 夜雨聆风
夜雨聆风Lance Martin 在网上发了一篇文章,标题叫《Designing loops with Fable 5》。表面看,它是在分享 Anthropic 内部怎样使用 Claude Fable 5。往深一点看,它讲的是下一阶段 Agent 工程的重心变化:模型本身当然重要,但更重要的是你给它设计了什么样的循环。
Lance Martin 原帖文章卡片。原帖发布于 2026 年 6 月 9 日,抓取时约 24.6 万浏览。
文章的开场很直接:
❝Mythos-class models like Claude Fable 5 have changed the way many of us work at Anthropic. I want to share two tips for getting the most out of this class of models.
❞
他要分享的两个 tips,不是“多写几个 prompt 技巧”,而是两个系统设计方法:
Self-correction loops:让模型在外部反馈中自我修正 Memory:让模型跨 session 复用经验,而不是每次从零开始
原文封面图。注意这张图里的核心不是“一个 Agent”,而是 Agent、workers、memory、review 之间形成的闭环。
这篇文章之所以值得深挖,是因为它把一个容易被忽略的事实说透了:长任务 Agent 的能力,不是靠一次更聪明的回答释放出来的,而是靠一套能持续纠错、评分、记忆、复用的运行时释放出来的。
不是“让模型反思”,而是让环境给它反馈
Lance 先讲 self-correction loops。
他提到,最近大家都在谈 loop。Anthropic 的 Boris Cherny 曾说自己的工作就是 “write loops”。这句话很有意思。它把 Agent 工程从“写提示词”往前推了一步:你不是在写一段让模型听话的文本,你是在写一个让模型反复试错、接收反馈、修正方向的环境。
在 Claude Code 里,/goal 是这种思路的一个入口。在 Claude Managed Agents 里,Outcomes 是另一个入口。它们做的事情相似:你不只是告诉模型“做这件事”,而是告诉系统“什么叫做做完”。
Anthropic 的 Outcomes 文档把这句话说得很清楚:
❝Tell the agent what “done” looks like, and let it iterate until it gets there.
❞
这和普通 prompt 的差别很大。
普通 prompt 更像一次请求。你写得越细,模型越可能一次性接近目标。但一旦任务变长,问题就来了:它会遗漏检查项,会把看起来完成的东西当成完成,会在错误方向上越走越远。
Loop 的做法不同。它把“完成标准”放进环境里,让模型每一轮都能拿到反馈。模型运行、观察结果、读取日志、对照 rubric、修正下一步,直到外部机制判定任务满足条件。
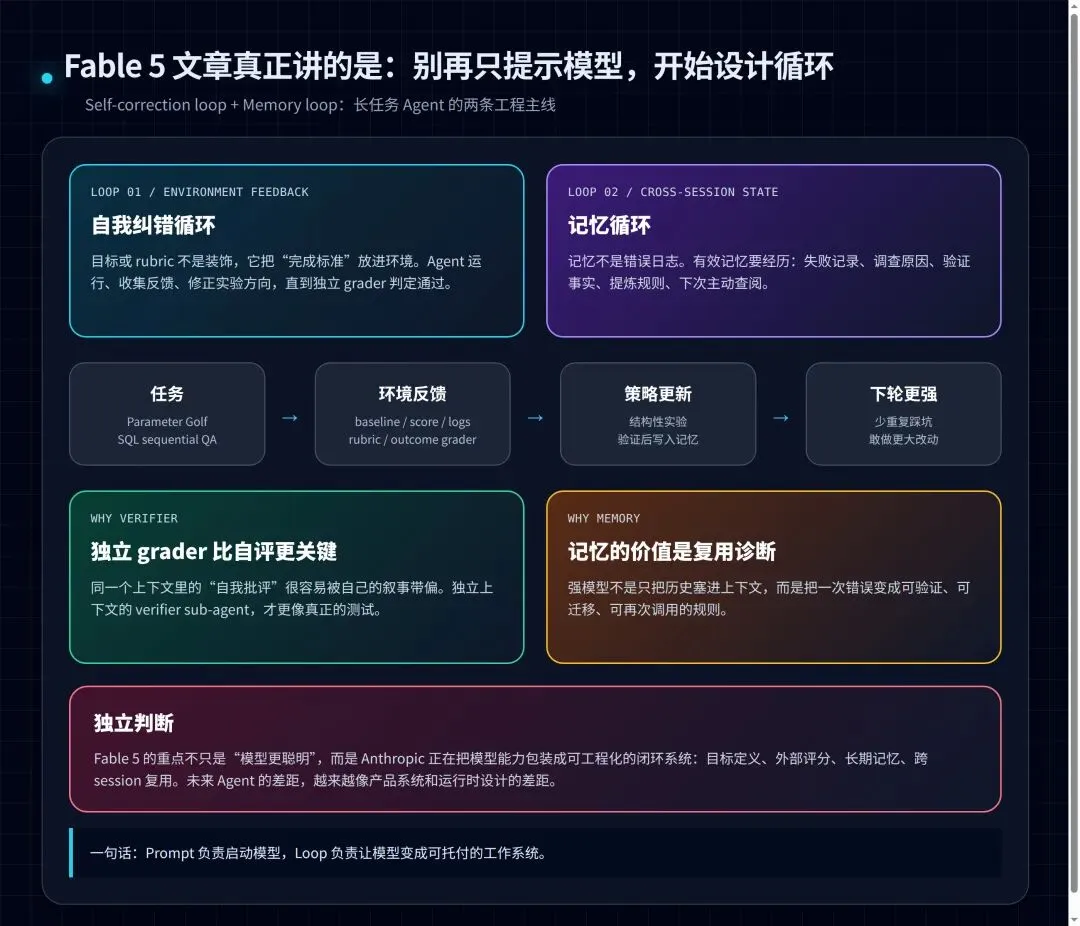
这张结构图是本文新增的理解图:Prompt 负责启动模型,Loop 才负责把模型变成可托付的工作系统。
这也是 Lance 文章里最值得记的一句话:与其直接 prompting 和 steering Fable 5,不如设计 loops,让模型响应环境反馈来自我纠错。
Parameter Golf:为什么 Fable 5 敢做结构性实验
Lance 给了一个具体实验:Parameter Golf。
Parameter Golf 是 OpenAI 的 Model Craft Challenge。任务听起来像机器学习版高尔夫:在极小限制里打出最好成绩。参赛者要训练一个语言模型,整个 artifact 必须小于 16 MB,训练时间少于 10 分钟,硬件预算是 8×H 100,评估指标是 FineWeb validation set 上的 bits per byte。
OpenAI 官方复盘里写过,这个挑战吸引了 1000+ 参与者和 2000+ 提交,讨论的不是“堆更大模型”,而是在严苛约束下做模型设计、量化、训练代码和实验策略。
Lance 用这个任务测试 Fable 5 很合理。它不像普通问答,不能靠背知识过关。它要求 Agent 真正做研究循环:
修改 train_gpt.py启动训练 轮询日志 读取分数 判断下一轮实验 继续调整架构、常数、量化或训练策略
Lance 把这个过程类比为 Karpathy 的 autoresearch 项目。这个类比很准,因为它测试的不是“模型会不会写代码”,而是“模型能不能像研究员一样做连续实验”。
他的实验设置也很重:使用 Claude Managed Agents,给 CMA 接入 8×H 100 的 self-hosted sandbox,每次最多跑 8 小时。每个测试都提供一个 rubric 文件,其中有 9 个可检查条件,比如跑 baseline、跑 20 个实验等。Outcomes grader 只有确认所有实验标准都满足,才允许 Claude 停止工作。
结果是:Fable 5 对训练 pipeline 的改进约为 Opus 4.7 的 6 倍。
更有意思的是差异不只在分数上,而在策略上。Lance 把实验分成两类:
structural:结构性实验,比如改架构 scalar:标量实验,比如调一个常数
Fable 5 更愿意押注大的结构性变化,并且更有韧性。原文举了一个细节:它曾经遇到量化回归,但仍然推进下去,最后拿到最大收益。
Opus 4.7 则更像保守优化器。第一个实验拿到小收益后,后续几乎都沿用同一模板:调一个标量,测一下,如果正向就保留。
这个对比很真实。很多 Agent 在长任务里看起来“稳定”,其实是过早收敛。它们找到一个局部有效模板后,就不断微调,很少跳出当前假设。Fable 5 在 Lance 的实验里更像一个敢改实验范式的研究员。
真正关键的是 grader,不是 self-critique
Lance 在文章里特别强调:what does the judging is important。
这句话需要单独拎出来。
很多人说“让模型自我反思”“让模型检查自己的答案”。这当然有用,但上限有限。原因很简单:同一个上下文里的自我批评,很容易被自己的叙事带偏。模型刚刚写完一个方案,它天然知道自己为什么这么写,也更容易相信自己已经覆盖了要点。
Lance 提到,Anthropic 观察到模型对自己输出做 self-critique 会有问题。相比之下,verifier sub-agent 往往更好,因为 grading 在一个独立 context window 中完成。
Claude Managed Agents 的 Outcomes 正是这样设计的:主 Agent 写,grader sub-agent 用 rubric 检查。grader 是独立上下文,不背着主 Agent 的自我解释,不被“我刚才已经做过了”的幻觉影响。
Anthropic Cookbook 里有一个很好的说法:Agent 很擅长产出“看起来完成”的东西。比如一份带引用的研究 brief,格式工整,脚注齐全。但仔细看,可能覆盖不够,引用漂移,来源只是新闻稿而不是原始文件。
Outcomes 的价值就在这里。它不是让模型“更努力”,而是让检查变成系统的一部分。
一个好的 rubric 也不是一句“检查内容是否完整”。它要让 grader 产出证据。比如:
打开 cited URL,确认页面真实可读 搜索引用原文,确认 quote match 判断这段引用是否真的支持正文 claim 对每个失败项给出具体原因
Cookbook 里的示例很说明问题。一个 research brief 第一次被 grader 驳回,因为 demand charges 只有定性描述,没有 $/kW 或成本比例。第二次又被驳回,因为作者找到了 sec.gov URL,但那是 8-K 的 earnings press release exhibit,不是 rubric 要求的 10-K 或 10-Q。第三次找到真正的 10-K 后才通过。
这就是工程意义上的“好循环”:不是让模型说“我检查过了”,而是让另一个上下文里的检查者逼它拿证据。
Memory 不是记事本,是跨 session 的外循环
Lance 的第二个重点是 Memory。
他把 memory 称为一个跨 session 的 outer loop。Claude 在一个 session 里写入 memory,未来 session 再检索这些 memory。
这里最容易误解。很多人以为 memory 就是“保存历史”。其实那只是最低级的形态。真正有效的 memory,不是把所有失败都记下来,而是把失败变成可验证、可复用、下次会主动查阅的规则。
Lance 用 Continual Learning Bench 1.0 做了测试。

Continual Learning Bench 关注的是 Agent 能不能在连续任务中学习,而不是每个任务都从零开始。
Continual Learning Bench 的问题意识很明确:传统 benchmark 往往假设模型是 stateless 的。每个样本互相独立,系统做完一个任务就离开,好像什么都没发生过。但真实部署的 AI 系统应该能从经验中学习。
它评估的是有顺序的任务序列:
任务之间不是独立的 系统允许,甚至被期待在评估中改变 早期实例包含对后续实例有用的信息 表现取决于系统如何使用经验
官网还引入了 gain 指标:reward 减去同一系统的 stateless baseline,用来衡量系统到底从经验里学到了多少。
Lance 选择了其中一个 SQL 数据库任务。每个问题都是一个独立 agent session,但系统提供 memory。Agent 要在连续问题中逐渐理解数据库、字段、单位和陷阱。
他总结出有效 memory 的五步:
fail:答错,并记录下来 investigate:继续前弄清楚为什么错 verify:把诊断变成检查过的事实 distill:把验证结果提炼成通用规则 consult:下次读取规则,而不是重新推导
这五步很朴素,但很关键。它把 memory 从“日志”提升成“学习机制”。
Sonnet、Opus、Fable 的差异:谁真的会用记忆
Lance 对三个模型的描述很有信息量。
Sonnet 4.6 大约停在第一步。它的 memory store 主要是失败笔记和开放猜测,比如:
❝maybe prc instead of prc_usd?
❞
它很少主动查阅之前的笔记。也就是说,它会记,但不会真正用。要提升表现,需要额外写 task-specific memory instructions。
Opus 4.7 大约走到第三步。它会创建 schema reference,也会标注不确定性,比如:
❝possibly prc in cents? Verify.
❞
但它的验证覆盖率很低。Lance 给的数据是 7–33%,中位数约 17%。这说明它知道“这里可能有问题”,但没有稳定把怀疑变成确认事实。
Fable 5 则倾向于完成整个流程。在强 run 里,它的 verification coverage 最高到 73%,也就是 30 个问题里验证了 22 个,并且会把 learnings 提炼成帮助未来任务的通用规则。
这段对比其实比“某 benchmark 提高多少分”更有价值。它描述的是 Agent 的行为质量:
会不会承认自己错了 会不会调查错误原因 会不会验证假设 会不会把经验提炼成规则 下次会不会主动查阅这些规则
这些能力组合起来,才叫在线学习。否则 memory 只是更长的上下文垃圾桶。
官方 Fable 5:强模型,也是一组安全约束下的系统产品
Lance 的文章是内部使用视角。要完整理解它,还得看 Anthropic 官方发布文。
Anthropic 在 2026 年 6 月 9 日发布 Claude Fable 5 和 Claude Mythos 5。官方说法是:Fable 5 是一个 Mythos-class 模型,但经过安全化,可以一般使用。Mythos 5 则是同一底层模型,在部分高风险领域解除 safeguards,先面向 cyberdefenders 和 infrastructure providers 这样的 trusted access 场景。
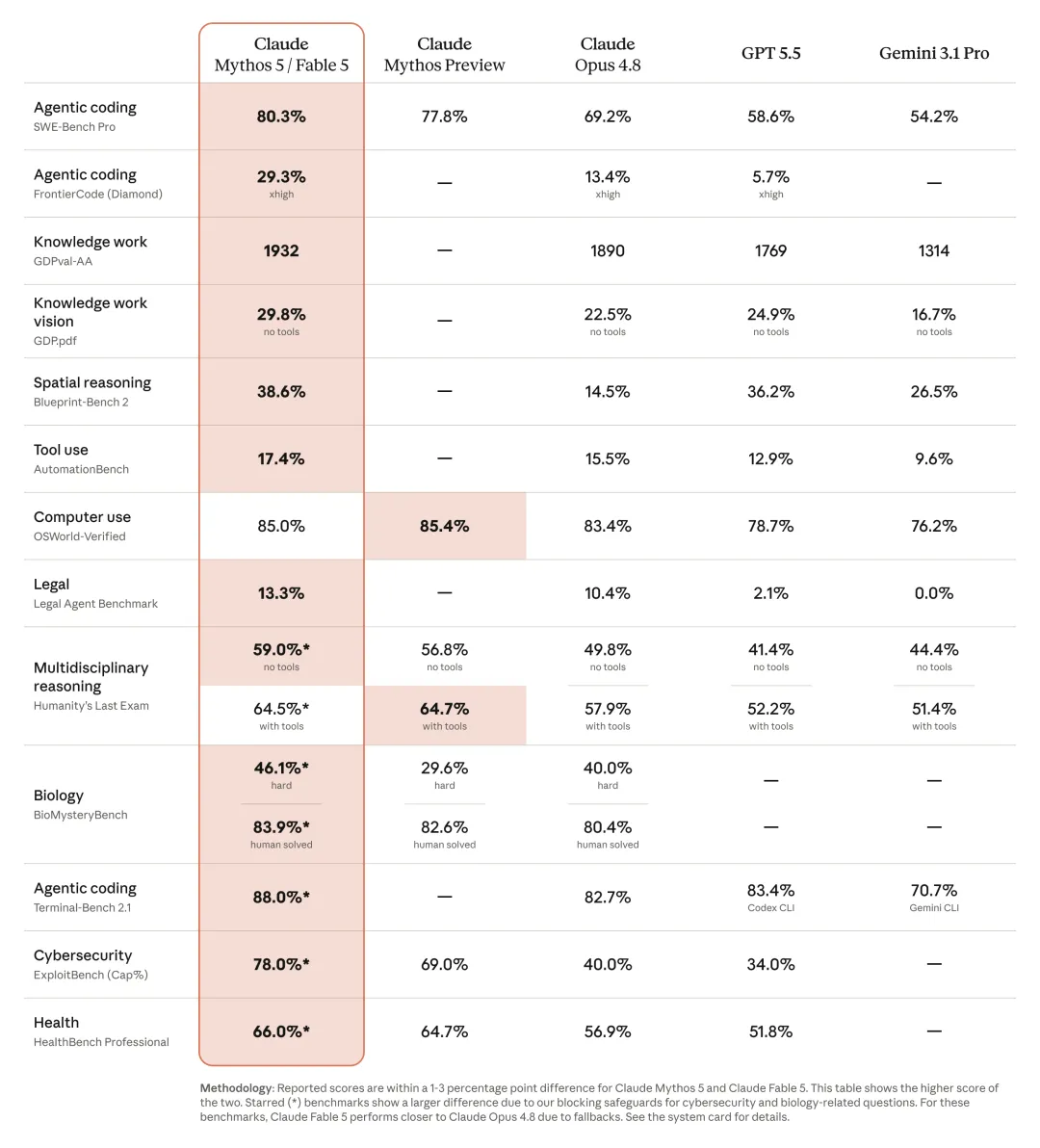
Anthropic 官方模型能力对比图。Fable 5 / Mythos 5 被放在同一列展示,强调它们是同一底层能力的不同访问形态。
官方最值得注意的不是“跑分领先”,而是这句话:
❝The longer and more complex the task, the larger Fable 5’s lead over our other models.
❞
这和 Lance 的文章完全对上。Fable 5 的优势不是短问答,而是长任务里的持续推进、纠错、记忆和工具使用。
官方还提到 Fable 5 / Mythos 5 能比之前任何 Claude 模型更长时间自主工作,能力覆盖软件工程、知识工作、视觉、memory、生命科学等领域。
几个官方例子也很夸张:
Stripe 早测反馈:在 5000 万行 Ruby codebase 中,Fable 5 一天完成原本一个团队手工超过两个月的 codebase-wide migration。 Cognition FrontierCode:Fable 5 在 frontier models 中得分最高。 Memory and long-context:在百万 token 长任务中保持专注,并使用自己的 notes 改进输出。 Slay the Spire 示例:持久文件记忆对 Fable 的 performance 提升是 Opus 4.8 的 3 倍。
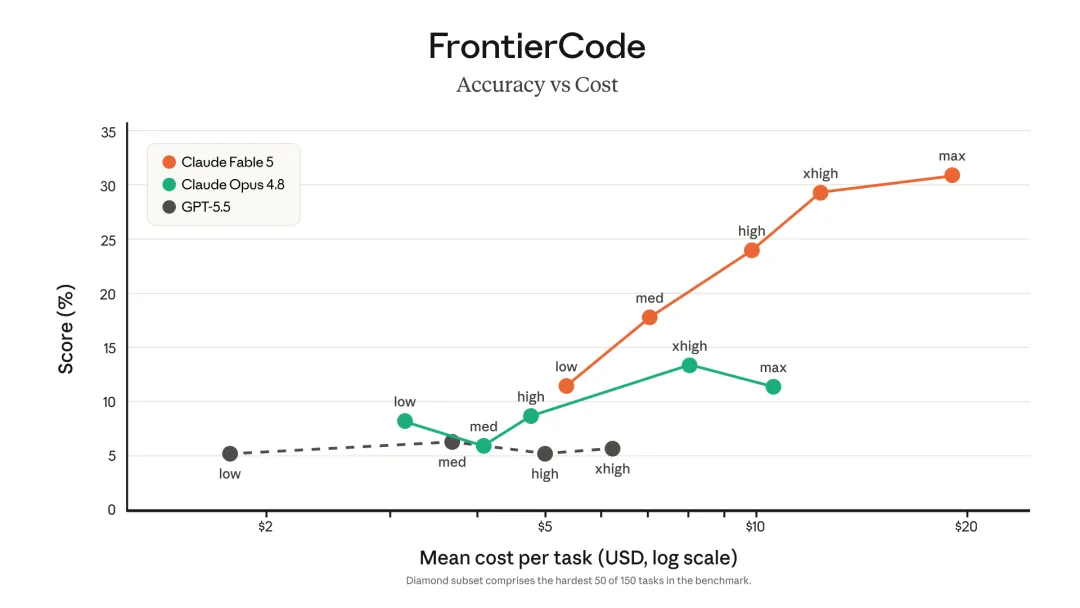
官方图表强调 Fable 5 / Mythos 5 在长任务、Agentic coding、工具使用和专业任务上的优势。
但这次发布也有一个重要背景:安全。
Anthropic 明确说,Mythos-class 模型在 cybersecurity 等领域能力很强,可能被误用。因此 Fable 5 上线时带有 safeguards。对 cybersecurity、biology/chemistry、distillation 等请求,分类器会触发 fallback,由 Claude Opus 4.8 接管。官方称超过 95% 的 Fable sessions 不会触发 fallback。
价格也公布了:每百万输入 token 10 美元,每百万输出 token 50 美元。
这个定价本身也说明了一点:长循环 Agent 不是免费的魔法。它会消耗大量 token、工具调用、sandbox 时间和验证成本。未来真正的产品差距,不只是“我接入了最强模型”,而是“我能不能用合理成本跑出可靠闭环”。
这篇文章对 Agent 产品的启发
我觉得 Lance 这篇文章最有价值的地方,是它把“Agent 能力”从模型榜单拉回到系统设计。
过去一年,很多人评价 Agent,还是在问:哪个模型更强?哪个模型写代码更好?哪个模型上下文更长?这些问题当然重要,但已经不够了。
更好的问题应该是:
任务有没有清晰的 done definition? rubric 是否具体到 grader 可以检查? grader 是否独立于 writer 的上下文? 环境是否能提供真实反馈,而不是只让模型脑补? 失败是否会被调查、验证、提炼为规则? 下一次 session 是否真的会读取这些规则? 系统是否知道什么时候该继续、什么时候该停?
如果这些问题没有答案,再强的模型也容易变成“会说话的长任务赌博机”。它会跑很久,会产出很多东西,但你不知道它是因为真的接近目标才停,还是因为它觉得自己差不多了。
Fable 5 的出现让这件事更明显。强模型会放大好系统,也会放大坏系统。你给它一个好 loop,它能自我修正、扩大实验半径、沉淀经验。你只给它一个含糊 prompt,它也可能更自信地把错误包装成完成。
写在最后:Prompt 启动模型,Loop 才让模型可托付
Lance Martin 的文章标题叫《Designing loops with Fable 5》,这个标题选得很准。
它没有叫 “Prompting Fable 5”。也没有叫 “How to use Fable 5 better”。它叫 designing loops。
这基本就是下一阶段 Agent 工程的关键词。
Prompt 仍然重要,但它越来越像启动器。真正决定长任务质量的,是后面的运行结构:goal、rubric、grader、sandbox、logs、memory、filesystem、verification、stop condition。
Parameter Golf 说明了自我纠错循环的价值。好的目标和外部评分,会逼 Agent 从小修小补走向更大胆的结构性探索。
Continual Learning Bench 说明了记忆循环的价值。好的 memory 不是历史堆积,而是从错误中提炼出下次能用的规则。
Anthropic 官方 Fable 5 发布则说明,模型公司也在往这个方向走:更强的长任务模型、更长的自主运行、更强调 memory 和 tool use,同时用 safeguards、fallback 和 trusted access 控制风险。
我的判断是:以后 Agent 产品的分水岭,不会只是“用了哪个模型”。真正的差距会越来越像操作系统和工作流引擎的差距。
谁能把任务定义、外部验证、长期记忆和环境反馈设计成稳定闭环,谁就能把模型能力转化成真正可托付的工作能力。
一句话:
「Prompt 负责启动模型,Loop 负责让模型变成系统。」
参考来源
Lance Martin X 原文:https://x.com/rlancemartin/status/2064397389189071163 Anthropic:Claude Fable 5 and Claude Mythos 5:https://www.anthropic.com/news/claude-fable-5-mythos-5 Claude Fable 官方页:https://www.anthropic.com/claude/fable Claude Managed Agents / Define outcomes:https://platform.claude.com/docs/en/managed-agents/define-outcomes Claude Cookbook / Outcomes verifier:https://platform.claude.com/cookbook/managed-agents-cma-verify-with-outcome-grader OpenAI Parameter Golf repo:https://github.com/openai/parameter-golf OpenAI Parameter Golf 复盘:https://openai.com/index/what-parameter-golf-taught-us/ Continual Learning Bench:https://continual-learning-bench.com/
