 夜雨聆风
夜雨聆风
点击蓝字
关注我们
Hy-Memory最有意思的地方,是它承认Agent也会“记混”
长期协作型 Agent 最怕的不是忘事,而是记了一堆半旧不新的东西。你上周说喜欢极简回答,今天又要它展开分析;一次会话里提过的偏好,到了下次任务还算不算数?这些细节放在人身上叫“熟悉你”,放在智能体里就会变成检索、更新和成本问题。
腾讯混元这次发布的 Hy-Memory,瞄准的就是这个麻烦。它没有把记忆简单做成一个更大的资料库,而是拆成 6 层:事实、画像、心智模型、前瞻意图等分开存。System 1 负责毫秒级抓取即时事实和会话摘要,System 2 则在后台慢慢整理用户模型和知识网络。
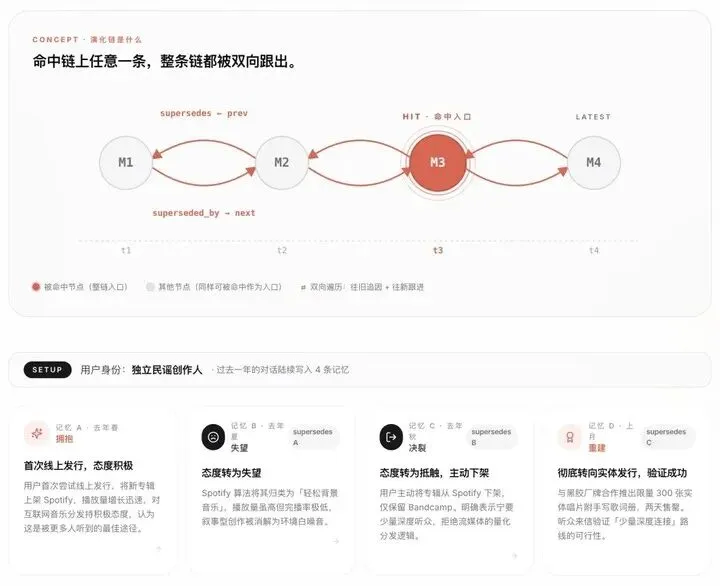
这套设计的关键,是让记忆有“时间感”。 supersedes 指针会把新旧记忆串起来,检索时不只给最新结论,也能看到偏好怎么变过。对长期 Agent 来说,这比单纯多塞上下文更现实:记忆越多,越要知道哪条该听,哪条该退场。
腾讯给出的数字也有点意思:LongMemEval 85.2 分,写入速度是 Graphiti 的 8 倍,记忆条数约为 mem0 的三分之一、Graphiti 的四分之一,长上下文 Token 消耗降 35%。这些数字真正指向的是部署压力,尤其是 Agent 真要跨天跑任务时,不能每次都靠堆 Token 装作自己很了解你。
当然,记忆插件听起来越聪明,用户越会追问另一件事:它记住的是偏好,还是误会?Lite、Pro、Ultra 三档配置和默认 Chroma 本地向量库,能把门槛降下来,但长期信任仍要靠一次次更新不出错来攒。
如果一个Agent越来越懂你,你更担心它忘事,还是担心它把旧判断一直当真?

