 夜雨聆风
夜雨聆风上一篇复盘的是:Claude Code 里如何启动一个子Agent(身份、权限、上下文、执行循环、终止清理),然后通过Python在复现最小的Agent-loop~
这篇看下CC里父子Agent怎么拆任务~
单个Agent-loop 实现的内容是 “一个Agent怎么自己埋头苦干”
但实际系统中,往往任务会很复杂,一个Agent自己干,会面临:效率不高、耗时长、活干久了就忘了、复杂任务怎么干都干不明白。
所以,往往对于较为复杂的任务,拆分出去多找几个帮手Agent一起干,这就是父Agent派生子Agent干活的情况
这里面就会有很多问题,比如:
一个复杂任务拆出去后,子Agent拿多少上下文?
多个子 Agent 同时干活,结果怎么汇回父 Agent?
怎么防止子Agent 继续派子Agent套娃,最后没有Agent在干活?
这篇会回顾CC的 forkSubagent.ts 和 AgentTool.tsx,希望能快速帮你理解对于上述问题该怎么解决
最后有我自己Python继续做的小实验,通过简单几句的Prompt,可以从头开始搭建个简单的loop,验证:父 Agent 发现可以派活 — 子Agent执行任务后汇报给父Agent — 父Agent汇总结果的实验过程回顾,踩坑也在最后,拒绝全黑盒 Vibe Coding~
希望对你有帮助,欢迎一键三连~
阅读指引
什么是forkSubagent?为什么需要 forkSubagent? 👉 一
实验复盘:怎么搭建复现最小 Orchestrator? 👉 二
实验复现和原版功能差距有哪些?👉 三
一、什么是forkSubagent?为什么需要 forkSubagent?
上一篇的 Agent loop,已经能让一个 Agent 持续运行。
它可以想一下、调工具、看结果、继续想。
但只靠一个 Agent 在一条消息链里干所有事,很快会遇到几个问题。
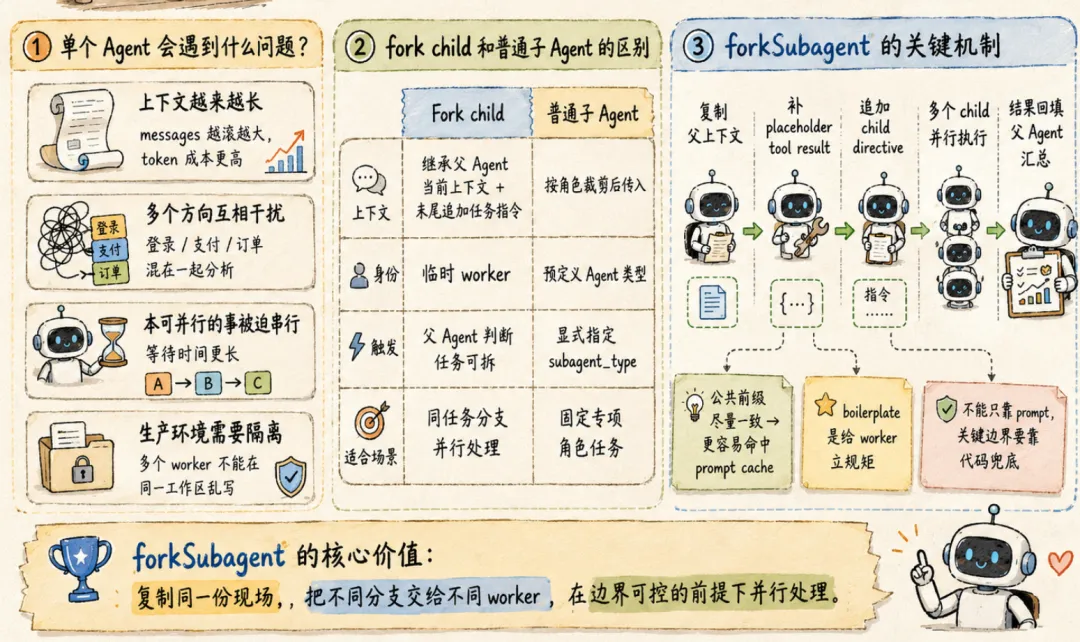
第一,上下文会越来越长,干着干着就干忘了
比如,在一个帮助做支付报销的复杂任务里,父 Agent 可能要同时看登录、支付、订单、权限、测试结果。但所有信息混在同一个 messages 里,那么后面每一轮都要重新带上,token 成本会上去,就像最开始的小龙虾,所有任务一个消息里,不停塞,没干什么活,花了一堆token
此外,模型注意力也会变散(Attention Dilution),看过25 年Chroma的那篇技术报告(Context Rot)就知道,
长上下文窗口只是说明模型“能装下”更多 token,但不代表模型能“均匀、稳定、准确地使用”所有 token
所以,从去年年底,通过标榜自己模型能塞下多长上下文的软文就少了很多
第二,多个方向会互相干扰,复杂任务干不明白
还是拿刚才那个做支付报销的举例,一个任务要分析三个模块
登录模块发现一个安全问题,支付模块发现一个接口问题,订单模块还在查日志,如果全塞给一个 Agent,它很容易一边分析一边切换视角,最后输出也混在一起
就跟人干活,复杂任务同时干很多,结果和要干什么就串在一起了,就会混淆
第三,可以并行的事情会被迫串行,效率低、时间长
很多代码阅读、文件分析、模块检查,本来可以分头处理。一个 Agent 从头做到尾,等待时间显然会被拉长。
第四,这种无隔离不稳定的方式没法进生产环境
如果不是用父Agent派生子Agent干活,那对生产中就要考虑一个问题,如果某个环节,多个Agent都需要改内容文件,在一个工作目录里乱写,那最后结果肯定是乱的,所以,需要考虑额外的隔离机制
所以,父Agent派子Agent给自己打工,不是叫上几个Agent一起干活就行,需要更聚焦在如何解决生产级别调度问题:
怎么把父 Agent 当前的现场复制出去?— 如何清晰有效低成本的传递任务命令 让多个 child 在相同背景下处理不同分支?— 如何分头行动不打架,不摸鱼 同时控制边界、上下文、权限、缓存和结果格式。
这就是forkSubagent起的作用~
这里面,澄清几个容易产生误解的地方~
1. fork child 和普通子 Agent 的区别?
CC 里有普通子 Agent,也有 fork child,上一篇讲了普通子Agent怎么起,有时候可能这里会有些误区,这两个不太一样
普通子 Agent 更像提前注册好的专门角色(见上一篇)
它有自己的 agentDefinition,有固定能力边界,也可能有自己的模型配置、权限设置和上下文裁剪方式。比如代码审查、搜索、规划,这种比较固定的角色,就适合走普通子 Agent。
fork child 更像临时复制出来的 worker,就是用来并行打工的
它直接继承父 Agent 当前的完整对话历史,再在末尾追加一段自己的任务指令,它没有预定义角色,重点是拿着同一份现场,去处理一个分支任务。
这个区别很重要,因为这决定着怎么拼接messages
fork child 的关键在于“复制同一个现场”,然后把不同分支交给不同 worker
父 Agent 当前已经读过的上下文、已经形成的判断、当前这一轮发出的工具调用,child 都能接着看。每个 child 的区别,只在最后那段 directive。
2. forkSubagent.ts 做的核心设计:构造 child 的消息
看 forkSubagent.ts,最先注意到的是 buildForkedMessages(),做的事看起来像拼消息,但里面有几个设计点要注意,这个决定着你自己搭这个的时候Prompt至少包含这些内容
大概结构是:
parent_history+ cloned assistant message+ placeholder tool_result+ child directive
第一步,克隆父 Agent 的 assistant message。
父 Agent 当时可能已经发出了多个 tool_use,比如准备读登录、支付、订单三个文件。fork child 需要知道父 Agent 当时处在什么状态,所以这里会复制这条 assistant message。
第二步,给这些 tool_use 补 placeholder。
placeholder 类似:
Fork started — processing in background这个占位符有实际作用,因为LLM API 的消息结构里,assistant 发出工具调用后,后面要有对应的 tool result
如果没有这个结果,消息链就是残缺的,第一篇我复现 tool_calls 的时候已经踩过这个点。
CC 在 fork 里放 placeholder,既保证消息结构完整,也让多个 child 的前缀尽量一致。
第三步,追加 child directive。
不同 child 的差异,主要落在最后那段任务指令上。
比如:
[FORK] 分析用户登录流程,找出安全漏洞另一个 child 可能是:
[FORK] 分析支付流程,找出异常处理问题问题前面大段父上下文保持一致,最后任务不同。
这里进一步提一个问题,为什么需要上下文保持一致?
可以暂停先先想想~
没想出来也没关系,这是生产中会需要在意的点,目前模型的收费是按照token,但仔细看过token计算价格的就会看到,缓存命中和非命中的价格是不一样的
对,这个的设计就是为了提高Child的缓存命中率(prompt cache),节省成本和时间~
因为,如果多个 child 的 API 请求前缀字节完全一致,模型供应商就有机会命中缓存。命中以后,公共前缀不用重复计算,可以省成本,也能降低等待时间。
当然,不同模型厂商这部分的缓存命中不一样,实际做的时候,要结合厂商的API说明来看~
所以 forkSubagent.ts 里的消息构造,同时在处理几件事:
消息链不能残缺 child 要继承同一份现场 多个 child 的公共前缀尽量一致 每个 child 只在任务指令上分叉 父 Agent 后面能读到干净结果
这也是我读CC源码时比较有收获的一点,CC是一个优秀的 harness engineering 的案例,看起来还是在拼prompt,但实际处理的是背后的上下文上下文、缓存、边界和结果汇总这些工程问题。
3. 怎么给并行打工的 worker 立规矩?
fork child 收到的任务指令前面,会带一大段boilerplate,这个就是有信息来立规矩的办法,里面会告诉 child
总共有10条,但是总结概括就是下面这几个:
- 搞清你自己的角色:你是 fork 出来的 worker,不承担主 Agent 的角色
- 不许工作再分包:不要再创建子进程
- 不要摸鱼,执行就行:不要聊天,不要追问
- 讲结果,不要讲废话:不要边做边解释
- 干好你该干的:只做分配给你的任务
- 汇报要统一:输出用固定格式
这些内容,打过工的都知道~ 这些不是为了效仿人,并行worker肯定会碰到的问题,要先立规矩~因为:
多个 child 同时跑,如果每个都顺手扩展范围,任务边界会乱。
如果 child 一边调用工具一边解释过程,父 Agent 拿到的结果会变脏。 如果 child 继续派 child,任务树可能很快失控。
如果输出格式不固定,父 Agent 汇总时还要从一堆自然语言里猜字段。
所以 boilerplate 的用途很明确:给 worker 设边界。
不过,prompt 约束有概率问题,模型可能遵守,也可能会飘一下。
那面向生产系统的设计,就不能接受的风险就不能只写在 prompt 里,所以CC这部分有代码兜底,做双层防递归~
除了prompt,CC还有两层检查:querySource、message scan
querySource 是运行时元数据,不在消息里,LLM 看不到。一个 fork child 如果再想调用 Agent 工具,AgentTool.tsx 可以从 options.querySource 判断它已经处在 fork worker 里,然后拒绝。
message scan 是扫消息历史,看里面有没有
两个检查命中一个,就不允许继续 fork。
实际生产中,越不能出错的规则,越要靠代码兜底
防递归、防越权、资源清理、文件隔离,这些东西不能只交给模型记住。
4. 既然有普通子Agent和fork,怎么判断啥时候起哪个?
AgentTool.tsx 就是解决这个问题的:父 Agent 调用 Agent 工具时,到底走普通子 Agent,还是走 fork child
核心逻辑可以压成三种情况:
有 subagent_type → 使用指定的普通子 Agent没有subagent_type + fork功能开启 → 走 forkpath没有 subagent_type + fork功能关闭 → 使用 general purpose agent
这里有个细节:省略 subagent_type 这个行为,来自系统提示词和工具路由的配合。
系统提示词会教父 Agent:如果要派并行 worker,可以省略 subagent_type;如果要派某个专用 Agent,就写明确类型。
模型负责表达意图,AgentTool.tsx 负责把这个意图送到对应执行路径。
这一点对我理解 Orchestrator 是有很大帮助的,因为,不是 “父 Agent 叫了一个 child” 就叫调度的,你至少还要包括:
模型怎么表达任务拆分意图?工具参数怎么承载这个意图?代码怎么根据参数走不同路径?
child 的上下文怎么构造?child 的权限和工具怎么收窄?child 的结果怎么回到父 Agent?
读到这里,forkSubagent 基本就讲的差不多了,还剩两个我自己看的时候产生的误区,一并贴出来
5. fork child 为什么不能重建工具列表?
AgentTool.tsx 把参数组装好再传给 runAgent.ts,这里面 fork child 的工具列表,用的是父进程的原始数组,而不是重新组装出来的。
代码里是这样写的:
fork path → availableTools = 父进程原始工具数组normal path → availableTools = 按 worker 权限重新组装的 workerToolsols = 按 worker 权限重新组装的 workerTools
这个设计的原因在于 permissionMode。
fork child 的权限模式是 bubble——权限请求往上冒泡给父 Agent 处理,不是自己决定。
如果按 bubble 模式重新组装工具列表,工具的序列化结果会和父进程不一样:哪些工具可见、工具描述里带不带权限提示文字,这些细节都可能变。
工具列表 JSON 只要有一个字节不同,API 请求前缀就不一致,prompt cache 全部失效。
所以 fork path 直接继承父进程原始工具数组,用 useExactTools: true 跳过重新序列化这一步。
这和前面提到的占位符要完全一样是同一个逻辑:cache 命中的条件是前缀字节完全一致,任何一个字节不同都会破坏。
6. forceAsync 是释放 turn,不代表换其他模型
fork 模式开启后,我最开始也产生了一个误解,forceAsync和模型选择没有关系~
const forceAsync = isForkSubagentEnabled();这行代码让所有子 Agent 都强制 async 执行,不只是 fork child。
听到”async”,容易第一反应是”用了不同的模型”或者”换了一套推理配置”。不是这样的
forceAsync 做的事是:父 Agent 派出 child 后,当前 turn 立即结束,不等 child 跑完。child 在后台独立运行,完成后通过
它解决的问题是:
如果子 Agent 同步跑,父 Agent 的 turn 会被占住,主循环卡着,用户这期间发不了消息。
强制 async 之后,父 Agent 的 turn 立即释放,主循环保持响应。
CC是TypeScript ,因为 JavaScript 是单线程事件循环,async/await 天然不阻塞
二、实验复盘:怎么复现最小 的Orchestrator?
学习做实验,还是不要上来大而全,先把最小链路跑出来,沿用上次的部分
父 Agent 的工具箱里有三个工具:get_current_time、calculate、agent
child 的工具箱里只有两个:get_current_time、calculate
这种就天然不会递归了:父 Agent 可以派活,child 只能干活。
1. 复现内容
Orchestrator 验证这条链路:
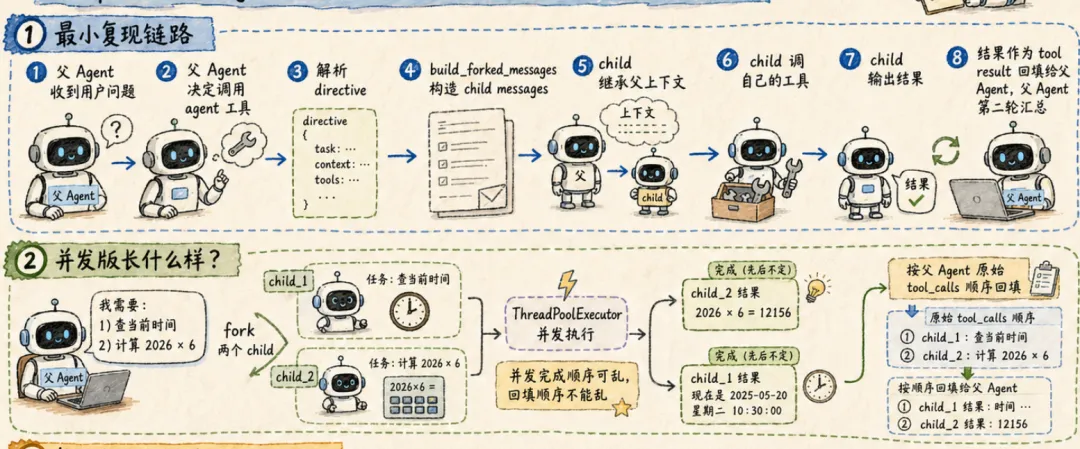
其中 run_parent() 负责父 Agent 主循环。run_child() 负责 child 自己的 loop。build_forked_messages() 复用前面实验里做过的 fork 消息构造。
2. 第一轮:父Agent 模型觉得任务太简单了,压根没派 child
我一开始给的问题很简单:帮我做两件事:查一下现在几点,然后算 2026 乘以 6,最后用一句话总结结果。
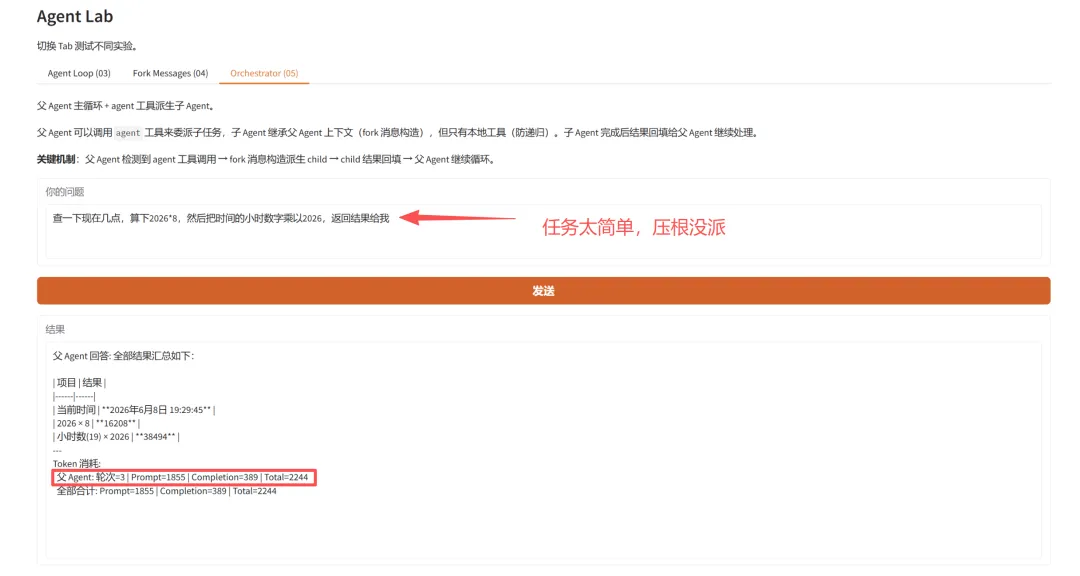
父 Agent 没有调用 agent 工具。
它自己把两个本地工具调完了。工具箱里有 agent,模型也不一定会用。任务太简单时,它会判断本地工具够用。
如果如果你自己做实验目标是观察父子 Agent 链路,就要把任务说清楚。否则你看到的还是单 Agent 调工具。
后面改了下用户输入的提示词
做两件事,派子Agent做:查一下现在几点,然后算 2026 乘以 6,最后用一句话总结结果。3. 第二轮:父子 Agent 链路跑通
成功触发 agent 工具后,父 Agent 会把每个 child 的任务指令取出来。
<child-1>查询当前的时间(日期和时间),然后返回结果。<child-2>计算 2026 乘以 6 的结果,然后返回。
日志里能看到:
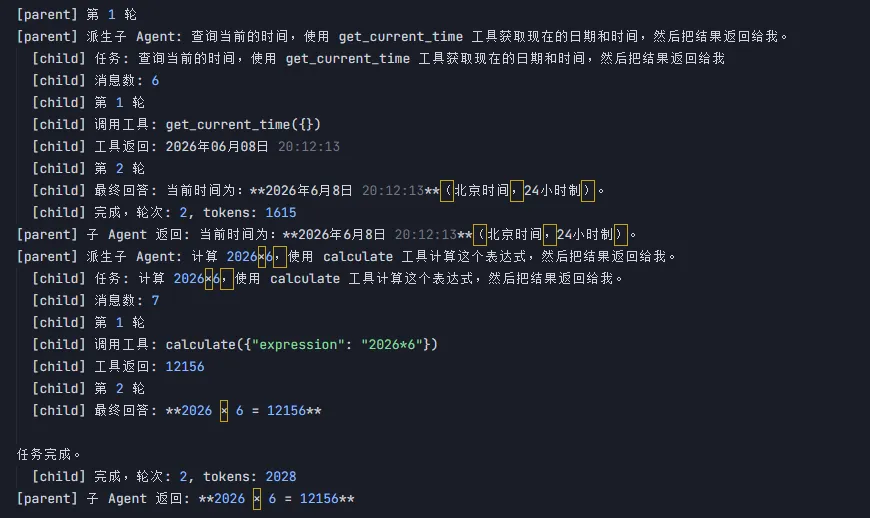
到这里,最小父子链路已经成立:
父 Agent 没有自己查时间,也没有自己计算。
它把两个任务拆出去,child 各自完成,再把结果交回来。
4. 第三轮:串行 child 改成并发 child
一开始的 child 是串行执行。代码逻辑大概是:
for tool_call in assistant_message.tool_calls:if func_name == "agent":child_answer, child_tokens = run_child(...)
这能证明父 Agent 会派活,但还没有复现 Orchestrator-Workers 里“workers 并行干活”的味道。
所以后面我把 agent 工具调用拆出来,用 Python自带的ThreadPoolExecutor 并发执行。
核心思路是
local_results = {}agent_calls = []for tool_call in assistant_message.tool_calls:if func_name == "agent":agent_calls.append((tool_call.id, directive))elif func_name in LOCAL_TOOL_FUNCTIONS:local_results[tool_call.id] = ...with ThreadPoolExecutor(max_workers=len(agent_calls)) as executor:...
这里我没有把所有工具都并发,本地工具比如 get_current_time、calculate,执行很快,直接跑就行。
需要并发处理的是 agent 工具,因为每个 child 都会再走一轮或多轮模型调用。
并发版,日志能看出来:
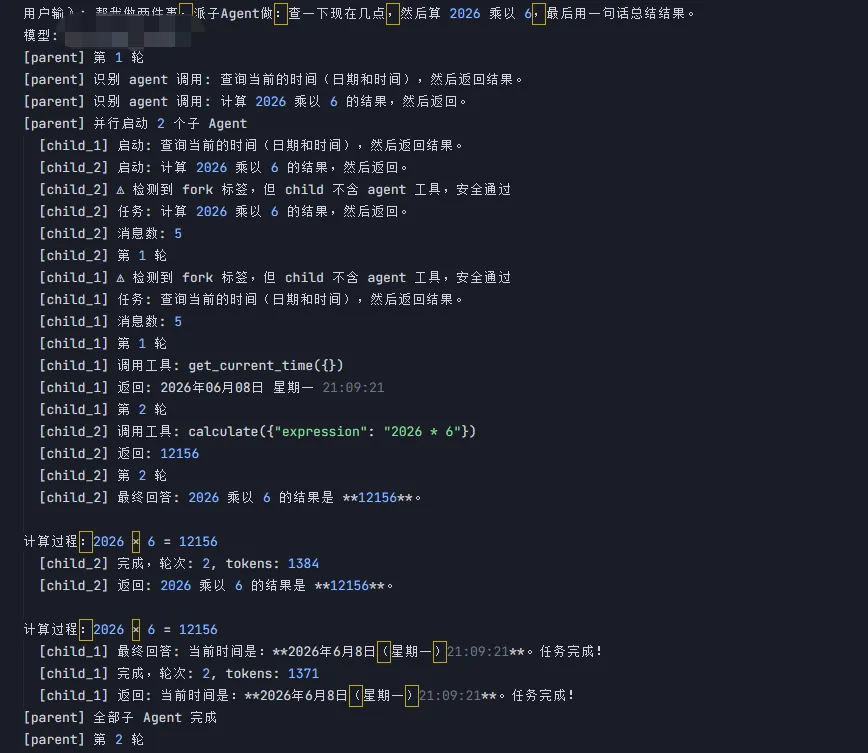
child_1 和 child_2 的日志交错出现,说明它们确实在并发跑。
但并发带来一个新问题:结果返回顺序不可控。
谁先跑完,谁先返回。
可是 API 对 tool_call_id 有要求。父 Agent 那一轮发出的每个工具调用,都要有对应的 tool result。
所以我用了两个字典暂存结果:并发完成后,不能按 child 完成顺序回填,要按父 Agent 原始的 assistant_message.tool_calls 顺序回填
for tool_call in assistant_message.tool_calls:result = local_results.get(tool_call.id) or agent_results.get(tool_call.id)messages.append({"role": "tool","tool_call_id": tool_call.id,"content": result,})
这个点就是防止上一篇, tool_calls 踩空的问题,并发可以乱序完成,消息回填不能乱。
三、实验复现和原版功能差距有哪些
我这轮目标是验证父子 Agent 链路,不做生产框架,所以原版好多地方我都省略了
因为CC要面对真实用户、真实仓库、长任务、后台任务、权限、文件修改、资源清理。
我只需要验证:
父 Agent 能不能派 child child 能不能拿到上下文 child 能不能调用自己的工具 child 结果能不能回填 多个 child 能不能并发跑
所以 worktree、权限系统、task notification、完整 agentDefinition,这些都直接砍掉了
如果,是自己学的话,不要一开始把所有生产设计都塞进来,最后很可能变成“代码很多,但不知道是哪一块让链路跑通”, 这就变成了纯黑盒的Vibe Coding了
踩坑一:工具没给事实,模型会猜(某家给的coding plan 给的模型)
这个就不说了,我只能说我无话可说

踩坑二:并发后,日志和回填都要管
串行时日志比较容易看的,一个 child 跑完,另一个 child 再跑,顺序天然清楚。
并发后就不一样了,多个 child 同时写日志,如果不加锁,很容易交叉。
log_detail() 加了 threading.Lock。
否则日志里全是 [child],后面复盘时根本分不清哪一行属于哪个任务。
还有回填顺序。,并发结果先放进字典,最后按原始 tool_calls 顺序回填,因为父 Agent 的下一轮推理,依赖完整的消息历史。
踩坑三:prompt 约束不能当安全边界
我在 child directive 里也加了类似 fork boilerplate 的规则:
你是一个 fork 子进程不要创建子进程,直接执行。你不承担主 Agent 的角色只在分配的任务范围内工作
但我不会把这些当成安全边界,这轮起作用的边界设计,是 child 工具箱里没有 agent。
它看不到派生工具,就没法继续派 child,这比只在 prompt 里写“不要递归”更可靠。
这轮实验对我来说,最有价值的地方是把父子 Agent 的链路跑实了。
这个系列下一篇:大概率 context / memory
这轮我先把父 Agent 派 child 的最小链路跑出来了,但拆任务只是第一步。
但还有遗留问题没干的是:上下文到底怎么给?
给多了,浪费 token,也可能让 child 分心。
给少了,child 拿不到关键信息,任务做不好。
给错了,还会误导它,CC对context、memory 有更细的相关的设计,所以下一篇大概率先复现这个
父 Agent 怎么组织上下文,哪些东西该进 context,哪些东西该通过工具按需拉,哪些历史要压缩,哪些信息不能丢。
这可能比“派几个 child 干活”更接近 Agent 能不能稳定工作的核心~
如果这个对你有帮助,欢迎一键三连,下篇文章见~
