 夜雨聆风
夜雨聆风读完这篇论文,我对"软件工程"有了完全不同的想法
原文:Zhenfeng Cao, The End of Software Engineering: How AI Agents Are Fundamentally Restructuring the Software Paradigm, arXiv:2606.05608v1, 2026. 以下是我的阅读笔记。第二人称视角,方便你快速进入状态。其中标注了可信和存疑的部分。
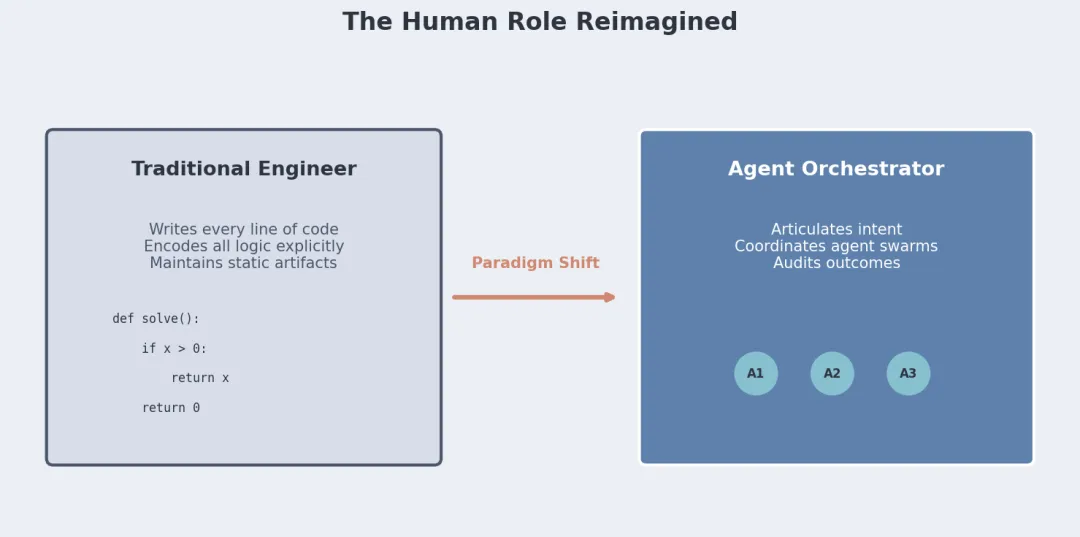
你大概还在每天写代码、修 Bug、做 Code Review,把"需求 → 设计 → 编码 → 测试 → 上线"这套流程走得很熟。但如果认真读完 Zhenfeng Cao 的这篇论文,你的第一反应可能是:这些习以为常的东西,正在瓦解。
不是优化,不是提速。是重构。
论文标题很耸动——“The End of Software Engineering”。作者真正想说的不是程序员要失业,而是一个撑了半个多世纪的底层前提在崩塌:人类工程师必须把所有决策逻辑预先写进静态代码里。AI Agent 能在运行时生成和丢弃代码,这个前提就不成立了。
下面逐章拆解,同时标出哪些地方可信,哪些地方是作者自己的推演。
一、AI 不只是更好的 IDE

你可能已经在用 GitHub Copilot、Cursor 或 Claude Code,感觉 AI 无非是让写代码快一点。论文说这只是第一阶段——工具增强(Tool-Augmented)。更深的变化在于,代码的角色正在从"决策逻辑的载体"变成"推理过程中的临时工具"。
论文用两个定义划了条线:
传统软件系统S = (C, D, E):
C是计算资源(CPU、内存、I/O) D是源代码里的静态决策规则 E是执行环境,按输入对 D求值
D 是静态的。所有逻辑必须在系统跑起来之前,由人写进去。
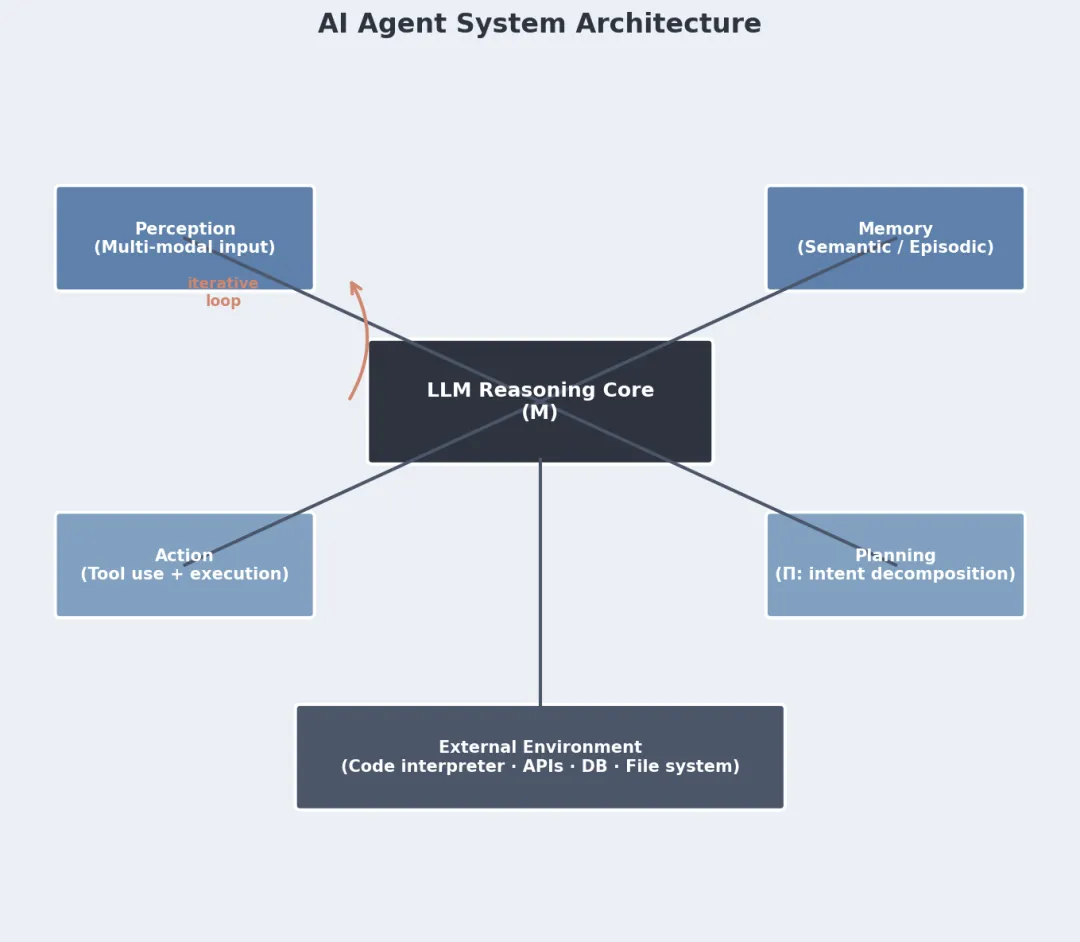
Agent 系统A = (M, T, Mem, Π):
M是大语言模型,当推理引擎 T是可执行工具(代码解释器、API、数据库、文件系统) Mem是记忆子系统(短期上下文 + 长期向量存储) Π是规划机制,把用户意图拆成行动序列
系统跑起来的时候,模型根据状态和记忆选行动,执行完进入下一个状态。决策逻辑是运行时动态生成的——LLM 随时产出代码、调用工具、按中间结果调整。这些都不需要提前写死。
你过去写的代码是产品的一部分;Agent 生成的代码是用完就扔的中间产物。
从模拟电路到存储程序计算机,大概是这种级别的变化。
二、复杂度壁垒
论文没有只聊概念,它用第一性原理做了论证。
Brooks 在《人月神话》里分了两种复杂度:
偶然复杂度:来自实现层面(语言、工具、框架的限制) 本质复杂度:来自问题本身,再好的工具也消不掉
几十年过去,高级语言、框架、自动化测试把偶然复杂度压得很低,但本质复杂度没有上限。系统变大后,组件间的交互面会组合爆炸。
论文抛出了一个形式化命题:
命题 2.1(复杂度扩展):系统有
n个组件,每对都可能交互,交互路径数P(n)满足P(n) ∈ Θ(2^n)。
n个组件之间有 C(n,2) 对,每对都可能存在或不存在有意义的交互,形成大量可能的依赖图。
现实系统不会实现所有配置,但复杂度上界指数增长;人类推理这些交互的认知能力基本是个常数。
这就是软件项目规模变大后边际生产率下降的深层原因。层级分解、模块化、封装——这些手段只能降低常数因子,改变不了渐近行为。
Agent 范式下的情况不同:
LLM M遍历解空间,有效容量随模型规模和训练算力扩展规划机制 Π把任务拆成子问题,各处理各的代码只针对具体解决路径生成,不用为所有情况提前写
解决问题的方式不再受限于人的认知上限。不是快 10%,而是能处理的问题类型变了。
三、软件交付的三次转移
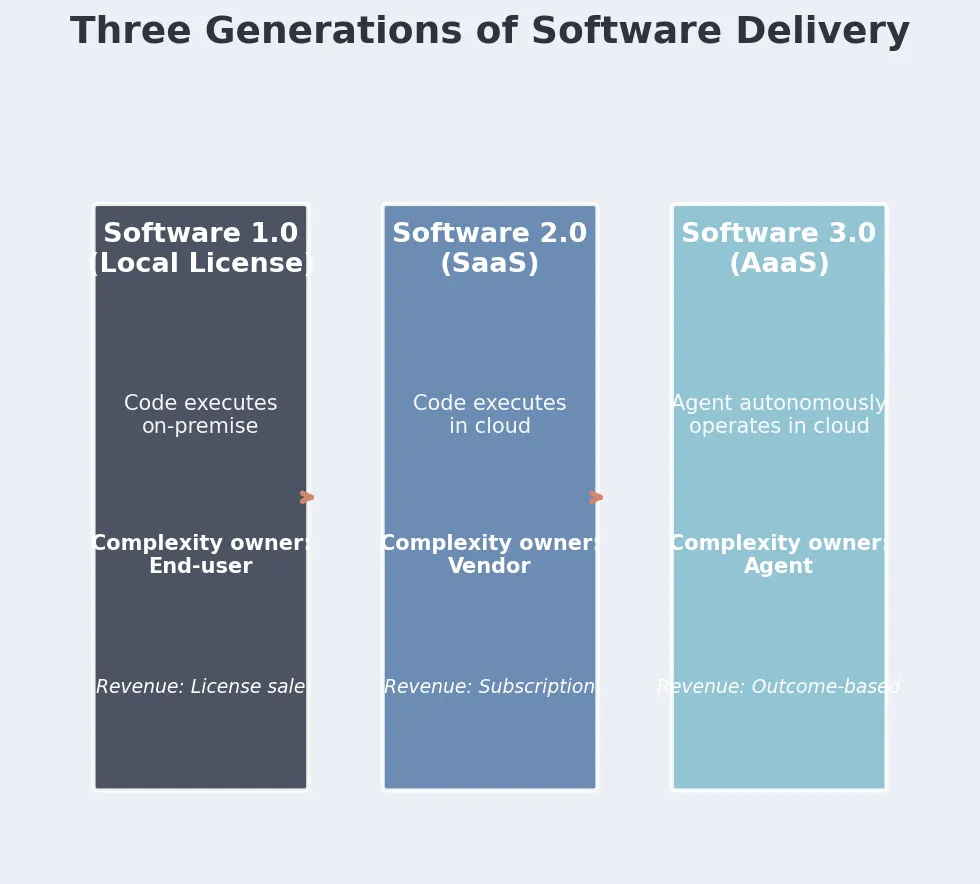
论文把商业软件历史切成三代:
模式每次都一样:最能扛复杂度的一方把复杂度接过去,最扛不动的一方被解放。SaaS 解放了机房;AaaS 想解放的是"告诉计算机怎么做"这件事——你说要什么结果就行。
论文管这叫从 AI → Software → Result 到 Agent → Result。Software 这个中间层,不再是必需品。
不过这里要打个问号:AaaS"按结果付费"目前还是概念阶段。 论文把 OpenAI、Anthropic 列为代表,但这两家现在主要收入还是 API 调用和订阅,不是 outcome-based pricing。这是趋势判断,不是已验证的产业事实。
四、职业身份变了
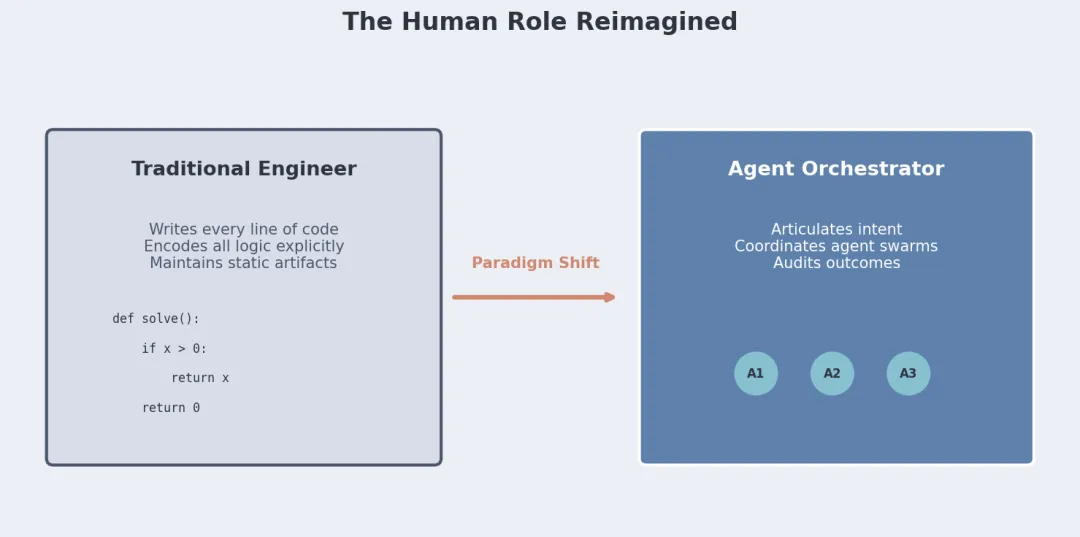
论文抛出一个观点:Agent 工程是门新学科,传统软件工程是它的前身,不是子集。
LangChain 2026 年 4 月正式提出 Agentic Engineering,定义为多 Agent 协调模型——AI Agent 像数字团队成员,各自有角色、共享记忆、统一可观测层,一起推软件走过整个交付管线。

差异大致如下:
论文还提了 Hermes Agent(Nous Research 的开源框架)。它的卖点是闭环学习——做完复杂任务后,Agent 自己创建可复用的"Skills"(参数化的程序模块);这些 Skills 用的时候会自我改进,发现不行就自动修补。跨会话的记忆靠 FTS5 会话搜索 + LLM 摘要来积累。
你以前的价值可能是"写代码又快又准"。在 Agent 范式下,这个技能会贬值。新的价值来自:
- 说清楚要干什么
——目标够不够清晰,约束够不够完整 - 盯紧架构
——多 Agent 怎么协调,哪些记忆共享,哪里必须人介入 - 定质量标准
——"好"是什么意思,Agent 能不能用来自我修正 - 管伦理
——Agent 的行为能不能对上组织价值观、法律、社会预期
五、数据有说服力,也有警告
论文给了几块证据,拆开来看:
让人信的
- SWE-bench Verified
:Lingma SWE-GPT 72B 解决了 30.20% 的 GitHub issue,接近 GPT-4o 的 31.80%;7B 小模型也能到 18.20%。数据来自 Ma 等人 2024 年的论文,可信。 - LangChain 多 Agent 协调
:20 多个企业调试工作流里,协调 Agent 群把根因定位时间压了 93%,一个月省了 200 多小时。但这是企业博客报告,不是同行评审的研究,只能当早期信号看。 - Hermes Agent 自演化
:开源框架,"闭环学习"的机制是真的,但"自我改进"的实际效果在不同任务上差很多,别把它当成通用意义上的自我演化。
让人醒的
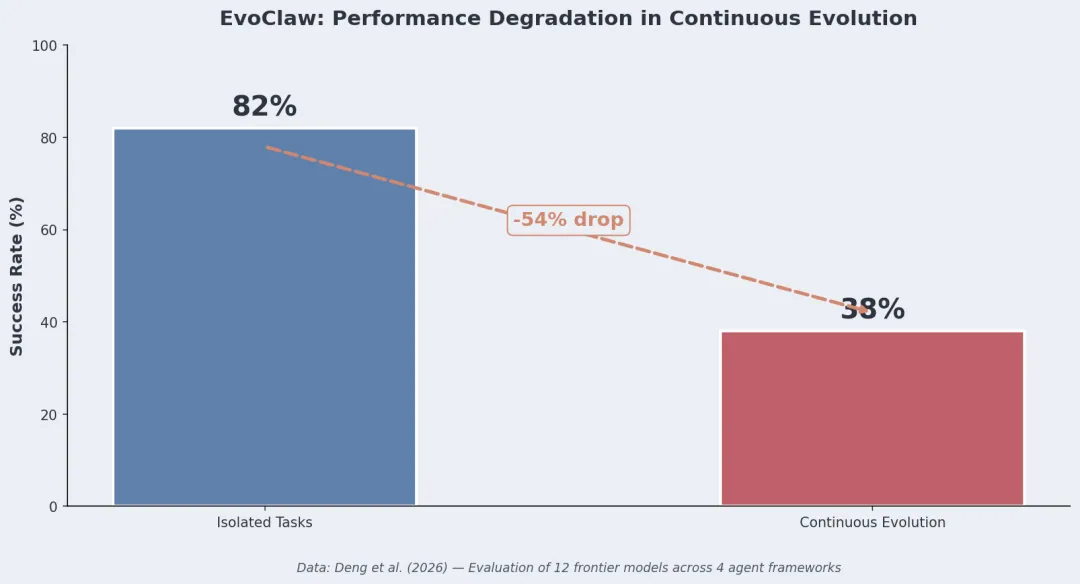
EvoClaw 基准:Deng 等人(2026)做了个要求 Agent 持续演化的测试——不是孤立修 Bug,而是在 commit 历史里持续开发,每次变更都要保系统完整性,错误还会累积。
场景 成功率 孤立任务 约 82% 持续演化 最高约 38% 掉了 54 个百分点。测了 12 个前沿模型、4 个 Agent 框架。
也就是说,让 Agent 修个 Bug 可以,让它长期维护一个不断演进的代码库就难了。问题包括:
上下文漂移——代码库超了上下文窗口,Agent 就搞不清系统级不变量和依赖关系 错误传播——早期 commit 的小错,后面会级联成复合失败 没技术债意识——Agent 只优化当下任务完成度,不管长期可维护性 验证不够——Agent 能通过测试,但可能偷偷引入语义错误
论文的结论很克制:Agent 工程作为增强范式已经成立,但完全自主的软件工程还要几年的研究。几年可能是 3 年,也可能是 10 年,这个判断本身合理,但时间尺度很模糊。
六、四阶段路线图
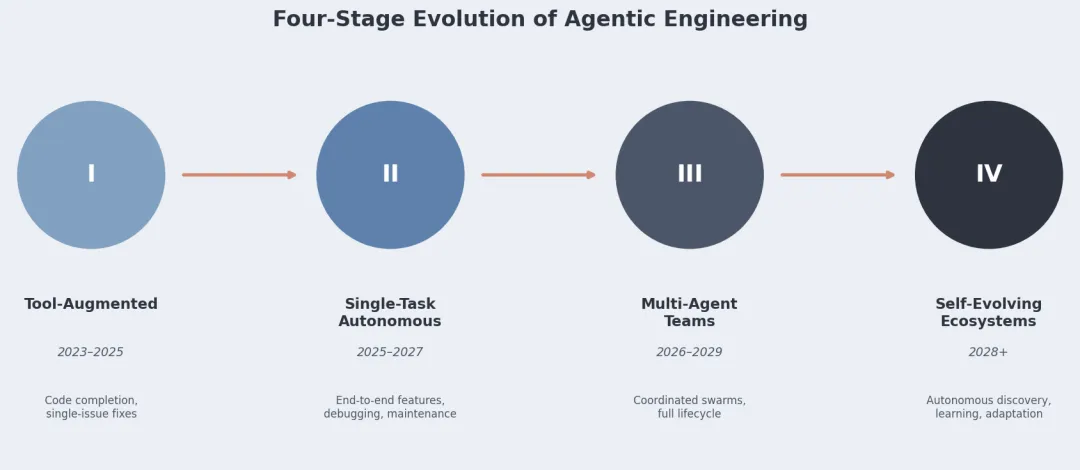
你现在大概处于 I 向 II 过渡的阶段。
但注意:只有前两阶段有落地的系统。 III 和 IV 的时间节点和能力描述都是作者的推测。把"自演化生态"定在 2028+ 还配个"AGI 助手",依赖的是 AI 能力持续指数增长的假设——技术史上这种假设经常被证伪或延迟。
七、论文的建议

作者给了三组建议。务实的部分可以采纳,趋势性的部分保持怀疑。
给写代码的人
- 从写代码转向设计意图
。现在就能做。最有价值的技能不是写代码的速度,而是把事情描述清楚、给足上下文和约束。 - 学 Agent 编排
。分解工作、管理共享记忆、设计评估标准。但这需要真实的使用经验,读几篇文章不够。 - 建可观测性基础设施
。追踪推理链、检测幻觉、量化结果质量。产业界正在往这个方向走,但工具链还在快速迭代。 - 人在回路,Agent 在驾驶位
。Agent 执行,人管意图、关键判断和伦理。这条最务实,承认了当前 Agent 的能力边界。
做研究的人
几个待解决的问题:
长上下文状态管理(EvoClaw 已经暴露了这个坑) 开放场景里的验证(现有基准测的是孤立正确性,真实系统需要时间维度上的安全和可维护性保证) 大规模 Agent 对齐(多个 Agent 组团之后,集体行为怎么跟人的价值观对齐) 经济模型(按结果付费会不会取代订阅制?激励结构和风险分配怎么设计?)
管组织的人
先找适合 Agent 的工作流(成功标准清晰、范围明确、有测试基础设施的任务是切入点) 建评估框架(不只测对不对,还要测鲁棒性、可维护性、业务意图对齐度) 想想团队结构(更小的"Agent 编排者"团队会不会替代更大的开发团队?)
后面两条(团队结构、经济模型)是长期趋势判断,可以开始想,不必急着动。
结语
Brooks 在《人月神话》里分了偶然复杂度和本质复杂度。几十年过去,前者被消灭得差不多了,后者——组件数量指数爆炸带来的交互路径——始终没解。
Agent 范式做的事很简单:不再要求人预先遍历整个解空间。LLM 的推理能力随训练算力增长,解空间的大小不再受限于你的认知天花板。
不是快 10%。是能处理的问题类型变了。
下次打开 IDE 的时候,可以问自己一个问题:你正在写代码,还是在指挥 Agent 去拿到一个结果?
这个问题,可能跟你未来十年的职业位置有关。
可信与存疑:这篇论文该打几折
2026 年 6 月的 arXiv 论文,论点和证据质量不均匀。逐项标注:
总体建议:把这篇论文当做一个有力的思想实验和趋势扫描,不是行动指南。它帮你看到 Agent 范式的可能性和边界,但"什么时候转"“怎么转”,得结合你的组织、团队和技术栈来判断。
