 夜雨聆风
夜雨聆风昨天有个老板问我:“我们在豆包和 DeepSeek 里测了几次,有时候被推荐,有时候不被推荐,这东西到底稳不稳?”
我先反问他一句:你测的时候,模型版本一样吗?有没有联网?有没有开深度思考?同一个问题有没有换过说法?你的网站页面最近有没有更新?他愣了一下,说:“我就是直接问的,截图给团队看。”
这就是现在很多老板最容易误判的地方。你把 AI 的一次回答,当成了搜索排名;你把今天的截图,当成了长期结论;你把“有没有提到我”,当成了一个固定座位。可 AI 推荐不是固定榜单,它更像一个随时会被模型版本、联网搜索、工具调用、页面证据和用户上下文重新计算的判断过程。
我的判断很直接:接下来老板不要只问 AI 推荐稳不稳,要先问一件更基础的事,模型和答案机制有没有变。模型换了,答案会变;联网策略变了,答案会变;页面证据变了,答案也会变。你不做答案回归测试,就会每天拿不同条件下的截图互相吓唬。
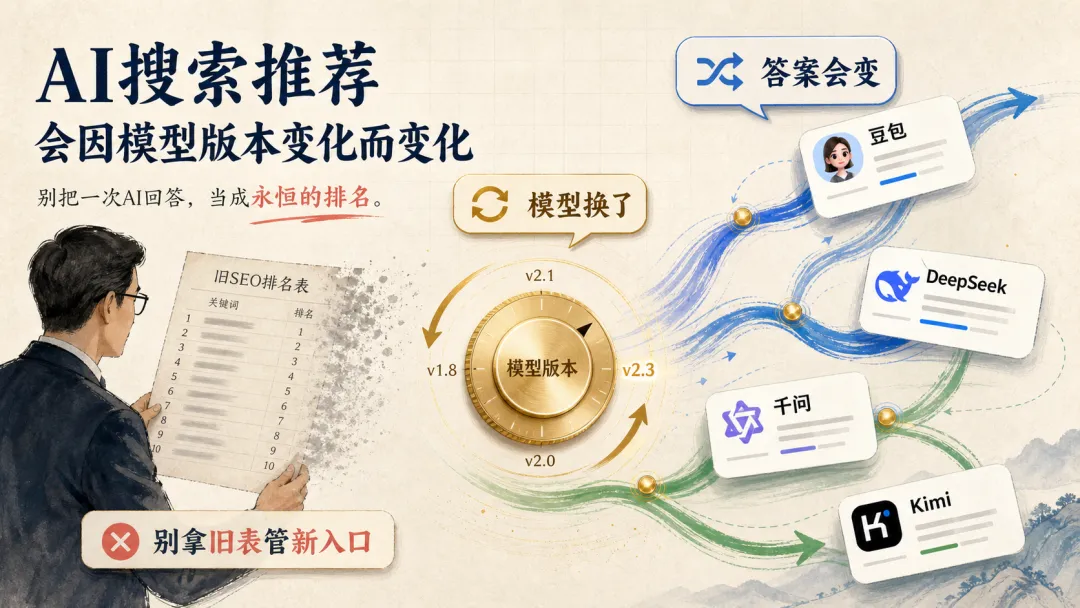
老板最容易错的,不是没测,而是把一次测量当结论
现在很多团队已经开始做 AI 搜索测试了,这当然比完全不看强。问题是,他们的测试方法太像“随手问一句”。
老板让市场同事打开豆包,问“XX 行业哪家公司好”;再打开 DeepSeek,问“某某产品推荐”;如果出来了自己,就高兴;没出来,就骂内容团队。第二天销售又换一个问题测,结果变了,于是全公司开始紧张:是不是昨天优化没效果?是不是平台抽风?是不是竞品刷了?
这套动作看起来勤快,其实非常危险。因为它没有控制变量。
你不知道模型版本有没有变,不知道是否触发了联网,不知道答案有没有调用工具,不知道 AI 是基于公开网页、平台内容、私域知识,还是模型内部参数在回答。你甚至不知道同一个问题里,用户意图有没有因为几个字的变化被重新识别。
所以我不建议老板再把“今天问了一句”当成 KPI。一次回答只能叫样本,不能叫结论。真正能指导业务的,是连续、同条件、可复盘的答案回归测试。
DeepSeek 这次模型迁移,给老板上了一课
为什么今天要专门讲模型版本?因为 DeepSeek 已经把这个问题摆到台面上了。
DeepSeek 官方 4 月 24 日发布 V4 Preview,V4-Pro 和 V4-Flash 可以通过 OpenAI ChatCompletions 和 Anthropic 接口访问。更关键的是,官方 changelog 写得很清楚:deepseek-chat 和 deepseek-reasoner 这两个旧模型名,会在 2026 年 7 月 24 日后停用;在当前过渡期里,deepseek-chat 和 deepseek-reasoner 分别指向 deepseek-v4-flash 的非思考模式和思考模式。
这不是一个纯技术更新。对企业来说,它提醒了一件很现实的事:你以为自己一直在测“DeepSeek”,但背后的模型、模式、路由关系可能已经变了。
如果你是做内容站、Affiliate、软件服务、AI 出海、本地服务获客,你更要意识到:AI 推荐结果不是一个静态排名。模型升级后,理解问题的方式可能变;长上下文能力变化后,能吃进去的资料可能变;工具调用能力变化后,答案里引用外部证据的方式也可能变。
这时候你再拿两周前的截图跟今天截图对比,说“为什么掉了”,意义不大。你要先问:测试条件是不是同一组?模型是不是同一版?是否触发联网?是否有同一批页面证据?如果这些都没记录,所谓变化很可能不是业务变化,而是测试口径乱了。
豆包和火山方舟告诉你,答案早就不只是模型自己说了
国内模型也一样。很多老板以为豆包、千问、Kimi、DeepSeek 的差异,就是“谁聪明一点”。这个理解太浅。
火山方舟的官方文档导航里,工具调用部分已经明确把豆包助手、Web Search(联网内容插件)、私域知识库搜索、Remote MCP、Function Calling 放在同一个能力体系里。DeepSeek 官方 Function Calling 文档也说明,模型可以返回一个工具调用,开发者执行函数以后,再把工具结果交回模型。也就是说,AI 的回答越来越不是“模型脑子里背了什么”,而是“模型判断该不该调工具、调什么工具、拿到什么外部结果、再怎么组织答案”。
这对企业内容意味着什么?
意味着你的网站不是只要被收录就行。你要让公开页面、产品说明、案例证据、价格边界、服务流程、FAQ、下载资料,都能在 AI 需要验证时派上用场。如果 AI 联网后找到的是你三年前的旧页面,答案就可能旧;如果 AI 调用工具后只能看到竞品更清楚的参数,你就会被竞品替代;如果私域知识库里没有你的最新定位,销售团队再怎么截图也说不清。
所以老板不要再问“为什么 DeepSeek 今天没推荐我”。先问:“它有什么理由推荐我?这个理由现在能不能在公开页面和可验证证据里找到?”
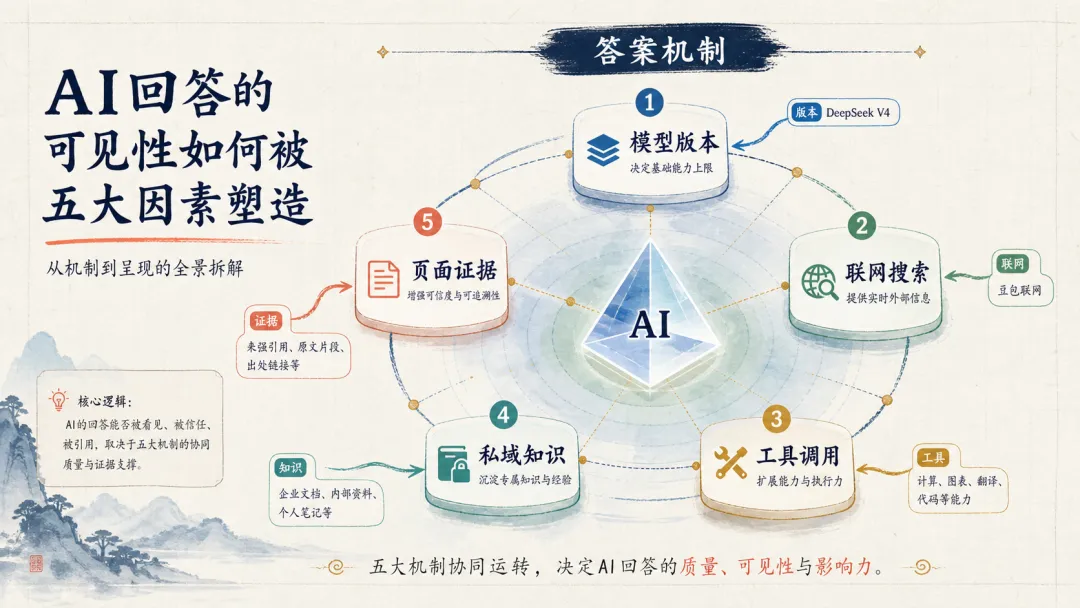
回到本源,AI 推荐要做的是回归测试,不是玄学祈祷
我更建议企业把 AI 推荐监测当成软件测试来做,尤其是做周度回归。
软件上线新版本,工程师不会只点一下首页就说没问题。他会跑一批关键用例,看核心流程有没有坏掉。AI 答案也是一样。模型更新、平台改版、页面改版、竞品发布新内容、热点事件出现以后,都应该跑一遍关键问题。
你要记录的不是“今天有没有提到我”这么粗的结果,而是四件事。
| 测试项 | 要看什么 | 为什么重要 |
|---|---|---|
| 问题是否一致 | 同一问题、同一场景、同一限制条件 | 避免把问法变化误判成排名变化 |
| 平台是否一致 | 豆包、DeepSeek、千问、Kimi 分开记录 | 不同平台的工具和语料不同 |
| 答案理由是否一致 | 推荐理由、竞品、引用来源、错误点 | 看 AI 到底凭什么推荐 |
| 页面证据是否同步 | 官网、案例、价格、FAQ、资料页 | 确保 AI 能找到最新业务证据 |
这才是 AI 搜索优化该有的管理方式。
具体行业怎么落地,别再做“万能问题”
拿 Affiliate 内容站举例。
过去你做工具推荐页,只要盯关键词排名、点击和佣金。现在你要补一层答案回归测试。比如用户问“低预算团队用哪个邮件营销工具更合适”,你不能只看 AI 有没有提到你的站。你要看 AI 推荐了哪些工具,理由是不是预算、功能、上手难度、退款政策、集成生态。然后回头检查你的页面有没有这些证据。没有,就别怪 AI 不引用你。
拿 AI 出海服务商举例。
你希望客户在豆包、DeepSeek 里问“AI 出海内容站谁能做”时看到你。那你就不能只发公司新闻。你要把适用客户、交付流程、预算区间、样例资产、失败边界写清楚。AI 推荐一个服务商时,需要的是判断材料,不是口号。如果页面上只有“专业团队、全案服务、成功案例众多”,模型很难给你一个强推荐理由。
拿本地服务行业举例。
装修、口腔、教培、法律咨询这些行业最适合做答案回归,因为用户问题天然带场景。比如“预算 10 万装修老房,哪类公司更适合”“种牙怎么判断医生靠不靠谱”“小学生英语一对一和班课怎么选”。这些问题每周跑一遍,你会很快发现:AI 更愿意推荐证据清楚、边界清楚、风险说得明白的页面,而不是只会写优惠活动的页面。
AI 推荐不是玄学。它只是把你以前没有写清楚的业务判断,拿到一个更苛刻的环境里重新审了一遍。
现在要做的 3 件事
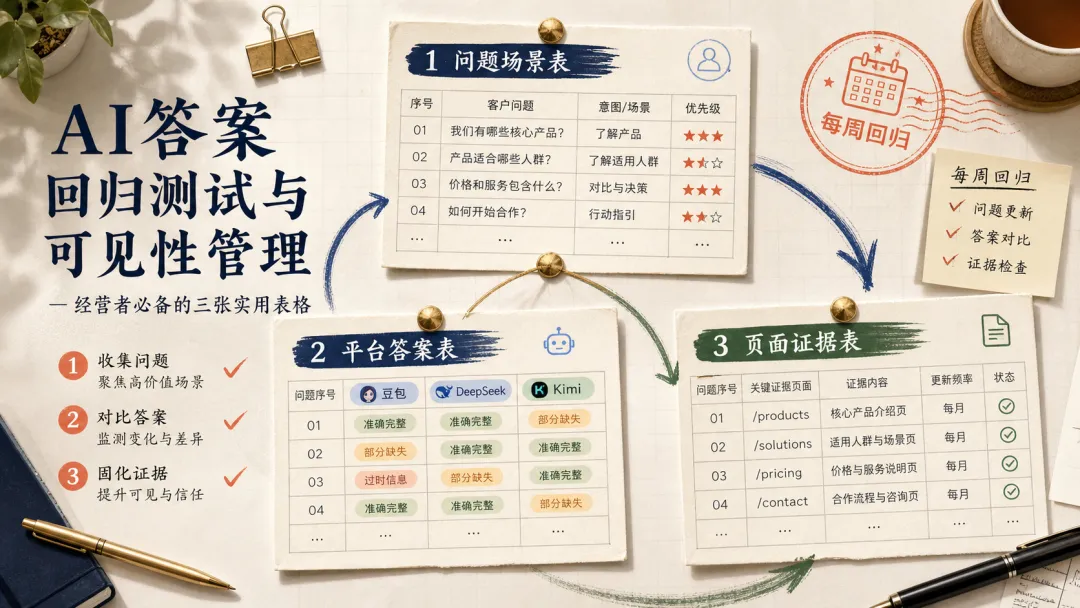
第一,建一张问题场景表。
不要从关键词工具里抄 100 个词。先从真实咨询里整理 30 个高价值问题,每个问题都写清楚用户身份、预算、用途、限制条件和决策阶段。比如“5 人团队”“预算 3000 元以内”“要中文客服”“不想自己搭系统”。这些限制条件决定 AI 怎么理解问题。
第二,建一张平台答案表。
每周固定在豆包、DeepSeek、千问、Kimi 里跑同一批问题。记录是否出现、排在第几层、推荐理由、竞品、引用来源、错误信息。不要只截图,要结构化记录。截图适合汇报,表格适合管理。
第三,建一张页面证据表。
每一个关键问题都要对应到你的一个页面或一组页面。页面要有更新时间、负责人、证据点、缺失项和下一步动作。比如补价格说明、补适用人群、补反例、补对比表、补案例证据、补资质说明。AI 答案变了,你才能知道该改页面,还是该观察平台变化。
写在最后
老板不要再把 AI 推荐想成一个固定榜单。它更像一个会随时重新计算的业务判断系统。
DeepSeek 的模型名迁移提醒你,模型版本会变;豆包和火山方舟的工具调用体系提醒你,答案可能来自联网搜索、私域知识和外部工具;Google 把生成式 AI 可见性拆成独立报告,也说明平台已经开始承认这是一套新的观察口径。你如果还只拿传统排名和单次截图管理,就一定会看错。
真正该做的不是每天问一句“AI 稳不稳”。真正该做的是,把高价值问题、平台答案、页面证据放进一套周度回归测试里。只有这样,你才知道自己是在变好,还是只是今天刚好被提到了。
01GEO 是 AI 搜索品牌可见性与排名监测工具,可查询品牌在豆包、DeepSeek、千问、Kimi 等 AI 平台里的推荐情况、排名变化和竞品对比,帮助企业持续追踪 GEO 优化效果。
