 夜雨聆风
夜雨聆风
AI价格战:中国开源模型如何改写全球AI经济学
硅基艺志 · 深度解读 · 2026.06.15
2026年6月,全球AI产业正在经历一场定价权的范式级地震——震源不在硅谷,而在杭州。
5月23日,DeepSeek宣布其旗舰模型V4-Pro的API价格从限时2.5折永久锁定为正式定价:输入\$0.15/百万token,输出\$0.28/百万token。这一价格仅相当于Anthropic Claude Opus 4.7输出价格\$75/百万token的约1/268,OpenAI GPT-5.5输出价格\$14/百万token的1/50。
这不是促销,这是一次定价锚的重置。它宣告了一个残酷事实:AI模型正在从"奢侈品"变成"日用品",而主导这场变革的不是拥有8520亿和9650亿估值的美国双雄,而是一群用MoE架构、国产芯片和极致工程效率武装起来的中国公司。

把数字摊开来看,差距已经不是"有竞争力",而是数量级的碾压。
| 模型 | 输入价格 (\$/百万token) |
输出价格 (\$/百万token) |
相对DeepSeek 输出价差 |
|---|---|---|---|
| DeepSeek V4-Pro | ~\$0.15 | ~\$0.28 | 基准 |
| DeepSeek V4-Flash | \$0.14 | \$0.28 | ~1x |
| 小米 MiMo-V2.5 | 极低 | 极低 | — |
| GPT-5.5 | \$1.75 | \$14.00 | ~50x |
| Claude Opus 4.8 | \$5.00 | \$25.00 | ~90x |
| Claude Fable 5 | \$10.00 | \$50.00 | ~180x |
数据来源:DeepSeek官方定价页、Price Per Token、Anthropic官方文档、OpenRouter及多家第三方监测平台(截至2026年6月中旬)
SemiAnalysis的测算更触目惊心:一个\$200/月的ChatGPT Pro订阅,如果用户充分利用其token配额,OpenAI的实际服务成本高达\$14,000。OpenAI在GPU集群利用率仅5.7%时就已进入负利润区间,Anthropic的盈亏平衡点也仅有10%。换句话说,两家公司的商业模式本质上是"赌你不会用满"——而一旦企业开始认真计较每花一块钱能换回多少生产力,这个赌局就崩了。
彭博旗下Silicon Data的LLM Token支出指数已在6月连续7个交易日下跌,创2026年1月以来最长连跌纪录。这不是需求萎缩的信号——全球AI token总用量仍在爆发式增长——而是单位token价格在加速坍塌。企业正在用脚投票:从每任务必用最贵模型,转向按任务精准选型。
价格战不是凭空发生的。它是在企业账单失控的现实压力下被点燃的。
2026年5月,Uber COO Andrew Macdonald公开说了一句震动行业的话:token消耗的增长与产品实质改善之间,"这条线还不存在"。他甚至造了一个词——"tokenmaxxing"——形容员工为了刷AI使用量而执行无价值的任务。更扎心的是数字:Uber 2026年的全年AI编程预算,仅前四个月就烧光了。
这不是孤例。Salesforce预计2026年全年付给Anthropic的费用将达约3亿美元。某匿名公司在未限制员工访问Claude的情况下,单月token账单高达5亿美元。企业数据平台Entelligence.AI汇总2444家企业数据后发现一个令人不安的真相:每投入1美元AI token费用——
未创造终端价值
的实际价值
自身引入的bug
亚马逊率先叫停了内部"token消耗排行榜"——这个曾经被硅谷科技公司当作荣誉榜的内部竞赛。微软则开始逐步停用部分关键产品部门员工的Claude Code订阅。高盛在最新研报中指出,部分企业AI token支出已占到员工总人力成本的10%,并警告这一比例可能继续攀升。
账单失控,就是中国企业打开市场缺口的第一把钥匙。
中国开源模型的竞争力,最终要在真实商业场景中验证。三个美国企业的案例值得细看。
🏢 Lindy(AI行政助理公司)
创始人Flo Crivello试用DeepSeek V4处理邮件撰写、收件箱管理、日程安排和会议转录等核心场景。结果:表现与Anthropic Sonnet不相上下,成本仅为1/10。"省了几百万美元",Crivello说。但他也坦言如果Anthropic大幅降价,"我们可能回去"——省钱是硬道理,但切换成本是一道真实的护城河,只是这道护城河正在变浅。
⚖️ Harvey(法律科技公司)
采用混合路由策略——Claude Opus保留给最复杂的法律推理,常规工作分流到智谱GLM 5.1。结果:推理成本直降3倍,质量无明显下降。联合创始人Gabe Pereyra的新质量观:"质量的定义正在从'永远用最强模型',演变为'用最合适的模型给出正确答案'。"
🛡️ Detail(漏洞检测公司)
90%的推理负载已从Claude和Gemini切换到自研模型+GLM组合。这是更深层的趋势——企业不仅在使用中国模型,还在基于它们构建自己的专属模型。
这三个案例共同指向一个结论:"够用且便宜10倍"不是口号,是一个正在被验证的商业事实。
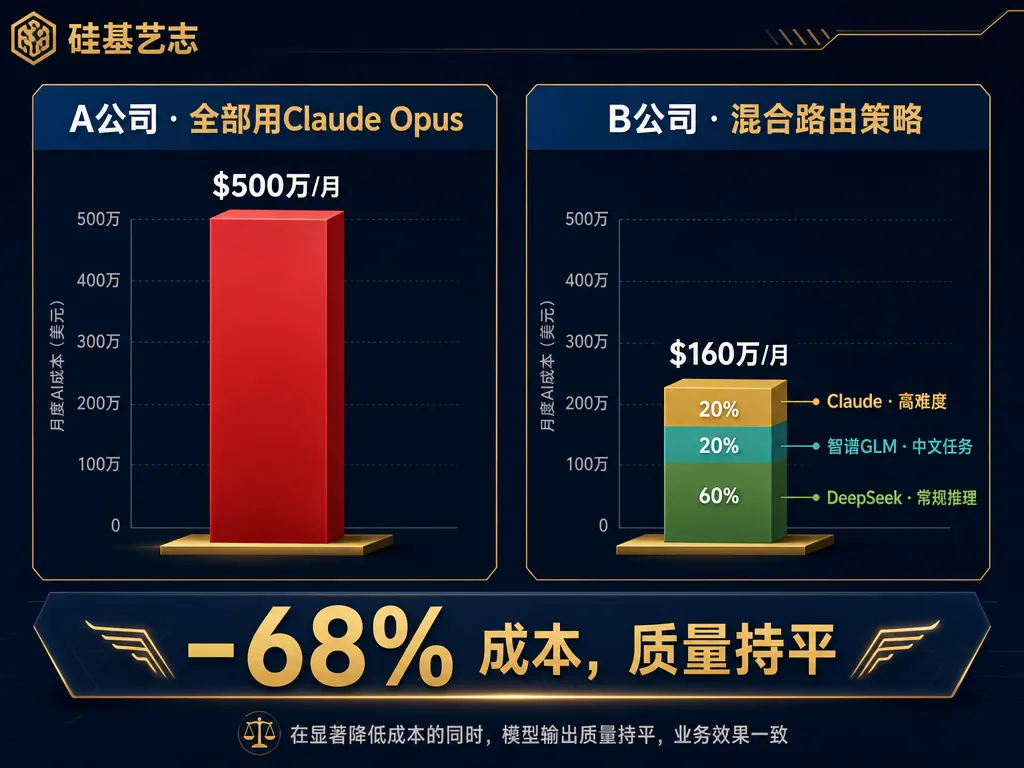
混合路由策略 vs 全Claude Opus:成本直降68%,质量持平
DeepSeek是价格战的引爆者,但它背后的中国开源矩阵才是真正的系统性力量。
DeepSeek V4
1.6万亿MoE · OpenRouter调用量全球第一 · SWE-bench 80.6%
智谱 GLM-5.1
Claude Opus 94.6%实力 · 订阅仅\$3/月
MiniMax M3
编程超GPT-5.5 · 港股+科创板双上市
Kimi K2.5
SWE-bench 65.6%超GPT-5.4 · 完全开源
Qwen 3.5
全球下载超7亿次 · 衍生模型18万+
小米 MiMo-V2.5
永久降价99% · OpenRouter全球周榜登顶
这不是一个孤胆英雄的故事。这是一个从芯片(昇腾950PR采购价仅为H200的1/3~1/4)到架构(MoE使单token算力降至传统架构的27%)到能源(西部绿电成本为美国的1/3~1/5)到规模(V4-Flash周调用量达3.43万亿token)的全栈成本优势。
OpenRouter数据:自2025年秋季至2026年春季,开源模型token用量增速是闭源模型的4倍。已有超过500家机构从专有模型完全切换到开源模型。
现在,回到那个最尖锐的问题。
OpenAI估值8520亿美元,Anthropic估值9650亿美元。两家公司合计估值超过1.8万亿美元——相当于加拿大的全年GDP。二者均已秘密向美国SEC提交S-1申请,冲刺Q4 2026上市。OpenAI明确将IPO目标估值定在1万亿美元。
这个估值建立在什么叙事上?简单说:前沿模型永远稀缺、永远昂贵、永远不可替代,企业将永无止境地向最强模型付费。但2026年6月的现实正在逐条瓦解这个叙事:
稀缺性在消失。中国开源模型与顶级闭源模型的综合性能差距已缩小到5%以内。SuperCLUE 2026年4月评测显示国产头部模型综合得分仅落后海外前三名不到1个百分点。
价格不可维持。当DeepSeek V4-Pro输出token比Claude Opus便宜约100倍且性能可接受时,企业不会为小数点级优势付100倍溢价。Sam Altman本人已承认成本成了"巨大问题"。
亏损在扩大。OpenAI每收入1美元就亏损约\$1.22。价格战将进一步压缩本已稀薄的利润空间。WSJ直言:价格战将"进一步扩大亏损,降低估值"。
结构性替代不可逆。Coinbase CEO预测80%的AI工作负载将在12-18个月内迁移到成本仅为当前1%的模型上。被"80%市场"抛弃的公司,估值逻辑需要根本性重写。
这不是说OpenAI和Anthropic会倒闭。它们仍有最强的综合能力、最完善的安全合规体系、最深厚的企业关系。但万亿美元估值隐含的假设是它们将吃掉整个市场的增长红利——而当中国企业把"够用"的价格压到它们的几十分之一后,这个假设不再成立。
这场价格战揭示了一个更底层的矛盾:AI行业的商业化和金融化逻辑正在发生冲突。
摩根士丹利的分析令人不安:五大超大规模云厂商的资本支出占收入比例持续攀升,而投资回报的信号越来越模糊。Gary Marcus警告:"一旦OpenAI走下坡路,很可能会拖垮英伟达、甲骨文、Coreweave等公司。"
💡 杰文斯悖论
效率提升 → 单价下降 → 总用量爆发式增长 → 算力总需求反而上升。DeepSeek降价75%后,调用量反而飙升到每周3.43万亿token,登顶OpenRouter全球榜首。IDC预测2026年全球AI支出突破\$1.4万亿。
在监管与数据主权的维度,中国模型存储用户数据于中国境内服务器,受《国家情报法》约束。对于处理敏感数据的美国企业和政府机构,这构成了实质性使用壁垒。但开源权重的可自部署性提供了折中方案——企业可以在自己的基础设施上运行中国开源模型,避开数据出境问题。
最终的格局可能呈现清晰的分化:90%的民用商用市场由高性价比的开源模型主导(中国模型在其中占据生态位优势),10%的涉密/主权/极端高难度场景由闭源旗舰模型守护。美国公司仍将在后者中保持优势——但这不足以支撑万亿美元估值。
2023年ChatGPT横空出世时,全球AI的叙事中心是硅谷。三年后,叙事中心正在分裂。中国公司不再是追随者——它们用MoE架构创新、国产芯片适配和极致的工程效率,主动定义了全球AI的"成本基准线"。
这不是"中国AI赢了"的简单叙事。美国企业在安全、合规、前沿探索和生态系统深度上仍然领先。但中国公司证明了一件事:AI不必昂贵到只有巨头才用得起。当AI从奢侈品变成日用品,受益的不是某一家公司,而是每一个想用AI但被价格挡在门外的创业者和中小企业。
对于OpenAI和Anthropic的万亿美元IPO,市场将用真金白银投票。但有一件事已经确定:不管结局如何,这场价格地震已经永久性地改变了全球AI经济学的底层逻辑。
定价权易手。DeepSeek V4-Pro永久降价75%不是促销,是中国开源模型从"跟随定价"到"设定基准线"的分水岭——输出价格仅为Claude Opus的1/100,差距大到已不能用"能力溢价"来解释。
万亿美元叙事承压。OpenAI和Anthropic冲刺万亿美元IPO的假设是"前沿模型永远稀缺且昂贵"。但中国企业用全栈成本优势证明"够用"可以被压到极低价格,而企业正在用脚投票。
赢家是应用层。推理成本砍掉75%甚至99%,最大受益者不是模型厂商,而是所有此前被token成本压制而不敢大规模部署AI的企业和开发者。AI真正的爆发,从价格跌穿ROI临界点开始。
📬 关注「硅基艺志」,获取AI产业深度解读。
我们追踪的不是新闻标题,是范式转移中的信号。
💬 今日互动
你所在公司或团队的AI token开销占比如何?如果中国开源模型价格仅为GPT/Claude的1/50且能力"够用",你会切换到中国模型吗?欢迎留言讨论。
完
硅基艺志 · AI创作,触手可及
