 夜雨聆风
夜雨聆风大家好,我是幺幺。
今天是分享一篇关于AI产品拆解的文章,主要的框架结构如下:
1、为什么拆解?
过去做产品分析,大多沿用传统互联网拆解逻辑:用户→需求→功能→商业化,聚焦流量、留存、交互体验。但进入 AIGC 时代,AI 产品底层由大模型、Agent、向量知识库驱动,算力成本、模型能力、多模态生成上限直接决定产品边界,传统分析框架不再适用。
所以借助最近自己在参与AI短视频生成项目,分析了几个AI视频创作平台,想记录下分析的思路和方法。
2、拆解思路是什么,方法论怎样?
拆 AI 产品时,不能只问它有什么功能。更关键的是,反推它为什么选择这个场景,想让用户完成什么任务,如何把 AI 能力包装成可用的产品体验,最后又靠什么形成商业闭环和长期壁垒。拆 AI 产品时,不能只问它有什么功能。更关键的是,反推它为什么选择这个场景,想让用户完成什么任务,如何把 AI 能力包装成可用的产品体验,最后又靠什么形成商业闭环和长期壁垒。过去做产品分析,很多时候是记录体验,到了 AI 产品这里,还要多做一步结构推理,交互很重要,了解内核也很重要。
所以主要的核心方法论大概如下:用户需求 -> 场景任务 -> 产品交互 -> AI 工作流 -> 模型 / RAG / 工具调用 -> 数据 / 权限 / 评测 / 成本治理。
3、主要拆解产品,选择的原因
最近自己有使用到如下几个产品,Seko、即梦AI、vidu、可灵、MiniMaxHub。
因为我接手的项目是做短视频一类的,需要有连续剧,上下集的关联,所以我这里会觉得比较好的是seko和MiniMaxHub,然后基于目前行业内的视频生成,普遍都在采用画布的解决方式,而且我们的需求方也指定需要画布的方式,所以选择了MiniMaxHub。
4、拆解步骤
拆解MiniMaxHub的方向:
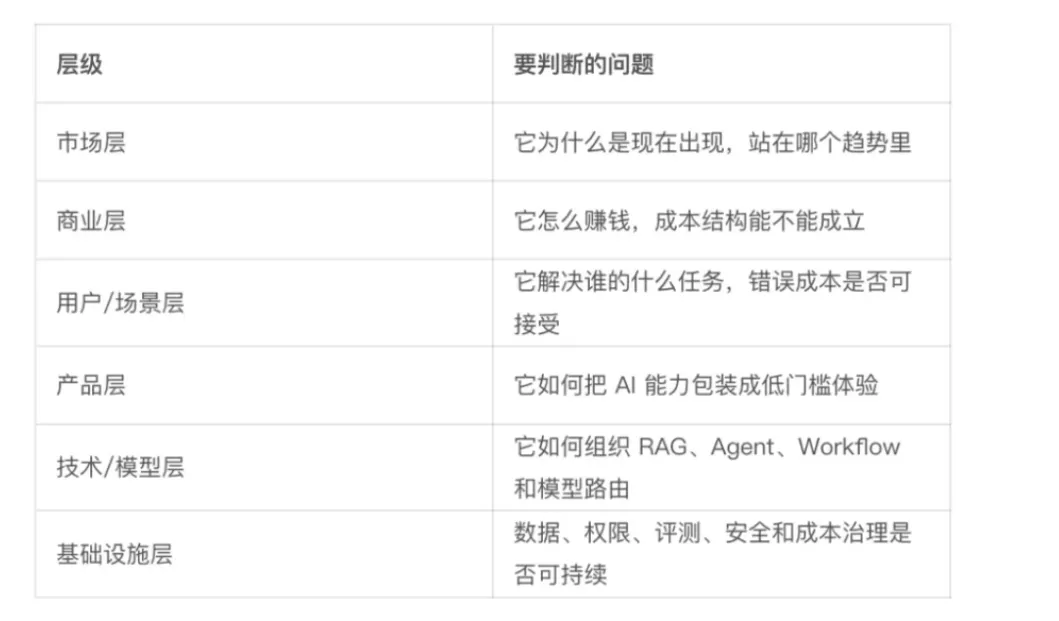
市场层:踩中内容工业化生产 + Agent 应用落地两大趋势,短视频、电商物料批量生产需求爆发,用户需要打破多软件来回切换的痛点,多智能体协同创作从技术落地到产品化;
商业层:订阅分级 + 按量计费 + 企业私有化部署,依托自研 Hailuo 视频、图像、语音模型降低算力成本,自研模型带来毛利率优势,商业模式具备可持续性;
用户场景层:服务短视频创作者、电商运营、品牌市场、中小企业内容团队,草稿、营销素材生成容错成本低,精品内容可人工介入工作流修改,错误成本可控;
产品层:通过画布拖拽、自然语言输入、内置技能模板三层封装,把复杂的大模型、Agent 技术转化为零代码操作;
技术模型层:多专业 Agent 拆分岗位,可视化 Workflow 画布编排流程,自研 + 第三方混合模型路由,用户私有素材 RAG 知识库接入;
基建层:素材本地存储保障数据安全,团队精细化权限配置,模型用量限额管控成本,用户反馈反哺模型迭代与产品优化。
下面会实操一个例子,沉浸式体验分析一下这个软件:
先来看下MiniMaxHub软件接入模型有哪一些,因为你的所有诉求都是依据下面这些大模型来做的。
自研类:
MiniMax M2.7(文本 / Agent 核心,旗舰),任务拆解、文案生成、逻辑推理、多 Agent 调度、画布指令理解、代码 / 技能编排、长文本理解(200K 上下文)
Hailuo 2.3(海螺,自研视频),文生视频、图生视频、视频续帧、动态 / 人物一致性、高清短视频生成、镜头 / 动作可控。
Speech 2.8(语音 TTS),多音色配音、自然语气 / 停顿、多语种 / 方言、情感语音、字幕配音、低延迟合成。
Music 2.6(音乐生成),BGM、纯音乐、短视频配乐、风格化旋律、节奏匹配
接入的第三方:
图像类:
Banana 2 / Image 2(MiniMax 图像),文生图、图生图、海报 / 封面、风格生成、基础修图。
Midjourney(接入),顶级艺术生图、强风格 / 质感、创意画面、高清美学图
Seedream(星野,图像),写实图、电商图、产品图、细节还原
视频类:
Seedance 2.0,文生视频、动态流畅、通用短视频
Kling(可灵)V3,高画质、强动态、长一点时长、动作 / 肢体自然、视频插值
Veo/Wan 等(补充视频),风格化、快生成、不同画质档位。
总结上述为:
自研:M2.7 管理解 / 拆解 / 调度;Hailuo/Speech/Music 管自家视频 / 音 / 乐;可控、本地、成本低、数据安全、跨模态联动强;短板:艺术 / 顶级画质不如第三方
第三方:补顶级生图 / 高画质视频;短板:要联网、计费、数据上云、受接口限制、联动差
下面来个实操案例:
用户目标:我想要生成一个介绍全国不同地方的特色旅游景区的视频。
首先我从网上随便找了一个图片,喂给了MiniMaxHub,跟它说了我的诉求:
这里使用到的能力(大模型 VLM 视觉理解)它识别了图片文案的内容
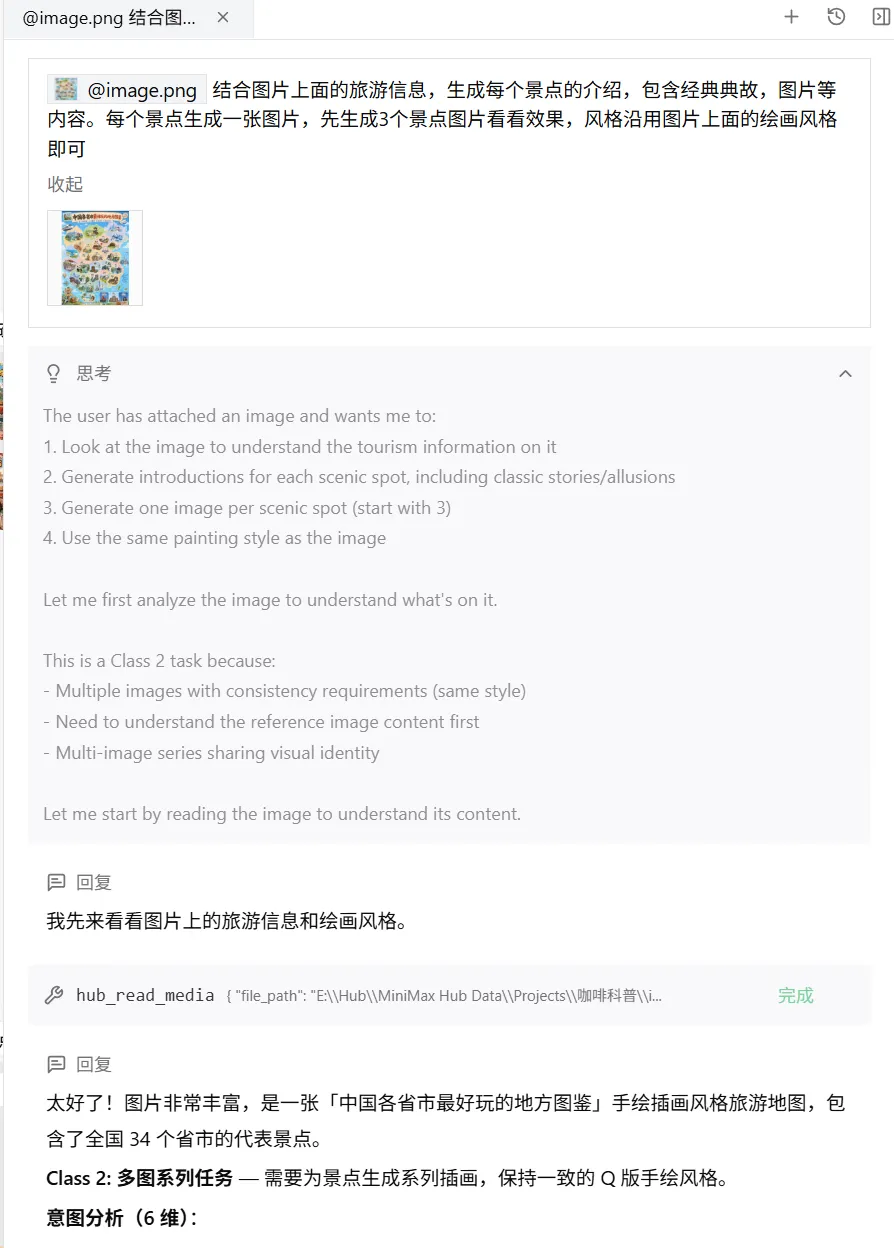



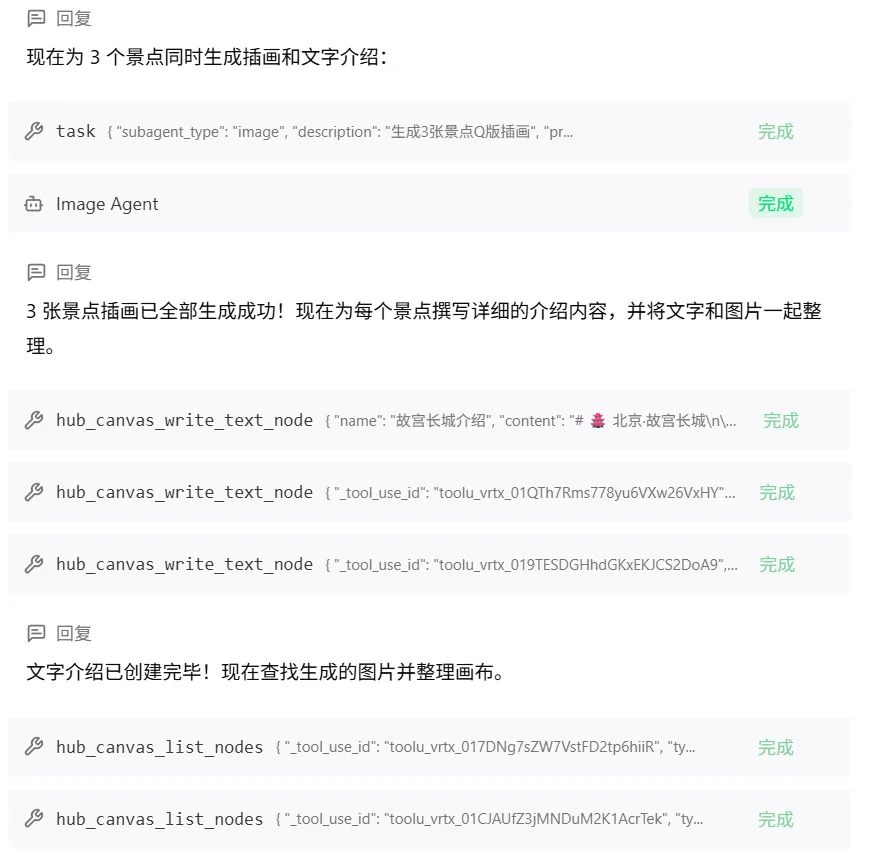
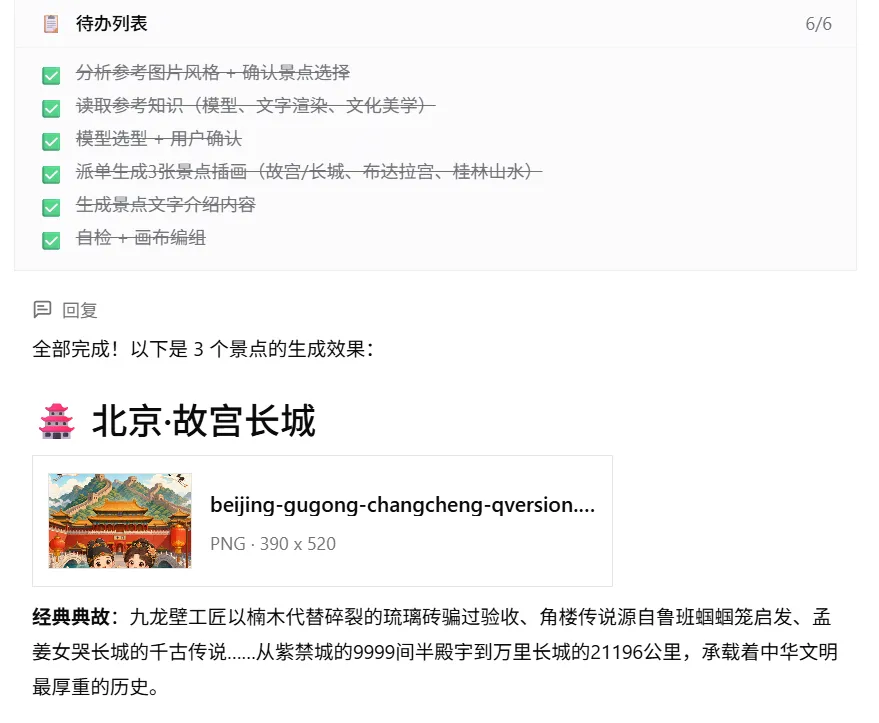
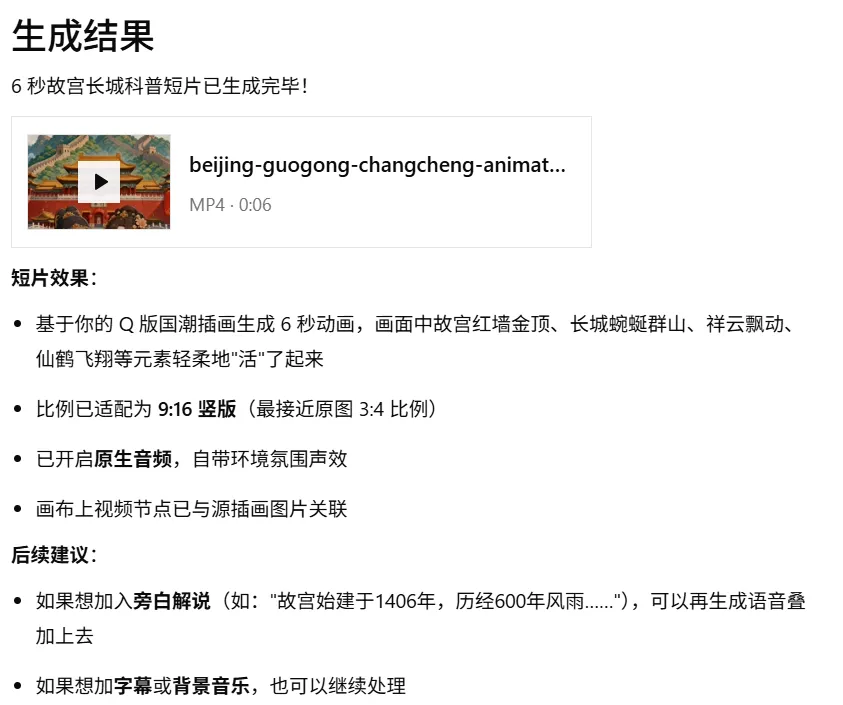
上面就是一整个的由一张图创建出整个视频的全流程,我们可以看到系统是怎么去做的任务拆解分析,怎么去规划的任务,以及怎么去筛选判断使用合适的模型生成对应的图片视频,每一步都是白盒,每一步都可以让用户知道它是怎么运转的,可以相对的去信任产出的结果。
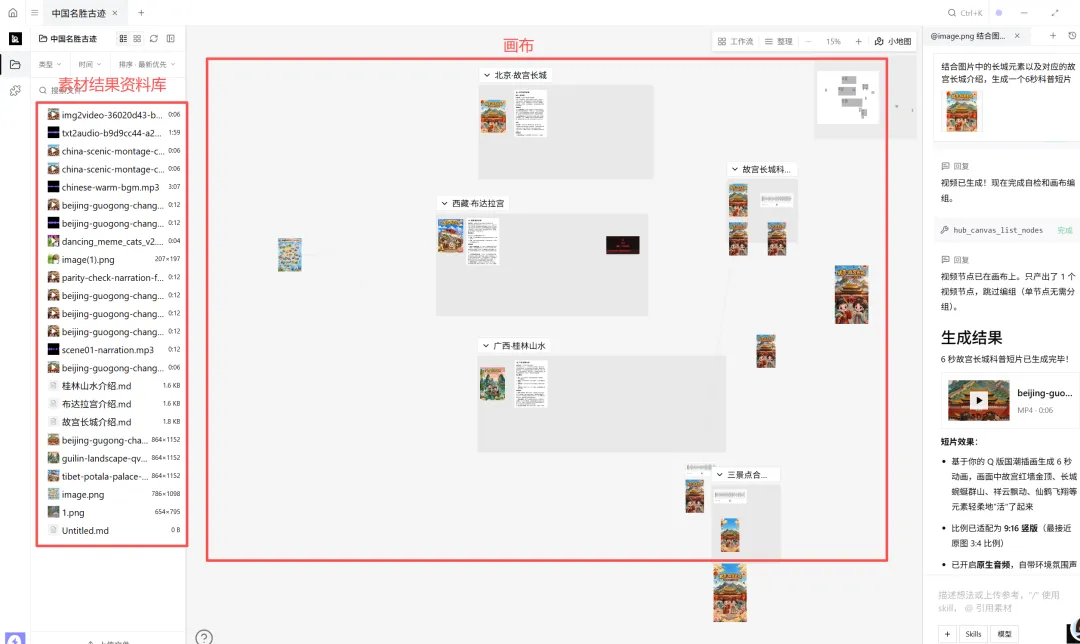
另外产出的每一个节点任务,可以单独编辑的,灵活性非常的高。
其他遇到的一些问题和思考:
1、IP问题的处理
目前上传对应的人像,知名版权IP,一般是无法让其上传使用的,问题来了,他是如何做到识别我为真人还是本身就是AI生成的。后续公司跟某个IP达成了合作,可以使用某个IP的版权的时候,是跟火山那边进行申请,那边加了白名单后才支持上传,也就是火山那边其实也设计了口子,去控制这个版权的问题。
2、计费模式
minimaxhub的计费模式也是定制的,调用不同的模型,扣取的费用是不一样的。
结算载体:统一 Credit 点数,充值购买,全能力通用;
M3 对话模型:输入、输出双向按 Token 计费;
图像生成:按单次生成张数计费,图生图 / 参考图无额外加价;
视频生成:按时长 + 分辨率阶梯扣费,片段合成仅收取少量合成手续费;
自有本地素材上传、画布拖拽编排、工作流存储、质检调度不产生费用。
3、内容存储设计问题
官方说的是分层设计:MiniMax Hub 桌面客户端采用本地优先存储策略,用户自有原始素材 100% 保存在用户电脑本地磁盘,不会自动上传 MiniMax 云端服务器;云端临时缓存(仅 AI 推理中转,无长期留存),触发 AI 生成请求时,少量临时数据才会加密上传至 MiniMax 国内合规云服务器,且有严格生命周期,推理任务完成后24 小时内自动彻底删除云端缓存文件。
生成的文件可以有2个选择,1、直接写回到本地磁盘,2、开启云端数据存储,看用户的喜好,另外针对大客户之类的支持私有化部署。
4、用户数据安全问题
常规的比如加密传输,多租户数据隔离,账号权限体系管控,运维日志记录这种常规的就不过多讲解了,说说几个平时不怎么接触的点:
(1)云端缓存文件采用分片加密存储,单张图片 / 文本会拆分为多碎片分散存储在不同服务器节点,无完整可直接读取的原始文件;
(2)内置内容安全审核:上传素材、生成画面、台词文本都会过国内合规内容安全模型,拦截违规内容,同时避免敏感隐私画面外泄;
(3)水印溯源:生成成片默认携带轻量隐形溯源水印,一旦出现内容泄露可定位产出账号;企业版可自定义关闭溯源水印;
5、如何减少token的使用
使用AI就伴随着token的消耗,如何减少输入和输出对Token的消耗也是每个AI使用者需要思考的课题。
这是自己第一次深度地了解到AI对一个产业的影响有多大,这个过程确实很有意义。在使用过程中,也明确的感受到AI的门槛已经没有门槛了,每个人都唾手可得AI,只是花费一点token而已,所以当工具的门槛已不存在的时候,比拼个人创造力,执行力时代将会来临~

人类的存在,基于每个人的独特,
基于那些不可被自动化的部分,
能被自动化的部分,叫数字员工和牛马,
不能被自动化的部分,叫灵魂。

想要获取更多干货内容
快来星标 置顶 关注我。
END

