 夜雨聆风
夜雨聆风AI 自动化 Agent 框架:移动端 UI 测试的架构设计与模式选择
上一篇文章讲了 AI vs 传统方案怎么选。这一篇深入 Agent 内部——框架选型、核心模式、架构决策。
一、从"调模型"到"建 Agent":为什么需要框架
上一篇文章的核心结论是:AI 自动化和传统自动化不是替代关系,而是共生关系。
但如果你决定上 AI 方案,下一个问题就是:怎么把一个大模型变成一个能稳定执行测试的 Agent?
直接调 API 很简单:
response = client.chat.completions.create( model="gpt-4o", messages=[{"role": "user", "content": screenshot + "点击登录按钮"}])# 拿到坐标 → 点击 → 下一步截图 → 再来一次20 行代码就能跑通一个 demo。但 demo 和产品之间,隔着一整套工程问题:
• 上下文长了模型开始"遗忘"任务怎么办? • 同一张图推理两次坐标差 20px 怎么办? • 模型返回了非法格式怎么兜底? • 复杂任务 20 步,怎么保证不跑偏? • 怎么知道 Agent 真的做对了而不是"看起来做对了"?
这些问题不是换个更强的模型就能解决的。Agent 框架解决的是"如何让 LLM 在不确定环境中可靠地执行多步任务"这个系统工程问题。
二、Agent 框架选型:四类方案
2.1 通用 Agent 框架
| LangChain / LangGraph | |||
| AutoGen | |||
| CrewAI | |||
| OpenAI Agents SDK |
这些通用框架的共同问题:太重了。
以 LangChain 为例,在移动端 UI 测试场景里,你需要的是:
• 对截图做推理(不是文本 RAG) • 操作手机(不是调用 API) • 每步 2-5 秒延迟(框架本身的 Python 开销是次要问题)
框架的抽象层反而成了累赘。这也是为什么移动端 AI 测试项目几乎都是自研 Agent 循环。
2.2 移动端 Agent 方案:值得借鉴的架构思路
一个常被混淆的概念:AppAgent、Mobile-Agent 这些不是 Agent 框架——它们是具体的 Agent 实现,就像你不能用"淘宝 App"来开发自己的电商 App 一样,你也不能用 AppAgent 来构建自己的测试 Agent。
但它们的设计思路值得拆解。以下是几个有代表性的移动端 Agent 方案及其核心架构创新:
| AppAgent | ||||
| Mobile-Agent | ||||
| UFO | ||||
| OS-Copilot |
AppAgent:先探索、后执行
AppAgent 的核心创新不是 Agent 框架本身,而是一种二阶段工作流:
阶段一:探索 打开应用 → 截屏 → 描述页面 → 记录可操作元素 → 尝试点击 → 观察结果 → 继续探索下一页 → 生成「经验文档」阶段二:执行 读取经验文档 → 任务匹配已知页面 → 直接定位操作这个思路解决的核心问题:Agent 第一次见一个页面时从零推理,又慢又容易错。 探索过的页面就有了"记忆"。
可复用的点:对于高频回归场景,可以在版本稳定后跑一次探索,将页面信息结构化存储,后续执行直接查表定位。本质上是"用空间(探索时间)换时间(执行速度)"。
问题:探索阶段耗时巨大(一个完整应用可能几小时),且 UI 改版后经验文档需要重建。
Mobile-Agent:多角色分工
Mobile-Agent 的架构将一次操作拆分为四个独立推理步骤:
规划 Agent → 阅读任务,拆分为子步骤序列 ↓决策 Agent → 看当前截图,决定"这一步具体操作什么" ↓反思 Agent → 操作完成后看新截图,"上一步达到预期了吗?" ↓管理 Agent → 协调以上三者,出现分歧时仲裁优势是权责分离——每个 Agent 只聚焦一类判断。问题是延迟叠加:一次操作四次模型调用,单步延迟 8-20 秒。
可复用的点:反思 Agent 的"事后验证"思路值得独立出来。这个"事后验证"的思路值得独立出来——例如把验证放到所有步骤完成后,而不是每一步都反思,可以避免延迟叠加。AutoPilot 的双模型断言就用了这个策略。
UFO:用图建模跨应用交互
微软的 UFO 针对 Windows 桌面端,但其核心数据结构 ControlGraph 对移动端跨应用测试很有启发:
ControlGraph(应用跳转有向图): 微信 ──"分享"──→ 朋友圈 微信 ──"支付"──→ 微信支付 微信 ←──"返回"── 朋友圈 系统桌面 ──"通知栏"──→ 系统通知面板 任意应用 ──"权限弹窗"──→ 系统权限对话框这个图的用途:Agent 需要从应用 A 的页面 X 跳转到应用 B 的页面 Y 时,ControlGraph 提供最短跳转路径。 不需要每次推理"怎么过去",直接查图。
可复用的点:跨应用测试(如"从微信分享到朋友圈")是传统自动化最头疼的场景。ControlGraph 可以离线构建一次,跨多个测试用例复用。
2.3 Midscene.js:字节跳动的跨平台实践
如果说前面的方案都是学术界的探索,那 Midscene.js 是目前工业界最接近「正经 Agent 框架」的东西——由字节跳动 Web Infra 团队开源(MIT,GitHub 13K+ Star),支持 Web / Android / iOS 三端,提供统一的 JavaScript SDK。
它的架构思路值得单独拿出来讲,因为和 AutoPilot 走了不同的路线,但面临同样的约束。
核心架构:截图 + DOM 提取 + 元素 ID 映射
Midscene 的感知方案不是纯视觉,也不是纯 UI 树,而是一个混合编码系统:
阶段一:页面上下文获取 截图(CDP/ADB) + DFS 遍历 DOM 树 → 提取可交互元素 → 为每个元素生成稳定哈希 ID(基于内容和位置)→ 建立 ID↔DOM 映射缓存阶段二:AI 规划 截图(含元素标记框) + DOM 描述文本 + 用户指令 → 发送给 VLM → 返回结构化操作序列(Input/Tap/KeyboardPress... + 元素ID)阶段三:元素验证(四层策略) XPath 匹配 → 缓存匹配 → Plan 结果 → AI Fallback(二次模型调用)阶段四:执行 验证通过 → 对目标元素执行实际交互关键设计:元素哈希 ID。 Midscene 在扫描阶段为每个 DOM 元素生成稳定哈希,这个 ID 在 AI 推理和执行之间充当桥梁——模型看到的是标记后的截图和元素列表文本,返回的是元素 ID,执行层靠 ID 映射回真实 DOM 节点。相比纯坐标定位,这种方式精确度更高;相比 XPath,对 UI 变化更有韧性。
两种执行模式:自动规划 vs 即时操作
aiAct("打开 Twitter 并发布一条推文") // AI 自动拆解为多步,ReAct 循环aiTap("登录按钮") // AI 只负责定位这一次,立即执行aiInput("搜索框", "关键词") // 同上aiAssert("页面显示搜索结果") // 自然语言断言这个区分很务实。aiAct() 对应 ReAct 模式,适合探索性任务;aiTap()/aiInput() 只让 AI 做一次定位,不负责规划,更快更可预测。AutoPilot 的自由模式/严格模式也是类似的思路——但 Midscene 把它分成了不同的 API 入口。
VL 模式:纯视觉定位
Midscene 支持跳过 DOM 提取,只用截图 + 视觉语言模型(如 Qwen-VL、UI-TARS)做坐标定位。这种模式下 token 消耗更少、速度更快,但精确度略逊于 DOM 辅助模式。本质上是让用户在「成本」和「精度」之间自己选。
缓存与报告
• 自动缓存:首次 AI 推理后缓存结果,后续相同操作直接回放,不消耗 token。和 AutoPilot 的脚本编译目标一致,但实现方式不同——Midscene 是自动缓存,AutoPilot 是手动编译为 YAML。 • 可视化报告:自动生成 HTML 报告,含动画回放和 AI 决策详情。AutoPilot 目前只有截图标注,这一点 Midscene 做得更完善。
局限性
Midscene 虽然覆盖了 Android/iOS,但它本质是 Web 优先的设计——DOM 提取、元素 ID 映射这套机制在移动端原生页面上不可用(需要用 UI 树替代),在 WebView 和纯 Canvas 渲染的应用上也受限。另外 YAML 脚本目前只支持 Web 端。
2.4 那么,有真正的「移动端 Agent 框架」吗?
严格来说,目前没有成熟的、通用的移动端 Agent 框架。 Midscene.js 是目前最接近的一个,但它仍是 Web 优先的设计,移动端支持在完善中。
原因在于:一个 Agent 框架要成立,需要抽象出可复用的通用组件。但在移动端 UI 操作这个领域,最核心的三个环节——感知(如何"看"屏幕)、行动(如何操作设备)、环境(Android/iOS/鸿蒙的差异)——都高度平台相关且碎片化严重,很难抽象成一套通用接口。
实际工程中的做法是:搭自己的 Agent 循环(200-500 行),集成设备抽象层,然后根据场景选择感知策略。
AutoPilot 就是按这个思路做的——下一节展开。
三、AutoPilot 的 Agent 架构:一个自研案例
AutoPilot 没有使用现成框架,而是根据移动端 UI 测试的需求自己实现了一套 Agent 体系。以下拆解它的核心设计——不是为了说明"这样做最好",而是展示在特定约束下的具体工程选择。
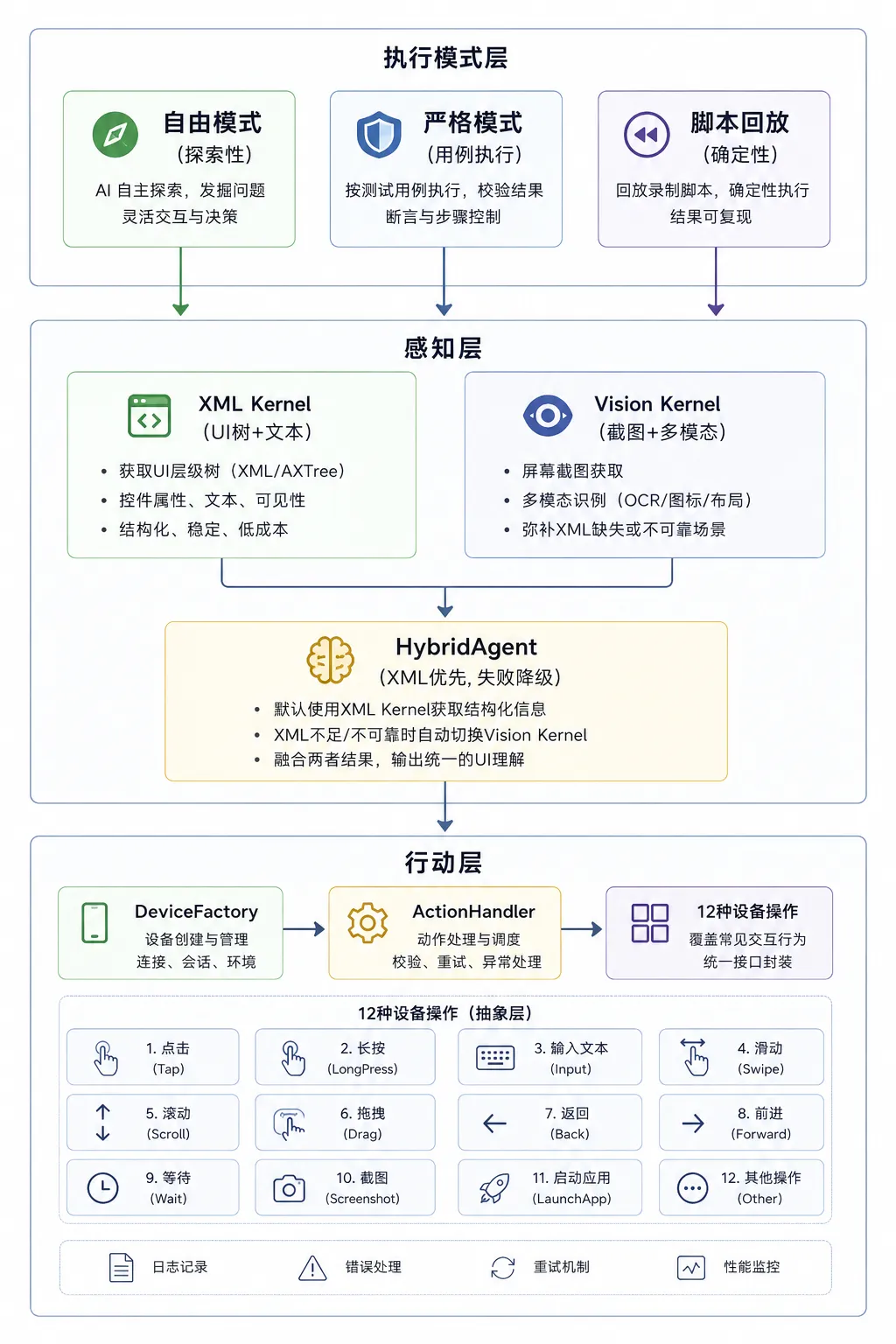
3.1 双 Kernel 混合:不止是"快慢选择"
上一篇文章提到 XML 和 Vision 两种定位方式。从 Agent 架构角度看,这不是简单的"快慢二选一",而是一个带自动降级的多层感知系统。
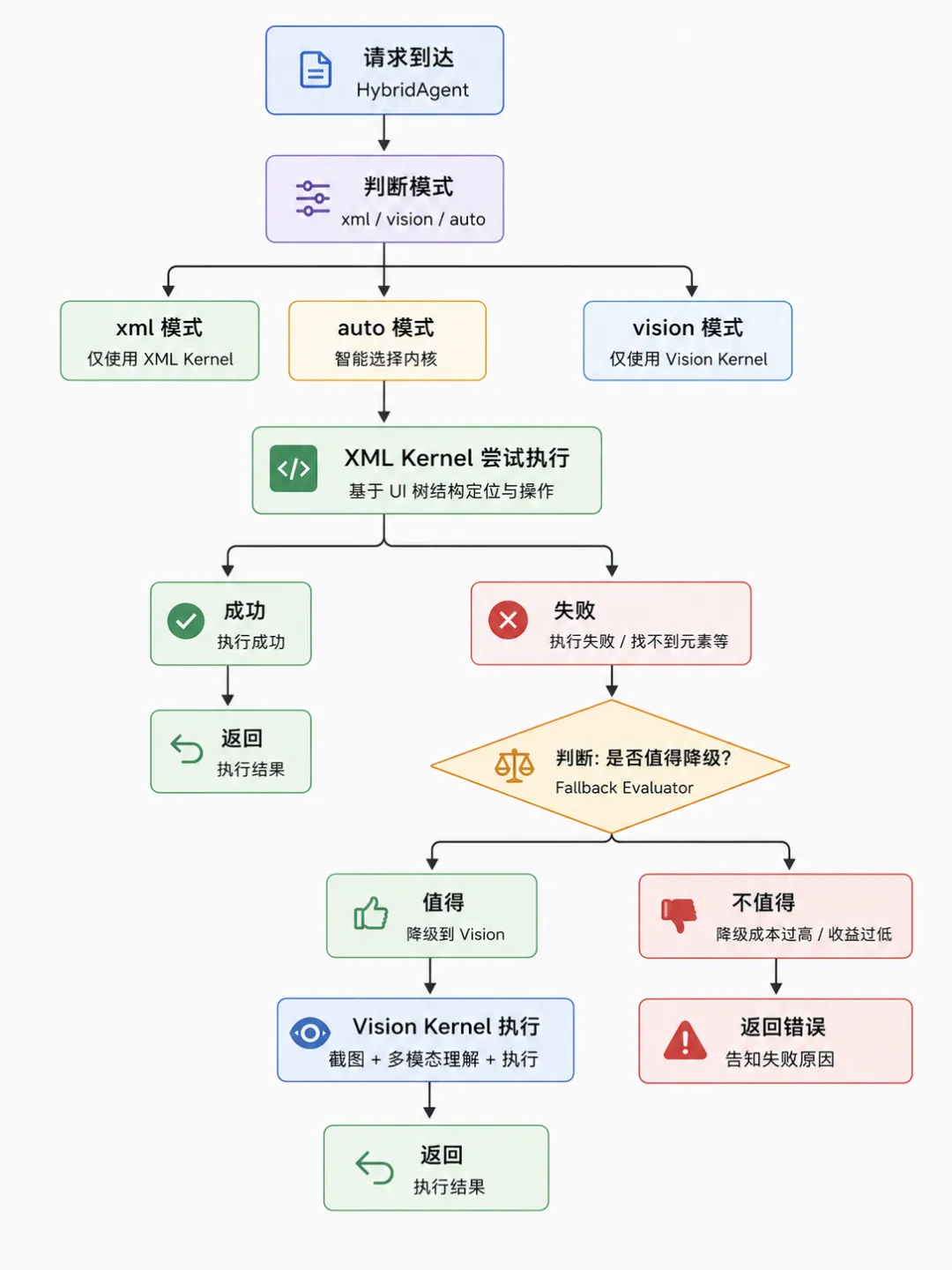
降级判断不是简单的"XML 失败就换 Vision"。关键是判断失败原因是否 Vision 能解决:
• XML 失败原因 = “UI 树拿不到”(WebView、自定义 Canvas)→ 值得降级 • XML 失败原因 = “步数耗尽仍未完成”(任务本身有问题)→ 不值得降级,返回错误
# hybrid_agent.py 的核心降级逻辑(简化)result = xml_agent.run_structured(task)if result["success"]:return result # XML 搞定,结束if result["should_fallback"]: # UI树不可用,切 Visionreturn vision_agent.run_structured(task)else:return {"error": "max_steps_exceeded"} # 不是感知问题,不降级3.2 两层执行模式:灵活性 vs 确定性
AutoPilot 有两套执行模式,对应不同场景:
自由模式(Flexible):Agent 收到任务描述,自行规划步骤。适合探索性测试、一次性任务。
输入: "帮我测试登录功能是否正常"Agent: 我看到登录页 → 输入用户名 → 输入密码 → 点击登录 → 看到"欢迎" → 完成严格模式(Strict):Agent 收到分步用例,必须按步骤顺序执行,不能跳步、不能遗漏。适合回归测试。
输入: 步骤1: 输入用户名 "testuser" 步骤2: 输入密码 "123456" 步骤3: 点击登录按钮 断言: 页面显示 "欢迎回来"Agent 内部: step_idx=1 → 必须输入用户名 step_idx=2 → 必须输入密码 step_idx=3 → 必须点击登录 完成后 → finish()严格模式的实现依赖 Prompt 约束 + 强制纠正:
system prompt 追加: "当前是第 {step_idx}/{total_steps} 步: {step_description}" "你只能执行这一步,完成后立刻 finish()"iOS 端额外强制纠正(iOS 端模型容易"跑偏"): 如果模型输出 Tap 但当前步骤要求 Kill → 强制覆盖为 Kill3.3 动作解析:比 tool calling 更可控
主流 Agent 框架用 OpenAI Function Calling 来让模型输出结构化动作。AutoPilot 用了另一条路:自定义 do() / finish() 函数约定 + AST 解析。
模型输出: do(action="Tap", element=[523, 847]) ↓ Python ast.parse() 安全解析 ↓ ActionHandler.execute("Tap", element=[523, 847]) ↓ 归一化坐标 → 绝对像素 → adb shell input tap为什么不用 Function Calling?
do(action="Tap", element=[x,y]) | ||
do(action= 即停 |
更重要的是容错设计:
defparse_action(content: str) -> Action | None:# 第一层: AST 解析(最安全)try: tree = ast.parse(content.strip(), mode='eval')return extract_action_from_ast(tree)except SyntaxError:pass# 第二层: 正则匹配(兜底)match = re.search(r'do\(action="(\w+)"(?:,\s*(.+))?\)', content)ifmatch:return extract_action_from_regex(match)# 第三层: 重试(给模型修正机会)returnNone# 调用方会带着错误信息重试3.4 上下文窗口管理:不丢任务、不爆 token
Agent 执行 20 步任务时,对话历史里有 20 张截图。如果不加处理,token 消耗呈线性增长,而且模型会在第 15 步时"忘记"最初的任务目标。
AutoPilot 的上下文管理策略是锚点 + 滑动窗口:
保留: [0] system prompt ← 永久保留(行为约束) [1] first user message ← 永久保留(任务目标,锚点) [2] first assistant msg ← 永久保留(初始理解) ... [N-4] 最近第4步 user msg ← 滑动窗口 [N-3] 最近第3步 assistant [N-2] 最近第2步 user msg [N-1] 最近第1步 assistant [N] 当前 user msg + 截图 ← 只有当前这条带截图!丢弃: 中间的所有消息(文本保留,截图移除)关键设计:历史消息中的截图全部移除,只保留文本。因为:
• 旧截图对当前判断没有帮助(UI 可能已变了) • 图片 token 消耗远大于文本 • 模型不需要"记住页面长什么样",只需要记住"之前做过什么"
def _trim_context(self): """保留 system + 初始锚点 + 最近 N 轮,移除旧图片""" max_msgs = self.max_context_turns * 2 + 1 # 默认 5 轮 kept = [self._context[0]] # system prompt kept += self._context[1:3] # 第一对 user+assistant(锚点) kept += self._context[-max_msgs:] # 最近 N 条 for msg in kept: if isinstance(msg['content'], list): # 移除图片,只保留文本 msg['content'] = [c for c in msg['content'] if c['type'] == 'text']3.5 双模型断言:不让 Agent 验证自己
测试的本质是断言——操作有没有产生预期结果。但如果让执行操作的模型同时做断言,就出现了"自己批改自己试卷"的问题。一个朴素的想法是:执行和断言使用独立模型。
AutoPilot 的做法:
执行阶段: 模型 A (如 gpt-4o) → 执行步骤 1, 2, 3 → 最后一张截图断言阶段: 模型 B (如 glm-4v-flash) → 看到最后一张截图 + 断言文本 → 返回 {"result": true/false, "reason": "..."}模型 B 选更轻量的模型,因为:
• 断言比执行简单(只需要判断"页面上有没有 X") • 轻量模型更便宜、更快 • 独立模型 = 独立视角,增加了可信度
def_verify_assertions(self, assertions: list[str]) -> list[dict]:"""使用独立的断言模型验证""" screenshot = self.device_factory.get_screenshot(device_id) results = []for assertion in assertions: response = self.assertion_client.request([ {"type": "image_url", "image_url": {"url": f"data:image/png;base64,{screenshot}"}}, {"type": "text", "text": f"请判断以下是否成立:\n{assertion}\n返回JSON"} ]) results.append(json.loads(response))return results3.6 脚本编译:从概率到确定
AutoPilot 的一个特色设计:把 AI 的一次性推理结果固化为可重复执行的脚本。
自然语言用例 │ ▼ Agent 执行(AI, 慢, 概率性) │ ▼ 验证通过 → 编译为 YAML 脚本 │ ▼ Executor 回放(无 LLM, 快, 确定性)脚本的结构:
steps:-action:Typetarget:hint:"用户名输入框"xml_text:"用户名"value:"testuser"-action:Typetarget:hint:"密码输入框"xml_text:"密码"value:"123456"-action:Taptarget:hint:"登录按钮"xml_text:"登录"fallback:strategy:visionhint:"屏幕下方蓝色按钮"assertions:-type:text_existsvalue:"欢迎回来"这种设计的意义:AI 用来"发现路径",脚本用来"重复走这条路"。
一次 AI 推理耗费 2-5 秒、消耗几千 token。脚本回放一步只需要几十毫秒、消耗 0 token。对于需要跑 100 次的回归测试,这就是 25 分钟 vs 5 秒的差异。
四、核心 Agent 模式全景
综合业界的各种方案,移动端 UI 测试 Agent 主要涉及以下几种模式:
模式一:ReAct(推理-行动循环)
┌──────────────────────────┐│ Observe → Think → Act ││ ↑ │ ││ └────────────────┘ │└──────────────────────────┘这是最基础的 Agent 模式。每一步:截图(Observe)→ 让模型思考(Think)→ 执行操作(Act),循环直到任务完成。
Midscene.js 的 aiAct()、AutoPilot 的 PhoneAgent 都是 ReAct 模式的具体实现。
模式二:Plan-then-Execute(先规划后执行)
任务输入 → 规划阶段 → 生成步骤列表 → 逐步执行 → 完成 ↑ │ └─── 执行失败/偏离 ── 重规划 ──┘先花一次模型调用做全局规划,生成结构化步骤,再逐步执行。执行过程中检测偏离时触发重规划。
适用场景:多步复杂任务、需要全局视角。优势:不会"走一步看一步"导致跑偏。代表:AutoPilot 的 PlanningAgent + PlanExecutor、Midscene.js 的 aiAct()(内部也做任务拆解)。
模式三:Reflexion(反思/自纠错)
执行 → 评估结果 → 不通过? → 反思原因 → 调整策略 → 重新执行让 Agent 评估自己的执行结果,失败时分析原因并调整策略。
适用场景:需要自主纠错的场景。局限:反思也需要模型调用,增加了延迟和成本。
AutoPilot 在检查点验证失败时触发的重试机制就是这个模式的简化版。
模式四:Multi-Agent(多 Agent 协作)
┌──────────┐ ┌──────────┐ ┌──────────┐│ 规划者 │ │ 执行者 │ │ 验证者 ││ (计划) │→ │ (操作) │→ │ (断言) │└──────────┘ └──────────┘ └──────────┘多个独立 Agent 协作,各司其职。前文提到的 Mobile-Agent 和 UFO 都用了这个模式。
适用场景:复杂系统、跨应用交互。局限:Agent 间通信和协调带来额外开销。
AutoPilot 的"双模型断言"本质上是一个两 Agent 协作系统(执行 Agent + 断言 Agent)。测试用例生成流水线是 7 个 Agent 的 DAG 协作。
模式五:Script-Compilation(推理一次,执行千次)
这是前文提到的脚本编译思路,Midscene.js 也有类似的缓存回放机制:
自然语言 → LLM推理(一次)→ 编译/缓存为确定脚本 → 确定性回放(无限次)核心逻辑:
AI 的价值在于发现操作路径,而不是每次执行都做推理。一旦路径确定,就应该用确定性方式重复执行。
类比:编译型语言 vs 解释型语言。脚本编译就是"AOT 编译",ReAct 就是"JIT 解释执行"。
模式选择决策表
五、架构决策:选择背后的权衡
回顾 AutoPilot 的架构,每个设计决策背后都有明确的权衡。这些决策不是"最优解",而是"在特定约束下的合理选择"。
决策 1:为什么不用 LangChain?
约束:移动端 UI 测试的核心操作是"截图 → 推理 → 操作手机"。LangChain 的抽象(Chain、Tool、Memory、Retriever)大部分用不上,反而增加了调用栈深度和调试难度。
选择:自研轻量 Agent 循环,代码量约 500 行。
代价:失去了社区生态和标准化工具。但在这个场景里,代价可以接受。
决策 2:为什么不用 OpenAI Function Calling?
约束:需要支持多种模型供应商(OpenAI、智谱、DeepSeek 等)。Function Calling 的格式各厂商不完全兼容。
选择:自定义 do() / finish() 文本约定 + 多层解析。
代价:需要自己处理解析容错。但换来了供应商无关性和更好的调试体验。
决策 3:为什么 XML 优先而不是 Vision 优先?
约束:Vision 太慢(2-5 秒)太贵(一次约 $0.05-0.15)。
选择:能用 XML(UI 树)就先用 XML,不行再降级 Vision。
代价:XML 只在 Android/iOS 原生页面可用。WebView、Canvas、游戏等场景必须走到 Vision。但这是"多数情况快"和"少数情况慢"的合理取舍。
决策 4:为什么用归一化坐标(0-1000)?
约束:同一个测试用例需要在不同分辨率的设备上执行。
选择:让模型在 0-1000 的归一化空间中输出坐标,执行时按实际分辨率换算。
代价:模型需要理解归一化空间(通过 Prompt 说明)。但相比让模型输出绝对像素再跨设备适配,归一化在实践中更方便。
决策 5:为什么保留截图标注?
约束:AI 测试失败时,很难判断是"模型推理错了"还是"执行出了问题"。
选择:每次 tap/swipe 后生成带标注的截图(红点/绿线),存入日志目录。
代价:每步多一次图片写入,约 50-200KB。但调试效率的提升远远超过这点存储成本。
六、未来方向:Agent 框架的演进趋势
6.1 从 prompt engineering 到结构化约束
当前方案大量依赖 Prompt 来约束 Agent 行为。Prompt 的问题是不稳定——换个模型版本,效果可能完全不同。
趋势是把约束写进代码而不是 Prompt:
• 状态机替代自然语言流程描述 • 类型系统约束 Agent 输出 • 编译期检查替代运行时验证
AutoPilot 的 YAML 脚本编译就是这个方向的实践:把一次推理结果固化为可验证的结构。
6.2 从单模态到端侧小模型
当前方案依赖云端大模型。延迟(网络 RTT + 推理时间)是主要的性能瓶颈。
趋势是端侧小模型做常规判断,云端大模型做复杂推理:
• 端侧模型(1-3B 参数):元素定位、简单判断、断言验证 • 云端大模型:任务规划、复杂页面理解、异常处理
延迟可以降到 100ms 以内,与传统的 Appium 方案接近。
6.3 从孤立 Agent 到测试知识图谱
单个 Agent 每次执行都是从零开始。但人类测试工程师有知识积累。
趋势是让 Agent 之间共享知识:
第一次测试登录 → Agent 学到了"登录按钮在页面底部" → 存入知识库第二次测试登录 → 其他 Agent 直接读知识库 → 跳过探索阶段UI 改版后 → Agent 发现知识失效 → 重新学习 → 更新知识库这种"可积累的智能"才是 AI 测试的长期价值——不是替代某一个测试步骤,而是让整个测试体系越来越聪明。
七、总结
Agent 框架不是银弹,而是一组工程权衡。
核心思路:不要为了"用上框架"而用框架。先明确你的约束条件(延迟、成本、可靠性、模型供应商),然后组合最适合的模式。
AutoPilot 的经验是:在移动端 UI 测试这个特定领域,自研轻量 Agent + 混合感知 + 脚本编译是一种有效的组合方案。 但这不意味着这个方案适合所有场景。Agent 架构的选择,永远始于对场景的深刻理解。
相关文章:
