 夜雨聆风
夜雨聆风一、实验目的与核心价值
本次实验的核心目标是基于已加工完成的用户画像统计表,利用助睿Max平台完成“浏览器用户画像分析”大屏的静态布局设计。实验不仅要求掌握大屏搭建的技术操作,更强调站在“数据产品”的角度,理解如何将抽象的用户人口属性数据,转化为更为直观数据大屏。
核心价值在于回答一系列关键业务问题:
目标用户是谁(年龄、性别、职业)? 用户的教育与收入水平如何? 用户的地理分布在哪里? 不同浏览器的用户画像是否存在差异?
实验环境:
实验平台:助睿在线实验平台 可视化工具:助睿Max(数据大屏)
二、业务问题与分析维度
三、整体设计方案与模块构成
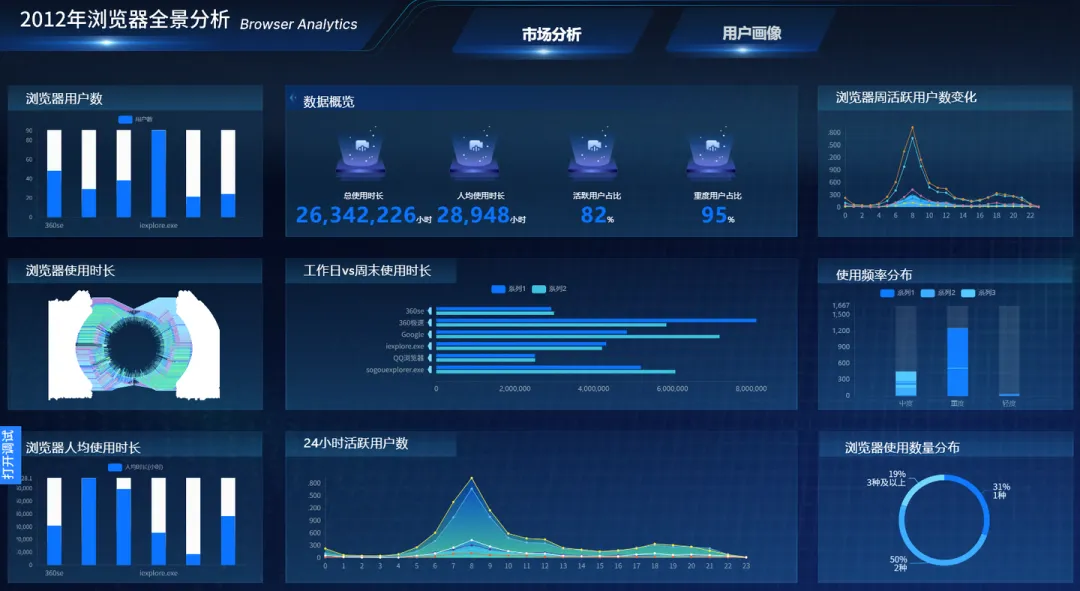
本次大屏设计遵循“信息层次清晰、分析逻辑连贯”的原则,整体分为五大分析模块,并搭配筛选器实现交互探索:
- 数据概览模块(核心指标卡)
:展示覆盖用户数、平均年龄、本科以上占比、中高收入占比四个关键指标,快速勾勒用户群的规模与基本轮廓。 - 基本信息模块(饼图/柱状图/条形图)
:包括性别分布、年龄分布、学历分布、职业分布、收入分布。针对不同维度特点选择合适图表——性别用饼图突出比例;年龄、职业、收入用柱状图便于横向对比;学历名称较长则采用横向条形图提升可读性。 - 地域分布模块(地图+列表)
:以中国地图(区域热力层)直观展示用户省份分布的空间热点与空白区域,辅以“用户数TOP5省份”轮播列表,弥补地图难以精确读数的不足,实现“看趋势”与“读数值”的互补。 - 居住地类型模块(轮播饼图)
:分析城市、城郊、乡村用户的结构占比,为差异化市场策略提供依据。 - 交互筛选模块(下拉多选)
:支持按单个、多个或全部浏览器进行筛选,使大屏从静态展示变为可探索的分析工具,便于对比不同浏览器用户的画像差异。
- 整体效果预览:
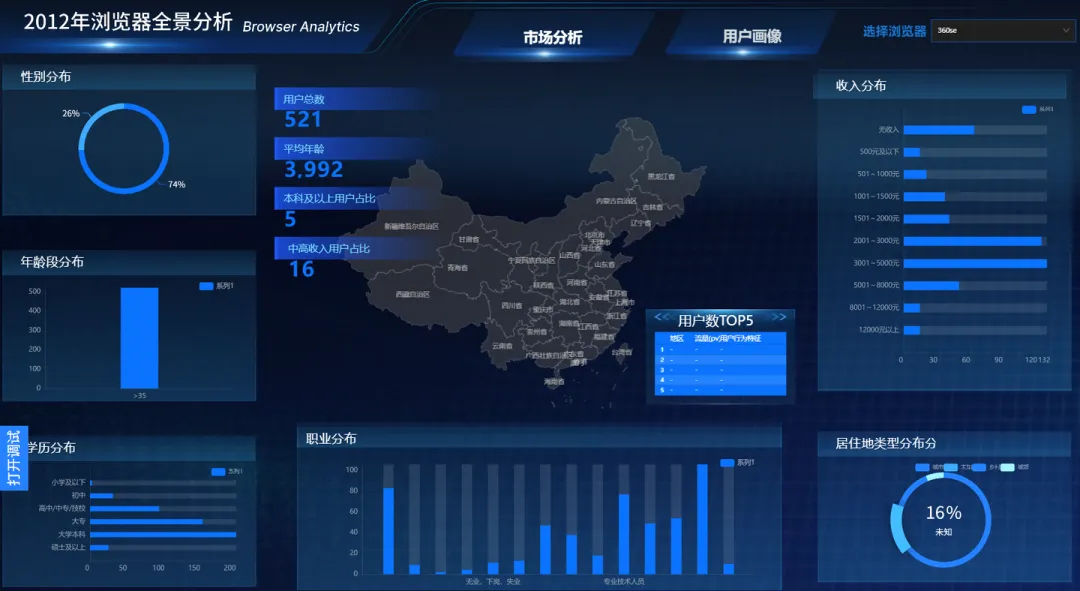
四、具体实验步骤
1.打开之前已完成“市场分析”大屏的项目文件。
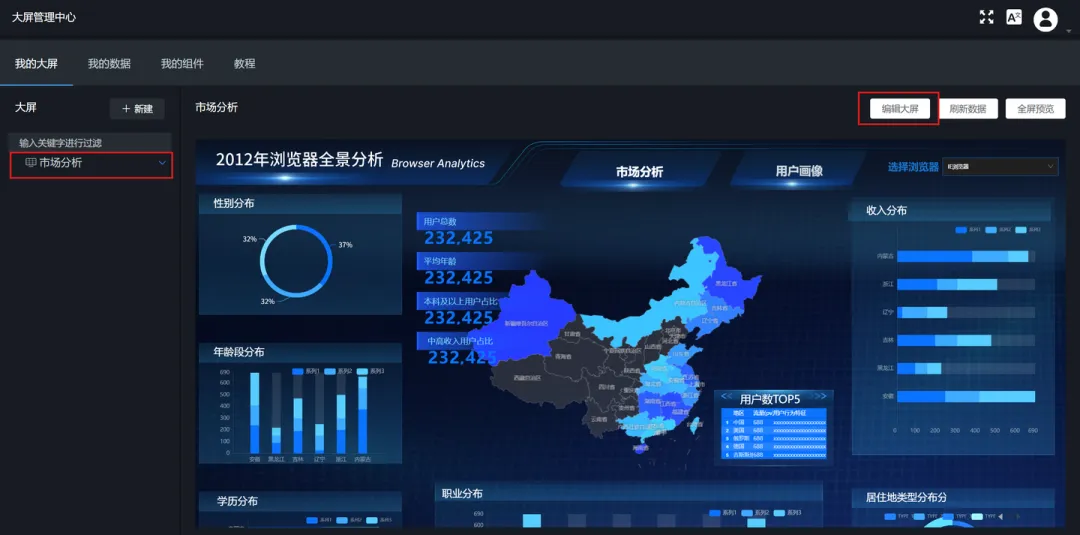
2.使用图层管理功能,将“市场分析”大屏的所有组件选中并整体复制。
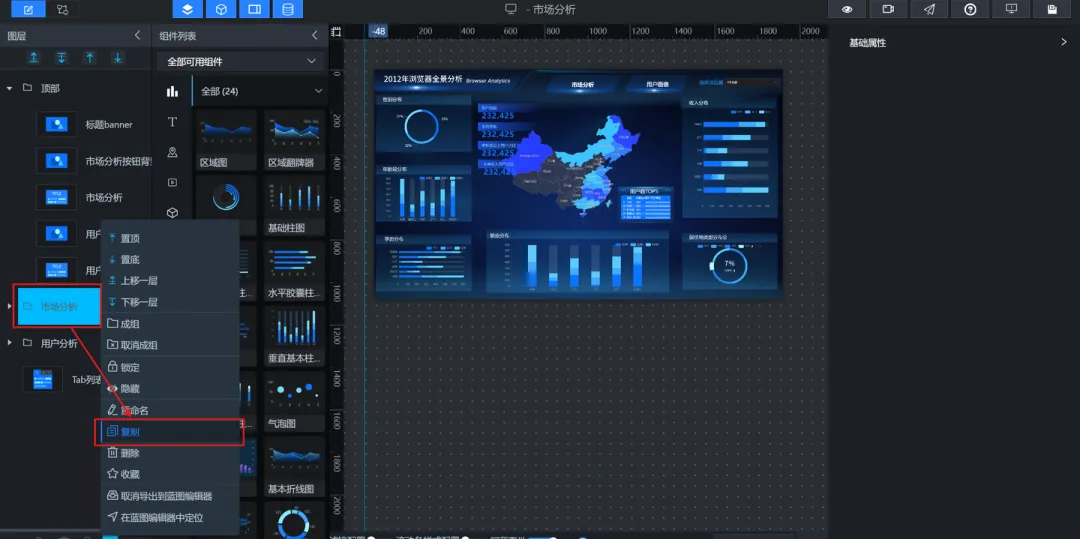
3.将复制得到的组件组重命名为“用户画像分析”,将“市场分析”组件隐藏,我们针对“用户画像”,逐步添加和布局本次实验所需的组件。
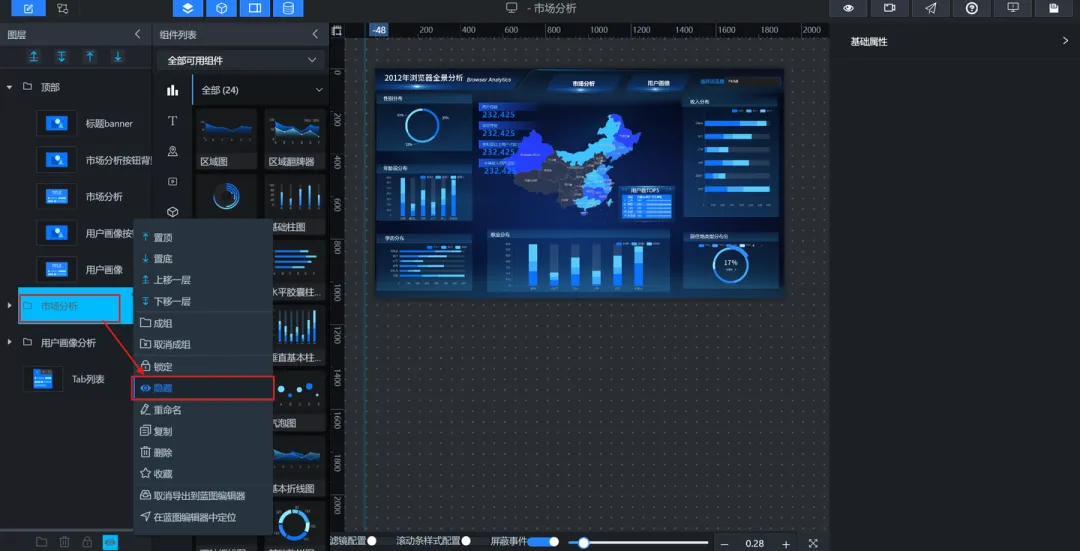
接下来我们正式开始几个小板块的设计:位置和大小可自行参照调整,下边不一一展示噢!
1)用户省份分布(地图→基础平面地图):在“子组件管理中”选择“区域热力层”
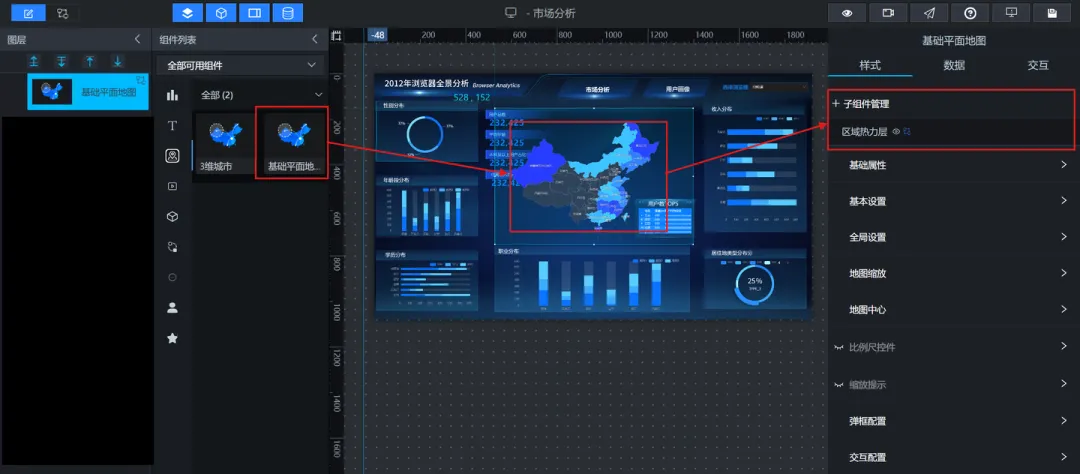
2)核心指标:参考图片添加4个“数字翻牌器”纵向排列,设置标题和数值样式,用“单张图片”设置标题背景
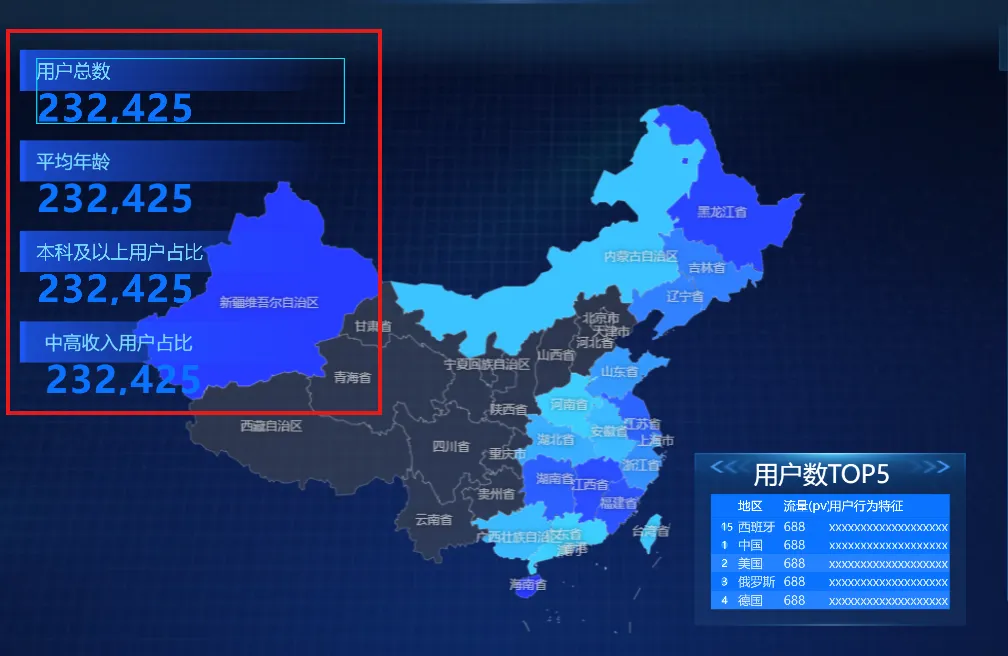
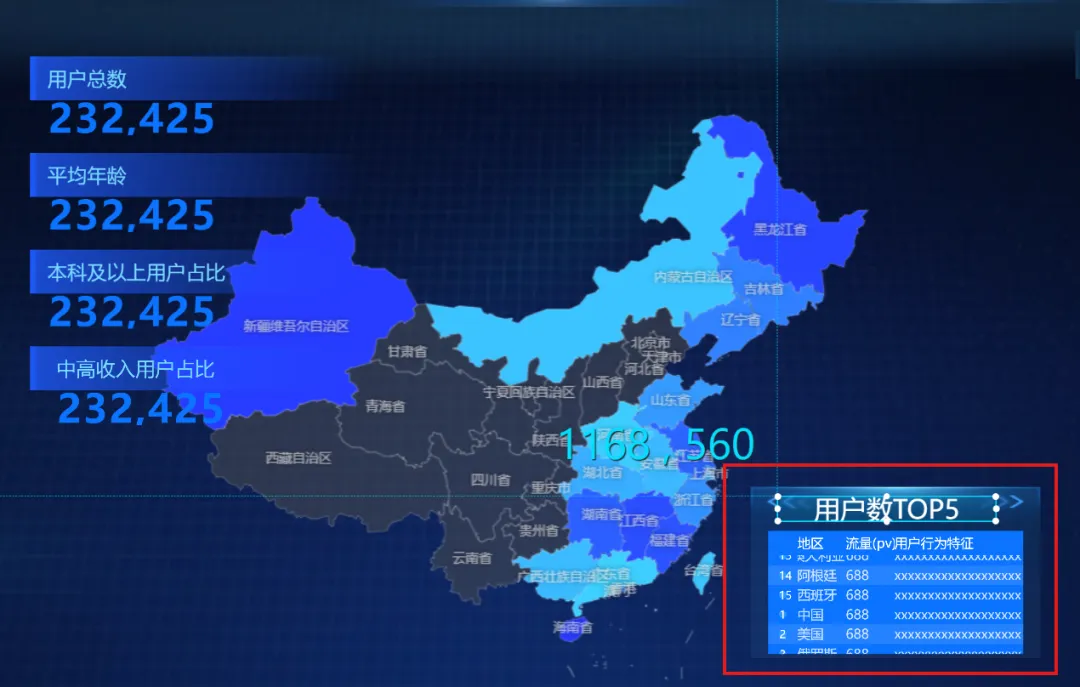
3)用户数TOP5省份排行榜(轮播列表):
①添加“单张图片”组件,作为排行榜区域背景
②添加“通用标题”组件,作为排行榜标题
③添加“轮播列表”组件,作为排行榜主体
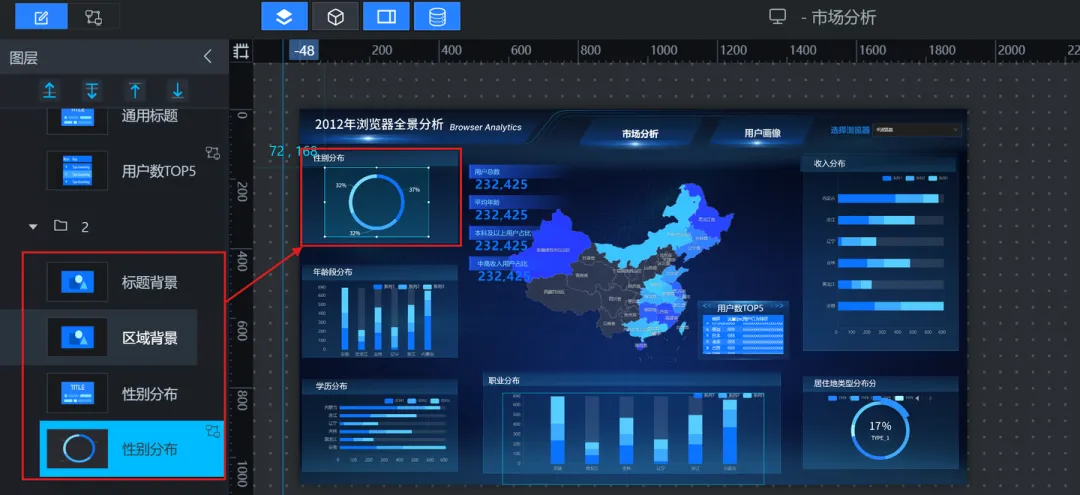
4)性别分布(基础饼图):
①使用“单张图片”组件设置区域背景,并设置好标题
②添加“基础饼图”组件,调整大小和位置
5)年龄段分布(基础柱图):
①使用“单张图片”组件设置区域背景,并设置好标题
②助睿Max 支持多种柱状图:基础柱图、弧形柱图、水平基础柱图、水平胶囊柱图等,这里我们使用基础柱图进行展示
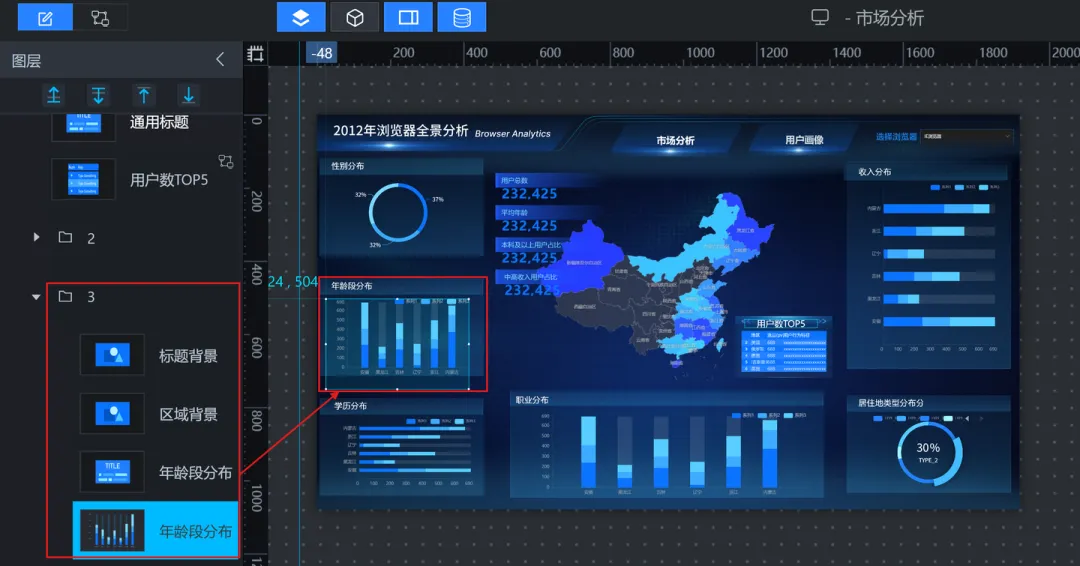
6)学历分布(水平基础柱图):
①使用“单张图片”组件设置区域背景,并设置好标题
②这里我们使用助睿Max 的水平基础柱图
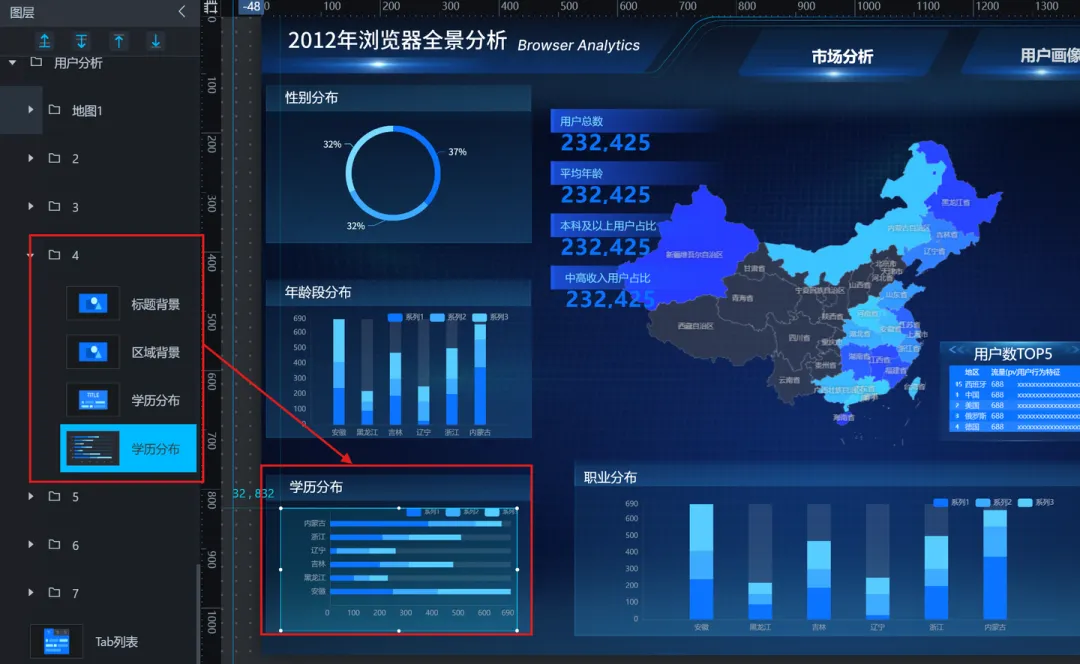
7)职业分布(基础柱图):
①使用“单张图片”组件设置区域背景,并设置好标题
②这里我们使用助睿Max的基础柱图
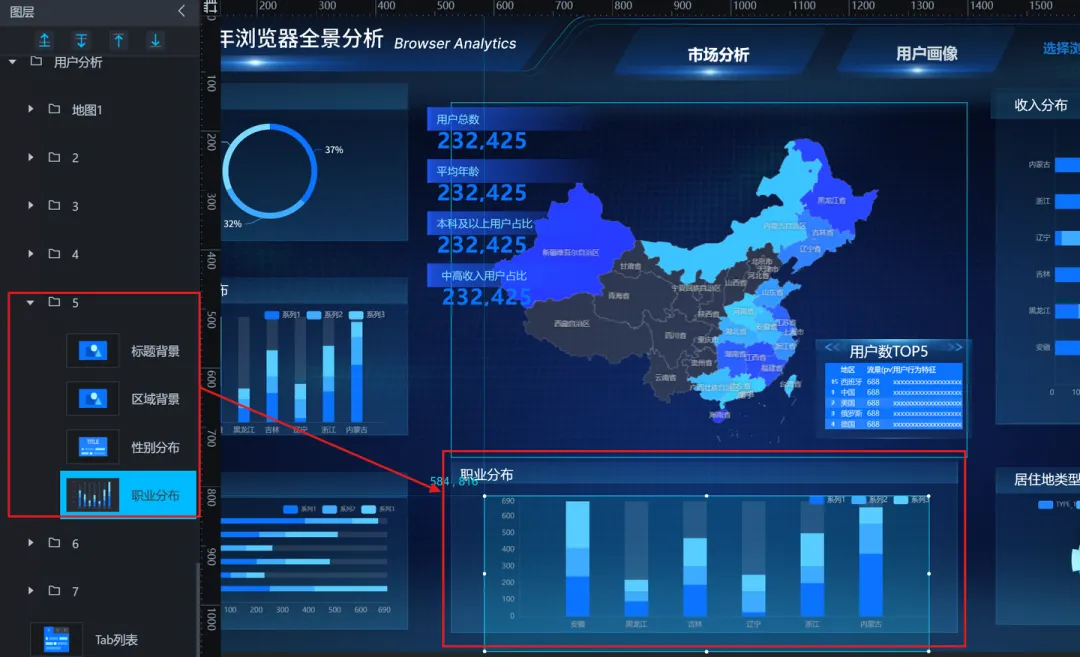
8)收入分布(水平基础柱图):
①使用“单张图片”组件设置区域背景,并设置好标题
②这里我们使用助睿Max 的水平基础柱图
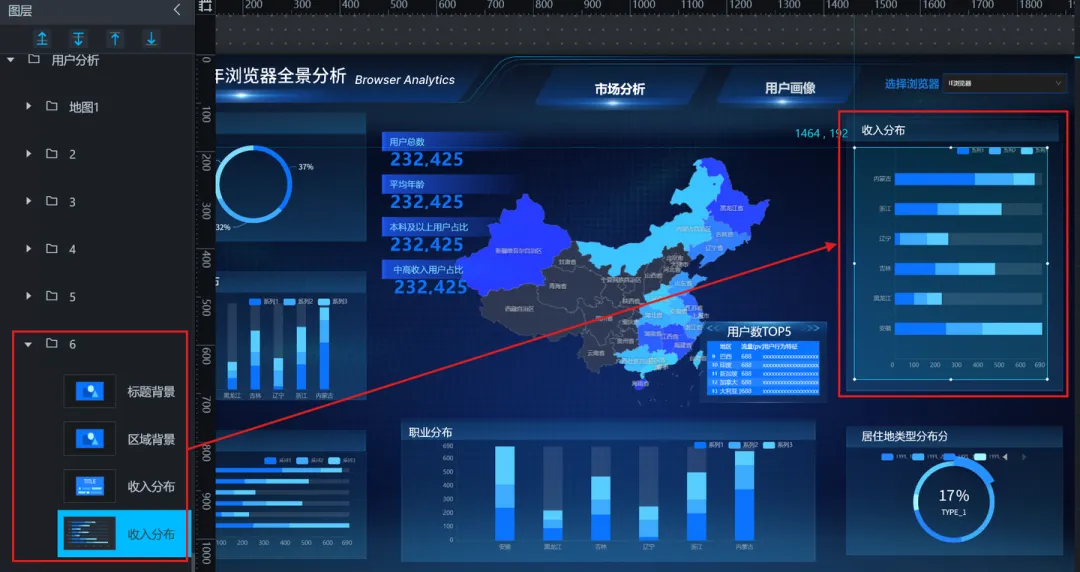
9)居住地类型分布(轮播饼图):
①使用“单张图片”组件设置区域背景,并设置好标题
②为了使大屏可视化效果更丰富,这里我们使用助睿Max 的轮播饼图
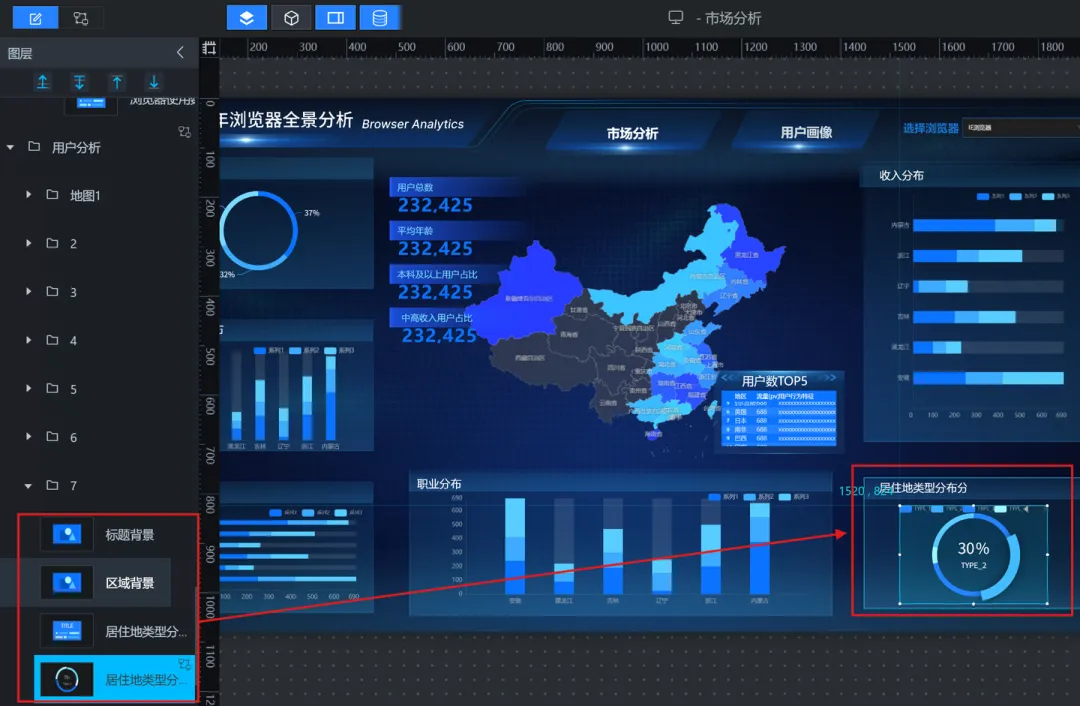
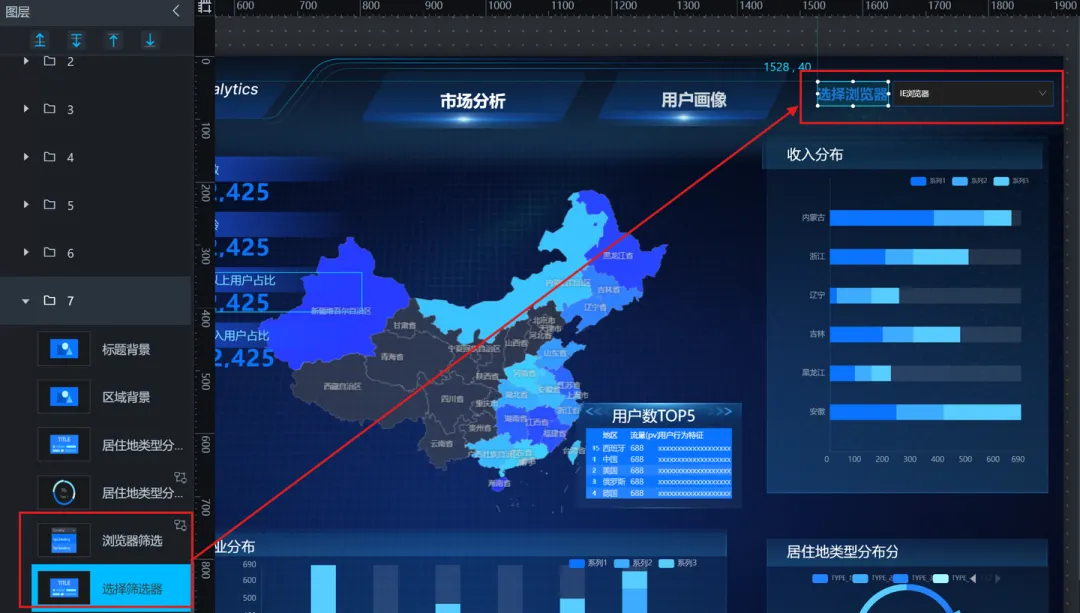
10)筛选器(下拉选择组件):
支持按不同浏览器进行对比分析。通过筛选器,用户可以:
查看全部浏览器用户的整体画像(默认视图),了解产品大盘用户特征; 选择单个浏览器(如 Chrome、IE、360 等),聚焦该浏览器用户的画像,回答“使用 Chrome 的用户与其他用户有什么不同?”; 选择多个浏览器进行对比,直观比较不同浏览器用 户画像情况
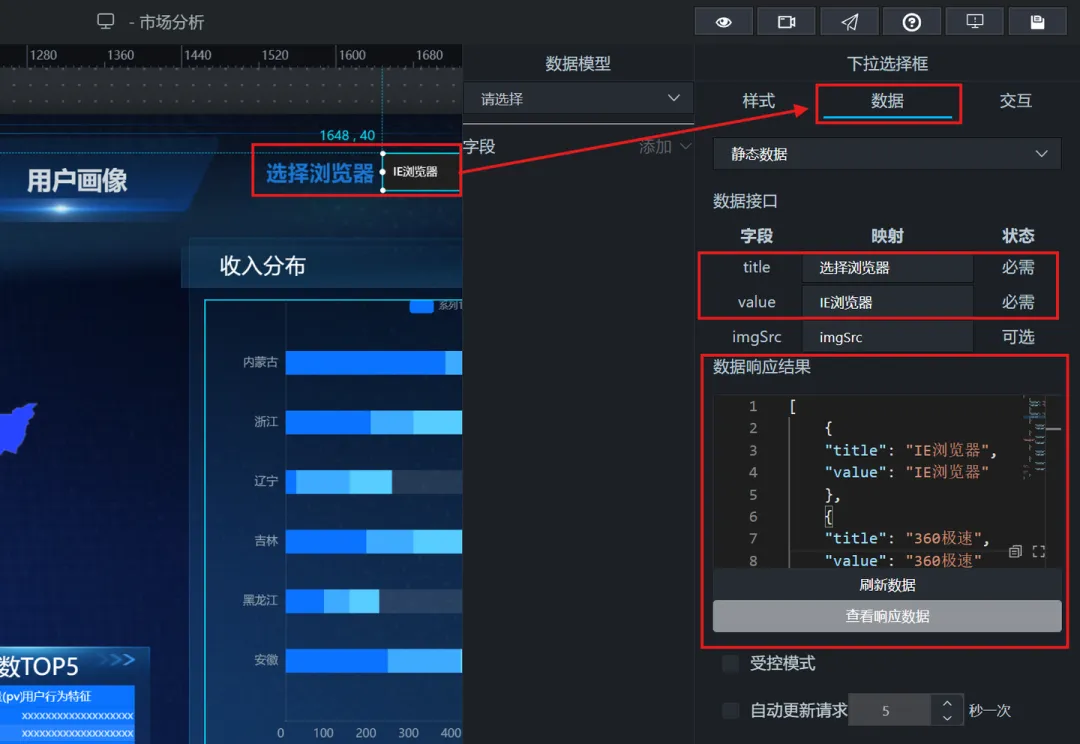
【下拉选择框的数据属性设置用于蓝图编辑器中,后边将基于这6个静态数据实现组件交互!!】
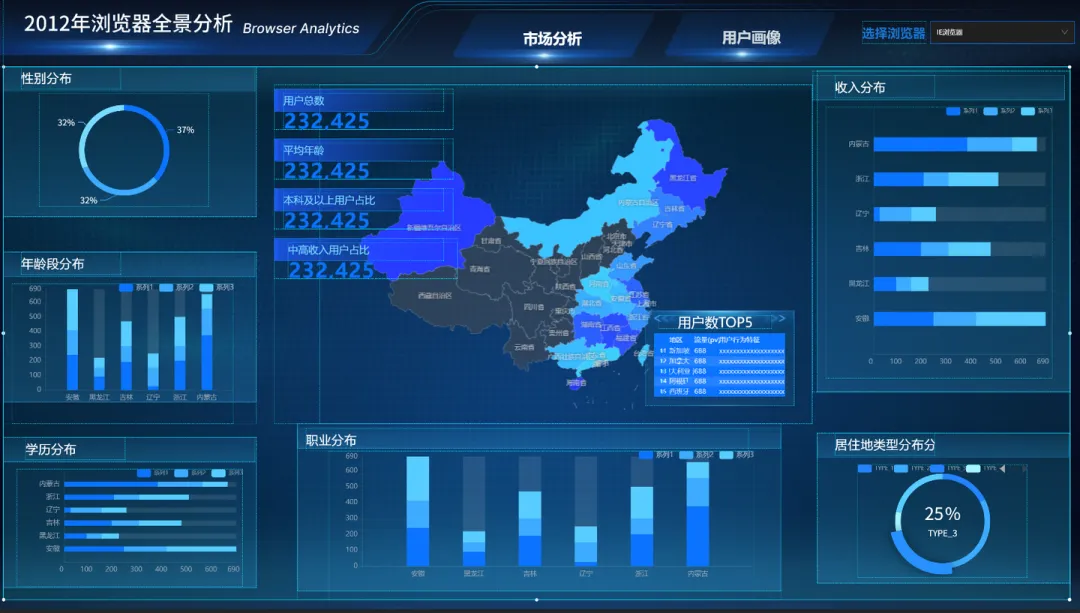
到这里,我们就完成了所需的10个小模块的静态设计,下边是整体的效果展示。
五、数据接入——使用蓝图编辑器
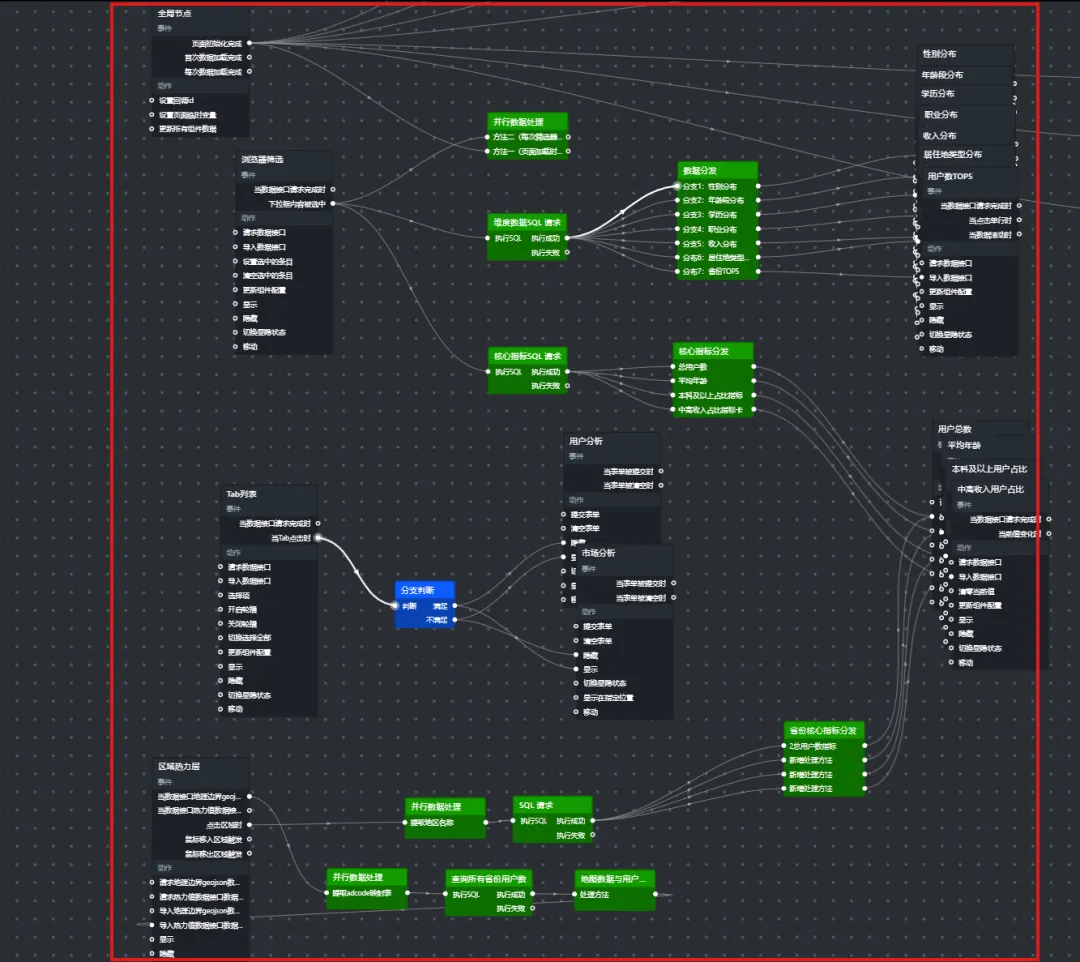
1. 整体设计流程
1)页面加载或用户选择浏览器 → 触发两个SQL请求:
维度数据SQL:查询性别、年龄、学历、职业、收入、居住地类型、省份分布。 核心指标SQL:查询总用户数、平均年龄、本科及以上占比、中高收入占比。
2)浏览器筛选器 → 将选中的浏览器值传递给两个SQL请求节点。
维度数据分发:通过一个并行数据处理节点,按 dimension_type分发到各个图表。核心指标分发:通过另一个并行数据处理节点,将单行多列的指标数据拆分为四个独立数值,分别发送给四个指标卡。
3)各图表组件接收数据并展示。
2.整体设计流预览:
3.前期准备
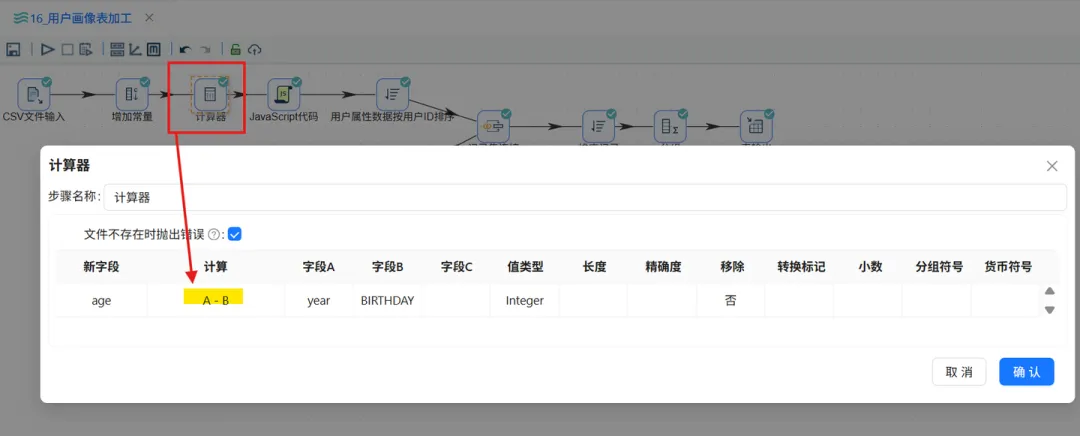
由于在数据大屏中,我们需要展示平均年龄这一核心指标,为了更准确地计算平均年龄,我们需要在 user_profile_stats表中增加一个age字段。
3.1 修改目标表的结构
使用“执行一个SQL脚本”修改原有的表结构,增加age字段。
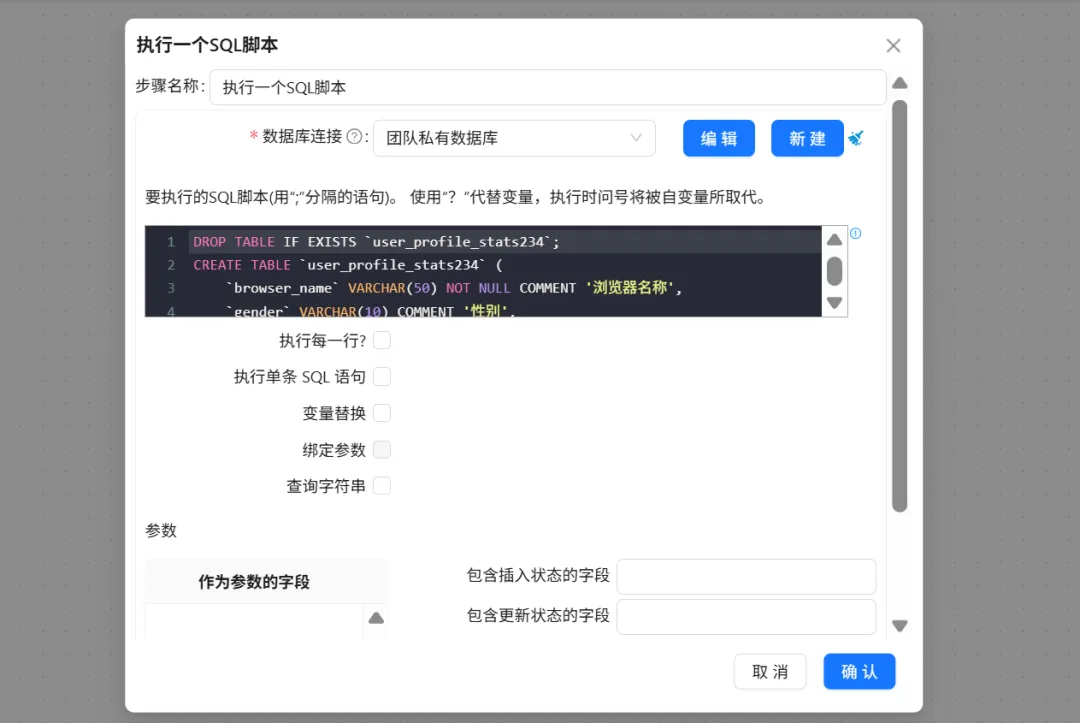
这一步执行的SQL语句如下:
DROP TABLE IF EXISTS `user_profile_stats`;
CREATE TABLE `user_profile_stats` (
`browser_name` VARCHAR(50) NOT NULL COMMENT '浏览器名称',
`gender` VARCHAR(10) COMMENT '性别',
`age` INT NOT NULL COMMENT '年龄',
`age_group` VARCHAR(10) COMMENT '年龄段',
`edu` VARCHAR(50) COMMENT '学历',
`job` VARCHAR(50) COMMENT '职业',
`income` VARCHAR(50) COMMENT '收入',
`city_type` VARCHAR(10) COMMENT '居住地类型',
`province` VARCHAR(50) COMMENT '省份',
`user_count` INT NOT NULL COMMENT '用户数'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户画像统计表';
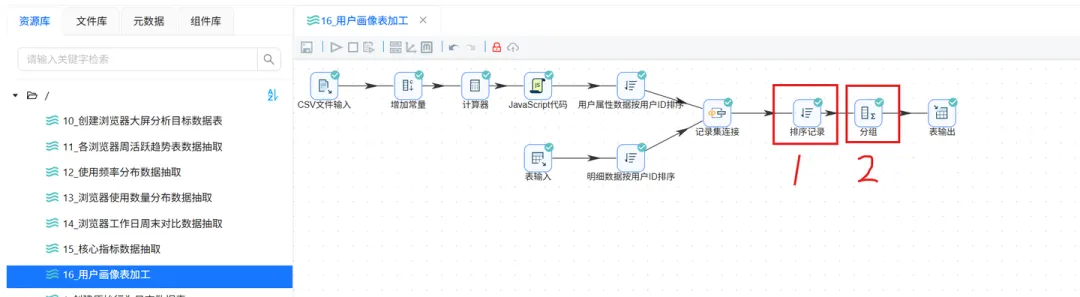
3.2 修改原“用户画像表加工”转换流
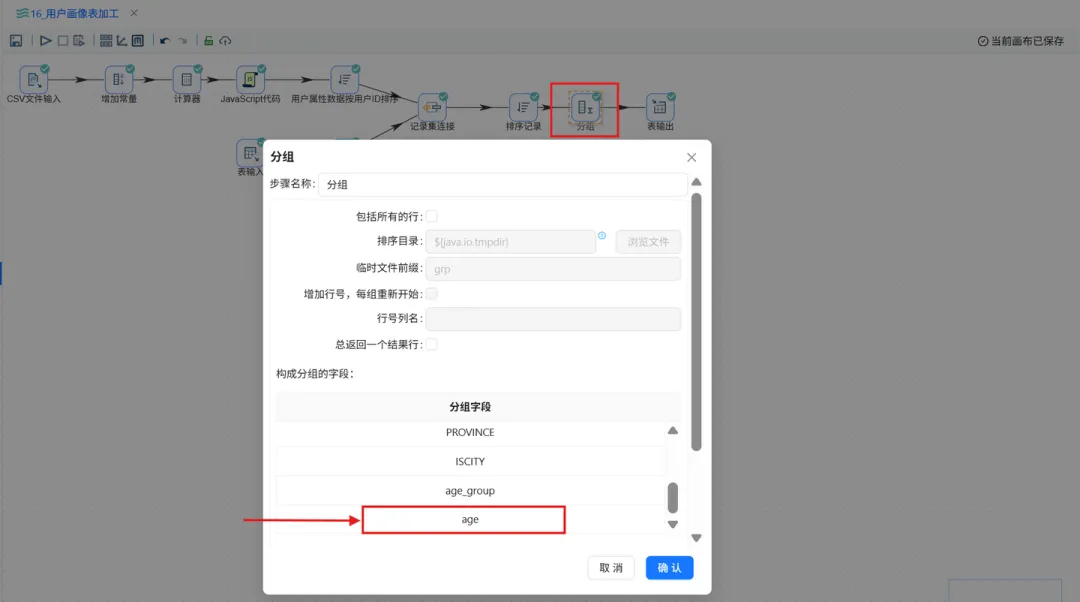
① 修改排序记录组件,增加 age 字段的升序排序
② 修改分组组件,分组字段更加 age
③ 执行转换流
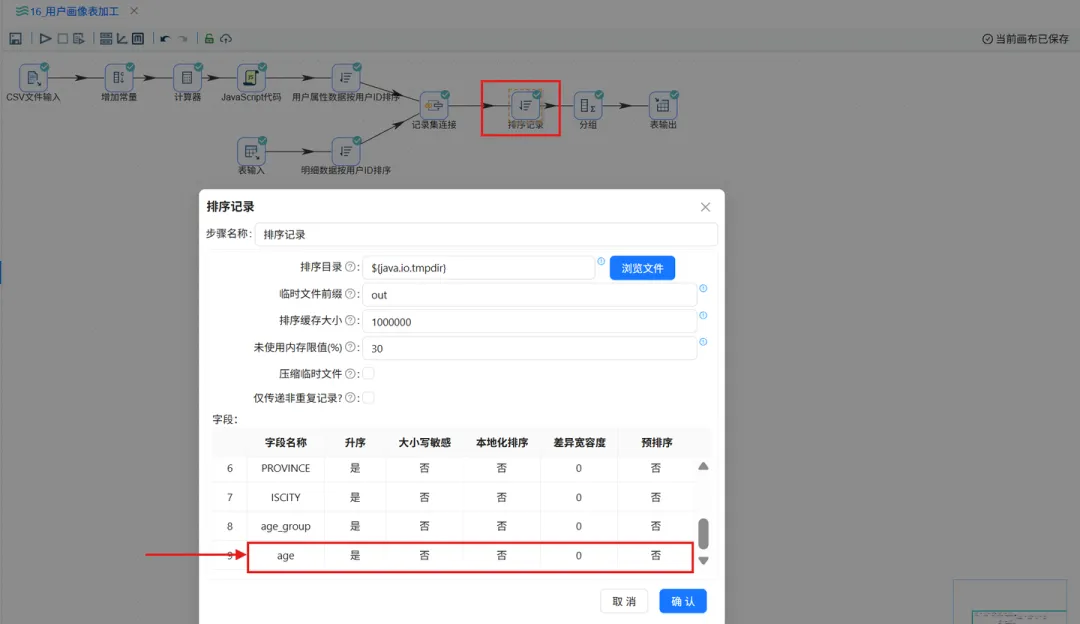
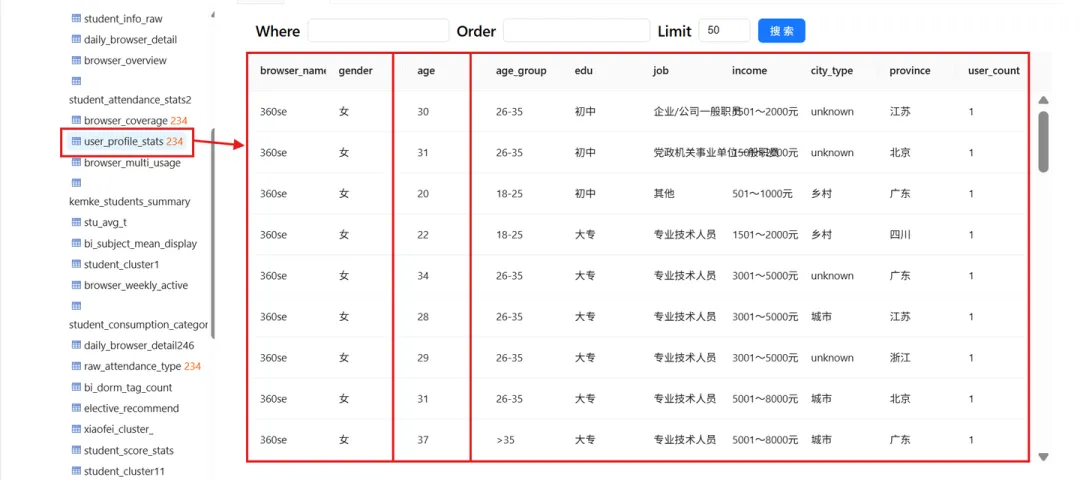
查看得到的数据表,检查age字段是否已经成功显示。(tips:若数据异常可排查计算器组件的配置,“计算”属性值可能会发生丢失,运行前记得检查一下噢!)
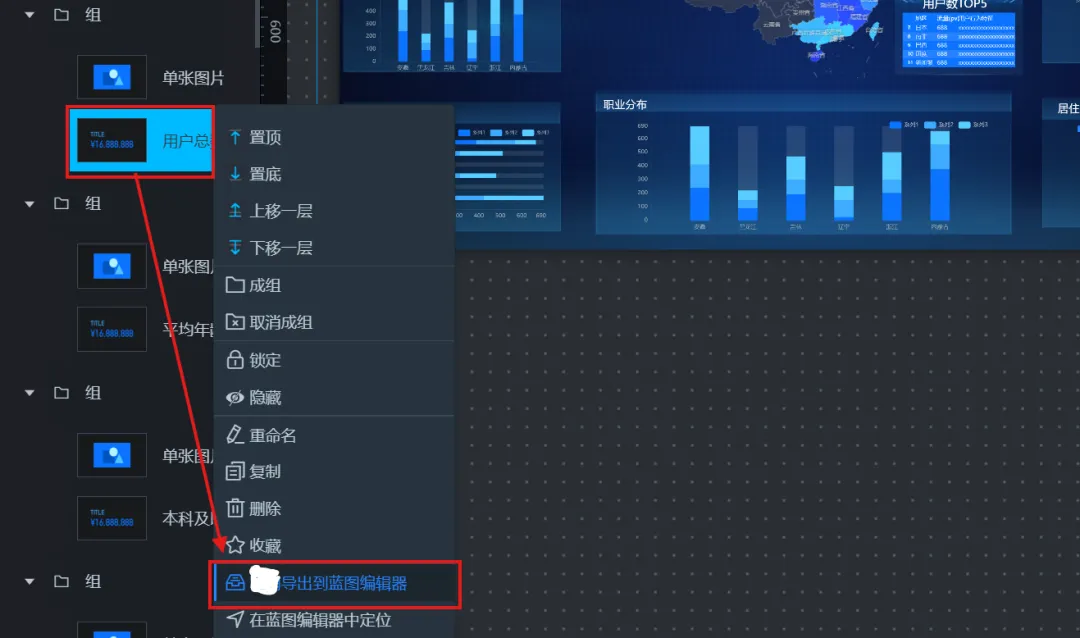
4.组件导出到蓝图编辑器
当组件导入到蓝图编辑器后,才可以为该组件配置交互和接入数据,所以我们需要将标签卡、各数据表和热力图等导出到蓝图编辑器中(注意:本次实验中基本平面地图自身不需要导出,导出的是它的 “区域热力层” 噢!)。 其他组件正常导出到蓝图编辑器即可:(演示时我已导出,大家操作时右键点击“导出到蓝图编辑器”即可)
接下来切换到蓝图编辑器,最终我们需要导出的组件可以参考下图:
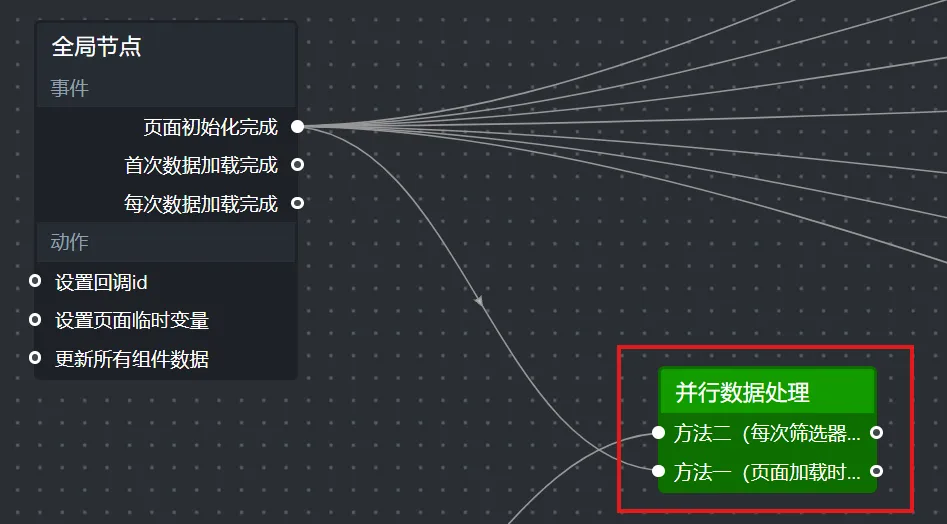
5.添加浏览器参数接收节点(并行数据处理)
大屏上的浏览器筛选器让用户可以选择某个具体的浏览器。当用户切换选择时,地图、饼图、柱状图等所有图表的数据都需要跟着变。实现联动的这个节点就是“浏览器参数接收”,它用“并行数据处理”组件来实现。
5.1 双击节点,添加两个处理方法
// 方法一(页面加载时执行一次,设置基础URL)
const BASE_URL = 'https://lab.guilian.cn'; window.GLOBAL_BASE_URL = BASE_URL; return data;
// 这个方法主要是为后续可能用到的外部API预留一个基础地址,本实验用不上,但保留结构。
// 方法二(每次筛选器变化时执行,接收浏览器参数)
const SELECTED_BROWSER = data.value; window.GLOBAL_SELECTED_BROWSER = SELECTED_BROWSER; return { value: SELECTED_BROWSER };
// 这个方法把用户选中的浏览器存到 window.GLOBAL_SELECTED_BROWSER 这个全局变量里。后面的SQL请求节点只要读取这个变量,就知道该查哪个浏览器的数据了。
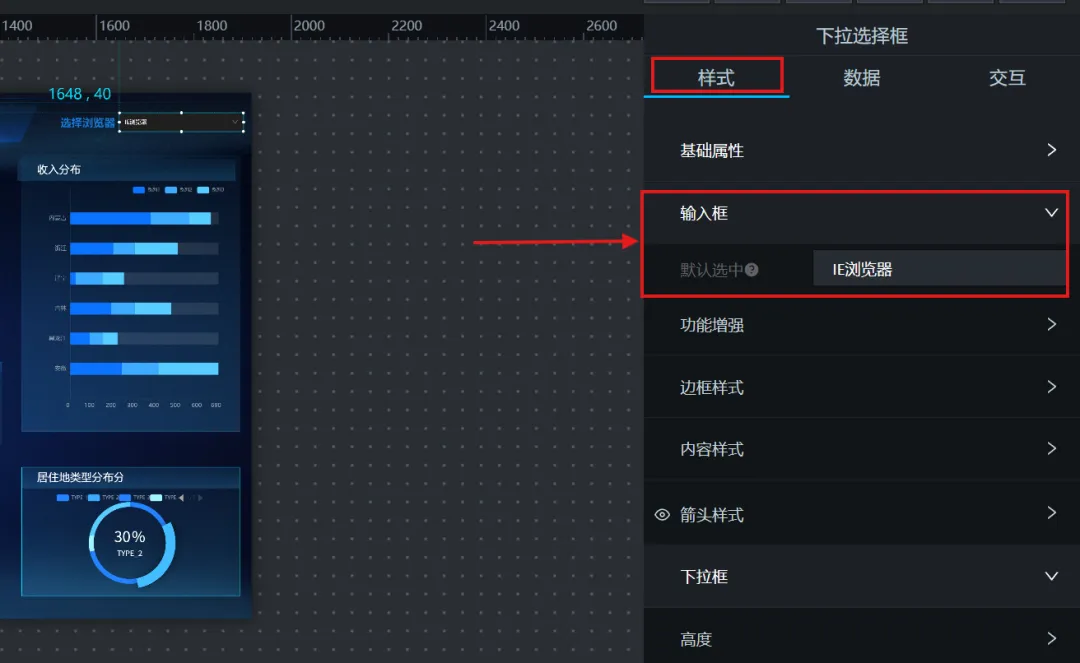
5.2 在画布编辑器中补全“下拉选择框”组件的配置
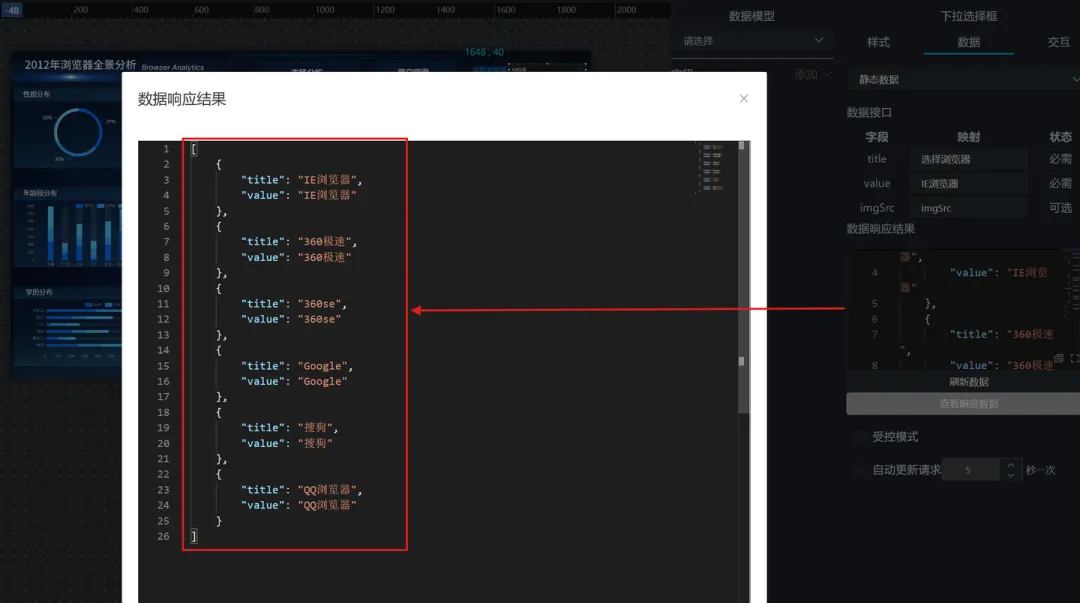
其中,浏览器的选项我们可以直接使用静态数据(因为个数不多):title为前端显示内容,value为实际查询内容,即数据库中存储的对应 browser_name,如:{ "title": "IE浏览器", "value": "IE浏览器" }(有多个值时用“[]”框起来,用“,”分割) 填写6个浏览器的对应内容,并刷新数据,同时,输入框中默认选中设置为“IE浏览器”
6.添加维度数据SQL请求(SQL请求)
【!!!注意:所有SQL查询语句都需要将from修改为自己的数据库表!!!】
这个节点负责查询性别、年龄、学历、职业、收入、居住地类型、省份等维度数据,使用 UNION ALL合并,输出格式为(dimension_type, name, value)。
添加“SQL请求”节点,重命名为“维度数据SQL请求”,查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 1.性别分布
select
'gender' as dimension_type,
gender as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by gender
union all
-- 2.年龄段分布
select
'age' as dimension_type,
age_group as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by age_group
union all
-- 学历分布
select
'edu' as dimension_type,
edu as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by edu
union all
-- 3.职业分布
select
'job' as dimension_type,
job as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by job
union all
-- 4.收入分布
select
'income' as dimension_type,
income as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by income
union all
-- 5.居住地类型分布
select
'city_type' as dimension_type,
city_type as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by city_type
union all
-- 6.省份分布
select
'province' as dimension_type,
province as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
group by province
`;
return sql
7.添加核心指标SQL请求(SQL请求)
只查询四个核心指标,输出单行多列格式(一行包含四个字段),不需要 UNION ALL,取值更简单。
添加“SQL请求”节点,重命名为“核心指标SQL请求”,查询SQL如下:
// 从全局变量获取选中的浏览器值
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
let sql = `
-- 核心指标(总用户数、平均年龄、本科及以上占比、中高收入占比)
select
'total_users' as name,
sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
union all
select
'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 1) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}'
`;
return sql
8.添加维度数据分发节点(并行数据处理)
基于上一步SQL查出来的是一张包含所有维度数据的大表,但每个图表只需要其中一部分,所以需要一个分发节点,把数据按 dimension_type拆开,分别送给对应的图表。这个节点也用“并行数据处理”来实现。
8.1 添加“并行数据处理”节点,重命名为“数据分发”。将SQL请求节点的“执行成功”连接到该节点。
8.2 双击节点,为每个图表添加一个处理方法
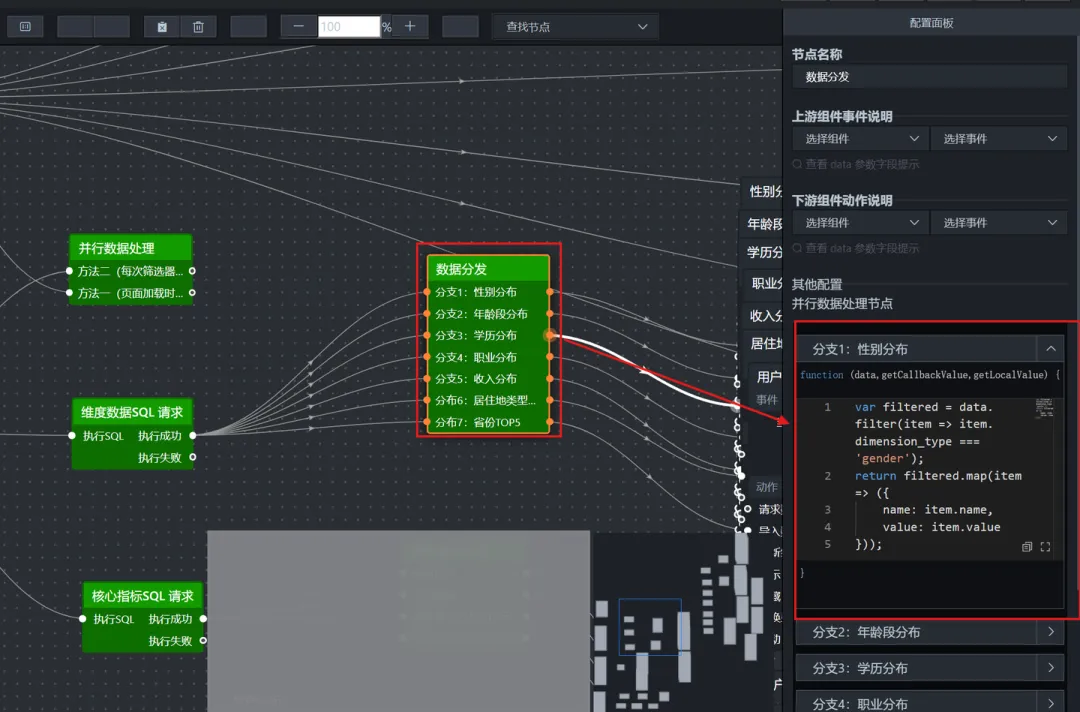
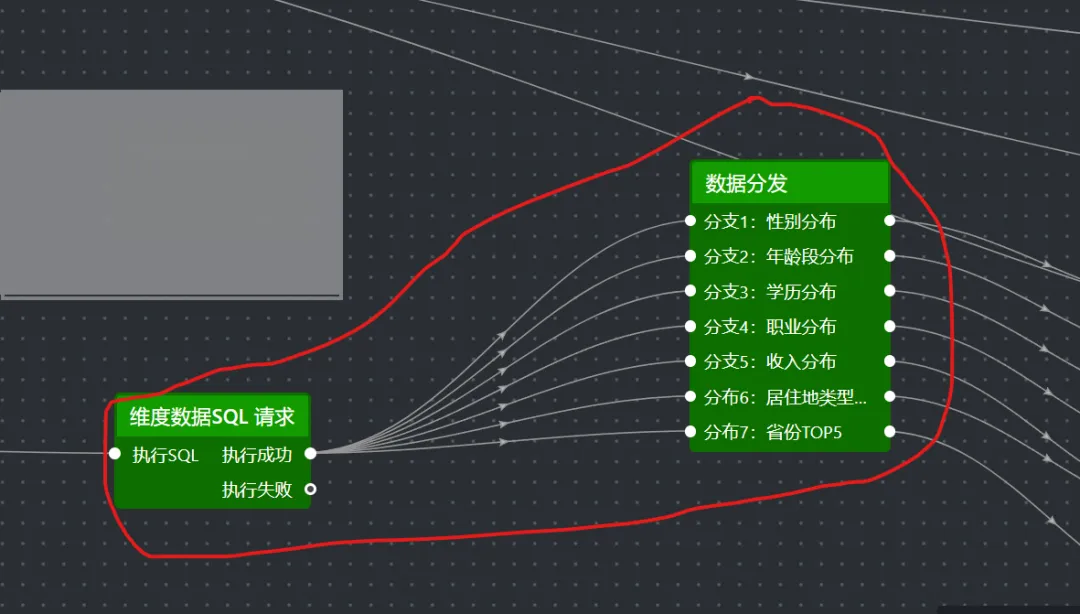
具体处理方法脚本如下:
分支1:性别分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'gender');
return filtered.map(item => ({
name: item.name,
value: item.value
}));
分支2:年龄段分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'age');
var order = ['<18', '18-25', '26-35', '36-45', '>45'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '用户数'
}));
分支3:学历分布(条形图)
var filtered = data.filter(item => item.dimension_type === 'edu');
var order = ['小学及以下', '初中', '高中/中专/技校', '大专', '大学本科', '硕士及以上'];
filtered.sort((a, b) => order.indexOf(a.name) - order.indexOf(b.name));
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '学历'
}));
分支4:职业分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'job');
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '职业'
}));
分支5:收入分布(柱状图)
var filtered = data.filter(item => item.dimension_type === 'income');
// 按收入金额升序排序(提取数字进行比较)
filtered.sort((a, b) => {
// 提取收入段中的最小金额
var getMinIncome = (incomeStr) => {
// 处理 "无收入"、"500元及以下" 等特殊情况
if (incomeStr === '无收入') return -1;
if (incomeStr === '500元及以下') return 0;
// 提取数字,如 "1501~2000元" 提取 1501
var match = incomeStr.match(/(\d+)/);
return match ? parseInt(match[1]) : 999999;
};
return getMinIncome(a.name) - getMinIncome(b.name);
});
return filtered.map(item => ({
x: item.name,
y: item.value,
s: '收入'
}));
分支6:居住地类型分布(饼图)
var filtered = data.filter(item => item.dimension_type === 'city_type');
return filtered.map(item => ({
name: item.name === 'unknown' ? '未知' : item.name,
value: item.value
}));
分支7:省份排行榜TOP5
/ 过滤出省份数据
var filtered = data.filter(item => item.dimension_type === 'province');
// 按用户数降序排序
filtered.sort((a, b) => b.value - a.value);
// 取前5条
var top5 = filtered.slice(0, 5);
// 直接返回组件需要的字段名
return top5.map(item => ({
province: item.name,
user_count: item.value
}));
以上的输出结果不正确的话,可以在最终输出结果的节点的处理方法代码中添加以下代码,查看返回的数据:
// console.log("返回的数据",data)9.添加核心指标分发节点(并行数据处理)
同样地,通过“并行数据处理”节点,我们按 name 字段过滤,将每个指标单独输出给对应指标卡。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');
return [{ value: item ? item.value : 0 }];
其他分支类似,参照指标数据的定义,只需修改 item.name === 'total_users'的条件即可
10.连接节点并保存预览
根据我们的需求和设计框架,参照下图完成组件间的连线
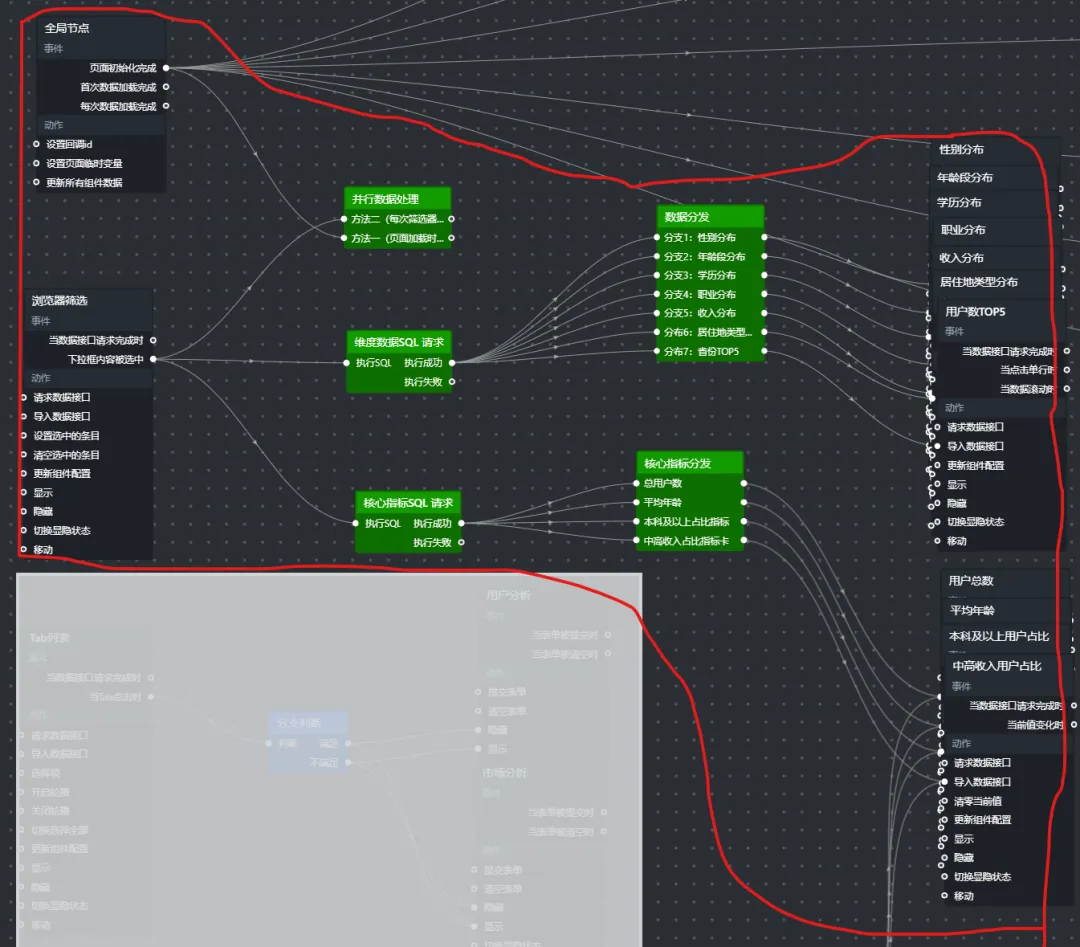
预览效果:(所有组件应该正常显示,我的热力图和排行榜部分仍需排查问题)
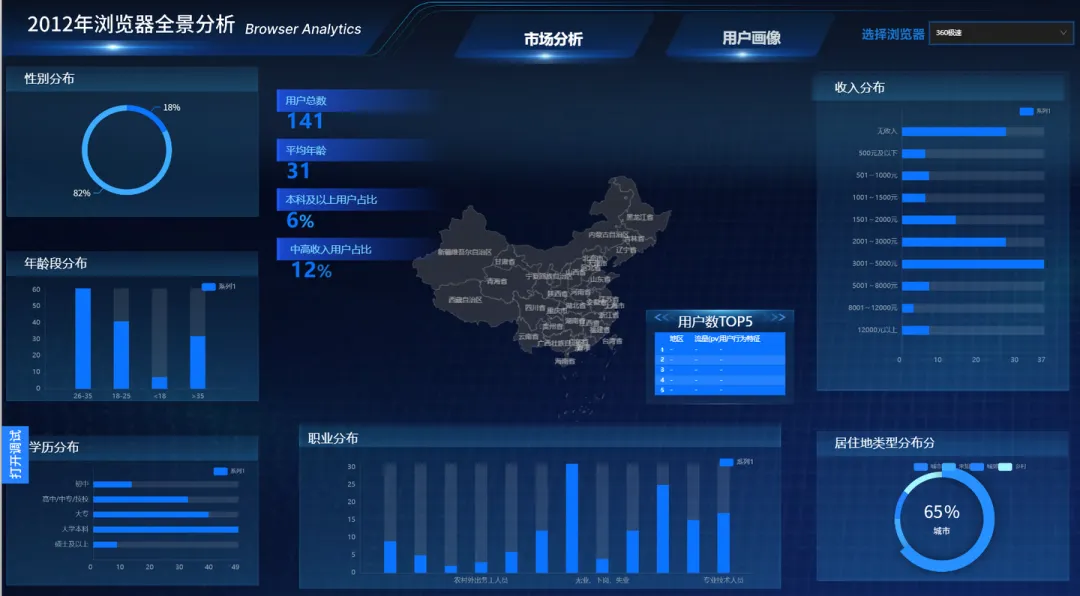
六、大屏交互设置
本实验基于前两个实验完成的市场分析大屏和用户画像大屏,使用助睿Max的蓝图编辑器,配置两个大屏之间的切换交互,以及地图省份点击联动指标卡的功能。
1. 大屏切换逻辑
市场分析和用户画像两个大屏实际上是在同一个大屏文件中,通过控制图层的可见性来实现切换。
实现原理:通过 tab列表组件实现。将市场分析的所有组件放入“市场分析组”,用户画像的所有组件放入“用户画像组”。tab列表组件设置2列(“市场分析”和“用户画像”),每列设置不同的ID(如 "id": 1 和 "id": 2),背景设为透明以融合导航栏样式。点击某列时,根据ID控制两个组的可见性:显示对应组,隐藏另一组。
助睿Max图层管理优势:通过“图层”面板可以轻松控制组件的显示/隐藏,无需编写代码。配合蓝图编辑器,可以实现按钮与图层可见性的联动。
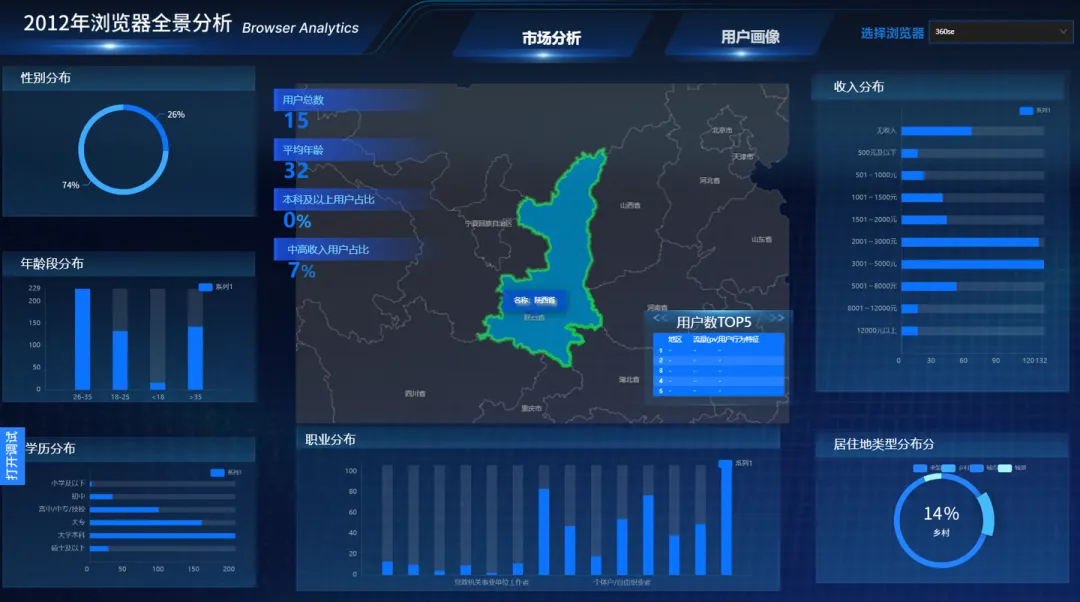
2. 地图省份点击联动逻辑
在用户画像大屏中,点击地图上的某个省份时,右侧的四个核心指标卡(总用户数、平均年龄、本科及以上占比、中高收入占比)需要更新为该省份的数据。
用户点击省份 → 地图组件触发“点击区域”事件 → 蓝图接收省份名称 → SQL请求查询该省份的核心指标 → 指标卡刷新数据
3. 完整蓝图连接示意图
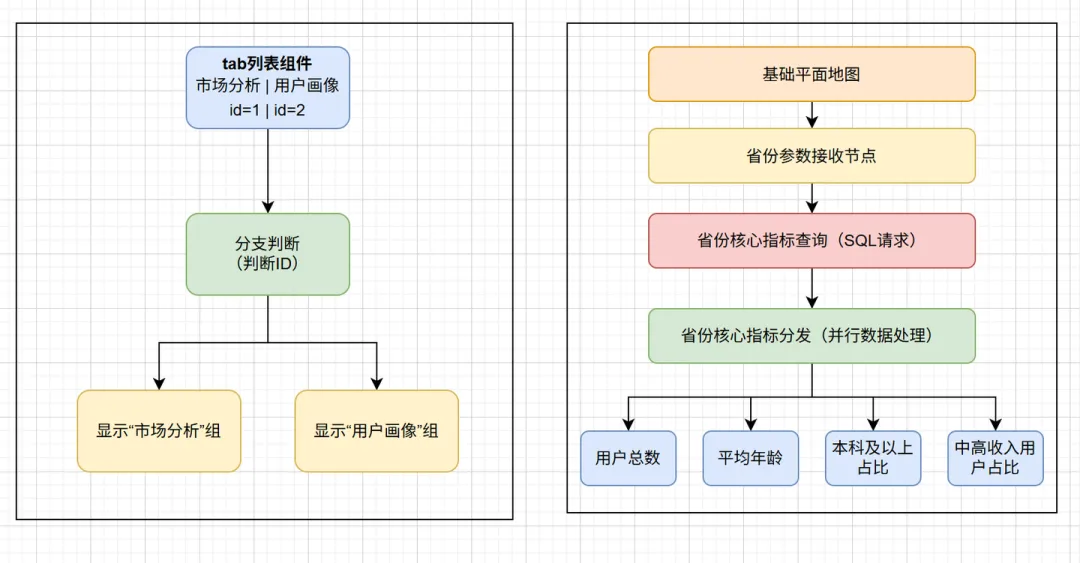
4. 具体操作步骤
4.1 配置大屏切换
(1)添加Tab列表组件,调整大小、位置,两个导航按钮重合
(2)Tab列表组件的基本设置中,设置行数为1,列数为2,再标签默认配置中,将“背景颜色”、“选中背景色”、“悬浮背景色”的透明度设置为0,这样就看不见Tab列表组件,给用户的感觉就是只有2个按钮
(3)设置Tab列表组件每个选项的id:在数据中,保留2列数据,id分别为1、2,content为空,设置后记得刷新数据
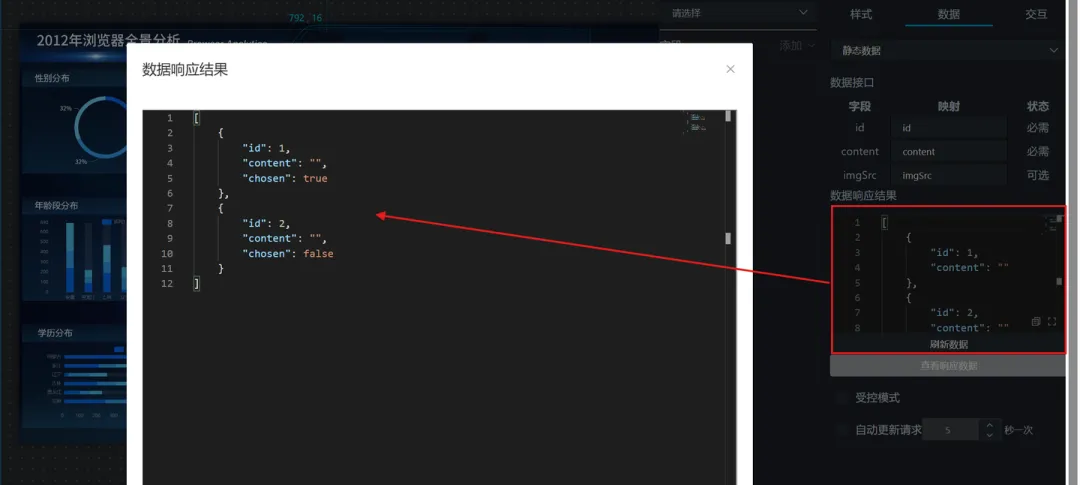
(4)将“市场分析”组、“用户画像”组、Tab列表组件导出到蓝图编辑器
(5)在蓝图编辑器中,将“市场分析”组、“用户画像”组、Tab列表组件添加到蓝图编辑器画布中,通过“分支判断”节点来做“当Tab点击时”的id判断,处理方法为:return data.id == 1;
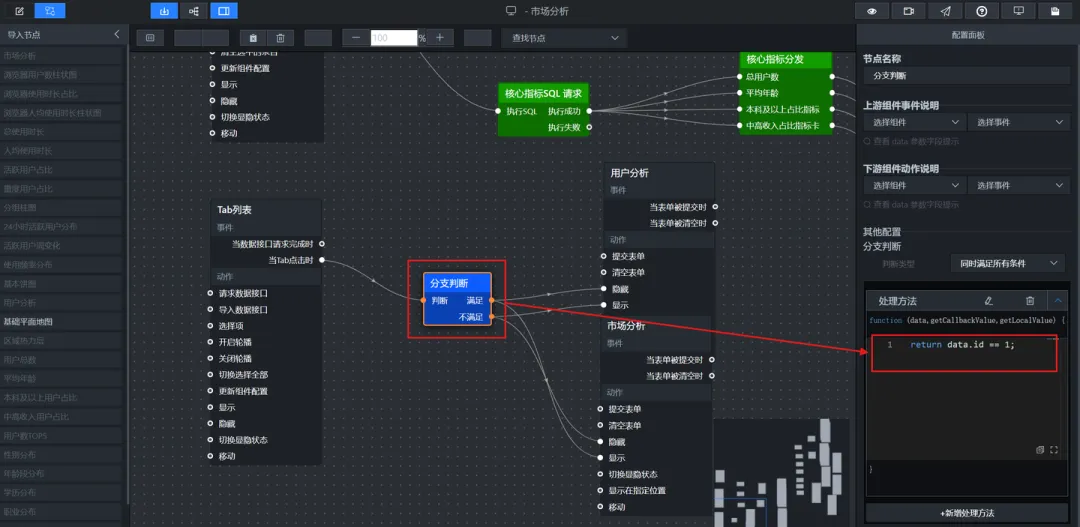
(6)在“分支判断”的 满足 分支上,添加两个“设置图层可见性”动作:(也就是连线)
目标图层:市场分析组 → 显示 目标图层:用户画像组 → 隐藏
(7)在“判断选项卡”的 不满足 分支上,添加两个“设置图层可见性”动作:
目标图层:市场分析组 → 隐藏 目标图层:用户画像组 → 显示
4.2 配置地图省份点击联动
核心知识点:
事件驱动:地图组件的“点击区域时”事件是起点,它会输出被点击区域的地理信息(如省份名称)。 变量传递:通过 window.globalProvinceName全局变量,可以将省份名称在不同节点间共享,避免重复连线。动态SQL:SQL请求节点可以接收外部变量,实现“根据用户点击的省份查询不同数据”。 并行数据处理:将一次查询返回的多行数据(每个指标一行)拆分、过滤,分别发送给不同的目标组件。
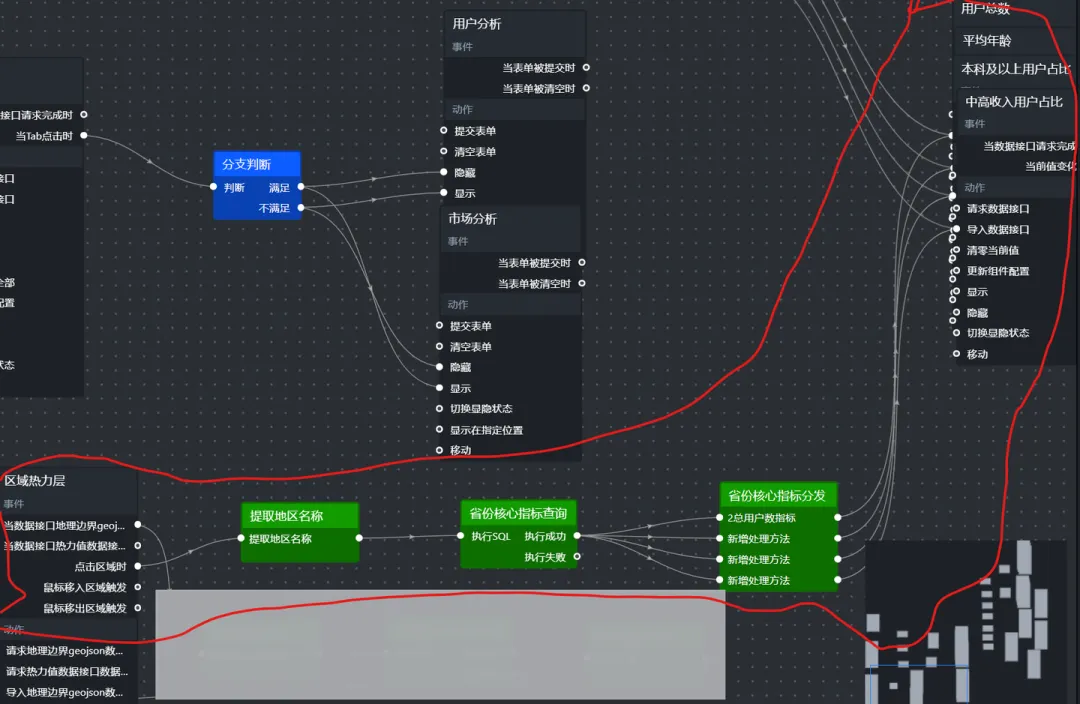
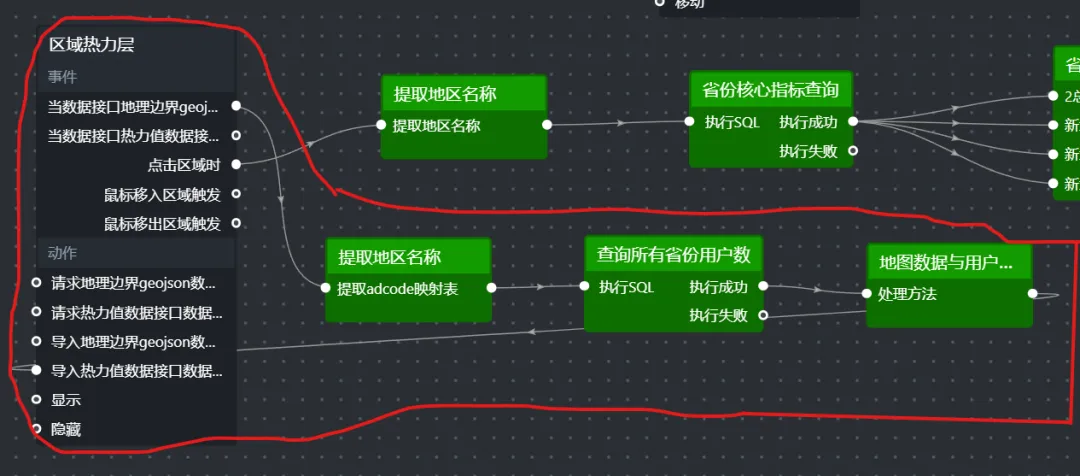
(1)提取地区名称(并行数据处理)
作用:接收地图点击事件输出的 data 对象,从中提取 name 字段,并通过映射表转换为数据表中的简称,最后存入全局变量 window.globalProvinceName。
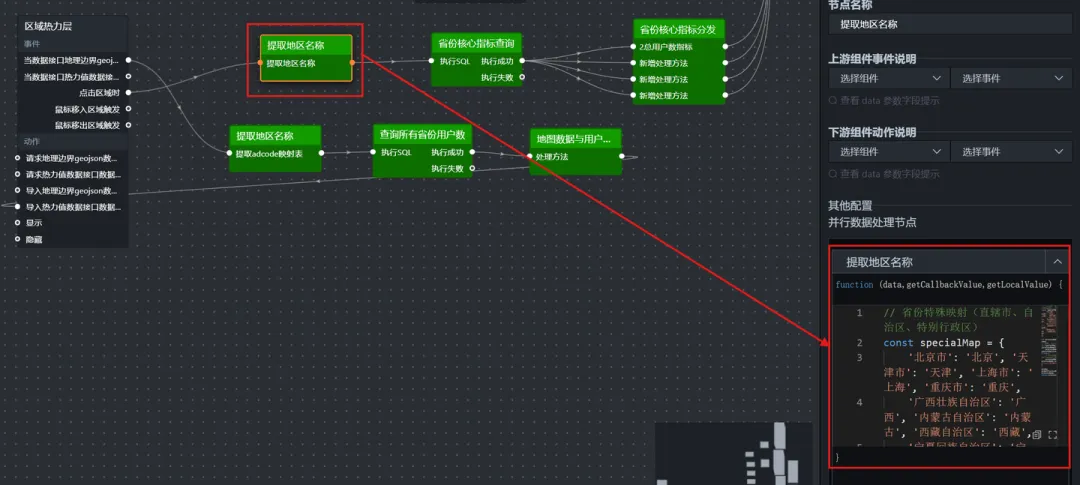
代码如下:
// 省份特殊映射(直辖市、自治区、特别行政区)
const specialMap = {
'北京市': '北京', '天津市': '天津', '上海市': '上海', '重庆市': '重庆',
'广西壮族自治区': '广西', '内蒙古自治区': '内蒙古', '西藏自治区': '西藏',
'宁夏回族自治区': '宁夏', '新疆维吾尔自治区': '新疆',
'香港特别行政区': '香港', '澳门特别行政区': '澳门'
};
let provinceName = data.name;
// 优先使用特殊映射
if (specialMap[provinceName]) {
provinceName = specialMap[provinceName];
} else {
// 通用处理:去除末尾的“省”、“自治区”、“市”
provinceName = provinceName.replace(/(省|自治区|市)$/, '');
}
window.globalProvinceName = provinceName;
return provinceName;
(2)省份核心指标查询(SQL请求节点)
根据当前选中的浏览器(window.GLOBAL_SELECTED_BROWSER)和点击的省份(window.globalProvinceName),从 user_profile_stats 表中查询四个核心指标。为了便于后续分发,使用 UNION ALL 将四个指标输出为多行,每行包含 name(指标名)和 value(数值)。
代码如下:
const selectedProvince = window.globalProvinceName;
console.log("点击的省份名称(处理后):", selectedProvince);
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER;
const sql = `
select 'total_users' as name, sum(user_count) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'avg_age' as name,
round(sum(age * user_count) / sum(user_count), 0) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'high_edu_ratio' as name,
round(sum(case when edu in ('本科', '硕士及以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
union all
select 'high_income_ratio' as name,
round(sum(case when income in ('5001~8000元', '8001~12000元','12000元以上') then user_count else 0 end) * 100.0 / sum(user_count), 2) as value
from labs.user_profile_stats
where browser_name = '${selectedBrowser}' and province = '${selectedProvince}'
`;
console.log("生成的省份核心指标SQL:", sql);
return sql;
(3)省份核心指标分发(并行数据处理)
SQL 返回的是四行数据,而四个指标卡每个只需要一个数值。通过“并行数据处理”节点,我们按 name 字段过滤,将每个指标单独输出给对应的指标卡。
分支示例(总用户数):
var item = data.find(item => item.name === 'total_users');
return [{ value: item ? item.value : 0 }];
其他分支类似,只需修改 item.name === 'total_users'的条件即可
(4)组件连线:将上述组件参照图片连接起来
4.3 地图热力层根据用户数渲染颜色
为了直观展示全国各省份的用户分布,我们需要在地图上用颜色深浅来表示每个省份的用户数(用户数越多,颜色越深)。这是数据大屏中常见的热力图效果。
助睿Max 的地图组件支持通过“区域热力层”子组件接收自定义数据。数据格式要求为 { name, value, area_id },其中 name 为省份名称,value 为用户数,area_id 为行政区划代码(adcode)。因此,我们需要完成以下步骤:
提取地理数据中的 adcode 和 name:地图组件内部包含全国各省份的 GeoJSON 边界数据,其中包含 adcode(行政区划代码)和标准名称。我们需要提取并建立一个“省份名称 → adcode”的映射表,存储在全局变量中。查询所有省份的用户数:根据当前选中的浏览器,从 user_profile_stats表中统计每个省份的用户总数。数据映射与格式化:将查询结果中的省份名称与 adcode 映射表匹配,输出格式 { name, value, area_id }。导入热力值数据:将格式化后的数据导入地图的“区域热力层”子组件,即可自动渲染颜色深浅。
(1)提取 adcode 映射表(并行数据处理)
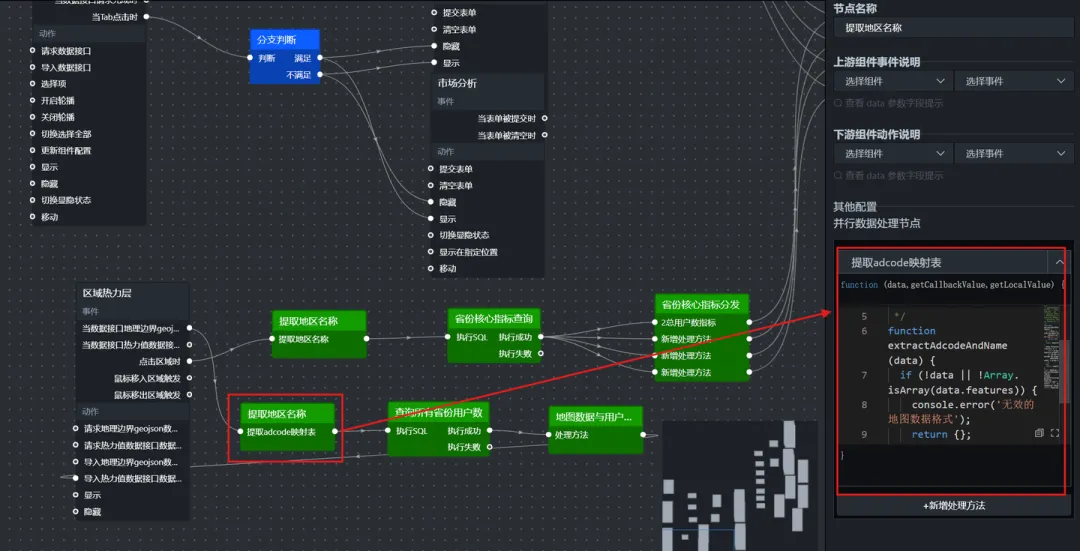
/**
* 提取地理数据中的 adcode 和 name,建立名称→adcode 映射
* @param {Object} data - 地理数据对象(包含 features 数组)
* @returns {Object} 名称到 adcode 的映射表
*/
function extractAdcodeAndName(data) {
if (!data || !Array.isArray(data.features)) {
console.error('无效的地图数据格式');
return {};
}
const nameToAdcode = {};
data.features.forEach(feature => {
const props = feature.properties;
if (props && props.adcode && props.name) {
nameToAdcode[props.name] = props.adcode;
}
});
return nameToAdcode;
}
const mapping = extractAdcodeAndName(data);
window.globalProvinceAdcode = mapping;
console.log("省份adcode映射表已加载", Object.keys(mapping).length);
return mapping;
(2)查询所有省份的用户数(SQL请求节点)
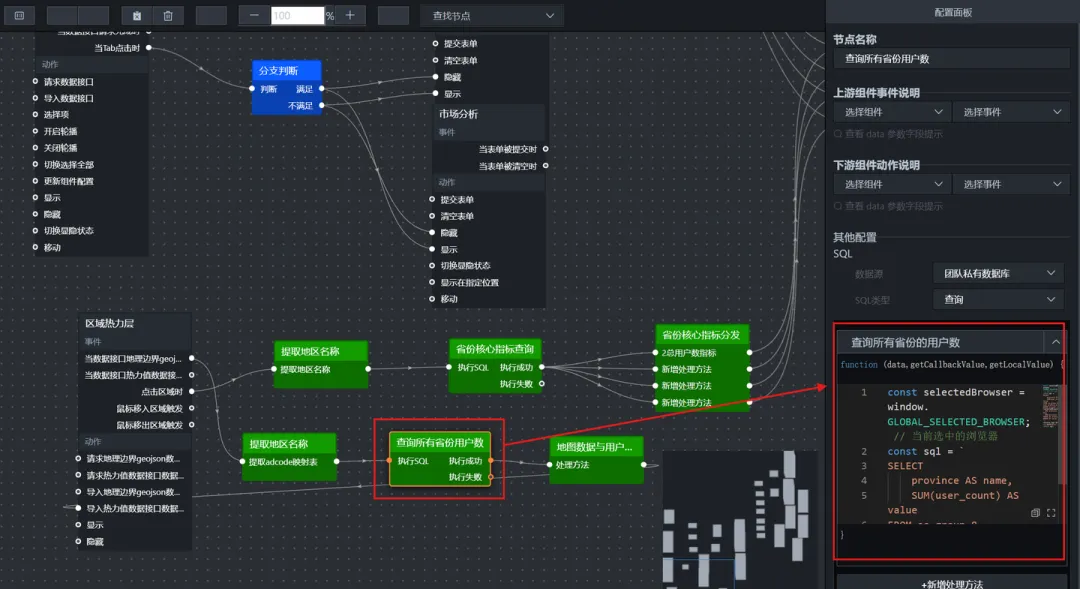
const selectedBrowser = window.GLOBAL_SELECTED_BROWSER; // 当前选中的浏览器
const sql = `
SELECT
province AS name,
SUM(user_count) AS value
FROM labs.user_profile_stats
WHERE browser_name = '${selectedBrowser}'
AND province IS NOT NULL
AND province != ''
GROUP BY province
ORDER BY value DESC
`;
console.log("生成的所有省份用户数SQL:", sql);
return sql;
(3)地图数据映射(并行数据处理节点)
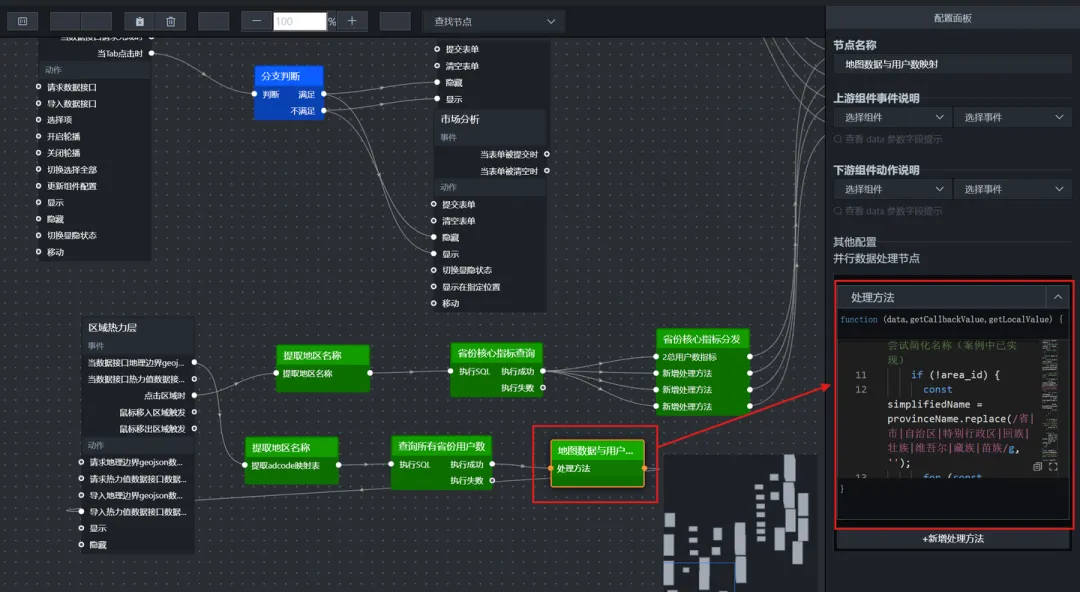
function convertToMapData(data) {
if (!Array.isArray(data) || data.length === 0) {
return [];
}
return data.map(item => {
const provinceName = item.name; // 注意:SQL 返回字段名为 name
let area_id = globalProvinceAdcode[provinceName];
// 如果直接匹配失败,尝试简化名称(案例中已实现)
if (!area_id) {
const simplifiedName = provinceName.replace(/省|市|自治区|特别行政区|回族|壮族|维吾尔|藏族|苗族/g, '');
for (const fullName in globalProvinceAdcode) {
if (fullName.includes(simplifiedName)) {
area_id = globalProvinceAdcode[fullName];
break;
}
}
}
if (!area_id) {
// console.warn(`未找到省份 "${provinceName}" 的匹配 adcode`);
area_id = "000000";
}
return {
name: provinceName,
value: parseFloat(item.value) || 0,
area_id: Number(area_id)
};
});
}
const result = convertToMapData(data);
// console.log("最终返回的地图热力数据:", result);
return result;
(4)蓝图连线与数据流
5.预览与发布
部分细节存在问题,完整的结果参照下图噢!
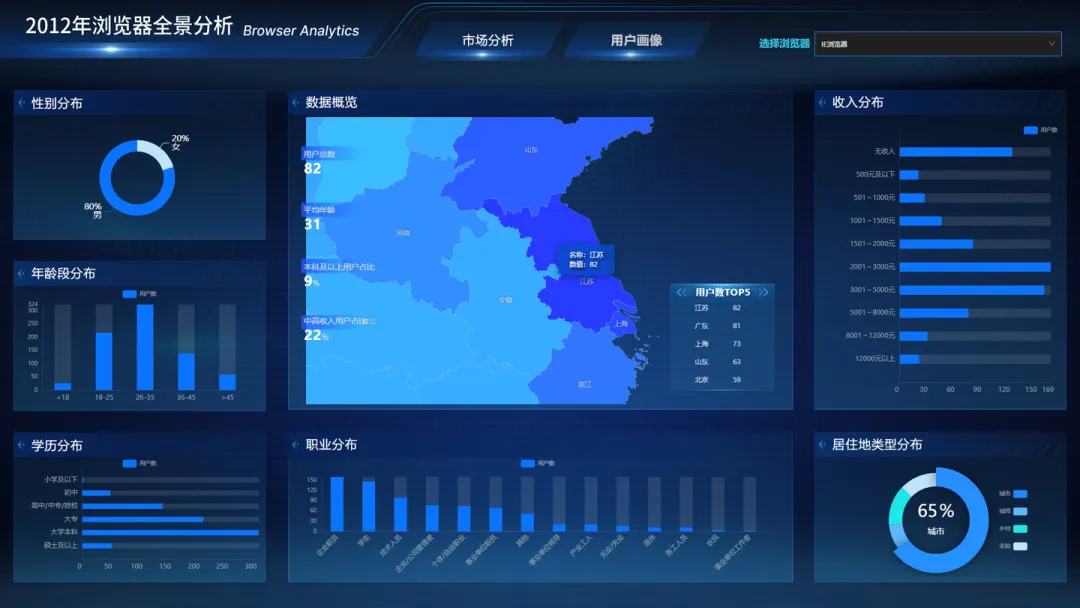
以上,我们就完成了本次实验的全部内容。
七、实验问题与总结评价
实验问题
- 数据库账号权限报错
现象:在预览调试蓝图时,控制台显示1045 Access denied账号访问拒绝。
原因:使用的数据库账号se_group_8未被授权当前客户端 IP 访问,或账号密码配置有误,无法直连数据库执行脚本。
临时处理:重新输入数据库密码,刷新数据源。
- SQL 请求节点未配置数据源
现象:Server error(500)报错。
后果:平台无法执行查询,直接抛出服务器错误。
处理:检查所有SQL请求节点的数据源配置,以及SQL表名是否正确修改
- 数据加工组件配置丢失
现象:修改数据转换流、新增age字段后,计算器、分组、排序等组件配置意外丢失,导致加工后数据异常。
原因:平台数据转换流组件稳定性不足,多次编辑、重新运行后易丢失自定义配置。
临时处理:每次运行转换流前逐项核对组件配置,补全丢失的排序、分组、计算规则。
实验总结
本次完成浏览器用户画像分析大屏搭建,实现布局设计、数据接入、多组件交互联动等操作。实验中遇到服务器报错,经查是 SQL 节点未选择数据源导致;同时存在数据查询返回空值、地图省份编码匹配异常、组件联动偶尔失效等问题,逐一排查后完成全部功能。通过实操,掌握了数据可视化大屏搭建、低代码蓝图配置与数据流转的基本方法。
平台评价
平台功能齐全,集成数据处理、可视化设计、交互配置等模块,组件丰富、上手简单,贴合课程教学需求。但报错提示有些模糊的问题。整体而言是较优质的教学实验平台,若优化细节体验,使用效果会更好。
