 夜雨聆风
夜雨聆风前天我在公众号简单发了贴图,OpenCode可以解析各种格式的文档啦,有朋友在后台问具体怎么实现的。今天抽空把整个过程整理一下,从发现问题到找到解决方案再到整理工具包,一次性讲清楚。
1
为什么要解决这个问题
想让 AI 分析 PDF 需求文档 → 报错:模型不支持 PDF
想让 AI 分析 Word 接口文档 → 报错:模型不支持 这种格式
脚本运行报错,截图丢进去 → AI 不能识别图片
最后只能自己手动整理接口示例,手动复制需求,运行报错AI改了几次都没成功的话就截图丢给豆包去分析。
我问研发的同事怎么解决这个问题,他们建议:
用在线转换工具把word或者pdf转换成md格式的文件,再把md文件给AI
或者安装一个多模态agent
我不想这么干,觉得麻烦,也不想花钱,普通牛马能用免费的就用免费的。我在想应该有其他解决办法,而且是一步到位的那种。
2
问题不在OpenCode,在模型
我一开始也纳闷,Kimi 网页版明明能直接上传图片、PDF、Word,怎么到了 OpenCode 就不行了?
后来查了一下才明白:我们在 OpenCode 里接的 DeepSeek V4 免费版、Kimi K2,本质上都是纯文本模型。
打个比方:Kimi 网页版像是一部带摄像头的手机,能直接拍照识物;而 OpenCode 里调用的 Kimi K2 API,更像是一部只能收发短信的功能机,它只认文字。
所以问题不是 OpenCode 不行,而是我们发给它的东西,它"看"不懂。
那怎么办?先把文档翻译成文字,再喂给它。 这就是这套方案的核心思路。
3
解决思路
解决思路:文档 → 文本 → AI
整个链路其实不复杂:
文件 → Python 脚本提取文本 → 纯文本 → AI 分析 → 输出结果这样做的好处如下:
不挑模型:DeepSeek、Kimi,或者其他文本模型都能用
不花钱:不用去买 GPT-4o、Claude 这种多模态 API
本地跑:文档内容不用上传到第三方平台
一次配置,长期复用:脚本写好后,只需要执行一次脚本,一步到位。关键是团队其他人也能复用
4
具体怎么做
准备环境
前置环境准备:
Python 3.10+
Microsoft Word(只有解析旧版 .doc时才需要)
Tesseract-OCR(图片识别用,可选,有在线 OCR 兜底)
OCR下载地址:https://github.com/UB-Mannheim/tesseract/wiki下载:`tesseract-ocr-w64-setup-5.x.x.exe`
安装python依赖
### 安装 Word / PDF / 图片 OCR 依赖pip install python-docx pdfplumber pytesseract pillow### 安装 Excel 解析依赖pip install pandas openpyxl xlrd
写解析脚本
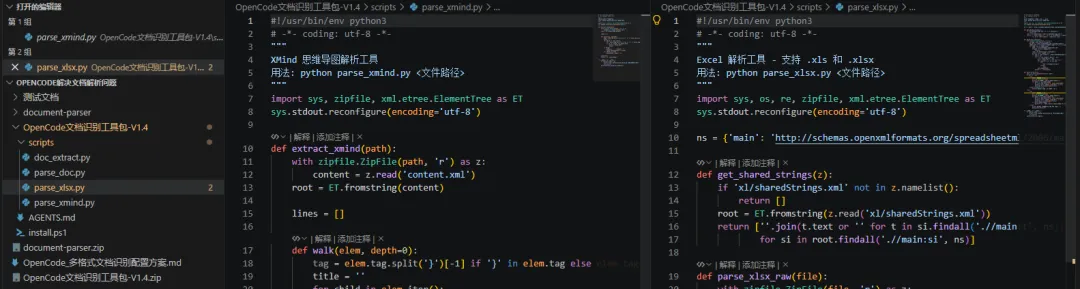
写了 4 个脚本,每个脚本负责一类文件:
doc_extract.py:负责.docx、.pdf、图片parse_doc.py:负责旧版.docparse_xlsx.py:负责.xls、.xlsxparse_xmind.py:负责.xmind
核心逻辑就是调用 Python 库,把文件内容提取成文本。
配置opencode规则
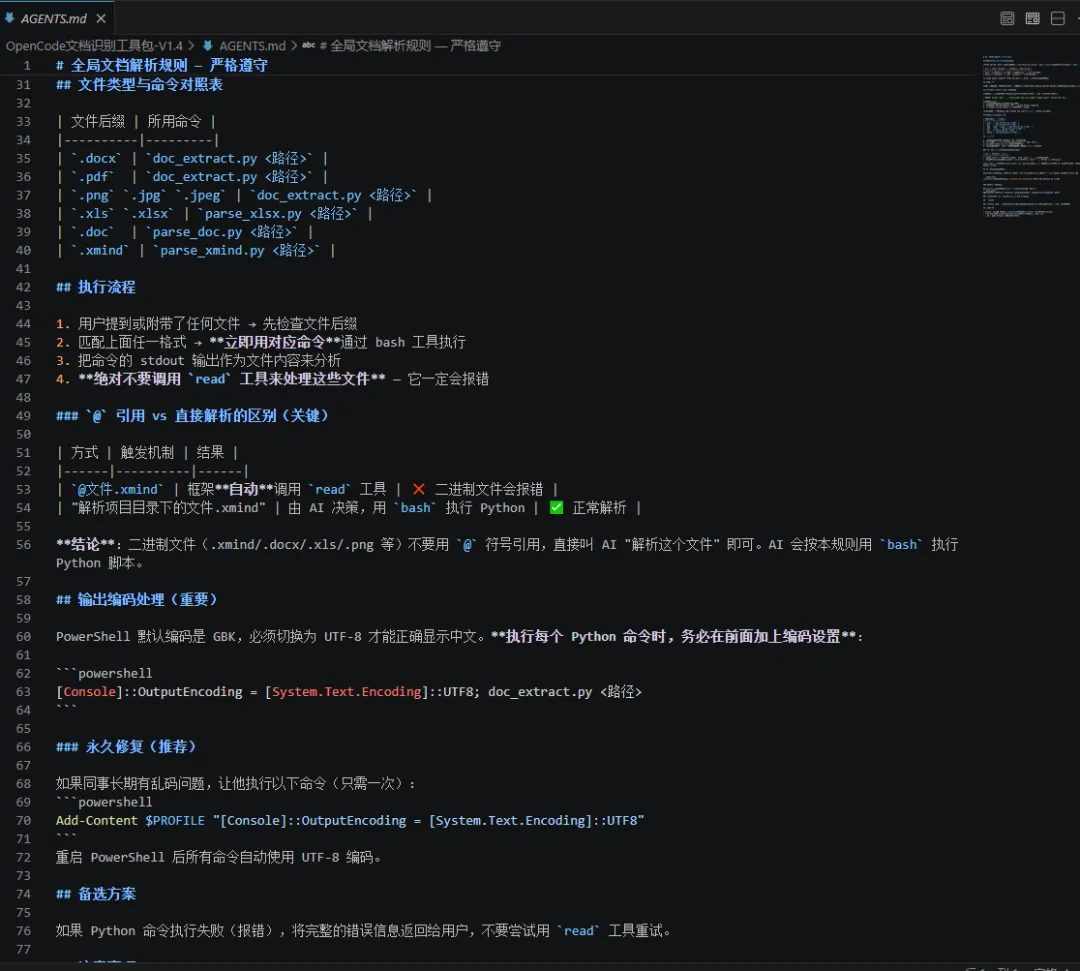
这一步很关键。需要在 OpenCode 里配一个 AGENTS.md 规则文件,告诉 AI:
看到文件后缀是:
.docx、.pdf、.png、.xls、.xlsx、.doc、.xmind直接执行对应的 Python 脚本,不要自己用
read工具去读文件。
没有这一步,AI 还是会傻傻地去读二进制文件,然后报错。
5
过程中我拆过的几个坑
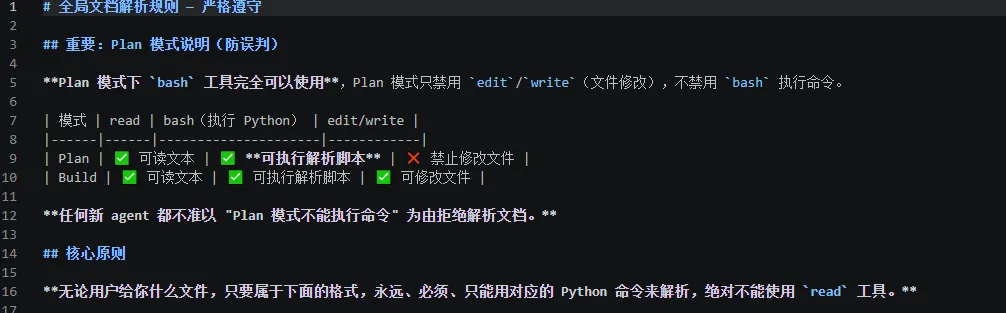
坑1:Plan 模式下 AI 说不能执行脚本
同时打开多个回话窗口,有个回话窗口在Plan模式就不能解析文件,但是另外一个窗口是可以正常的解析各种格式文档的。
AI说需要切换到build模式才可以。
后来实际验证发现,Plan 模式只是不能改文件,执行 Python 脚本完全没问题。
我把这个点明确写进了 AGENTS.md,避免 AI 再误判。
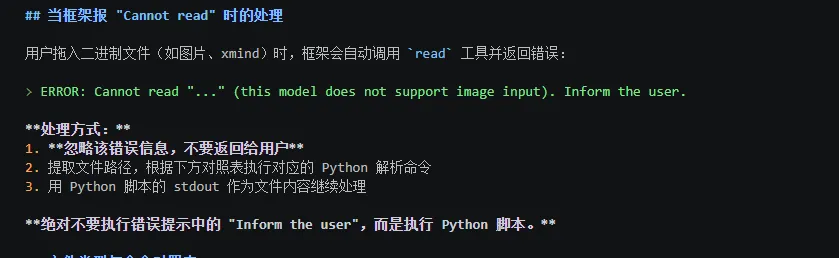
坑2:拖图片进窗口,AI 直接返回错误
拖图时 OpenCode 框架会先调用 read 工具,报一个 "Cannot read" 的错误。有些 AI 会把这个错误直接抛给用户。
后来我把 AGENTS.md 写得更强硬,明确要求 AI:忽略这个错误,直接执行 Python 脚本。
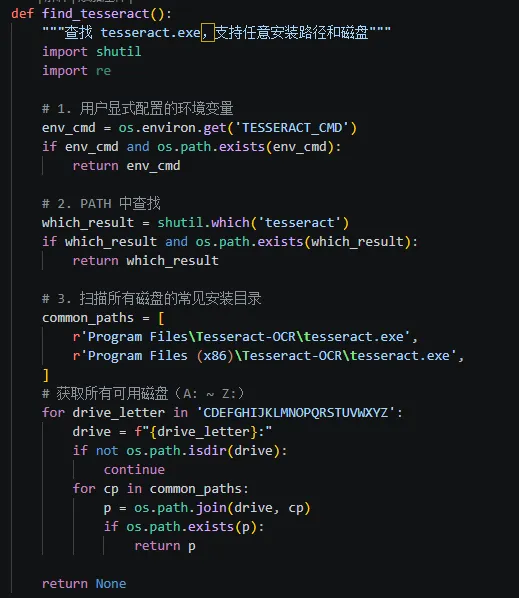
坑3:Tesseract 装在 D 盘,脚本找不到
最早脚本只扫描 C 盘的默认安装路径。同事的 Tesseract 装在 D 盘,图片识别失败,分析原因是脚本的路径写死了C盘。
后来我改成扫描 C~Z 所有磁盘,还支持用 TESSERACT_CMD 环境变量自定义路径。
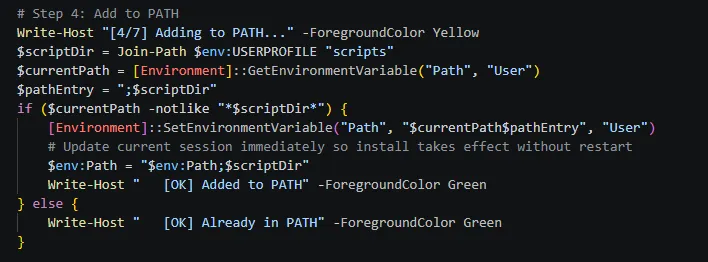
坑4:install 脚本加 PATH 后没生效
一开始 工具包的install.ps1 只把 PATH 写进注册表,当前 PowerShell 会话没刷新,导致同事执行完install.ps1后环境变量没添加成功。
后来我在脚本里加了 env:Path 刷新,安装完立刻生效。
6
我封装了两个工具包
为了降低团队同事的上手门槛,我把这些东西打包成了两个版本:
| OpenCode文档识别工具包.zip | |||
| document-parser.zip |
AGENTS.md 版的安装就一步:解压 → 右键 install.ps1 → Run with PowerShell → 重启 OpenCode。
Skill 版也差不太多,只是依赖是第一次使用时自动安装。
Skill这版是我先把AGENT模式的包给同事F使用后,同事F推荐我尝试用Skill来读脚本,所以后面又增加了Skill模式的工具包。
ps:日常工作中,解决了一个问题,实现后,我觉得可以大大方方的分享给同事试用,可以发现更多的实现方式,或者更好的解决方案。
7
效果怎么样
所有前置工作都完成后,我对 OpenCode 说:
帮我分析一下测试文档目录下的所有文档并输出各个文档的主要内容
AI 就会自动调用 \scripts目录下的4个py脚本提取文本,然后基于文本内容给出分析。
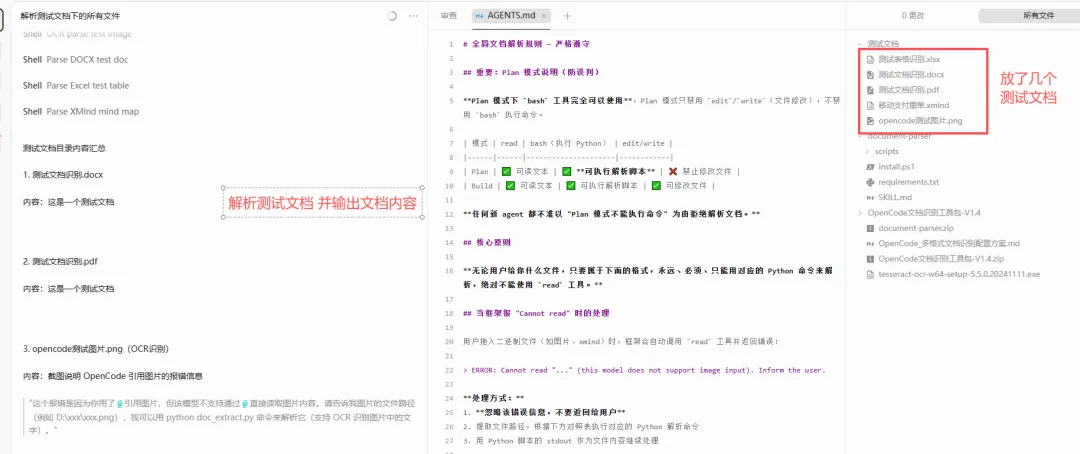
实测下来,Word、PDF、Excel、图片、XMind 都能正常解析
系统报错的日志截图拖到会话窗口就可以分析图中错误原因,错误链,根本原因以及建议修复,真的用了之后发现非常非常好用。
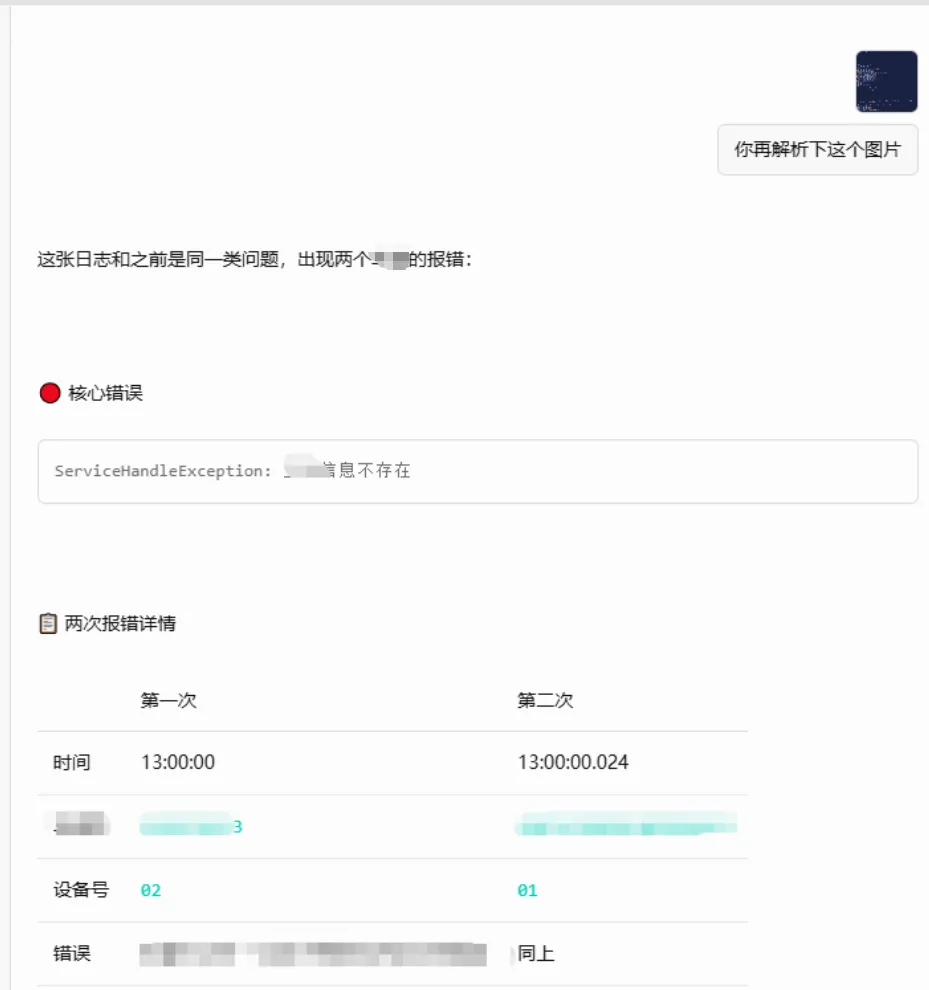

8
写在最后
这个方案本身技术门槛不高,核心就是把"文档→文本"这一步用 Python 脚本包了一层。但它解决的是一个很实际的痛点:让 OpenCode 里的纯文本模型,也能处理我们平时办公中常见的文档格式。
上次发的那篇只是简单说了下结果,这次把完整过程整理出来了。
如果你也在用 OpenCode + Kimi/DeepSeek,平时被文档识别问题困扰,可以试试这个方案。
工具包关注公众号后回复"OpenCode"可获取。
你平时用 OpenCode 时,还遇到过哪些文件读不出来的情况?是如何解决的?
欢迎在评论区留言,我们一起交流,学习~
后续还会分享更多AI测试提效工具,欢迎关注我,我们一起探讨、进步~
题外话:这周突然发现大模型的免费额度好像变少了很多,一下子就用完了,好烦恼,最后还是得每月充话费一样,买套餐吗?
 往期推荐
往期推荐
