 夜雨聆风
夜雨聆风帮一个电商客户搭推荐系统那会,没先上模型。
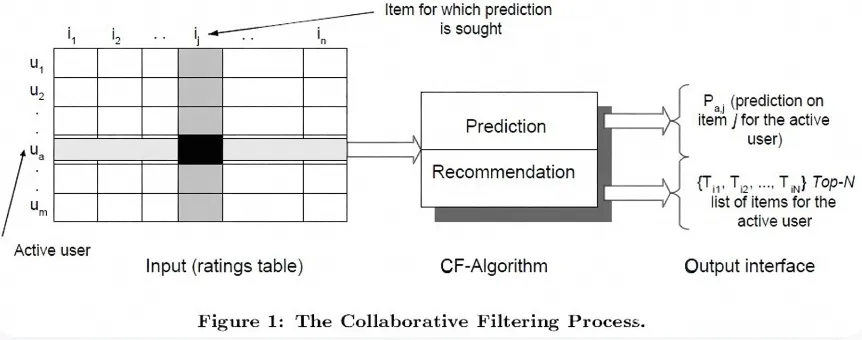
我习惯先用手边最熟的家伙把逻辑跑通再看要不要换。那次用的Excel。
─────────────────────────
从Excel开始
他是卖女装的,品类挺固定。我没去折腾用户聚类那一套,直接算商品跟商品的关系——COUNTIFS拉浏览记录,看哪两个商品同时被同一个人看过。跑完是一张商品x商品的共现矩阵。
连衣裙跟打底裤一起出现的次数特别高。能说明问题。
Item-based就这么回事。在他这个数据上够用。后来做过好几个项目,品类别太宽的我都先试Item-based。
不是它多好,就是不出错。打底裤搭连衣裙,不会因为用户今天心情好不好就变了。
不是Item-based多好,就是不出错。商品跟商品的关系,比用户跟用户的关系稳。
▎ 相似度换了三次
相似度我换过三次。也不是什么有计划地AB测试,碰到问题了就换。
一开始用的余弦。它只看方向不看长度——张三什么都爱点,他的评分向量跟竹竿一样长,但方向对上了就算对。这个特性在行为数据飘忽不定的时候还挺好用。
后来碰到一个项目,打分习惯差太多了。有人最高只打3分有人全5分。余弦全算出了不该是邻居的邻居。换了皮尔逊。皮尔逊会先减掉每个人的平均分再比,代价也有——两个人得有足够多的共同评分商品,数据一稀疏就傻了。
再后来有个客户干脆没评分,只有点击。余弦跟皮尔逊都指望不上,Jaccard硬算的,两个人都点过的除以总共点过的。东西不复杂,反而最稳。
方法 | 我什么时候用 | 依赖条件 |
余弦相似度 | 评分+行为混合,默认先用这个 | 需要数值型特征向量 |
皮尔逊 | 打分习惯差异大 | 两用户要有足够共评商品 |
Jaccard | 只有点击/浏览 | 有交集就能算 |
三种轮过一遍,脑子记住的不是谁好谁不好,是每种卡在什么地方过。后来新项目上来,扫一眼数据大概就知道该用什么。不是总结出来的,是做多了。
三种方法轮一遍,记住的不是谁更好,是每种卡在什么地方。新项目扫一眼数据就知道该用什么。
────────────────────────
协同过滤够不着的地方
协同过滤最舒服的状态是数据够了。新用户冷冰冰进来什么行为没有,新商品上架了没人点过——这时候协同过滤使不上力。
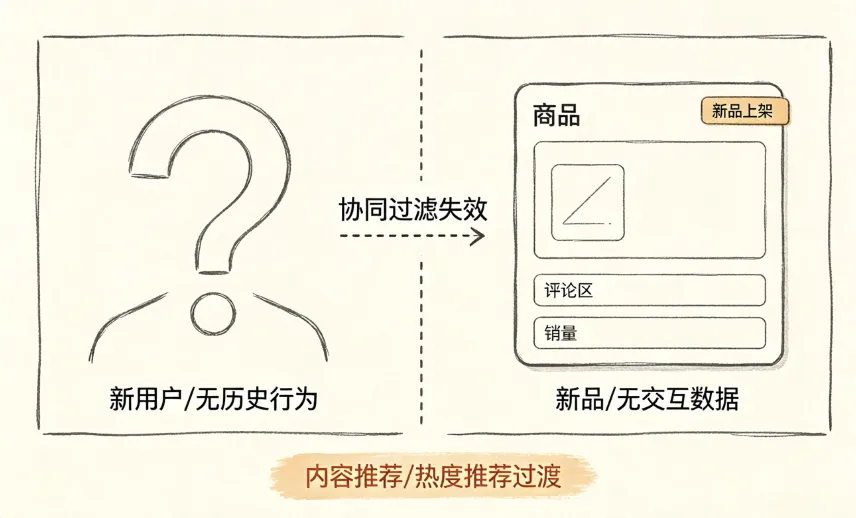
▎ 冷启动二选一
做法挺直接的。新用户先推热榜,等点过两三个商品立刻切Item-based。就这一个切换,比一直推热榜高了大概20%的转化。新品上架前运营把品类标签风格标签填好,靠标签推,攒够点击了再切回来。
老用户也有一类不好办的情况。数据看着不少,全扎在促销爆款上了。这时候Item-based推出来的东西全是同类爆款,画像是歪的。我把同品类权重砍一半,掺30%没在这个用户历史里出现过的品类新品。阈值设在用户80%以上的互动都集中在单一品类时触发。
这些办法都不算完美但能跑。协同过滤还有管不到的——搜索词特别长、语义特别冷的用户。协同过滤靠的是"跟这个用户行为相似的人也喜欢什么",搜索词太奇怪就找不到邻居了。
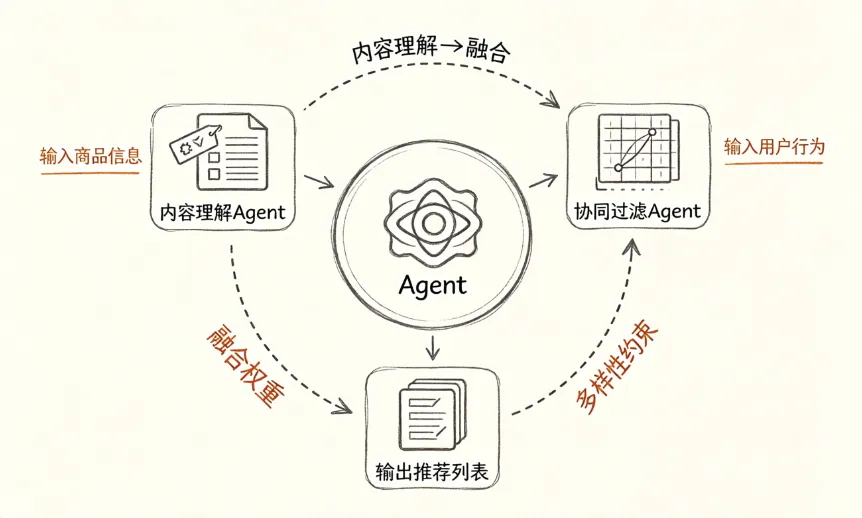
▎ AI补协同过滤的缺口
AI补的是这块。从搜索词里拆维度——夏天穿的、风格偏正式、场景面试、预算不高——然后在向量库里做多维匹配。不是找相似用户了,是找跟这些维度都匹配的商品。
举个例子。有个用户搜了"夏天穿的轻薄西装""面试正装不要太死板""初入职场穿搭",然后点了两件浅灰色blazer。协同过滤按她点的blazer找人——也点过相同blazer的人还点了什么。AI从搜索词里拆出季节、风格、场景、预算,在库里同时匹配。
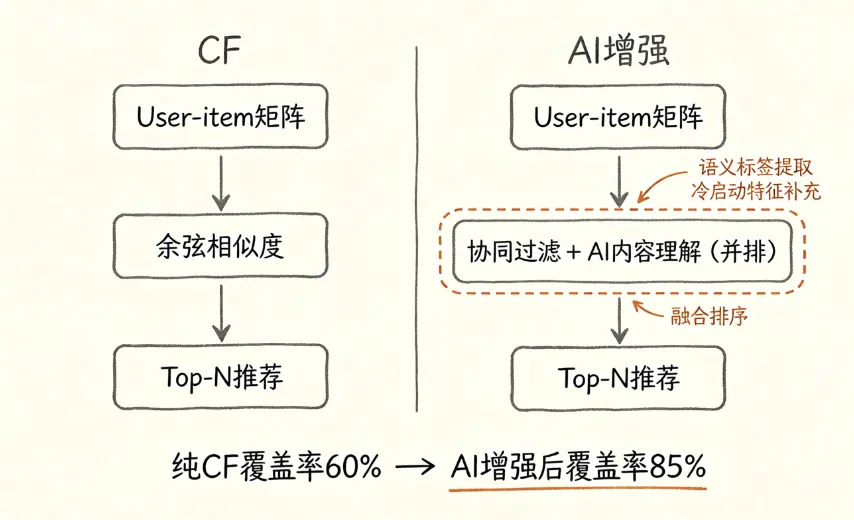
那个女装客户的数据:纯协同过滤点击率大概3.8%,加query理解加embedding到了5.2%。涨最多的不是热门,是长尾。协同过滤根本够不着的那些冷门搜索,AI能兜住。
纯协同过滤3.8%,加AI到5.2%。涨最多的不是热门,是长尾——协同过滤够不着的冷门搜索,AI能兜住。
对比项 | 协同过滤 | 加一层AI之后 |
推荐点击率 | 3.8% | 5.2% |
长尾品类覆盖 | 找邻居困难 | query语义匹配兜底 |
新品上架 | 等数据积累 | 图文描述直接入向量库 |
─────────────────────────
搭完挂上去就不管了
▎ 画像不带标签,拆三层
画像我没用那种"年轻女性喜欢运动预算中等"的标签。太粗了,啥都能套啥都不准。
拆了三层。年龄地域注册来源这些不怎么变的当锚点。近30天点了什么品类什么价格带搜了什么词,30天一滚。从行为推算出来的——"可能准备结婚""可能在换季"——写清楚置信度。
推荐的时候锚点兜底,行为层主推,推理补几件做试探。
画像是活的。每天算跟每周算效果差不少,这个差别比换算法还大。不是直觉说的,我们拿同一个月的数据跑了两次对比出来的。
画像是活的,每天算跟每周算效果差不少。这个差别比换算法还大——天天跟数据打交道的人才懂。
▎ 挂的三个定时任务
几个固定活挂到OpenClaw上让它自己跑。
凌晨两点拉一次热榜——各品类最近24小时Top100,拆开推给对应人群。
每周拉一次长尾曝光不足但评分高的,混进推荐池限流推送。
这些东西不靠Agent盯着,人自己盯不了。不是不勤快,是记不住。
yaml
# OpenClaw Agent配置:推荐系统agents:hot_rank_refresh:trigger: cron(02 * * *)task: >查询每个品类最近24小时点击Top100商品,按品类分组写入Redis(key: hot_rank:{category}:{date})constraints:- 只读操作,不修改商品数据- 超时300秒user_profile_weekly:trigger: cron(04 * * 1)task: >读取最近7天用户行为,更新行为层:品类偏好分布(按点击占比)、价格带偏好(加权平均)、搜索词聚类(keybert抽Top3关键词),推理层重新打分标置信度,写Redis(key: user_profile:{uid})constraints:- 单用户计算不超过30秒- 置信度低于0.5的推理标签标___PH___STR0_auto_tag_new_item:trigger: webhooktask: >读商品标题、主图、描述文本,提取品类名称、风格属性、季节属性、适用场景四个维度的标签,写标签系统,置信度低于0.6标___PH___STR0_constraints:- 单次不超过10个商品- 标签值从预定义词表选择max_runtime: 120
跑起来之后基本不管了,偶尔看指标调阈值。
▎ 数据不到家别急着上AI
以前干过一件蠢事。有个项目数据还不到五万条,上来就想全上AI端到端。AI在小数据上找的相似性基本是瞎猜,协同过滤好歹能找到几个硬邻居。
后来就分清楚了。
行为数据量 | 做法 |
<5000条 | 热榜+规则,不上协同过滤 |
5千~10万 | Item-based协同过滤为主 |
10万~50万 | 协同过滤打底,AI二层做query理解和长尾 |
>50万 | embedding召回+精排,协同过滤当基线 |
实际很少只用一种。热门品类协同过滤快,长尾切AI语义。混排兜一下多样性,列表不全是类似的东西就行。
协同过滤最好自己上手算一遍,Excel也行。算跟不算是两回事。
