,可能不在“用了哪个模型”,而在它能不能拿到正确上下文,能不能过滤噪音,能不能维护状态。
第三,harness 会变成组织能力。
个人可以靠技巧把 AI 用得不错,团队不能靠每个人临场发挥。团队需要把标准、权限、流程、评估、复盘、错误处理写进系统。谁能把这些东西变成 agent 可读、可执行、可验证的环境,谁就更容易把 AI 变成真实产能。
第四,人的位置会上移,但不会自动变轻松。
在 Prompt 阶段,人负责提问。在 Context 阶段,人负责整理信息。在 Harness 阶段,人负责定义目标、设计约束、选择反馈、处理判断。听起来更高级,但也更难。因为你不能只盯着产出,还要判断这个系统会不会把你带偏。
第五,软件会越来越多地面向 agent 设计。
今天的软件主要给人用,所以重视 GUI、按钮、页面、交互路径。未来的软件还要让 agent 用得明白:状态要可读,接口要稳定,错误要清楚,日志要能追,结果要能验证。一个产品如果只能让人慢慢点,却不能让 agent 理解和操作,它在自动化世界里的存在感会变弱。软件产品会从面向人渐渐变为面向 agent ,相互界面也会从 GUI 越来越多变为 CLI 。
对于个人开发者和内容创作者
对于使用AI写代码的开发者,搭建自己的 harness 会成为主流。需求、架构、测试、部署、日志和代码规范放进仓库,让 AI 参与一个可验证的工程循环。
内容创作者则可以把选题池、素材库、风格偏好、发布数据、标题复盘放进一个系统,让 AI 参与一个持续进化的内容机器。
每做一次,系统就厚一点。下一次不是重新开始,而是在旧资产上继续长。
我自己对这个变化有一点兴奋,也有一点不安。兴奋的是,个人产出的上限确实被抬高了。很多以前卡在执行量上的事情,现在可以真的试一试。不安的是,AI 会让“看起来很忙”变得更容易。你可以一天产出很多东西,但没有判断、没有品味、没有积累,那些产出很快就会变成一堆更漂亮的废料。
这篇文章最后想说的,别停在新名词上。
提示词要学,但别迷信提示词。上下文要管,但别把资料越堆越多。Harness 更值得认真对待,因为它逼你回答一个更难的问题:
你到底想让 AI 进入你的哪一部分工作?
如果只是偶尔帮你省点时间,那写好 prompt 就够了。
如果你想让 AI 参与长期生产,你就得给它一个可以工作的环境,也给自己一套不会被它带跑的判断系统。
以后更值钱的,可能是另一件事:
谁能把 AI 放进自己的生产系统里,然后还保留人的方向感。
