 夜雨聆风
夜雨聆风昨天一则消息,看得我心头一震。
市场监管总局和国家发改委联合印发了《人工智能计量体系和能力建设指引(2026版)》。乍一看是个技术标准文件,没人会把它当热点。但读了三遍之后,我觉得这可能是今年以来最重要的AI政策——不是因为它说了多少新东西,而是它解决了一个一直没人解决的根问题:AI到底怎么量。
你用过AI工具,肯定遇到过这种情况。
同一个任务,问Claude、问GPT、问DeepSeek、问Kimi,四个回答。哪个好?凭感觉。同一个模型,昨天和今天回答同一个问题,语气完全不一样。是模型更新了?还是我的提示词变了?不知道。
这叫"测不准、比不了、难追溯"。
我们做企业服务的,这个感受太深了。
上个月给一个客户做数字化转型方案,客户问我:"你们用的AI模型,准确率到底多高?"我说以什么为衡量标准呢?他说,"你们做大数据做数字化的,自己都说不清楚AI到底多准,我怎么相信你推荐的东西?"
我当时确实答不上来。
不是因为我们不行。是整个行业没有一个统一的"度量衡"。你能说清楚这个模型在某个任务上的准确率达到多少,但不同厂商的评测方法不一样、测试集不一样、评估标准不一样,你根本没法横向比较。就像拿中国的秤去量美国的货——数据都对,但就是算不到一起。
这个问题卡住的不只是我。它卡住了整个AI产业的落地速度。
几个数字能说明白为什么
2026年3月,全国日均Token调用量突破140万亿。2024年初这个数是1000亿。两年涨了1400倍。
算法跑得飞快,芯片堆得凶狠,算力中心的灯亮的时间比人还长。
但怎么鉴定一个模型好不好?怎么评价一套系统安不安全?怎么追溯一次故障是谁的责任?
没有答案。
算法就是个"黑箱"——输入进去、输出出来,中间发生了什么你完全看不见。这也是校企合作中最头痛的地方。学者们做了新算法,发布论文说效果多好,但企业一测,复现不了。不是论文造假,是评估环境和标准不同。
《指引》这次要做的事情,用一句话说就是:给AI装上仪表盘。

三个维度,值得每个做AI落地的人关注
第一,算法不再"黑箱"了。 文件明确要攻关"人工智能系统内部状态监测与表征"技术。说白了,就是让模型的决策过程能追踪、能解释、能复现。以后你问"为什么AI给了我这个答案"——它得说得清楚。这对金融、医疗、法律这些高信任门槛行业,意义巨大。
第二,AI有了自己的"度量衡"。 文件提出要研制自主知识产权的AI计量标准装置。这意味着以后对比模型、评测系统,用的都是一套标准。对采购方来说是福音——不用再被各家厂商的自定义评测分数"带节奏"了。对我们这些做数据资产融资服务的也是利好——数据资产的估值一直缺少统一标尺,如果AI的计量体系能铺开,数据资产的计量逻辑也会跟着规范起来。
第三,训练数据的"源头治理"。 文件特别提到了"构建具有最高计量特性数据集、标准参考数据集和测试数据集"。注意用词——"最高计量特性"。这意味着国家要从源头打造一批基准级的数据集,作为模型训练和评测的黄金标准。数据虚标、注水、掺假,想骗过这套体系只会越来越难。

为什么说这比出新模型还重要?
你知道为什么AI落地难吗?不是技术不够好。是"信任"不够。
银行不敢把核心风控交给说不清楚决策逻辑的AI。医院不敢把诊断建议交给"测不准"的AI。中小企业老板更不用说——买个几百块的软件都要对比一下参数,你让他把几万块投进一个"说不清多好"的AI工具上,凭什么?
《指引》解决的就是这个"凭什么"的问题。它让AI从"黑箱"变成"仪表盘",从"听说过很好"变成"测出来很好"。
我们粤桂大数据帮企业做数据资产融资,最核心的壁垒不是技术,而是帮客户把数据的"可信度"建起来。银行不是听你说了就放贷,它要看你的数据能不能复核、能不能审计、能不能追溯。
AI也是一样的道理。
技术会迭代,模型会升级,芯片会换代。但"可度量、可比较、可追溯"这个逻辑,一旦建立起来,就是AI产业真正的底层基座。
从"拼算力"到"拼质量",这个转折点来了。
不是靠一个更猛的模型,而是靠一套能说清楚的尺子。

DeepSeek连续三周霸榜榜首!全球 AI 模型调用量中国占前四,数据背后隐藏了哪些造富机会?
根据OpenRouter最新数据测算,上周(6月1日至6月7日)全球 AI 大模型总调用量达到 36.1 万亿词元Token,较前一周增长 13.5%,已经连续七周上涨。大模型词元Token调用需求仍在持续释放,中国大模型的词元Token调用量还在持续高速增长,中美大模型调用量差距进一步扩大!
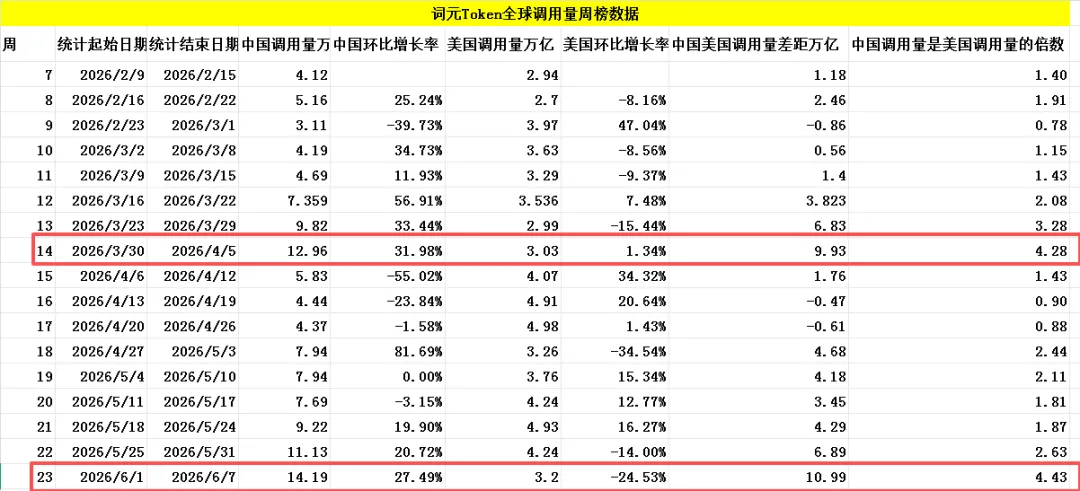
根据粤桂大数据提供的词元Token全球调用量周榜数据汇总,上榜的AI大模型中,中国AI大模型周调用量达14.19万亿词元Token,环比增长高达27.49%,这个数据是创粤桂大数据有记录以来的新高,上一次的新高是两个月以前的4月12日那周创下的12.96万亿词元Token,而另外同期美国AI大模型周调用量为3.2万亿词元Token,环比下跌了24.53%。从数据对比来看,中国大模型周调用量还是远超美国,再次以4.43倍遥遥领先,这已经是连续六周实现反超并稳居全球首位。
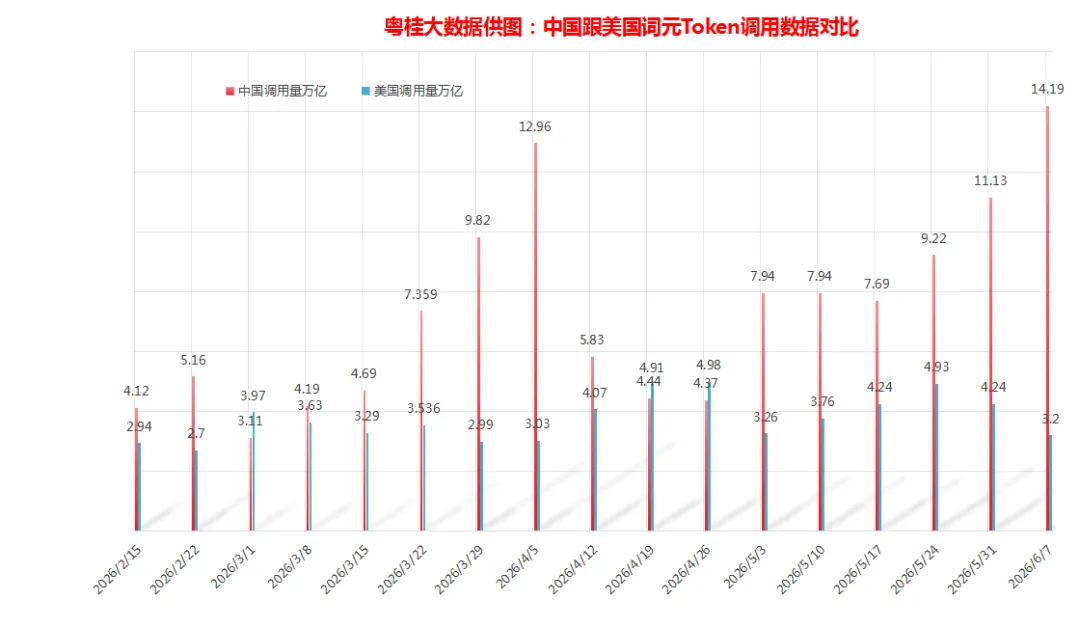
粤桂大数据记录的中国跟美国词元Token调用数据对比
截至目前,DeepSeek-V4-Flash再次霸榜OpenRouter全球AI大模型调用榜榜首位置。值得注意的是,全球调用榜前四名均为国产模型,分别是 DeepSeek-V4-Flash、腾讯 Hy3 preview,MiniMax M3,小米 MiMo-V2.5。
那现在进入人工智能时代,未来会以什么来表征人工智能的财富呢?
在人工智能时代,这一关键指标正变为词元Token——用户输入的每一个字,模型生成的每一段话、识别的每一幅图像,都在消耗词元Token。
怎么理解词元Token?简单来说,词元是人工智能大模型为了高效处理数据,把数据进行拆分后的“最小信息载体”,可以理解为“字/词片段/符号”等。比如“我爱中国!”,可拆分成“我”“爱”“中国”“!”4个词元,大家注意到没有,中国两个字居然是一个词元Token。

总之一句:中国人工智能发展迅速,以大模型调用量的大爆发来说,这里面隐藏了未来更多的投资机会,在人工智能特别是算力领域我们的机会才刚刚开始。

热门话题人工智能领域算力之词元Token:
同样的词元Token,有人烧出千万、有人烧了个寂寞,数据才是命门
DeepSeek连续三周霸榜榜首!全球 AI 模型调用量中国占前四,数据背后隐藏了哪些造富机会?
DeepSeek继续霸榜!中国大模型词元Token用周调用量连续五周超越美国:DeepSeek大模型位居全球调用榜榜首!数据背后隐藏了哪些造富机会?
稳居全球首位!中国大模型词元Token用周调用量连续四周超越美国:DeepSeek大模型问鼎全球调用榜!数据背后隐藏了哪些造富机会?
利好来了!全线大涨!美伊,突传大消息!科创板盛宴你参与了吗?华为 “韬(τ)定律”影响深远!
DeepSeek-V4问世,中美AI的天要变了!黄仁勋预言的灾难仅9天梁文锋就帮他成真了!
国家数据局:拟探索词元交易等新型交易模式,词元Token未来到底有哪些机会?
1.信息处理量
词元(token)是大语言模型处理信息的基本单位,用于衡量输入文本(如用户提问)和输出文本(如模型生成的回答)的规模。例如,一段文字被拆分为多个词元(Token),词元(token)数量越多,表示处理的信息量越大。词元(token)正成为衡量AI工作量的核心单位,其经济价值推动算力产业链变革,上游芯片与服务器厂商受益,下游企业则面临成本压力,倒逼技术优化与国产算力替代进程加速。
2.算力消耗
模型每处理一个词元(token),都需要消耗一定的计算资源(如GPU算力、内存等)。因此,词元(token)数量直接反映了模型运行时的算力消耗程度,是衡量计算成本的重要指标。
3.服务计费依据
在AI服务商业化场景中,词元(token)通常作为计费单位。服务提供商根据用户消耗的词元(token)数量收取费用,用户使用越复杂、越长的任务,消耗的词元(token)越多,费用也越高。简而言之,词元(token)既是技术层面衡量信息处理和算力使用的单位,也是商业层面衡量AI服务价值和成本的核心指标。
你对人工智能的未来发展有什么看法?
欢迎评论区留言交流
以上所有内容仅供投资者学习交流用,不作为投资建议。股市有风险投资需谨慎!
