 夜雨聆风
夜雨聆风📖 阅读时间:约 14 分钟
本文目录:
- 为什么今天还要谈 TensorFlow?
- TensorFlow 曾经解决了什么问题?
- 从 TensorFlow 到 XLA:框架会表达计算,不代表硬件会高效执行
- XLA 到底想解决什么问题?
- XLA 的核心机制:从 TensorFlow 子图到 HLO,再到机器代码
- 发展时间线:TFXLA、JAX、MLIR、StableHLO、PJRT、OpenXLA
- MLIR 与 XLA 的关系:为什么 HLO 之外还需要多层 IR?
- OpenXLA 的工程意义:从框架后端到跨生态接口
- 工程落地视角:自研硬件接 XLA 为什么不等于“免费可移植”
- 最后:怎样理解 XLA 的历史位置?
1. 为什么今天还要谈 TensorFlow?
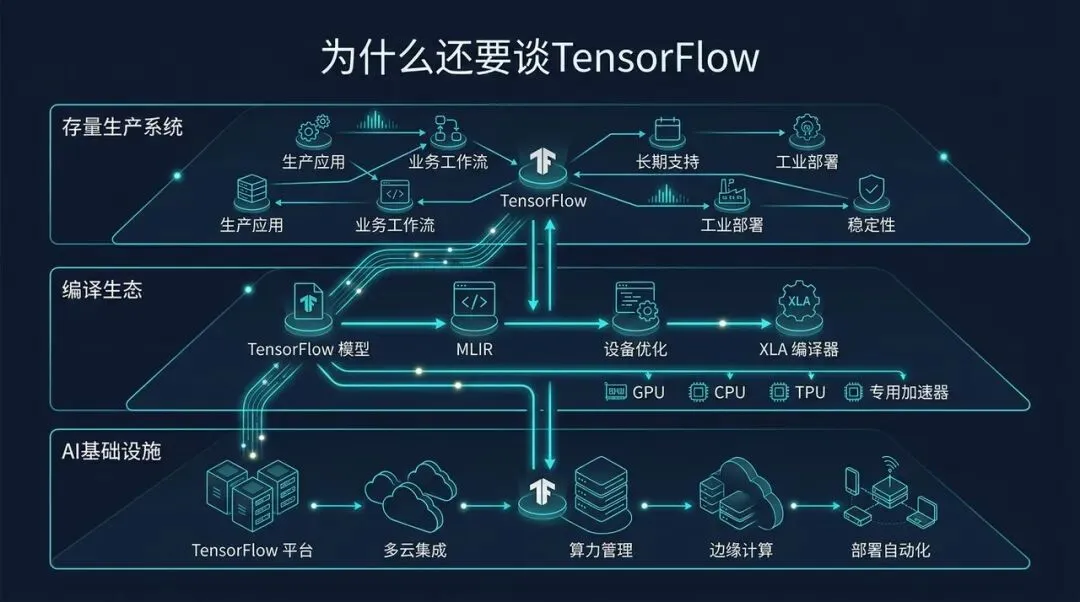
TensorFlow 仍值得讨论:存量系统、编译生态和 AI Infra 三条线交汇
如果只看今天的开源模型讨论区,你很容易产生一种错觉:TensorFlow 已经过时了,AI Infra 的主战场只剩 PyTorch、Triton、vLLM、各种推理引擎和大模型训练框架。
但这只是表层视角。
真正到生产系统里看,TensorFlow 仍然是一块绕不开的地基。很多存量推荐、广告、搜索、语音、视觉、端侧推理和 Serving 系统,早就围绕 TensorFlow 建了多年工程资产:模型导出链路、特征处理、Serving、监控、A/B 实验、模型格式、硬件适配、团队经验,都不是一夜之间能迁走的。
更重要的是,TensorFlow 的历史价值不只是“一个深度学习框架”。它把深度学习计算从一堆 Python 调用,变成了可以被运行时分析、切分、调度、放置到异构设备上的 dataflow graph。这个方向后来深刻影响了几乎所有 AI 编译和运行时系统。
今天各大硬件和云厂商对 TensorFlow / XLA / OpenXLA 生态的支持,也说明这条线并没有断掉:
- OpenXLA 官方把 XLA 定位为可以承接 TensorFlow、JAX、PyTorch 等前端,并面向 GPU、CPU、TPU 和 ML 加速器优化执行的编译器。
- Intel Extension for TensorFlow 文档中明确介绍了通过 PJRT plugin 支持 Intel GPU,并让 JAX、TensorFlow、PyTorch/XLA 等前端更容易接入。
- Google Open Source Blog 介绍 OpenXLA 时,也把它放在 TensorFlow、JAX、PyTorch/XLA、多硬件后端之间的开放编译生态里。
- AWS Trainium 也在公开资料中被放进 PJRT / OpenXLA 生态讨论里,用 PJRT plugin 让 JAX 等前端可以面向新的训练硬件。
也就是说,TensorFlow 的前台热度也许不如前几年,但它留下的编译模型、图执行思想、XLA 体系,以及后来演进出的 StableHLO、PJRT、OpenXLA,仍然是 AI Infra 里非常核心的一条主线。
尤其是 Google 自己的 TPU 生态和 JAX 生态,本质上一直在强化这件事:高层模型代码只是入口,真正把模型高效喂给硬件的,是图、IR、编译器和 runtime。
所以这篇文章不只是讲一个 TensorFlow 的历史功能,而是从 TensorFlow XLA 出发,讲清楚一个更大的问题:
深度学习框架写出来的是“我要算什么”,但 AI 编译器要回答的是“这段计算怎样变成硬件最爱吃的形状”。
2. TensorFlow 曾经解决了什么问题?
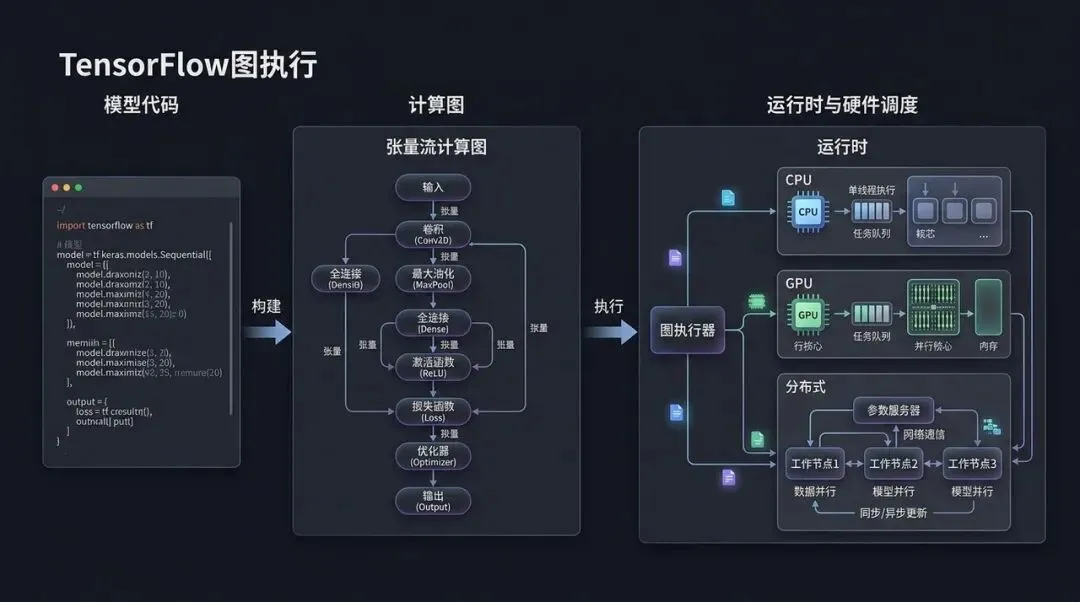
TensorFlow 图执行:先把模型变成系统可调度的计算图
TensorFlow 最早的核心设计,是用 dataflow graph 表达大规模机器学习计算。
这在当年非常关键。
如果模型只是在一张 GPU 上跑几层神经网络,那么动态图、命令式执行、逐行调试都很舒服。但工业界很快遇到的是另一类问题:模型越来越大,数据越来越多,训练要跨 CPU、GPU、TPU、Parameter Server、分布式集群;推理要接 Serving、批处理、在线延迟、灰度发布、监控和回滚。
这时,框架不能只负责“算一个 tensor”。它必须知道:
- 这段计算由哪些节点组成?
- tensor 在哪些设备之间流动?
- 哪些 op 可以放在 GPU,哪些必须在 CPU?
- 哪些变量是状态,哪些节点可以并行?
- 分布式训练时,通信和计算怎么组织?
TensorFlow 的 GraphDef 正是为这个时代的问题服务的。它把计算写成图,让 runtime 可以管理设备放置、执行顺序、通信、状态和分布式调度。
这也是 TensorFlow 曾经在工业生产里极其重要的原因:它不是只服务“研究员写模型”,而是服务“公司把模型变成系统”。
不过,图能表达计算,不代表图就能自动跑得足够快。
TensorFlow Graph 更像一个框架级表达:它知道用户要做 MatMul、Conv2D、Add、Relu,知道这些 op 之间的数据依赖。但它默认的执行粒度仍然是 op。每个 op 对应一个或多个设备 kernel,runtime 按图调度这些 kernel。
这就留下了一个编译层面的边界:
- GraphDef 更适合表达框架语义,不天然适合作为底层优化 IR。
- TensorFlow runtime 的调度粒度主要是 op。
- 每个 op kernel 只能看见自己,很难做跨 op fusion。
- 图优化器可以做 rewrite,但很难统一做 layout、tiling、buffer、codegen。
这就是 XLA 出现的背景。
3. 从 TensorFlow 到 XLA:框架会表达计算,不代表硬件会高效执行
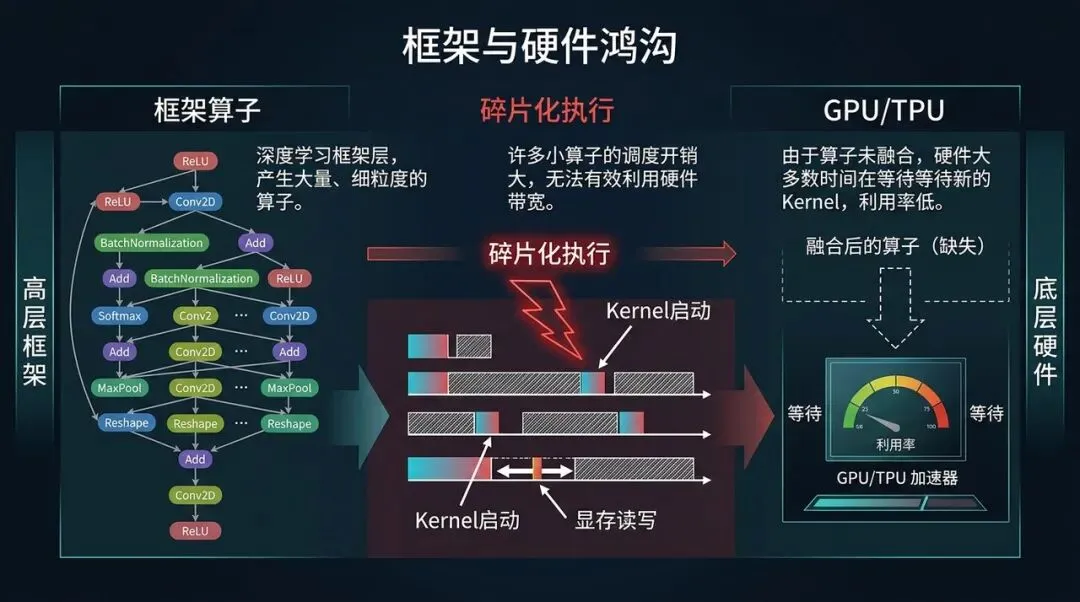
框架算子与硬件执行之间的鸿沟:碎片化调度、Kernel 启动和显存读写
先看一个很简单的模型片段:
从 Python 代码看,这就是一行表达式。但在传统逐 op 执行模式里,它可能会变成四次 kernel 调用:
- 启动一个
mulkernel,计算x * w,把中间结果写回显存; - 启动一个
addkernel,加上b,再写回显存; - 启动另一个
mulkernel,乘上mask,继续写回; - 启动
reduce_sumkernel,做规约。
这里真正浪费的,不一定是浮点乘加本身,而是三类开销。
第一类是调度开销。每个 op 都要经过 runtime 调度,每个 GPU kernel 都有 launch overhead。单个 overhead 可能不大,但模型里这种短小 op 很多时,累积起来非常明显。
第二类是内存开销。x w、x w + b、再乘 mask,每一步都可能产生中间 tensor。它们被写回显存,再被下一个 kernel 读出来。GPU 的算力很强,但显存带宽不是免费的。
第三类是优化边界太窄。单个 op kernel 看不到上下游,就很难知道:这个 mul 后面马上接 add,这个 add 后面马上接 reduce,能不能合并?中间 buffer 能不能省掉?tensor layout 能不能换成更适合后端的形式?
TensorFlow 里已经有 Grappler 这样的图优化器,可以做 constant folding、layout rewrite、arithmetic simplification、remapper 等图级 rewrite。
但 Grappler 更像“改写图”。XLA 问的是更进一步的问题:
这段图能不能直接编译成目标硬件上的 executable?
这一步很关键。因为它把问题从“运行时调度一堆 op”,推进到了“编译器生成一段整体执行单元”。
4. XLA 到底想解决什么问题?
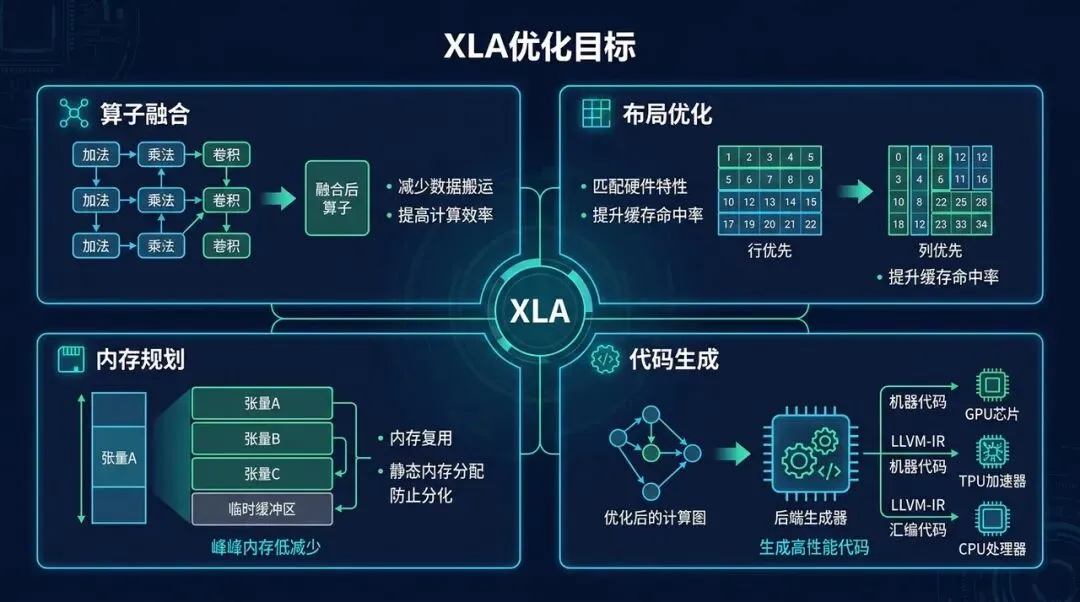
XLA 的四类核心优化目标:融合、布局、内存规划和代码生成
XLA 的第一性问题可以概括成一句话:
深度学习模型已经有了全局计算结构,为什么执行时还要把它拆回一堆局部 op?
所以 XLA 的目标不是简单地“打开一个加速开关”,而是把可编译的计算子图变成更适合硬件执行的形态。
它主要解决四类问题。
| 目标 | 解决的问题 | 典型手段 |
|---|---|---|
| 提升执行速度 | 短小 op 太多、kernel launch 太多 | 子图编译、fusion、专门化代码生成 |
| 降低内存使用 | 中间 tensor 反复写回、buffer 生命周期缺少统一规划 | buffer assignment、in-place / alias 分析 |
| 减少 custom op 依赖 | 手写融合 op 成本高、硬件适配碎片化 | 自动 fusion,把普通 op 组合优化到接近手写 kernel |
| 提升硬件可移植性 | 新硬件不想为每个大 op 重写 kernel | 通过 HLO / backend 复用高层图优化,再接目标代码生成 |
这里最容易被误解的是“可移植性”。
XLA 的可移植性主要发生在 HLO / StableHLO 这样的抽象层。它让前端框架可以把计算表达成统一的 tensor IR,也让后端可以在相对稳定的语义上做编译。
但这不等于任意硬件都能直接复用开源 GPU 后端。真正的硬件适配,还要处理 lowering、runtime、library call、collective、debug/profiler、ABI、LLVM/MLIR 版本、算子覆盖等一大堆工程问题。
这个坑,我们后面还会单独讲。
5. XLA 的核心机制:从 TensorFlow 子图到 HLO,再到机器代码
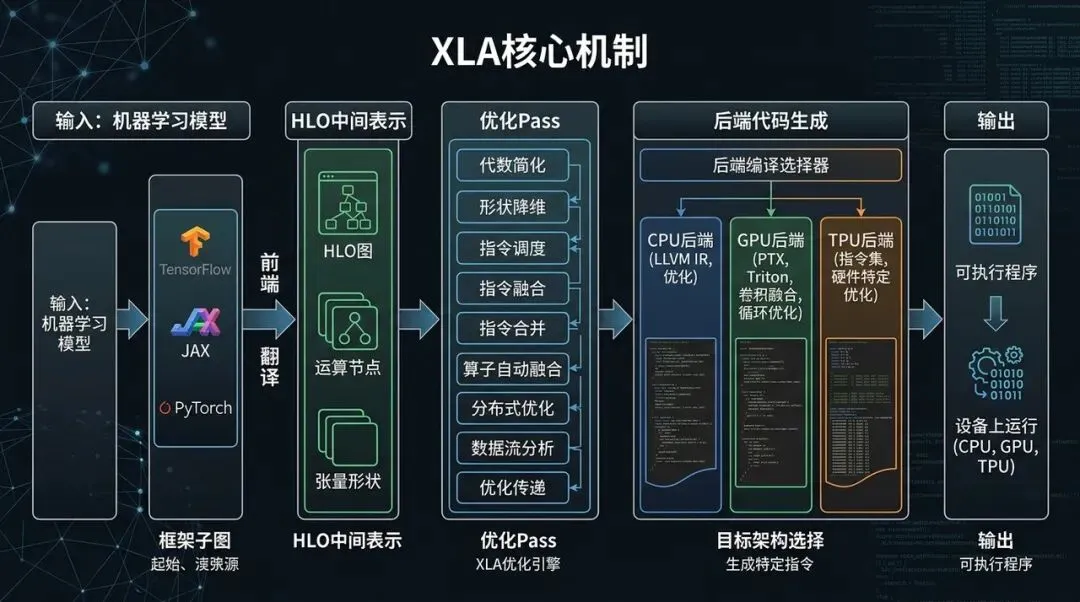
XLA 核心机制:从框架子图到 HLO,再到后端可执行程序
XLA 的典型编译链路可以粗略理解为:
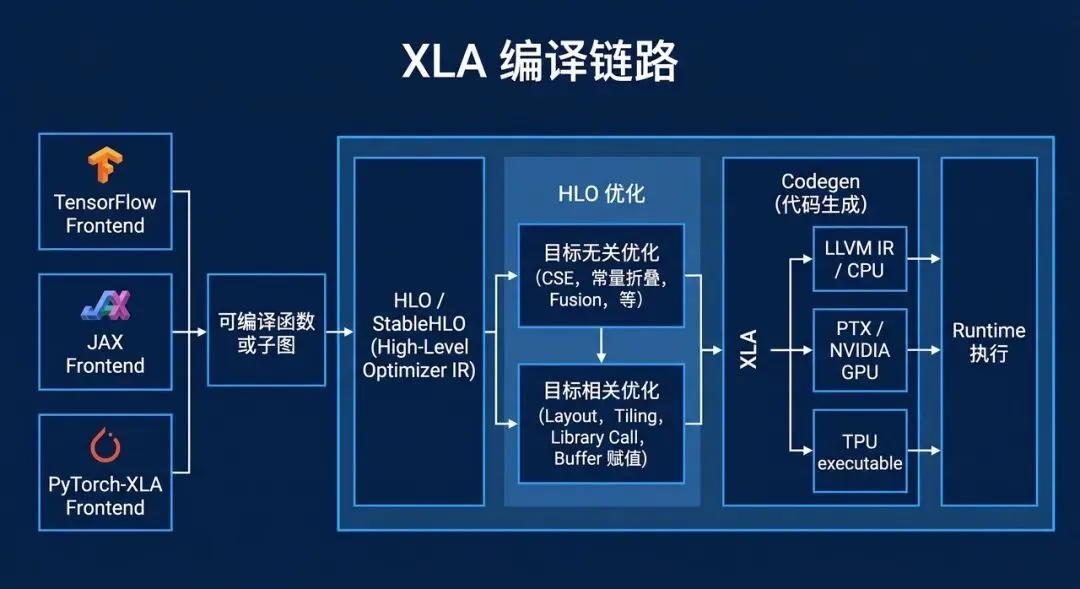
这条链路里最重要的中间层是 HLO,也就是 High Level Optimizer / High Level Operations。
为什么需要 HLO?因为 TensorFlow op 太靠近框架 API,LLVM IR 又太靠近底层机器。中间需要一个既能保留张量语义、又方便做编译优化的层次。
可以把 HLO 理解成“深度学习编译器的工作台”。在这个工作台上,编译器可以做几类关键优化。
5.1 Fusion:把多个 op 合成一个执行单元
前面的例子里,mul + add + mul + reduce 如果逐 op 执行,就会产生多次 kernel launch 和多次中间写回。
Fusion 的思路是:如果 producer 和 consumer 的关系足够清晰,就把它们合成一个 fusion computation。这样中间值可以留在寄存器、shared memory 或更近的层级里,不必反复写回显存。
这也是 XLA 在 GPU 上经常能拿到收益的原因之一。GPU 不怕算,怕碎、怕等、怕反复搬数据。
5.2 Algebraic simplification:消掉不必要的计算
深度学习图里经常会出现冗余 reshape、transpose、broadcast、算术恒等式、常量表达式。框架层写出来的图,未必是最简形态。
XLA 可以在 HLO 层做 algebraic simplification,把这些冗余结构消掉。比如两个连续 reshape 可能合并,某些 broadcast 后的 elementwise 操作可以重排,常量表达式可以提前折叠。
这类优化单看不性感,但在大模型和复杂训练图里非常重要。因为每省掉一个无意义中间 tensor,就可能省掉一次访存、一次调度、一次同步。
5.3 Layout assignment:选择硬件友好的 tensor 布局
同一个 tensor,逻辑 shape 一样,物理内存布局可以不一样。
对 CPU、GPU、TPU 或自研加速器来说,什么布局最合适并不相同。某些后端更喜欢连续访问,某些后端对向量化、tile、matrix unit、cache line 有特定偏好。
XLA 的 layout assignment 就是在后端语境下,为 tensor 选择更适合硬件的内存布局。
这一步如果做得好,计算单元更容易吃满;做得不好,硬件可能大部分时间都在等内存。
5.4 Buffer assignment:统一规划内存生命周期
逐 op 执行时,每个 op 更像独立申请和释放中间 tensor。编译器看到全图之后,可以做更激进的 buffer 复用。
Buffer assignment 关心的是:
- 哪些 tensor 生命周期不重叠?
- 哪些输出可以复用输入 buffer?
- 哪些中间结果可以原地写?
- 峰值内存能不能降下来?
这对训练尤其关键。训练图里激活、梯度、优化器状态、通信 buffer 都很吃内存。编译器能不能做全局内存规划,直接影响 batch size、模型规模和吞吐。
5.5 Target-specific lowering:进入目标后端
HLO 之后,编译链路会进入目标相关阶段。
例如 GPU 后端可能生成 LLVM IR,再走 NVPTX 路径生成 PTX;CPU 后端也常通过 LLVM 生成机器码;TPU 或厂商加速器则可能有自己的 executable 格式、runtime 和 library。
这一步开始,抽象的“张量计算”会越来越接近具体硬件:线程块、向量化、tile、memory hierarchy、ABI、runtime custom call、库调用,都要进入视野。
这也是为什么 XLA 既像“机器学习编译器”,又必须深度理解硬件。
6. 发展时间线:TFXLA、JAX、MLIR、StableHLO、PJRT、OpenXLA
XLA 的演进不是为了让架构图更漂亮,而是被一个个真实瓶颈推着走。
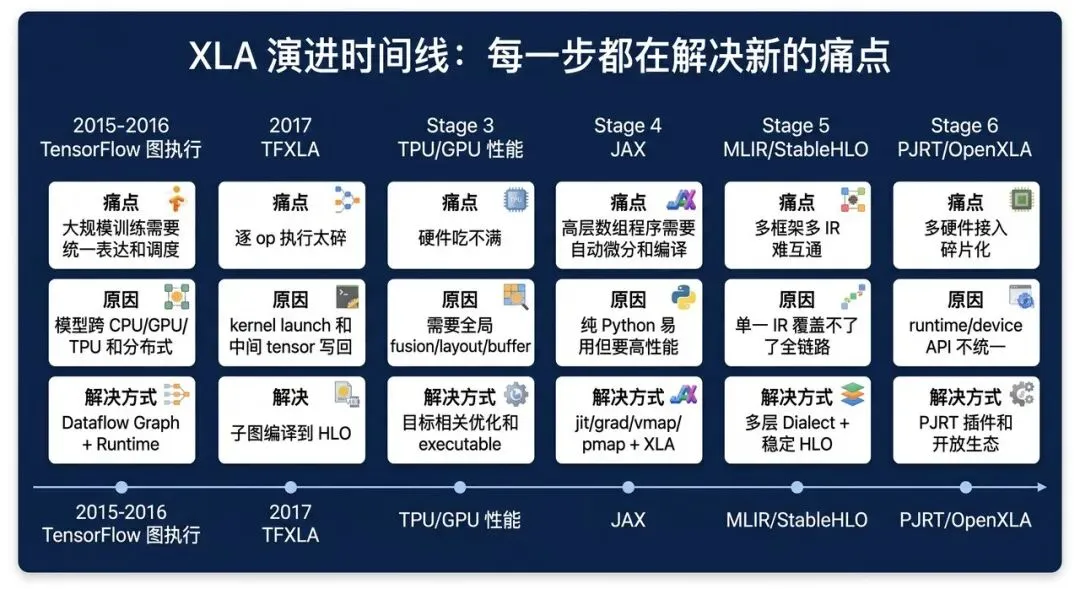
如果只记名词,很容易把这条线看散:TensorFlow、XLA、JAX、MLIR、StableHLO、PJRT、OpenXLA 好像每个都是单独冒出来的新系统。
但按时间顺序看,它们其实在回答同一个问题:
模型越来越复杂,硬件越来越多,框架越来越碎,谁来把“高层模型代码”稳定、高效地变成“硬件可执行程序”?
下面按“痛点是什么、为什么出现、怎么解决”来拆。
6.1 2015-2016:TensorFlow 图执行——先把大规模训练表达出来
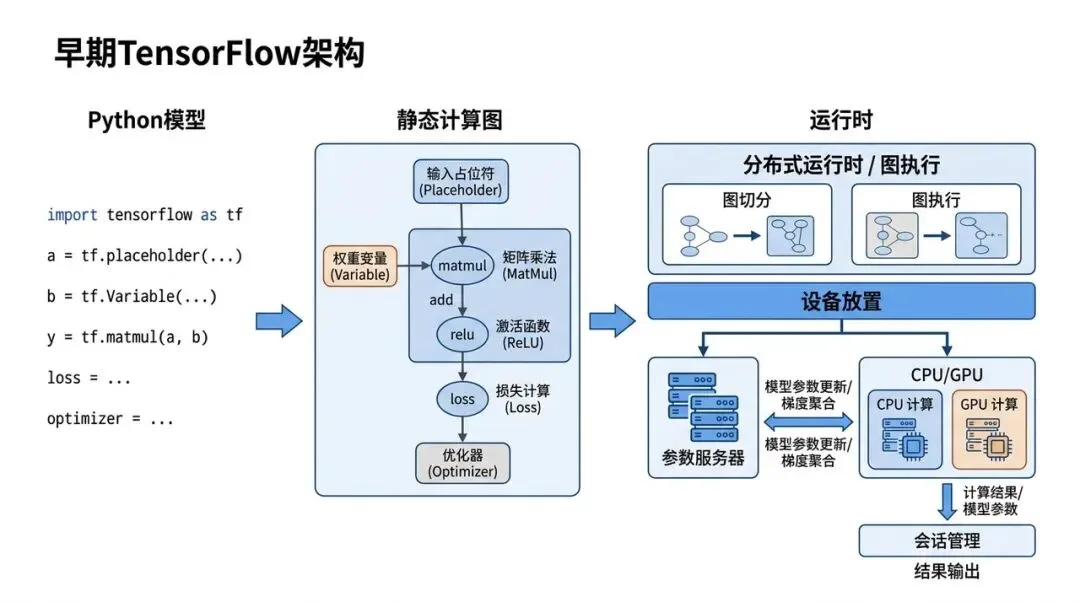
2015-2016:早期 TensorFlow 架构,静态图加运行时调度
痛点是什么?
早期深度学习代码更多是命令式调用:一层一层算,一步一步执行。研究原型很好写,但工业训练很快遇到更大的问题:模型要跨 CPU、GPU、TPU,要分布式训练,要保存状态,要和 Serving、监控、数据流水线接起来。
这时框架不能只知道“下一行 Python 要算什么”,而要知道整张计算图:哪些 op 依赖哪些 tensor,哪些变量是状态,哪些节点可以并行,哪些计算适合放到什么设备。
为什么会出现?
因为工业界面对的不是单卡小模型,而是大规模机器学习系统。训练和推理需要稳定的图表示、设备放置、状态管理、分布式调度和生产部署。
大概怎么解决?
TensorFlow 用 Dataflow Graph 把计算表达成图,再用 runtime 负责执行、设备放置、通信和状态管理。
这一步解决的是“模型如何被系统理解和调度”的问题。但它也留下了下一阶段的问题:图能表达计算,不代表硬件执行已经足够高效。
6.2 2017:TFXLA——逐 op 执行太碎,必须把子图编译起来
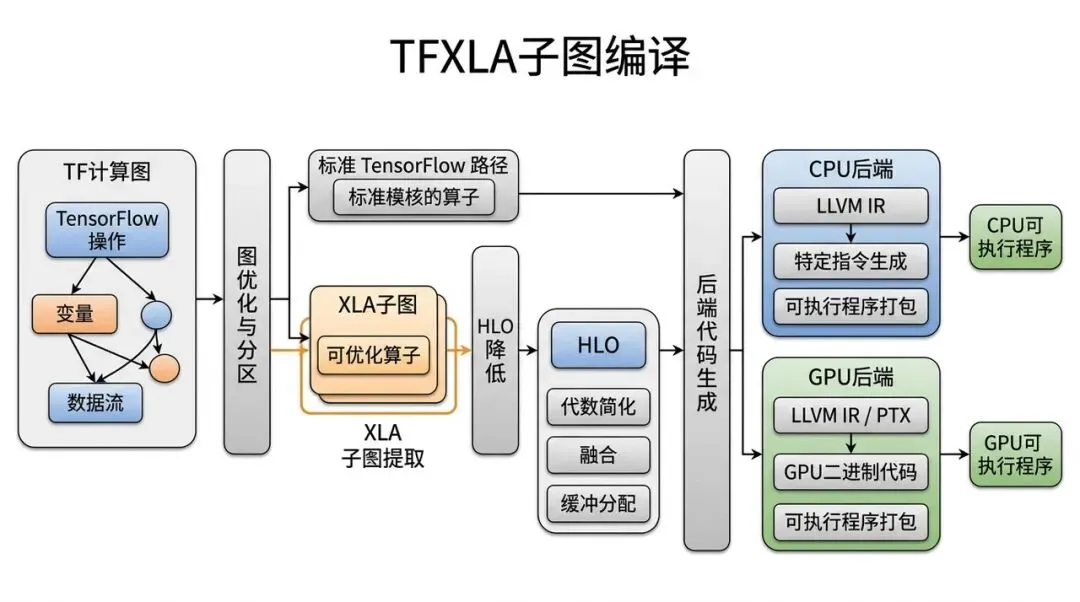
2017:TFXLA 架构,把 TensorFlow 子图抽成 XLA Cluster 后编译
痛点是什么?
TensorFlow Graph 里的计算最终还是经常按 op 调度。一个 mul + add + reduce 的小片段,可能变成多个 kernel launch 和多次中间 tensor 写回。
模型越大,op 越多,这种“碎片化执行”越明显。
为什么会出现?
框架 op 是很好的 API 边界,但不是最好的硬件执行边界。单个 op kernel 看不到上下游,也就很难做跨 op fusion、全局 buffer 规划和 layout 优化。
大概怎么解决?
XLA 把可编译的 TensorFlow 子图 lowering 到 HLO,在 HLO 层做融合、代数化简、常量折叠等优化,再生成 CPU/GPU/TPU 可执行程序。
这一步解决的是“不要把模型执行拆成一堆碎 op”的问题。
6.3 TPU / GPU 性能阶段:硬件越来越强,编译器必须更懂硬件
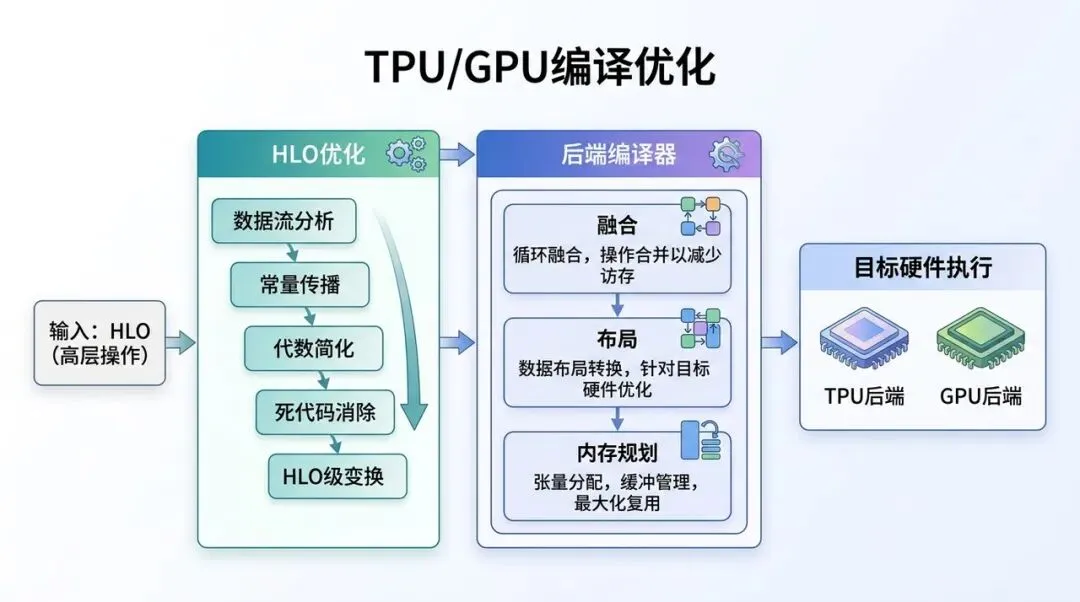
TPU/GPU 性能阶段:HLO 优化之后进入面向硬件的后端编译
痛点是什么?
TPU 和 GPU 的算力很强,但如果输入的是一堆细碎 op,它们并不会自动吃满。很多时候瓶颈不是浮点计算,而是 kernel launch、显存读写、layout 不合适、buffer 生命周期规划不足。
为什么会出现?
专用加速器希望拿到更完整、更规整、更接近硬件执行形态的计算。它们不希望 runtime 每次只丢过来一个小 op,而希望 compiler 能做整体优化。
大概怎么解决?
XLA 在 HLO 之后加入目标相关优化:layout assignment、tiling、backend-specific fusion、library call、buffer assignment、codegen。
这一步让 XLA 从“图编译器”变成真正面向硬件性能的 ML compiler。
6.4 JAX:高层数组程序也需要编译
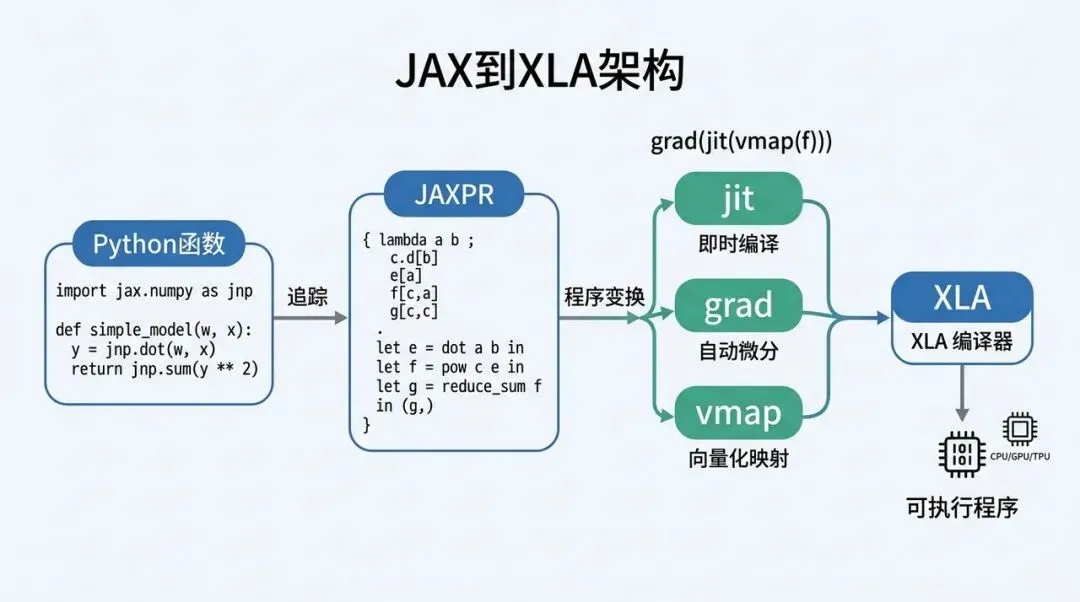
JAX 到 XLA:Python 数值函数经 tracing 和程序变换后进入编译器
痛点是什么?
研究者喜欢 Python/NumPy 风格的高层表达,也希望自动微分、向量化、并行化都能自然组合。但纯 Python 执行不适合高性能训练。
为什么会出现?
科学计算和深度学习都在追求同一件事:用户用接近数学的方式写程序,系统负责追踪计算、自动微分、编译优化和设备执行。
大概怎么解决?
JAX 通过 tracing 捕捉 Python 数值程序,把它转成中间表示,再交给 XLA 编译。jit、grad、vmap、pmap 这些能力,让“程序变换 + 编译”成为主范式。
这一步改变了 XLA 的心智:它不再只是 TensorFlow 的后端,而是高层数组程序的编译目标。
6.5 MLIR:单一 IR 覆盖不了全链路
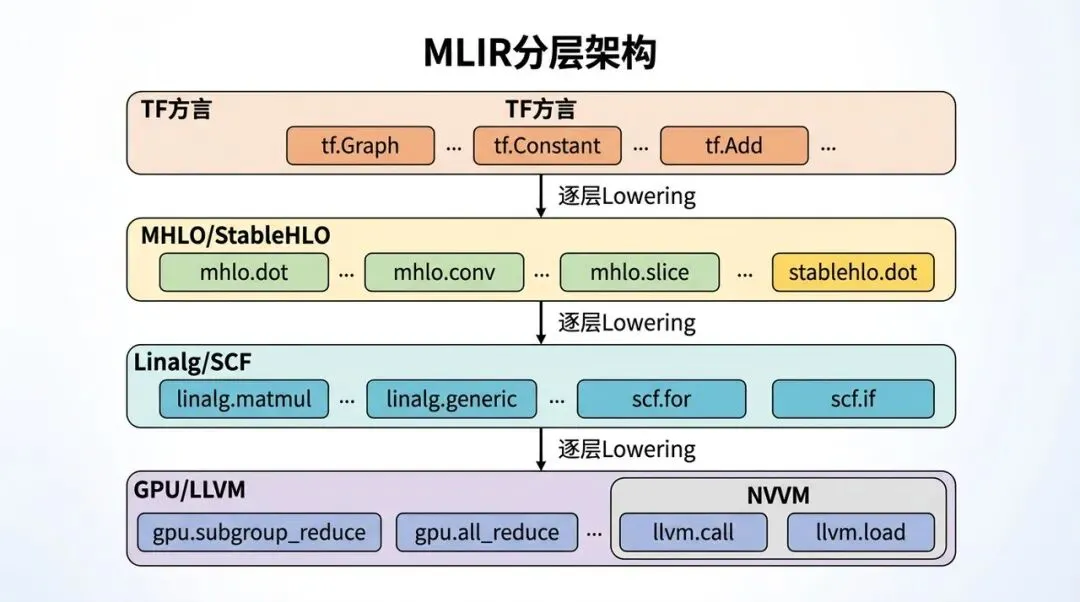
MLIR 分层架构:用多个 Dialect 承接从框架到硬件的语义变化
痛点是什么?
TensorFlow GraphDef 太高层,HLO 适合张量代数,LLVM IR 太底层。深度学习编译链路从框架语义一路降到硬件指令,中间需要很多层表达。
为什么会出现?
控制流、动态 shape、tensor 语义、linalg、loop、memory、GPU block/thread、LLVM lowering,这些东西很难全部塞进一个 IR 里。
大概怎么解决?
MLIR 提供 dialect 机制和多层 lowering 基础设施。框架可以有 TF Dialect,HLO 可以进入 MHLO/StableHLO,结构化计算可以进入 Linalg/SCF/Affine,低层再进入 GPU/NVVM/ROCDL/LLVM Dialect。
这一步解决的是“编译器链路如何模块化、分层、可扩展”的问题。
6.6 GSPMD:单设备编译不够,大模型需要自动分片
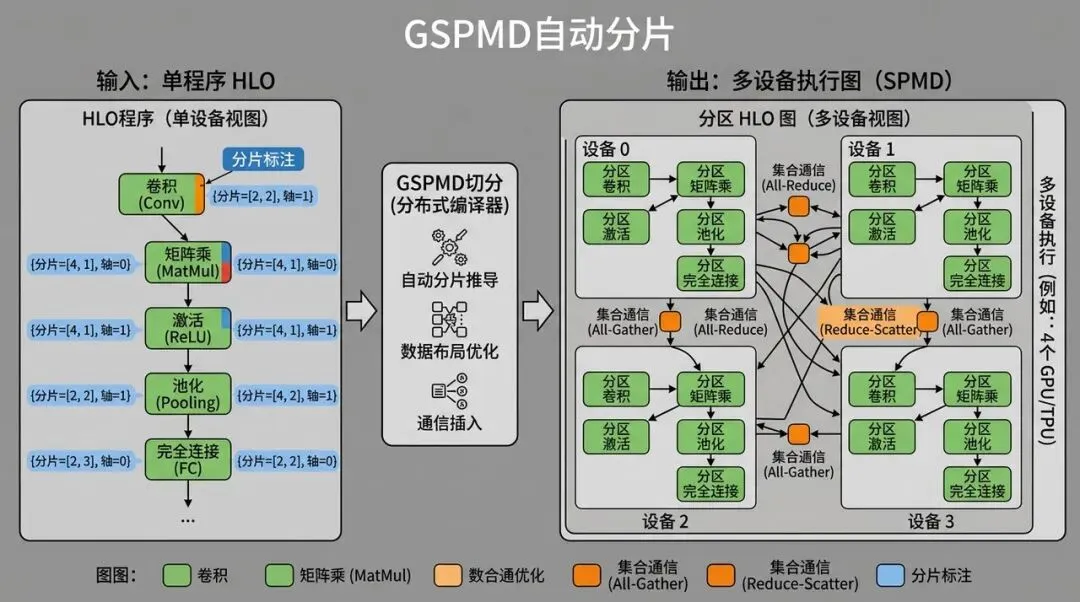
GSPMD 自动分片:单程序加分片标注,编译器生成多设备执行图
痛点是什么?
大模型训练不可能只靠单设备。数据并行、张量并行、流水并行、专家并行混在一起后,手写分布式逻辑成本极高。
为什么会出现?
模型规模增长超过单设备能力,开发者又不希望每个模型都重写一套通信和分片逻辑。
大概怎么解决?
GSPMD 让用户在少量 tensor 上标注 sharding,编译器把 HLO 图自动 partition 到多设备上。开发者更像是在写单设备程序,编译器负责把它扩展成多设备程序。
这一步让 XLA 从“单设备性能编译”走向“大规模分布式编译”。
6.7 StableHLO:多框架和多编译器之间需要稳定契约
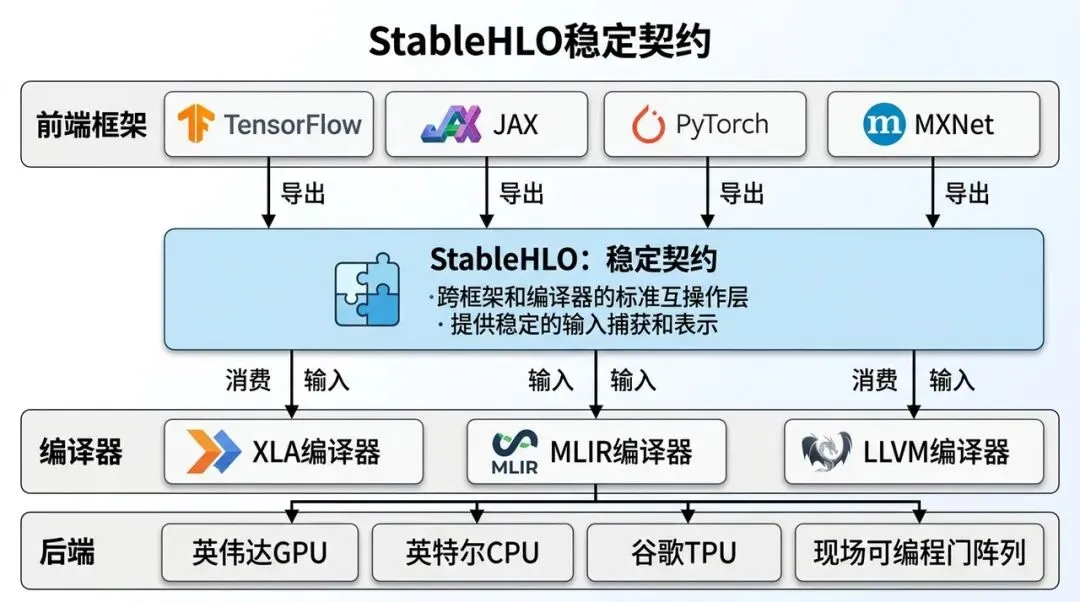
StableHLO 稳定契约:多前端和多后端之间的共同语言
痛点是什么?
如果每个框架都输出一套私有 IR,每个编译器都适配一遍,生态会非常碎。前端和后端强耦合,版本一变就容易断。
为什么会出现?
TensorFlow、JAX、PyTorch-XLA、IREE、厂商 compiler 都需要一个共同语言。这个语言既要保留 tensor 语义,又要稳定、版本化、可测试。
大概怎么解决?
StableHLO 把 HLO 操作集稳定下来,成为框架和编译器之间的 IR 契约。
可以把它理解成一句话:前端不要把内部私有图直接扔给后端,而是导出一个稳定的、可交换的张量计算表示。
6.8 PJRT / OpenXLA:设备接入也需要统一边界
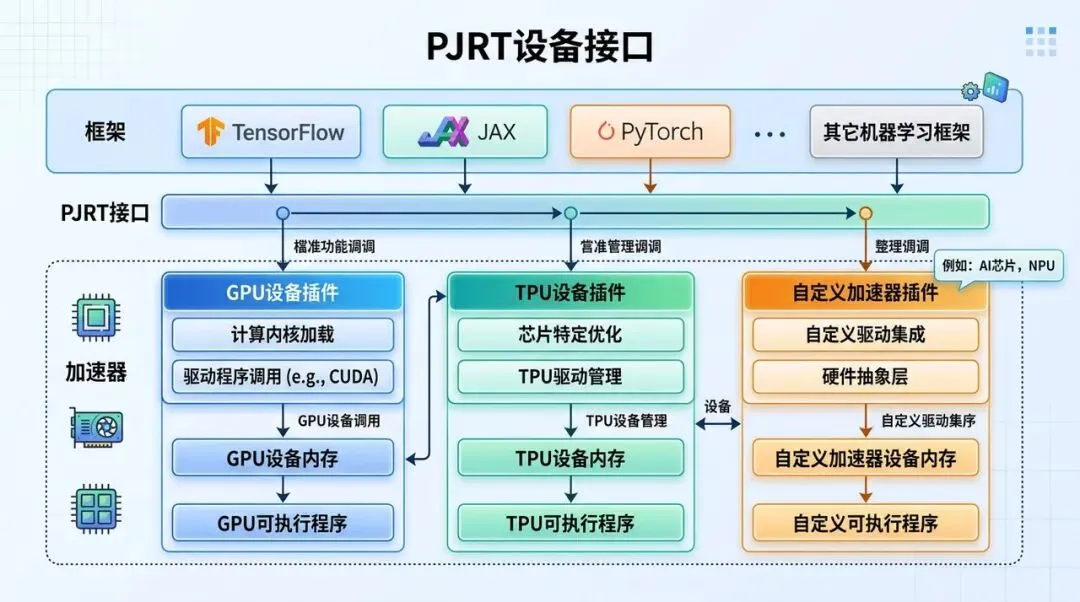
PJRT 设备接口:框架通过统一 API 调用不同硬件插件
痛点是什么?
就算 IR 稳定了,框架怎么调用设备、怎么加载 executable、怎么管理 memory、stream、event、collective,仍然可能各做各的。
为什么会出现?
硬件越来越多:CPU、GPU、TPU、Trainium、各种厂商加速器。每个框架都直接接每个硬件,复杂度会爆炸。
大概怎么解决?
PJRT 提供统一 Device API,框架通过 PJRT 调设备,硬件厂商通过 PJRT plugin 接入。OpenXLA 则把 XLA、StableHLO、PJRT 等组件放到更开放的生态框架里。
这一步解决的是“多框架、多硬件如何形成公共接口”的问题。
所以,XLA 的历史主线不是“TensorFlow 多了一个加速开关”,而是:
从图执行,到子图编译;从单框架后端,到多框架 IR;从单设备优化,到多设备分片;从内部 runtime,到开放设备接口。
7. MLIR 与 XLA 的关系:为什么 HLO 之外还需要多层 IR?
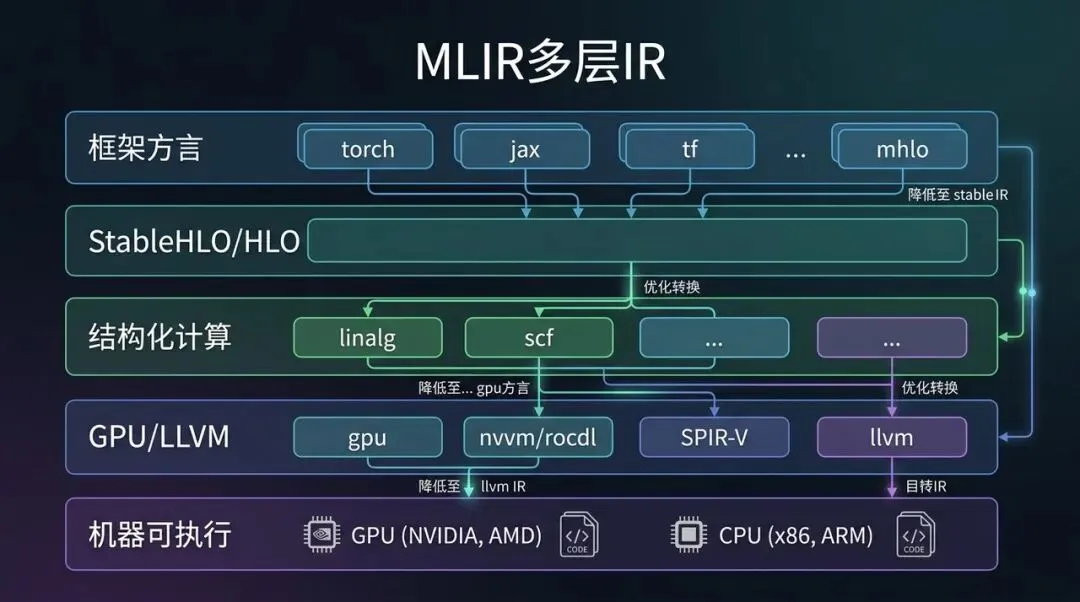
MLIR 多层 IR:从框架语义逐层 Lowering 到硬件执行
一个容易混淆的问题是:既然 XLA 已经有 HLO,为什么还需要 MLIR?
答案是:HLO 适合表达“张量计算图”,但整个机器学习编译链路远比 HLO 更长。
可以把几种 IR 放到一条层次线上看:
HLO 在中间层很强,尤其适合做 tensor algebra 层面的优化。但它不一定适合表达所有框架控制流、资源语义、动态 shape、低层循环、内存层次、GPU block/thread 映射。
MLIR 的价值是提供一个“可扩展 IR 家族”的框架:
- 高层 dialect 保留框架语义;
- 中层 dialect 表达张量、线性代数、循环和内存;
- 低层 dialect 对接 LLVM、GPU、SPIR-V 等后端;
- lowering 过程可以分阶段发生,每一层都有自己的 verifier、pass 和 pattern rewrite。
所以 MLIR 和 XLA 不是简单替代关系。
更准确地说:
XLA 是面向机器学习计算的编译器;MLIR 是构建多层编译器的基础设施。StableHLO / MHLO 把 XLA HLO 语义放进 MLIR 生态中,让框架、编译器和硬件后端之间更容易组合。
8. OpenXLA 的工程意义:从框架后端到跨生态接口
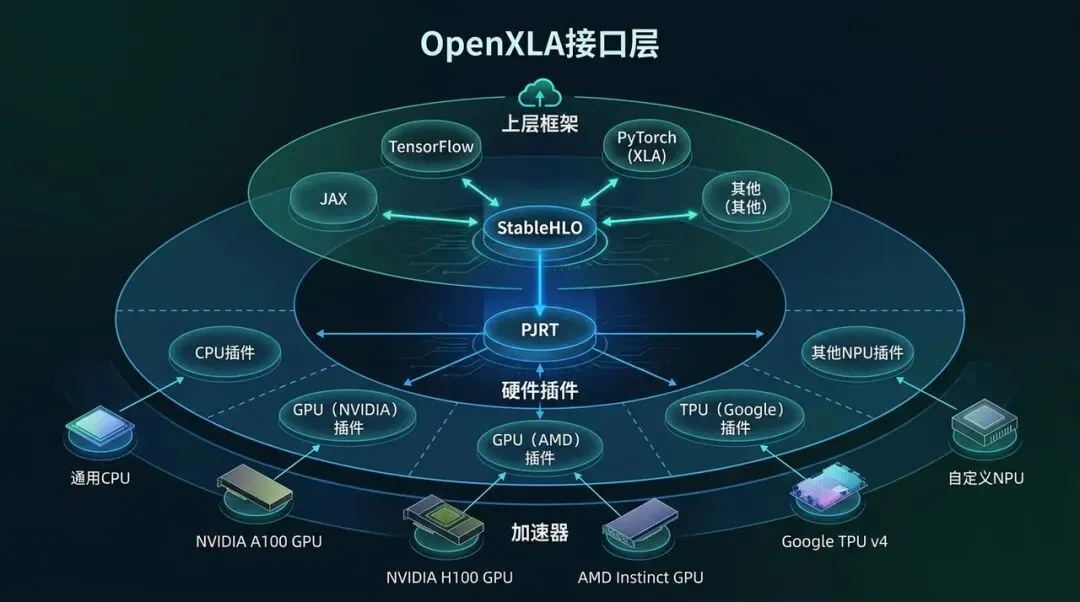
OpenXLA 接口层:StableHLO 连接前端,PJRT 连接设备
OpenXLA 最重要的变化,是把“XLA 作为 TensorFlow / JAX 内部编译器”升级成“多框架、多硬件都可以对接的编译接口层”。
这件事可以拆成两个接口。
8.1 StableHLO:前端和编译器之间的稳定契约
StableHLO 是一个版本化的 HLO 操作集。它解决的问题是:前端框架导出的 IR 不能今天一个样、明天一个样,否则后端编译器很难稳定支持。
理想链路是:
没有 StableHLO 时,框架和编译器之间很容易形成私有耦合。有了 StableHLO,前后端至少有了一个可以讨论兼容性的共同语言。
这对厂商很重要。因为硬件公司不一定想深度 fork TensorFlow 或 JAX,也不希望每个框架都接一遍私有 IR。StableHLO 给它们提供了更清晰的入口。
8.2 PJRT:框架和设备之间的统一 Device API
PJRT 可以理解为 OpenXLA 生态里的 device runtime API。它让框架通过统一接口和设备交互,设备厂商通过 PJRT plugin 接入。
理想链路是:
公开资料里,Google 把 PJRT 描述为 JAX 的唯一接口、TensorFlow 的主要接口,并支持 PyTorch/XLA。Intel Extension for TensorFlow 也使用 PJRT plugin 方向支持 Intel GPU。AWS Trainium 相关公开资料同样把 PJRT plugin 作为 JAX 面向新平台的重要接入方式。
这说明 PJRT 的价值不只是 Google 内部 runtime,而是在尝试成为一个更通用的设备接入边界。
当然,接口稳定不代表后端实现免费。
PJRT 解决的是“框架怎么调设备”的问题,不自动解决“设备怎么编译和执行模型”的问题。真正落地时,compiler、runtime、collective、memory management、library call、debug/profiler 都要补齐。
9. 工程落地视角:自研硬件接 XLA 为什么不等于“免费可移植”
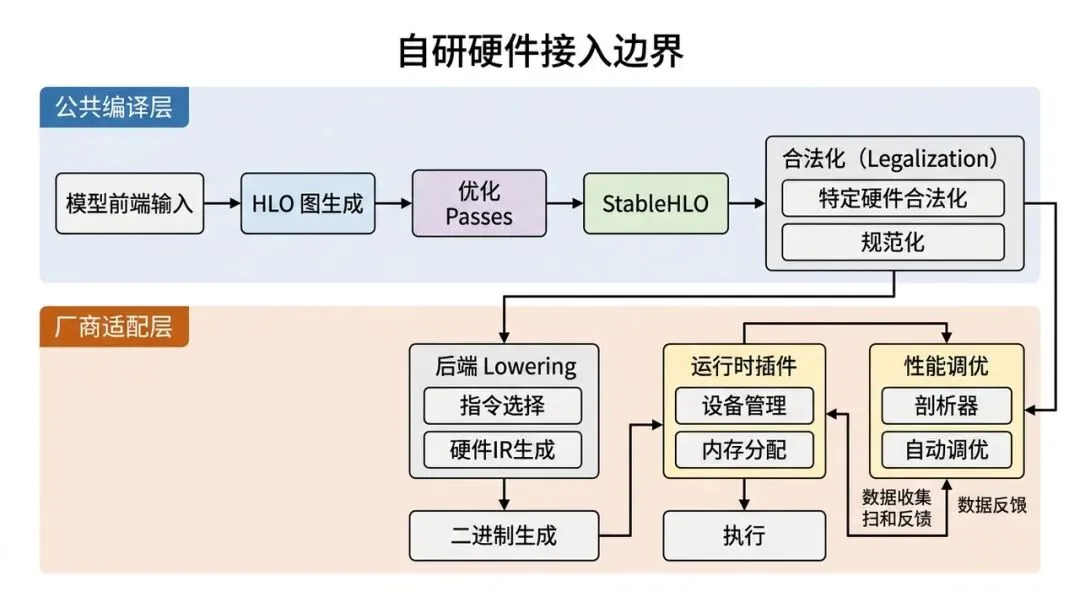
自研硬件接入 XLA 的真实边界:公共编译层之外还有厂商适配层
这部分对 AI Infra 工程师尤其重要。
很多团队第一次看 OpenXLA,会有一个直觉:既然 TensorFlow、JAX、PyTorch/XLA 都能到 StableHLO / XLA,那自研硬件是不是只要接一下 XLA,就能“免费吃到”多框架生态?
答案是:没那么简单。
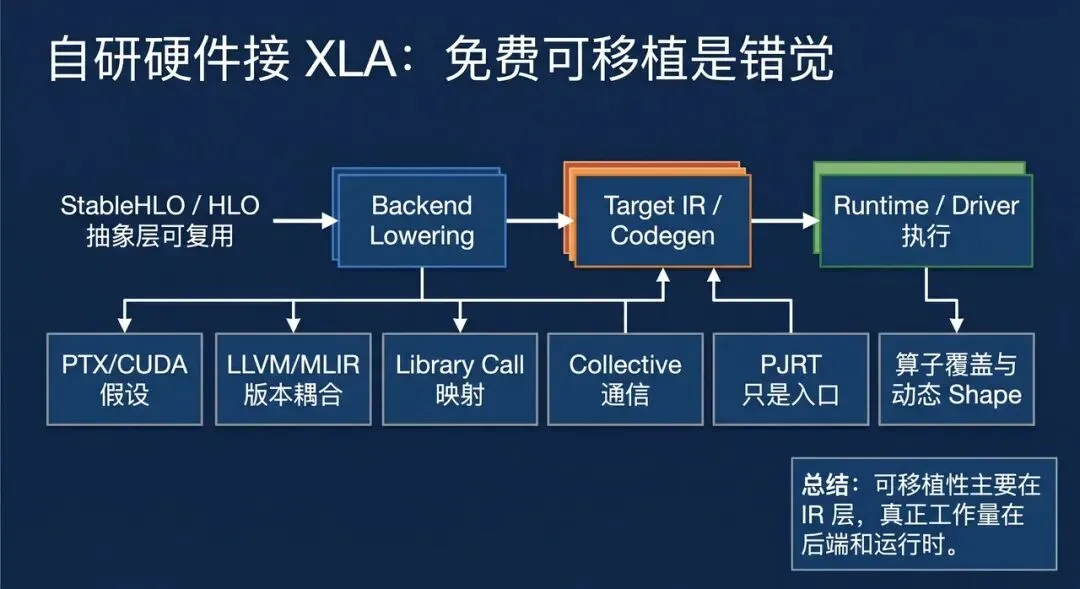
9.1 开源 GPU 路径默认绑定 CUDA / NV 生态
开源 XLA GPU 后端的大致路径是:
如果目标是 NVIDIA GPU,这条路很自然,因为 XLA GPU backend、LLVM NVPTX、CUDA driver、cuBLAS/cuDNN 等生态是配套的。
但如果目标是自研硬件,直接复用这条路径会遇到第一层问题:PTX 不是通用 accelerator IR,而是 NVIDIA 生态的中间目标。
更麻烦的是,TensorFlow / XLA 和 LLVM / MLIR 版本通常有强绑定。某个 TF 版本绑定特定 LLVM 版本,而自研硬件工具链可能使用另一个 LLVM 版本。强行替换 LLVM,往往会牵动 IRBuilder API、pass pipeline、target interface、MLIR/LLVM dialect 兼容性。
这不是改一个 Bazel 依赖就能解决的。
9.2 “拿 NV 路径生成 LLVM IR 再给自研后端编”通常也不稳
一个自然想法是:能不能复用 XLA GPU 前半段,让它先生成 LLVM IR,然后把这个 LLVM IR 交给自研后端?
问题在于,这个 LLVM IR 往往不是“纯净、硬件无关”的 IR。它可能已经带有:
- NV target assumption;
- CUDA builtin / libdevice 依赖;
- 地址空间和 ABI 假设;
- warp / thread / block execution model;
- 对 cuBLAS / cuDNN 或 runtime custom call 的依赖;
- 特定 LLVM 版本的 IR 细节。
所以即使 LLVM 版本对齐,也还要做 target 语义转换。否则拿到的不是“通用张量计算”,而是一段已经偏向 CUDA / NV 生态的低层代码。
9.3 原生 XLA backend、StableHLO、自研 compiler、Triton-like 路径怎么选?
评估 XLA / OpenXLA 接入自研硬件时,不建议只问“XLA 能不能支持”。更好的问题是:我们在哪一层接入?
| 方案 | 优点 | 主要成本 | 风险 |
|---|---|---|---|
| 原生 XLA backend | 语义贴近 TF/JAX/OpenXLA,长远更正统 | HLO lowering、LLVM/MLIR 版本、runtime、custom call、库映射全要做 | 多 TF 版本维护成本高 |
| 复用开源 GPU LLVM IR 路径 | 看似能少做前端 | CUDA/NV 假设很重,需要剥离 target 依赖 | PTX/ABI/builtin 不兼容,可能越改越深 |
| StableHLO → 自研 compiler | 前端边界清晰,避开 TF 内部耦合 | 需要完整消费 StableHLO,并实现优化/代码生成 | 算子覆盖和动态 shape 语义要补齐 |
| StableHLO → Triton-like 路径 | 可复用 Triton 生态和已有后端投入 | 需要把 HLO/Linalg 等模式转成 Triton 可表达 kernel | 不是所有 HLO 模式都天然适合 Triton |
| PJRT plugin | 框架接入形态更标准 | 只解决 runtime / device API,不自动解决 compiler 后端 | compiler 能力不足时,PJRT 只是入口 |
如果只是短期支持几个存量 TensorFlow 模型,强行做完整原生 XLA backend 可能过重。
如果目标是长期进入 OpenXLA 生态,StableHLO + PJRT + 自研 compiler/backend 会更有战略价值。
但无论选哪条路,都要提前回答七个问题:
- 前端需求:必须支持 TensorFlow 存量业务吗?还是主要面向 JAX / PyTorch 新业务?
- IR 边界:选择 GraphDef、TF Dialect、StableHLO、HLO、Linalg、Triton IR 中哪一层作为主入口?
- 版本策略:支持一个固定 TF/LLVM 组合,还是支持多个历史版本?
- 后端能力:是否已有成熟 LLVM target、MLIR dialect、Triton backend 或专用 graph compiler?
- 运行时能力:PJRT、stream、event、memory、collective、custom call、profiler 是否齐全?
- 算子覆盖:核心模型是推荐、CV、NLP、LLM 还是通用训练?动态 shape 和稀疏算子多不多?
- 性能目标:追求功能跑通、单模型打磨,还是通用模型覆盖?
这比单纯说“走原生 XLA”或“转 Triton”更接近真实决策。
10. 最后:怎样理解 XLA 的历史位置?
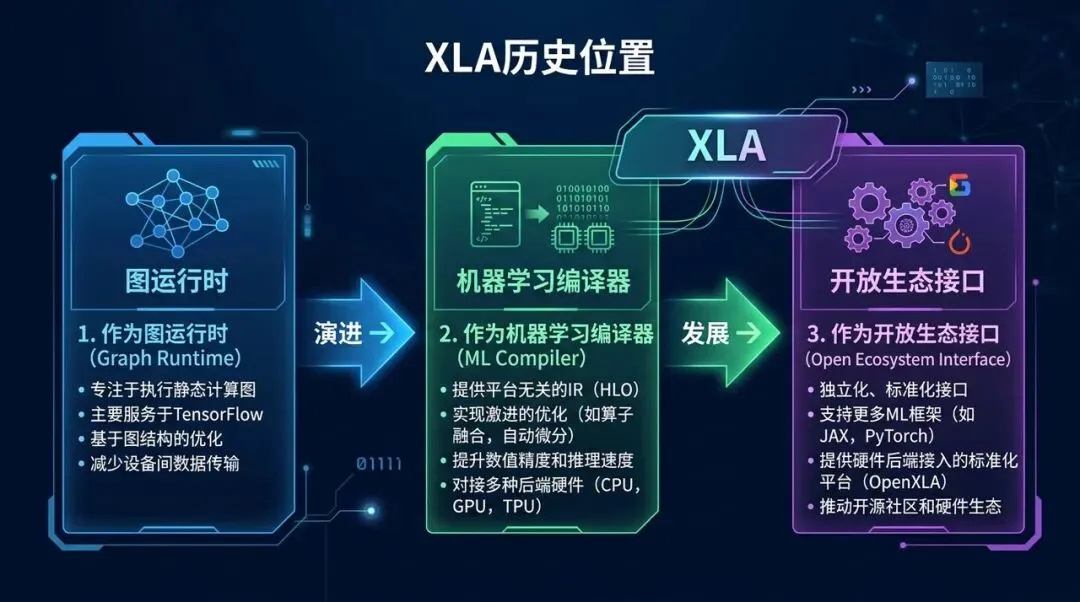
XLA 的历史位置:从图运行时后端,到机器学习编译器,再到开放生态接口
XLA 的历史可以压缩成三句话。
第一,它最初是 TensorFlow 为了解决逐 op 执行低效而引入的图编译器。
第二,它后来被 TPU、GPU 性能需求、JAX program transformation、大规模并行训练推成了通用 ML compiler 的核心部件。
第三,它现在通过 StableHLO 和 PJRT 进入 OpenXLA 生态,目标是成为多框架、多硬件之间的公共编译层。
所以,如果只把 XLA 理解成 jit_compile=True,会低估它的历史位置。
它真正代表的是深度学习系统的一次重心迁移:
从逐算子执行,走向整体图编译;从单框架后端,走向跨框架、跨硬件的编译生态。
对 AI Infra 工程师来说,理解 XLA 不是为了背一堆名词,而是为了看懂今天很多系统设计背后的共同逻辑:
- 为什么大模型训练越来越依赖 compiler?
- 为什么 JAX 能和 TPU 生态结合得那么深?
- 为什么 StableHLO、PJRT、MLIR 会变成厂商讨论硬件接入时绕不开的接口?
- 为什么自研硬件不能只说“兼容 XLA”,还必须讲清楚 lowering、runtime、library、collective 和版本策略?
TensorFlow 的时代也许已经不像过去那样站在舆论中心,但它留下的 XLA 主线,仍然在今天的 AI 编译器生态里继续生长。
下一篇如果继续沿着“AI 编译器”这条线走,我们就可以顺着 StableHLO、MLIR、Triton、IREE、TVM、TorchInductor 这些系统,继续拆解一个更大的问题:
当模型越来越大、硬件越来越多、框架越来越碎,AI Infra 到底该把“性能”交给谁?
参考资料
- OpenXLA Project:https://openxla.org/
- OpenXLA XLA GitHub:https://github.com/openxla/xla
- Google Open Source Blog: OpenXLA is available now:https://opensource.googleblog.com/2023/03/openxla-is-ready-to-accelerate-and-simplify-ml-development.html
- Google Open Source Blog: PJRT Plugin to Accelerate Machine Learning:https://opensource.googleblog.com/2024/03/pjrt-plugin-to-accelerate-machine-learning.html
- Google Open Source Blog: A Robust Open Ecosystem for All: Accelerating AI Infrastructure:https://opensource.googleblog.com/2024/12/a-robust-open-ecosystem-accelerating-ai-infrastructure.html
- Intel Extension for TensorFlow: OpenXLA Support on GPU via PJRT:https://intel.github.io/intel-extension-for-tensorflow/v2.13.0.0/docs/guide/OpenXLA_Support_on_GPU.html
- TensorFlow: A system for large-scale machine learning:https://research.google/pubs/pub45381/
- TensorFlow v1.0.0 Release Notes:https://github.com/tensorflow/tensorflow/releases/tag/v1.0.0
- TensorFlow XLA documentation:https://www.tensorflow.org/xla
- OpenXLA TF2XLA JIT compile tutorial:https://openxla.org/xla/tf2xla/tutorials/jit_compile
- Pushing the limits of GPU performance with XLA:https://blog.tensorflow.org/2018/11/pushing-limits-of-gpu-performance-with-xla.html
- MLIR official website:https://mlir.llvm.org/
- MLIR: A Compiler Infrastructure for the End of Moore's Law:https://arxiv.org/abs/2002.11054
- GSPMD: General and Scalable Parallelization for ML Computation Graphs:https://arxiv.org/abs/2105.04663
「老许漫谈AIInfra」 · 持续关注 AI 基础设施工程实践
