 夜雨聆风
夜雨聆风基于超声造影的 AI 模型对肝脏局灶性病变进行多分类:一项多中心临床研究
Journal of Hepatology, 2025, 83: 426–439 | DOI: 10.1016/j.jhep.2025.01.011
一、研究背景
肝脏是人体最易发生占位性病变的器官之一。常见肝局灶性病变(FLL)包括肝细胞癌(HCC)、肝转移癌(HM)、肝内胆管细胞癌(ICC)、肝血管瘤(HH)和肝脓肿(HA)等,罕见类型还包括肝腺瘤、肝淋巴瘤等。
不同类型的 FLL 治疗方案差异巨大。例如 HCC 和 HM 虽然同为恶性,治疗策略完全不同。简单地鉴别良恶性,或仅能识别一两种 FLL 类型,远不足以制定正确的治疗决策。因此,FLL 诊断应转向精确的多分类。
超声是最常用的肝脏影像检查手段,便捷、低成本、实时,但对 FLL 的诊断能力不理想。MRI 被公认是 FLL 最佳影像诊断工具,诊断性能仅次于病理,但高昂的成本和物流限制影响了其可及性。
超声造影(CEUS)可将常规超声从"筛查"提升至"诊断"水平,能连贯记录 FLL 的血流灌注特征,但高度依赖操作者经验。此外,典型的 CEUS 视频包含上千帧图像,远超其他肝脏影像检查,如何准确、全面地捕获与多类型分类相关的关键动态特征仍是挑战。
为克服这些难题,深度学习(DL)驱动的人工智能(AI)被认为是有希望的解决方案。既往研究多仅能分析静态超声/CEUS 图像,无法连贯分析动态视频,且仅能粗略区分少数常见 FLL 类型。本研究首次将"从影像到生物标志物"和"从影像到疾病"两条 AI 策略与临床特征整合,开发了 Model-DCB,对六种 FLL 进行准确分类。
二、研究方法
数据收集与分组
本研究于 2017 年 1 月启动(NCT04682886),获得中国人民解放军总医院伦理委员会批准。
入组标准: 1)明确实性结节 >1 cm,有 CEUS 视频;2)恶性结节经病理确认;3)良性结节经临床确认、MRI 和随访确认。
排除标准: 1)年龄 <18 岁;2)CEUS 图像质量差;3)临床信息缺失。
最终,来自 52 个中心的 3,342 名患者、3,725 个 FLL 被纳入分析。
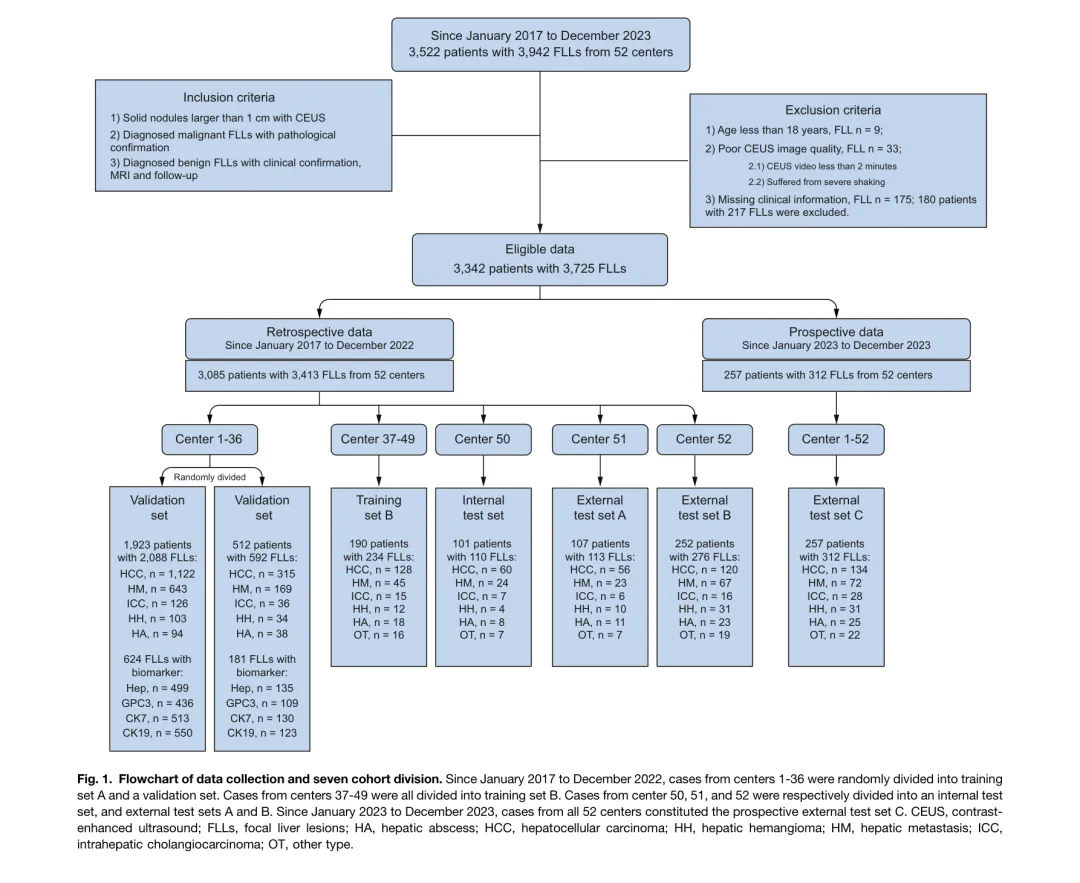
图 1. 数据收集流程图。 2017 年 1 月至 2022 年 12 月,中心 1-36 的病例随机分为训练集 A 和验证集。中心 37-49 全部分配至训练集 B。中心 50、51、52 分别分配至内部测试集、外部测试集 A 和 B。2023 年 1 月至 2023 年 12 月,所有 52 个中心的病例构成前瞻性外部测试集 C。CEUS,超声造影;FLLs,肝脏局灶性病变;HA,肝脓肿;HCC,肝细胞癌;HH,肝血管瘤;HM,肝转移癌;ICC,肝内胆管细胞癌;OT,其他类型。
临床含义:这是目前 FLL 多分类 AI 研究中规模最大、中心数最多的前瞻性验证数据集。
两阶段模型构建
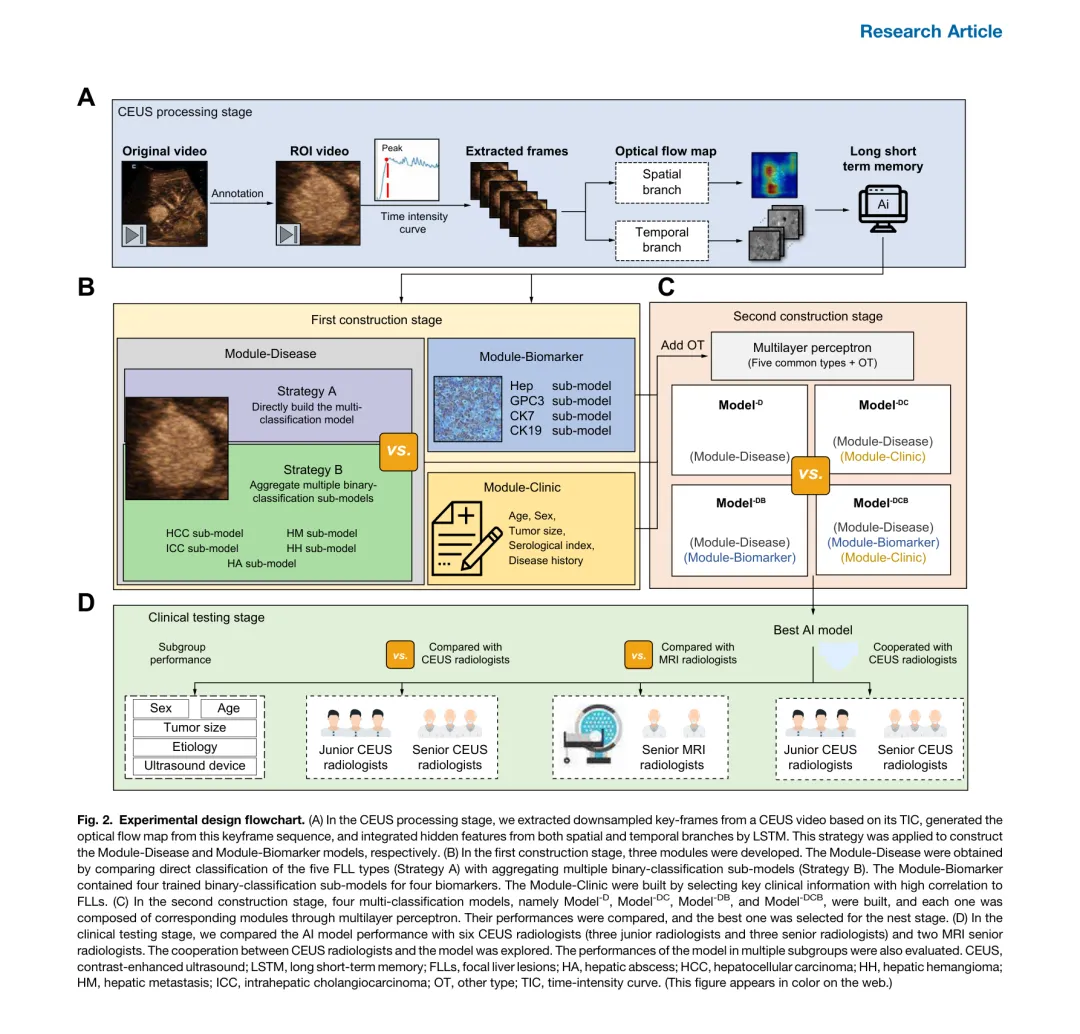
图 2. 实验设计流程图。(A)CEUS 处理阶段:基于时间-强度曲线(TIC)从 CEUS 视频中提取降采样关键帧,生成光流图,通过 LSTM 整合空间和时间分支的隐藏特征。(B)第一阶段构建:开发 Module-Disease(通过比较直接五分类与聚合多个二分类子模型)、Module-Biomarker(四个生物标志物子模型)和 Module-Clinic(筛选与 FLL 高度相关的关键临床信息)。(C)第二阶段构建:通过多层感知器(MLP)组合对应模块,构建并比较 Model-D、Model-DC、Model-DB、Model-DCB。(D)临床测试阶段:将最佳模型与 6 名 CEUS 放射科医生和 2 名 MRI 资深医生进行比较,探索人机协作效果及多亚组性能。
CEUS 处理: 从每个视频中,沿 TIC 曲线的起始到峰值均匀采集 80 帧,从峰值到结束均匀采集 20 帧,共计 100 个 ROI。采用双流模型提取空间和时间信息——空间分支通过 ResNet34 提取空间特征,时间分支通过光流图(计算相邻帧像素位移)后经 ResNet18 提取时间特征。
第一阶段:三个模块
• Module-Disease: 比较直接构建多分类模型(策略 A)与聚合多个二分类子模型(策略 B)。五个子模型:HCC vs. 非 HCC、HM vs. 非 HM、ICC vs. 非 ICC、HH vs. 非 HH、HA vs. 非 HA。 • Module-Biomarker: 四个二分类子模型预测 Hep、GPC3、CK7、CK19 的阳性/阴性表达。 • Module-Clinic: 筛选与 FLL 类型相关系数绝对值 >0.2 的 17 种临床信息。
第二阶段:模型聚合 — 通过 MLP 组合模块,构建四个多分类模型。对于罕见类型(OT),不单独训练子模型,而是利用 MLP 将 OT 设为五种常见类型之外的额外分类——当某病例对所有五种 FLL 类型的预测概率均较低时,归类为 OT。
模型评估
在四个测试集中通过多分类指标、亚组分析(性别、年龄、肿瘤大小、病因、肝硬化、脂肪肝、超声设备制造商)和六型雷达图评估模型性能。与 6 名 CEUS 放射科医生(3 名初级、3 名资深)和 2 名资深 MRI 放射科医生进行对比。间隔 1 个月洗脱期后,评估放射科医生在模型辅助下的表现变化。
三、核心结果
研究对象基线特征
表 1. 训练集、验证集和各测试集的基线特征
| 年龄 | |||||||
| 性别 | |||||||
| 病毒性肝炎史 | |||||||
| 肿瘤大小 | |||||||
| FLL 类型 | |||||||
各数据集之间基线特征均无显著差异(p1/p2/p3 均 >0.05)。训练集 A 中有 624 个 FLL 具有生物标志物信息(Hep n=499,GPC3 n=436,CK7 n=513,CK19 n=550)。
第一阶段:三个模块的性能
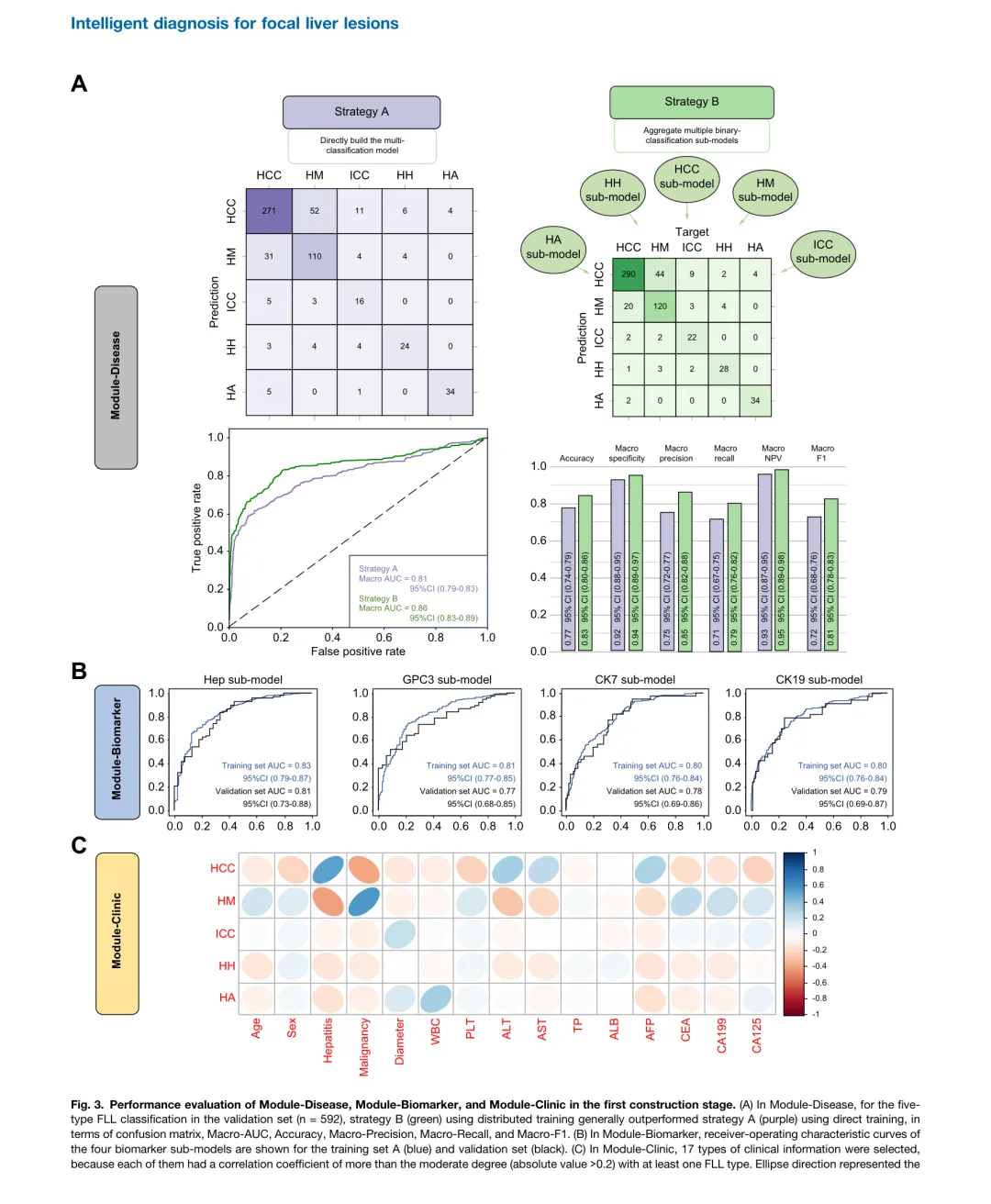
图 3. 第一阶段 Module-Disease、Module-Biomarker 和 Module-Clinic 的性能评估。(A)在验证集(n=592)的五分类中,采用分布式训练的策略 B(绿色)在混淆矩阵、Macro-AUC、Accuracy、Macro-Precision、Macro-Recall 和 Macro-F1 方面普遍优于直接训练的策略 A(紫色)。(B)四个生物标志物子模型在训练集 A(蓝色)和验证集(黑色)上的 ROC 曲线。Hep 子模型 AUC 0.83/0.81,GPC3 子模型 0.81/0.77,CK7 子模型 0.80/0.78,CK19 子模型 0.80/0.79。(C)17 种临床信息被选中,每种与至少一种 FLL 类型的相关系数绝对值超过 0.2。
• Module-Disease: 策略 B(聚合多个二分类子模型)Accuracy 为 0.83(95% CI 0.80-0.86),显著优于策略 A 的 0.77(95% CI 0.74-0.79),p <0.001。 • Module-Biomarker: 四个生物标志物子模型训练集 AUC 范围为 0.80-0.83,验证集 AUC 范围为 0.77-0.81,表明 CEUS 视频能够以良好性能预测免疫组化生物标志物。
第二阶段:四种模型的比较
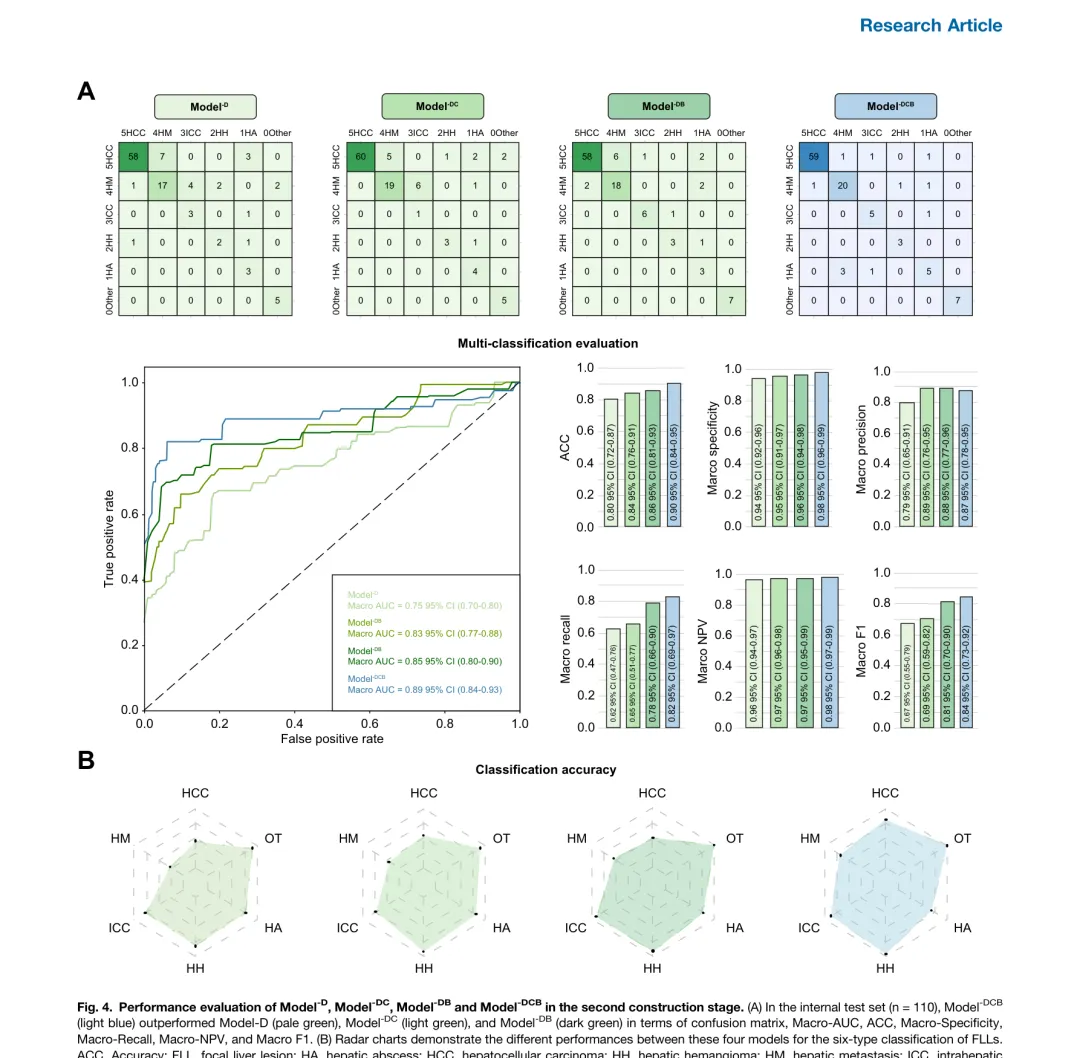
图 4. 第二阶段 Model-D、Model-DC、Model-DB 和 Model-DCB 的性能评估。(A)在内部测试集(n=110)中,Model-DCB(浅蓝色)在混淆矩阵和各项指标上均优于 Model-D(浅绿色)、Model-DC(亮绿色)和 Model-DB(深绿色)。(B)雷达图展示四种模型在六分类中每类准确度的差异。Model-DCB 对所有六种 FLL 的诊断准确率均达到或超过 0.94。
在内部测试集中:
• Model-DCB Accuracy:0.90(95% CI 0.84-0.95),Macro-AUC:0.89(95% CI 0.84-0.93) • 从 Model-D 到 Model-DB,Accuracy 从 0.80 提升至 0.86(+7.5%),加入 Module-Biomarker 带来的提升大于 Module-Clinic • Model-DCB 对六种 FLL 的诊断准确率均 ≥0.94,而其他模型在 HCC 和 HM 上的分类能力较差
Model-DCB 在四个测试集中的表现
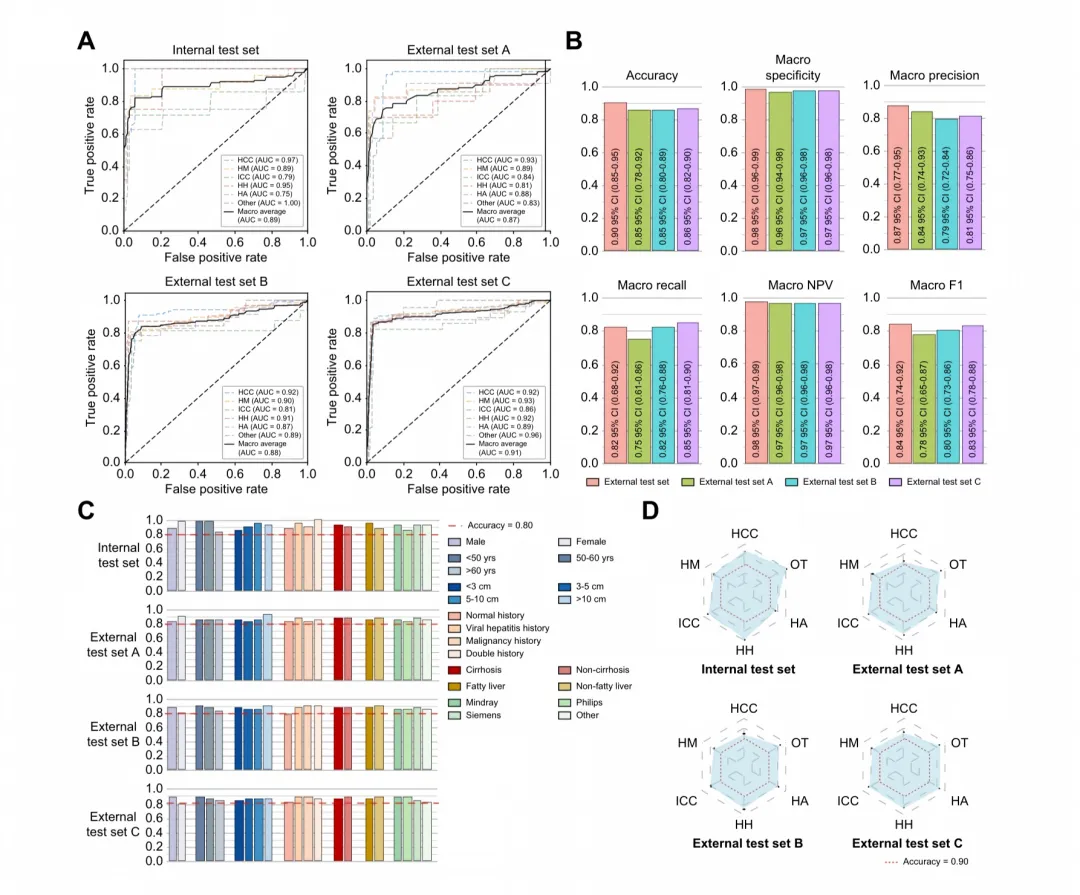
图 5. Model-DCB 在四个测试集中的性能。(A)ROC 曲线和 Macro-AUC。(B)各项指标范围:Accuracy 0.85-0.90,Macro-Specificity 0.96-0.98,Macro-Recall 0.75-0.85,Macro-Precision 0.79-0.87,Macro-NPV 0.97-0.98,Macro-F1 0.78-0.84。(C)亚组分析:在性别、年龄、肿瘤大小、病因、肝硬化、脂肪肝和超声设备制造商共 84 个亚组中,准确率范围为 0.77-1.00,绝大多数超过 0.80。(D)六分类雷达图:所有六种 FLL 的准确率均超过 0.90。
与放射科医生的对比和协作
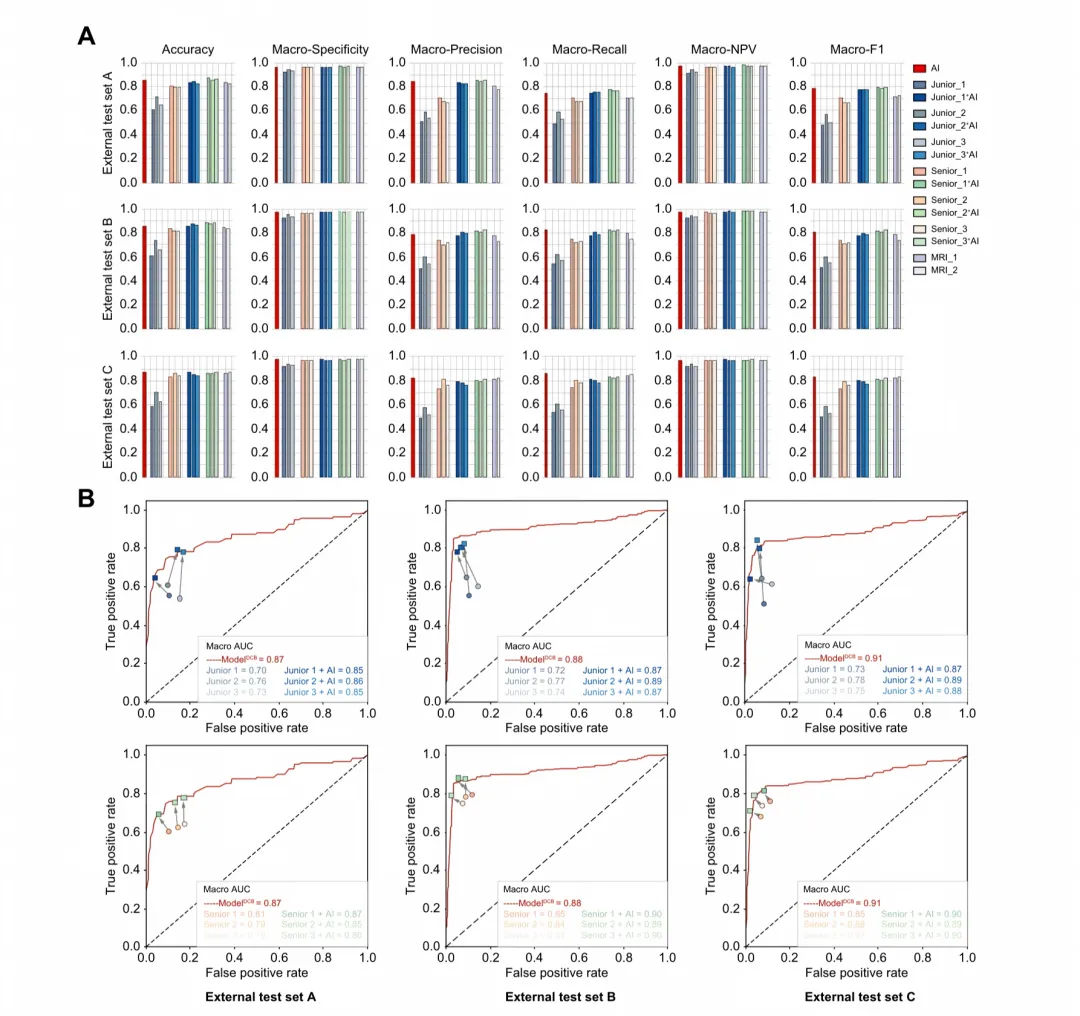
图 6. Model-DCB 与放射科医生的对比与协作。(A)在三个外部测试集中,Model-DCB 显著优于初级 CEUS 医生,与资深 CEUS 医生和资深 MRI 医生水平相当。(B)在 Model-DCB 辅助下,初级 CEUS 医生的 Macro-AUC 大幅提升(如 Junior 1 从 0.70 升至 0.85)。(C)资深 CEUS 医生同样有所提升,但幅度较小。
表 2. 临床测试阶段——外部测试集 C(前瞻性多中心测试集)
| AI | 0.86 (0.82–0.90) | ||||||
临床含义:在 AI 辅助下,初级 CEUS 医生的 Accuracy 从 0.59-0.73 显著提升至 0.82-0.87(p<0.05),达到了资深放射科医生的水平。这也意味着基层或偏远地区的初级医生在 AI 辅助下,可为 FLL 患者提供与资深 MRI 医生相当的诊断服务。
模型泛化性和稳健性
• 泛化实验: 在三种模拟临床场景(体检中心 1:9 良恶性比、门诊 5:5、住院病房 9:1)中,Model-DCB 的准确率无显著差异,表明 FLL 患病率差异不影响模型性能。 • 稳健性实验: 随机调整 ROI(扩大/缩小/移动/组合)100 次重复实验,对模型性能无显著影响。
误诊分析
三个外部测试集中(n=701):
• 最频繁误诊: HCC 与 HM 之间(n=27,5.7%,27/472),这两种 FLL 在临床上本身也以鉴别困难著称。 • 最关键误诊: 恶性 FLL(HCC/HM/ICC)误诊为良性(HH/HA)(n=21,4.0%,21/522),其中坏死性转移灶与 HA 在 CEUS 上的鉴别困难被临床和实验室信息有效弥补。
四、文献精读要点
背景 → 目的
• 肝脏局灶性病变(FLL)的多分类是制定正确治疗决策的前提,但最常用的超声检查缺乏足够准确性 • 超声造影(CEUS)诊断性能更好,但高度依赖操作者经验,且视频信息量巨大超出人工分析能力 • 本研究旨在开发基于 CEUS 的 AI 模型(Model-DCB),实现 FLL 的六分类,并在多中心临床测试中验证其性能
核心方法
• 52 个中心、3,725 例 FLL 的大规模多中心数据库(含 805 个生物标志物结果) • 两阶段策略:先独立构建 Disease/Biomarker/Clinic 三个模块,再通过 MLP 聚合为 Model-DCB • 创新点:将"从影像到生物标志物"策略与"从影像到疾病"策略融合,利用光流法处理动态视频的时间信息
核心结果
• 在前瞻性外部测试集 C(n=312)中,Model-DCB Accuracy 0.86,显著优于初级 CEUS 医生(0.59-0.73),与资深 CEUS 医生(0.83-0.85)和资深 MRI 医生(0.86)水平相当 • 在 AI 辅助下,初级 CEUS 医生 Accuracy 从 0.59-0.73 提升至 0.82-0.87(p<0.05),达到资深医生水平 • 84 个亚组分析中准确率范围 0.77-1.00,跨设备、跨人群稳定性良好
局限性与结论
• 数据全部来自中国中心,未来需国际验证;部分良性 FLL 基于临床而非病理诊断 • Model-DCB 通过有效整合 CEUS 视频、生物标志物信息和临床信息,为 FLL 提供了准确的六分类 • 该模型具备低算力需求、跨厂家稳定、即装即用的特点,尤其适合 MRI 可及性有限的偏远地区
— 医文笔记小小侠 | 大龄医学博士在读 · 二孩爸爸 — 慢慢读,慢慢积累。
