 夜雨聆风
夜雨聆风我们缺的不是更多规则,而是规则不通过时,流程真的走不下去。
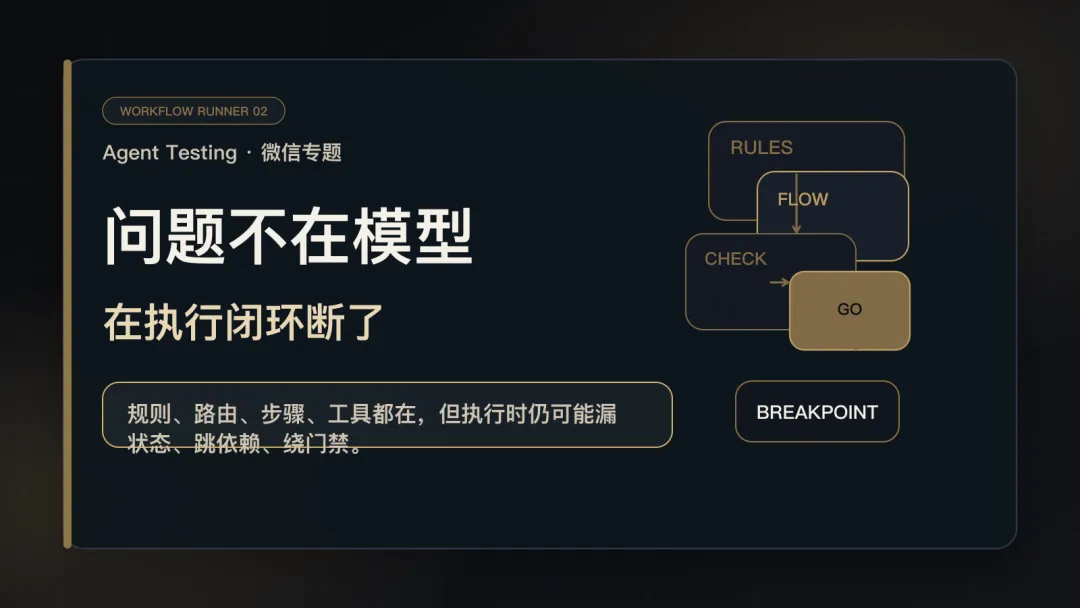
前两篇确认了一个问题:文档约束不等于执行约束。治理体系做得再完整,只要 Agent 执行过程中缺少一道"拦住它"的门,规则就可能被绕过。
接下来的解法选择,很容易走偏。
一、我们排除了什么
改 Prompt 更强势?在我们的实践中,约束力度和指令遵循之间不是线性关系。"你必须先做 A 才能做 B,否则禁止继续"——效果有改善,但仍不稳定。上下文丢失后,规则没有持久化状态支撑,Agent 恢复时还是可能跳过。
做一个管理平台?对于一个本地仓库驱动、几个人用的 Agent 工作流来说,维护一套 Web 服务的成本远大于收益。我们要解决的是"在命令行层面拦住 Agent 不让跳步骤",不是多租户和可视化面板。
上 Agent 编排框架?编排框架解决的是多个 Agent 之间的协调。我们要解决的是单个 Agent 内部的流程推进。用 DAG 编排来管"Agent 有没有先做环境前置",是高射炮打蚊子。
所以我们回到最朴素的问题:怎么用最低成本,给 Agent 的执行流程加一道真正拦得住的门?
二、Workflow Runner 做什么
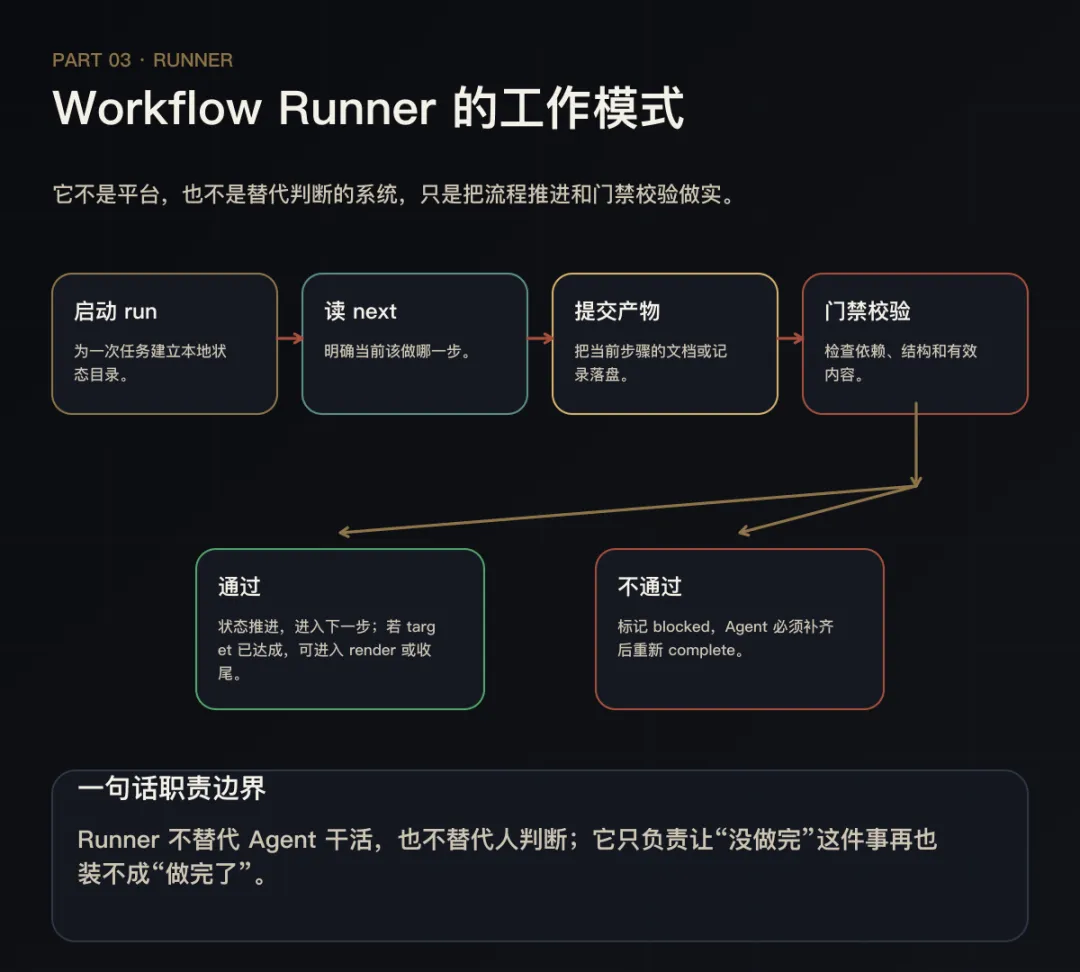
Workflow Runner 是一个命令行工具。它做的事情很简单:
1. 为一次测试实施任务创建一个本地 run 目录
2. 在这个 run 中定义好步骤序列和依赖关系
3. Agent 每完成一步,通过 Runner 做门禁校验
4. 校验通过才能进入下一步
5. 校验失败就卡住,Agent 必须补齐后重试
Runner 就是一层壳。它不自动执行测试,不连远端,不替代 skill 里的具体方法论,也不替代人类的判断。它只负责两件事:
告诉 Agent 下一步是什么。
检查这一步的产物是否满足最低结构要求。
整体流程:用户请求 → Agent 命中测试实施任务 → 启动 Runner → Runner 创建 run 目录和 checklist → Agent 按步骤产出文件 → Runner 校验(标题、非空、表格、有效数据)→ 通过就推进 / 不通过就卡住 → 目标产物达成。
三、边界画得很死
Runner 负责的事情:定义步骤和顺序;记录每步状态;校验产物结构;阻止跳步和跳依赖;支持中断后恢复。
Runner 不负责的事情:不自动执行真实测试,不自动连接远端环境,不替代现有 skill 里的方法论,不替代人工判断,不自动修改规则或 skill,不自动发消息通知,不做多 Agent 并发控制。
这条边界很重要。Runner 的价值不在于它能做多少事,而在于它只做一件事——拦住 Agent 跳步骤——并且把这件事做可靠。
四、不强求跑完全程
测试实施不是每次都需要跑完整闭环。有时只要一份实施指南,有时只需要执行记录,有时要从头到尾跑到最终报告。
Runner 通过 target 模式支持这一点:
execution_guide——只走到测试实施指南,后面的步骤标记为"暂不要求"。
execution_record——走到执行记录。
report——走到最终报告。
full——完整闭环,包含测试工程反思。
后面的步骤不阻塞,但也不假装做了。如果后续需要继续,可以基于同一个 run 往下推进,不用重来。
五、为什么选"轻量本地"
Runner 本质上是一个 Python 命令行工具,加本地 YAML 配置,加本地 JSON 状态文件。没有服务端,没有数据库,没有界面。
这个选择是有意为之的。不需要额外部署和维护,因为它就是一个脚本。状态落在仓库的 .runs/ 目录下,和代码在一起。Agent 可以直接调用,不需要额外适配层。状态文件是普通 JSON,人类随时可以打开看。.runs/ 已加入 .gitignore,不污染主仓库,用完可以丢。
对于一个本地开发环境下的 Agent 测试工作流来说,这已经够了。未来如果需要跨团队协作或审计追溯,再考虑服务化——但那是下一步的事。

六、补上的那道门
在 Runner 之前,我们的治理体系能告诉 Agent"你应该先确认环境,再做工具选型,再写实施指南"。但如果 Agent 直接写了实施指南,没人拦。
在 Runner 之后,如果 Agent 没通过环境前置的门禁校验,它就做不了工具选型。如果工具选型表里只有占位符数据,它就进不了实施指南步骤。
这不是把 Agent 管死,而是让流程有了最低的执行保障。
下一篇,我们把 Runner 打开来看:8 个步骤、门禁到底怎么校验、中断后怎么恢复。
