当前时间: 2026-06-13 10:51:50
分类:办公文件
评论(0)
大规模服务下的插件发布、灰度与可靠性实践插件管理听起来像是一个很小的问题:上传一个包,让业务服务加载起来。但在真实的大规模服务环境里,它很快会变成另一件事。一个插件可能跑在线上服务、同步链路、离线任务里;可能影响服务启动、读写链路和发布回滚;也可能因为版本不一致,把一次普通升级放大成线上风险。所以,插件管理真正要解决的不是“怎么装上去”,而是:在异构系统、上千个服务和高可靠要求下,如何让发布、灰度、质检、回滚和状态一致性都可控。这篇文章复盘的,就是一次从“烟囱式插件发布”走向“统一插件管理平台”的工程实践。一、问题不是装插件,而是规模化管理插件
实际落地时,插件会分布在多种系统形态中:在线系统、同步系统、离线系统。它们使用的插件框架、语言、运行环境和灰度方式都不同。在线系统里,插件可能以服务网格 Sidecar 的形态工作,运行在火山引擎容器服务 VKE 等容器环境中,按机房或可用区逐步灰度;同步系统里,插件可能以流式计算 Flink 版 UDF 的方式接入,按库表维度灰度;离线系统里,插件可能运行在 EMR Hive 或 ByteHouse 这类分析链路中,灰度和回滚方式又是另一套逻辑。如果每一种系统都单独建设一套接入、发布、灰度和回滚能力,复杂度会迅速失控。这个复杂度不是线性增长,而是多个维度叠加后的组合爆炸:系统类型、技术栈、运行环境、灰度策略、插件数量和服务数量会彼此放大。系统类型 × 技术栈 × 运行环境 × 灰度策略 × 插件数量 × 服务数量当插件种类超过 10 个、用户量级超过 100、服务量级超过 1000 时,继续依赖人工接入和烟囱式发布,就会暴露出三个直接问题。下图先把这些复杂度来源拆开。图里的每一层差异,都会在真实发布中变成额外成本。第一是效率低。接入一个插件往往要跨多个平台、多个环节,接入、调试、升级都会消耗大量时间;放到千级服务规模,人工成本会被迅速放大。插件接入不是简单安装,版本依赖、框架版本、插件冲突、业务容量、加载状态和运行指标都可能影响最终效果。只靠人工经验,很难保证每次接入都是安全的。每多一个插件系统,就重复建设一套发布能力;每多一种灰度策略,就增加一套特化逻辑。短期可以跑通,长期会形成很重的技术债。所以,插件管理平台的核心目标不是多做一个发布页面,而是把异构系统里的共性问题抽出来,形成一套可复用、可扩展、可治理的统一能力。二、烟囱式发布为什么会失控
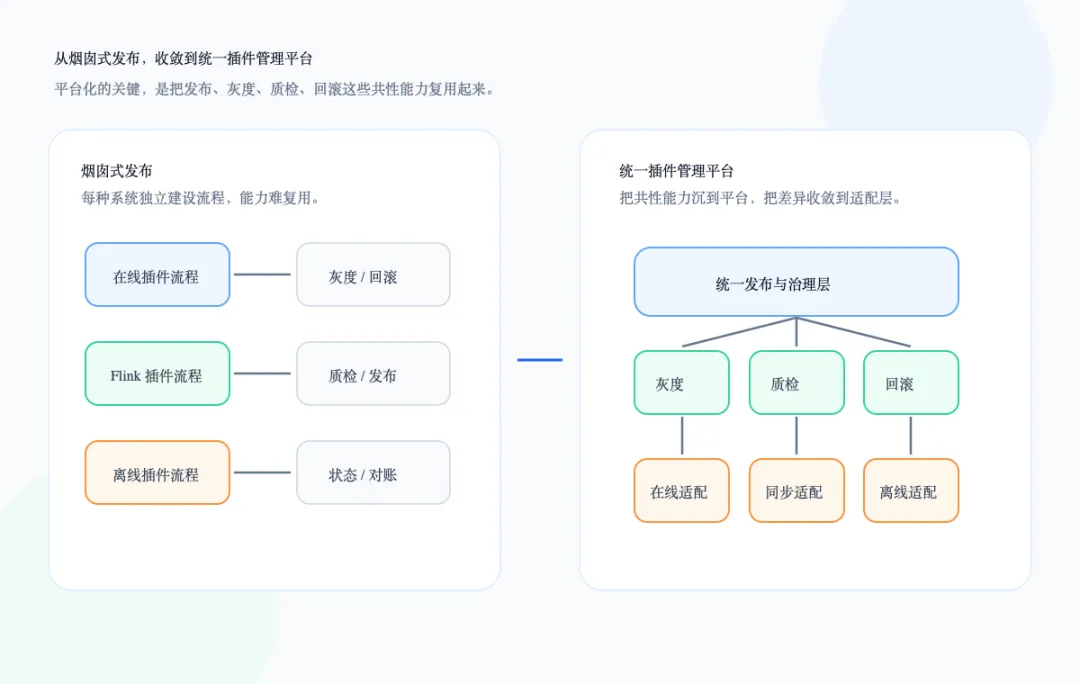
烟囱式发布最大的问题,是每个系统都在解决相似的问题,却没有沉淀出共同抽象。在线插件要发布,离线插件也要发布;服务网格 Sidecar 要灰度,流式计算 Flink 版 UDF 也要灰度;一个插件要质检,另一个插件也要质检。只是它们的运行环境、发布动作和灰度维度不同。如果平台直接面向每一种具体场景写逻辑,就会变成这样:每套流程都要单独处理版本、灰度、回滚、质检和异常恢复。一方面,新增插件系统的成本很高。每接入一个新系统,平台都要重新理解它的发布模型、灰度模型和异常处理方式,开发周期很难收敛。另一方面,平台能力无法复用。比如冲突检测、版本检测、容量评估、质量检查这些能力,本质上是插件接入的通用问题,但如果它们被写死在某个系统流程里,就无法自然服务于其他插件。破局点不是继续堆流程,而是把“插件是什么”和“插件怎么运行”拆开:前者沉淀成统一描述,后者交给适配层处理。三、统一抽象:把插件描述和插件实现分开
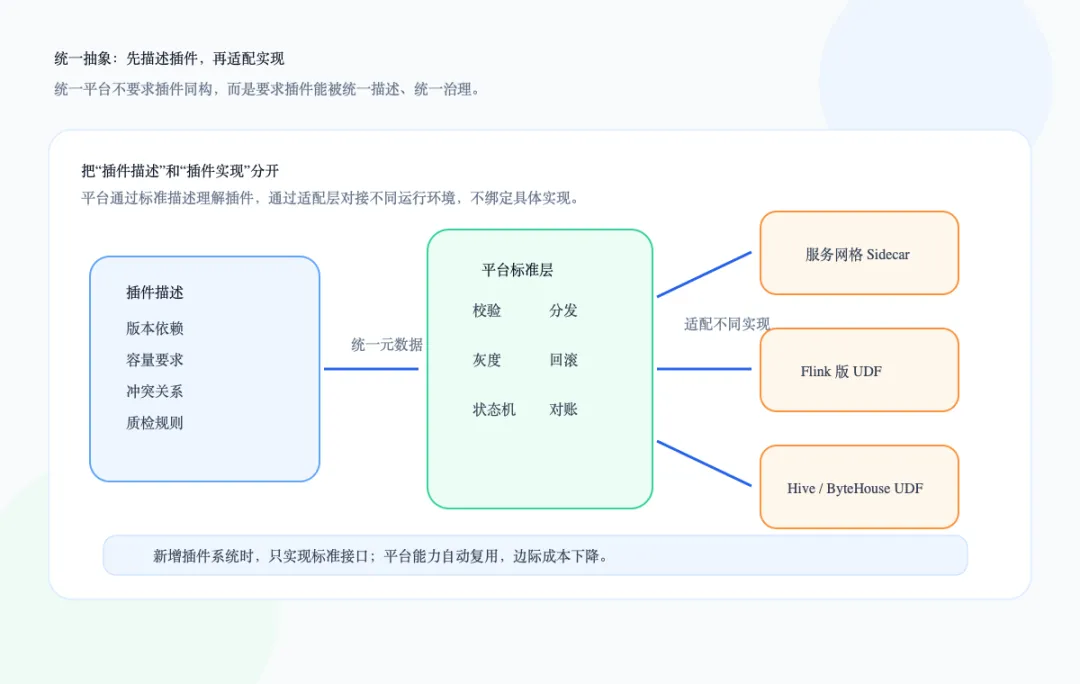
我们最终选择的设计思路,是建立一套和具体技术栈无关的插件标准。这套标准不是要求所有插件都用同一种实现方式,而是要求所有插件都能用统一的方式描述自己:它依赖什么框架版本、需要多少 CPU 和内存、有哪些冲突插件、稳定版本是什么、接入后要检查哪些指标、发布时要走什么策略。换句话说,平台不直接关心插件包内部怎么写,而是先关心插件对外暴露的元数据和生命周期能力。电器可以是不同品牌、不同功率、不同内部结构,但只要它遵循统一的插座标准,就能接入同一套供电体系。插件管理平台也是类似:插件实现可以不同,但插件接入、校验、发布、回滚、状态追踪这些平台能力,应该建立在统一标准之上。底层是适配层,负责对接不同运行环境和插件形态。比如服务网格 Sidecar、流式计算 Flink 版 UDF、EMR Hive / ByteHouse UDF,都可以通过适配层接入平台。中间是发布与治理层,负责统一处理插件注册、版本管理、灰度发布、容量评估、质量检查、紧急下线和版本召回。上层是用户使用层,面向插件开发者和业务研发,提供接入、发布、升级、查询和运营分析能力。这样做的收益很直接:新接入一种插件系统时,不再需要从零建设整套插件管理能力,而是只需要实现标准接口,把差异收敛在适配层。下图把这个关系拆成三层:上层面向使用,中层沉淀发布治理,底层适配运行环境。四、灰度、质检、回滚:平台要兜住变化
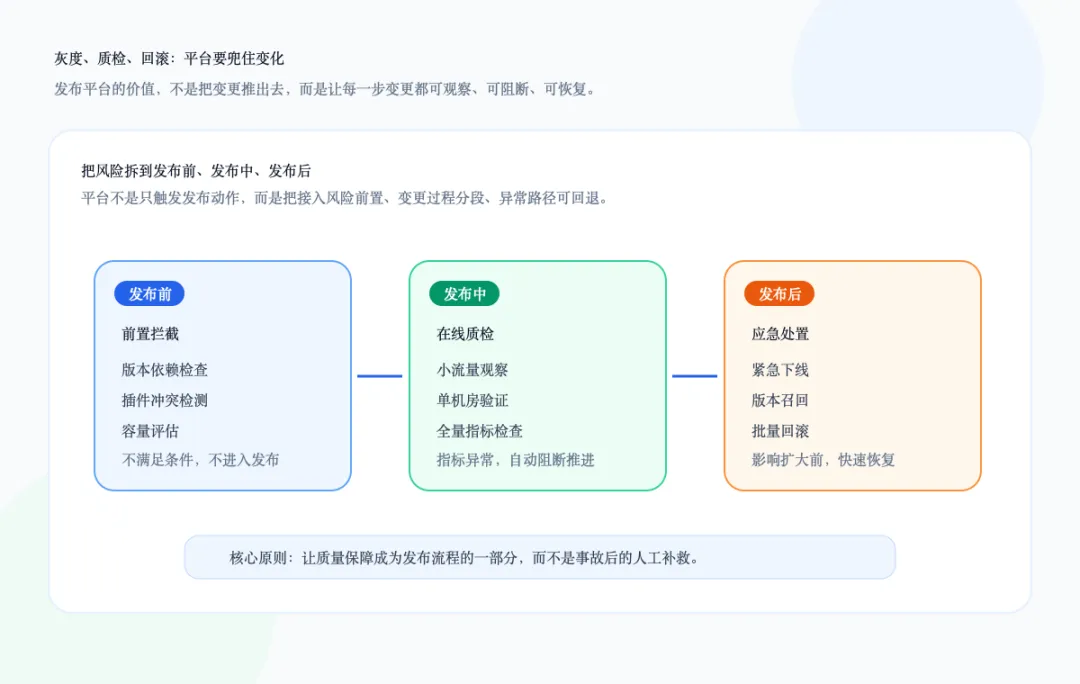
插件管理最危险的地方,不是发布动作本身,而是发布之后的变化是否可控。一个插件版本从小流量到单机房,再到全量发布,中间任何一步都可能出问题。问题可能来自插件代码,也可能来自业务容量、框架版本、插件冲突、指标异常,甚至来自发布流程被取消或回滚。因此,平台不能只做“发布”,还要把发布前、发布中、发布后的质量保障串起来。比如框架版本是否满足要求,业务 SDK 是否已经升级,业务容量是否足够,插件之间是否存在冲突,当前接入版本是否是稳定版本。这些信息都可以通过插件元数据和业务运行指标提前判断。插件进入小流量或单机房阶段后,平台需要持续观察关键指标,比如插件是否正确加载、业务流量是否经过框架、CPU 和内存是否异常、错误率是否变化。对于需要重启才能生效的升级,还可以结合容器或运行环境的升级事件,在版本真正生效后触发异步质检。当插件版本出现问题时,平台必须支持紧急下线、版本召回和批量回滚,而不是让业务方逐个服务手动处理。这也是统一平台的价值:它把原本散落在人工经验、脚本、流水线和各种平台里的动作,收敛成一套标准流程。业务研发不需要理解所有底层细节,平台负责把风险前置、把变更分阶段、把异常留出回退路径。下图对应的是这条质量保障链路。五、可靠性:控制面可以降级,数据面不能拖垮业务
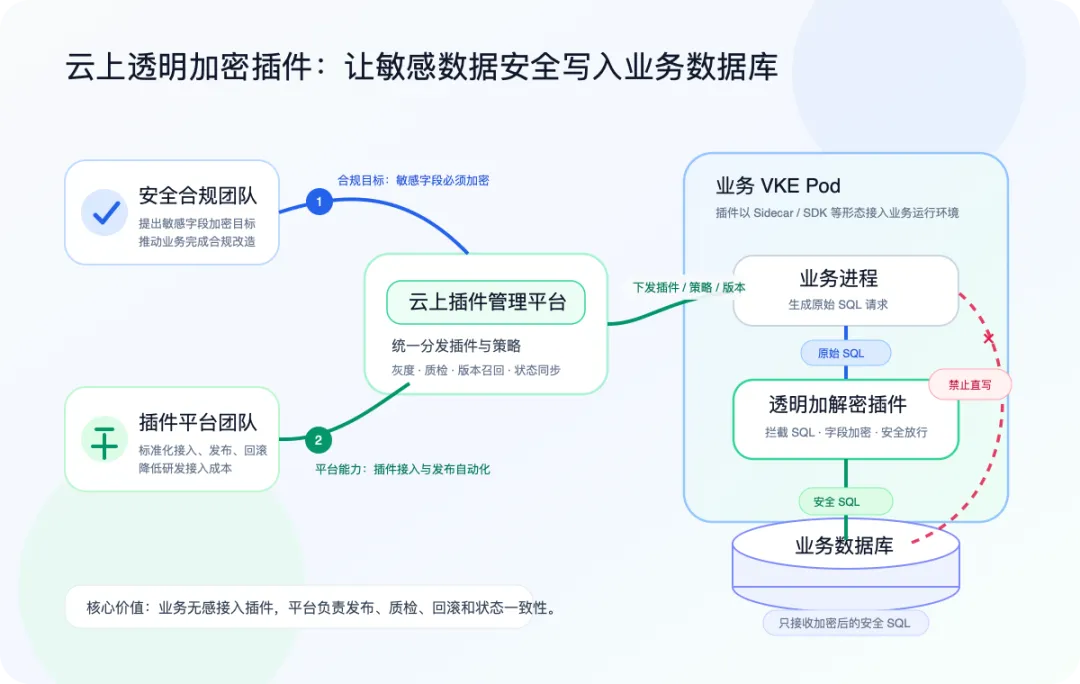
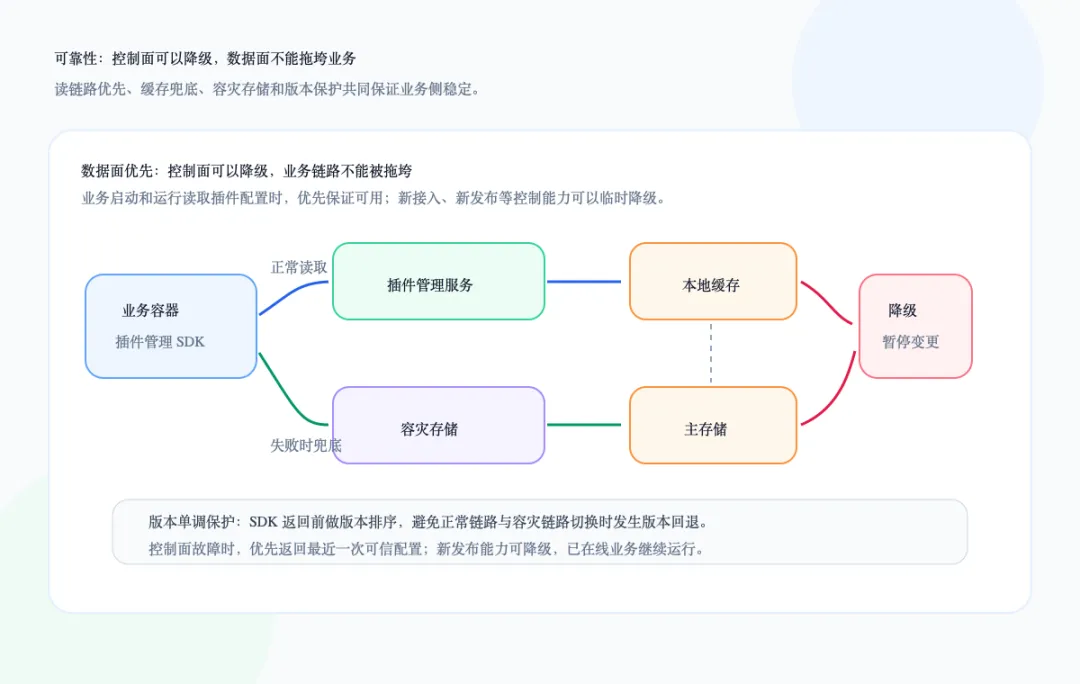
插件管理平台还有一个很容易被低估的问题:它自身也会成为业务链路的一部分。尤其在透明加解密这类场景中,业务容器启动时可能需要拉取插件配置或插件列表。如果插件管理服务不可用,最严重的结果不是“发布失败”,而是业务服务启动受阻。我们把优先级定得很清楚:数据面可用性高于控制面可用性。控制面可以临时降级,比如暂停新接入、新发布、新变更;但数据面不能因为控制面故障而影响已经在线的业务服务。业务容器读取插件配置是高优先级路径。服务端侧通过本地缓存、异步回源、过期数据兜底等方式,尽量避免读请求被数据库故障或短时流量洪峰阻塞。当正常 RPC 请求失败时,SDK 可以从缓存数据库 Redis 版等容灾存储中读取最近一次可用数据。这样即使控制面短暂不可用,业务侧仍能拿到可运行的插件配置。容灾链路会引入一个新的问题:不同数据源之间可能存在短暂不一致。比如正常链路读到新版本,降级链路又读到旧版本,就可能导致业务侧版本回退。解决这个问题的关键,是在 SDK 读时做版本排序和本地最新版本保护。返回配置前,SDK 会保证对外暴露的版本单调递增,避免因为链路切换导致插件版本反复横跳。平台启动时,不应该因为某个非核心依赖故障,就影响核心读链路。比如当某些接入能力依赖的存储不可用时,可以自动关闭新接入能力,但保留插件运行所需的核心读取能力。这些设计的目标都指向同一件事:控制面可以慢一点、少做一点,但不能把风险传导到业务数据面。下图展示的是控制面降级和数据面容灾之间的边界。六、状态一致性:大规模发布必须可预测
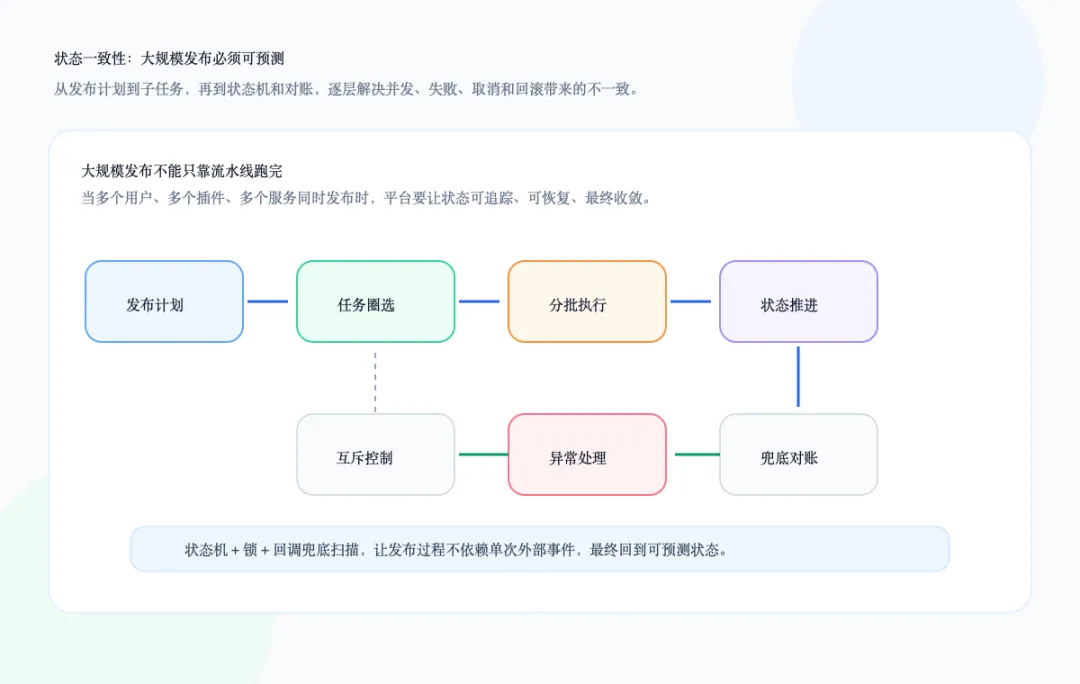
当插件发布进入规模化阶段,状态一致性会成为新的核心问题。在小规模场景里,一个人发布一个插件,手动盯一下流程也许还能接受。但当多个用户同时开发、接入、升级不同插件,平台累计执行数千个接入流水线和上千个发布工单时,单靠人工已经无法保证状态不乱。比如小流量节点已经执行完成,但流水线失败、取消或回滚了。如果平台没有兜底机制,就可能出现部分实例已经升级、部分实例停留在旧版本的状态。如果两个发布流程同时操作同一个服务标识,一个流程发布 v1,另一个流程发布 v2,它们的小流量、单机房、全量节点交叉执行,就可能导致版本短时间内反复变化,最终状态也不一定收敛到预期版本。因此,大规模发布系统不能只依赖“流程跑完了”这个结果,而要有明确的状态机、锁机制和对账能力。对于同一服务标识的并发发布,需要通过锁或互斥策略避免关键阶段交叉执行。对于流水线失败、取消、回滚等异常路径,需要有兜底对账,定期检查线上实际版本和平台期望版本是否一致。对于大规模批量发布,需要把发布计划、子任务、分批策略、状态回调、轮询扫描和进度持久化都纳入统一状态机管理。外部系统的状态回调可能丢失,单个子任务可能失败,部分批次可能回滚。平台不能假设外部事件一定可靠,而要通过主动扫描和状态推进机制,保证发布过程最终可追踪、可恢复、可收敛。下图把这套状态推进关系收束在一起。七、结果:效率、可靠性和复用能力一起收敛
第一,接入和发布效率提升。插件接入耗时从 30~60 分钟降低到 10~30 分钟,人工操作成本从约 30 分钟降低到约 3 分钟;大规模发布也从数小时级压缩到数分钟级。平台累计执行 2525 个接入流水线、1400+ 个发布工单,实现 665 个新服务接入和升级,累计节约约 3156 小时,也就是约 395 人日。通过容灾、降级、优先级限流、版本保护和多机房部署等能力,数据面可靠性目标达到 99.99%。平台上线至今,核心服务支撑约 600 QPS,未出现插件下发失败或 P 级服务故障。更重要的是,这套实践沉淀出了一组可以复用到其他平台型系统里的工程判断。第一,当一个能力要覆盖多类系统时,先不要急着做页面和流程,而要先判断哪些差异是业务差异,哪些差异可以被抽象成统一模型。抽象做早了会空,做晚了会被烟囱式实现拖住。第二,发布系统不能只关注“能不能发出去”,还要关注发出去之前能不能发现问题,发出去之后能不能回滚,异常发生时状态能不能收敛。规模越大,质检、灰度、回滚和对账越应该成为平台能力,而不是人工经验。第三,控制面和数据面的边界要尽早划清。控制面可以降级、重试、延迟恢复;但数据面一旦进入业务链路,就要优先保证稳定性,不能因为平台自身故障放大业务风险。第四,平台化的价值不只是节省一次接入成本,而是让后续每一种新插件、新运行环境、新发布策略的边际成本持续下降。下图把这套方法收束为四层:统一抽象、质量前置、变更可控、状态收敛。真正值得复用的,是面对大规模服务变更时的一套治理方式:把差异收敛成模型,把风险前置到质检,把变化关进灰度和回滚,把状态交给系统持续收敛。
基本
文件
流程
错误
SQL
调试
- 请求信息 : 2026-06-14 14:42:11 HTTP/1.1 GET : https://www.yeyulingfeng.com/a/746260.html
- 运行时间 : 0.176518s [ 吞吐率:5.67req/s ] 内存消耗:4,872.09kb 文件加载:145
- 缓存信息 : 0 reads,0 writes
- 会话信息 : SESSION_ID=ec9d6eb6a7982b3af3aa74c824068044
- CONNECT:[ UseTime:0.001072s ] mysql:host=127.0.0.1;port=3306;dbname=wenku;charset=utf8mb4
- SHOW FULL COLUMNS FROM `fenlei` [ RunTime:0.002241s ]
- SELECT * FROM `fenlei` WHERE `fid` = 0 [ RunTime:0.000797s ]
- SELECT * FROM `fenlei` WHERE `fid` = 63 [ RunTime:0.000726s ]
- SHOW FULL COLUMNS FROM `set` [ RunTime:0.001694s ]
- SELECT * FROM `set` [ RunTime:0.000629s ]
- SHOW FULL COLUMNS FROM `article` [ RunTime:0.001714s ]
- SELECT * FROM `article` WHERE `id` = 746260 LIMIT 1 [ RunTime:0.005136s ]
- UPDATE `article` SET `lasttime` = 1781419332 WHERE `id` = 746260 [ RunTime:0.019302s ]
- SELECT * FROM `fenlei` WHERE `id` = 64 LIMIT 1 [ RunTime:0.000737s ]
- SELECT * FROM `article` WHERE `id` < 746260 ORDER BY `id` DESC LIMIT 1 [ RunTime:0.001324s ]
- SELECT * FROM `article` WHERE `id` > 746260 ORDER BY `id` ASC LIMIT 1 [ RunTime:0.001072s ]
- SELECT * FROM `article` WHERE `id` < 746260 ORDER BY `id` DESC LIMIT 10 [ RunTime:0.013497s ]
- SELECT * FROM `article` WHERE `id` < 746260 ORDER BY `id` DESC LIMIT 10,10 [ RunTime:0.012422s ]
- SELECT * FROM `article` WHERE `id` < 746260 ORDER BY `id` DESC LIMIT 20,10 [ RunTime:0.011278s ]

0.180459s

 夜雨聆风
夜雨聆风