 夜雨聆风
夜雨聆风给AI agent装上专门的记忆管理模块,让它在连续任务中越做越好——这个听起来很合理的思路,在一组持续学习基准里没有稳定兑现。论文提出的CL-BENCH基准测试显示,最朴素的全上下文学习(ICL)在多数设置下反而是强基线,而即便是表现最好的系统,也仅捕获了25.4%的归一化增益,留下了巨大的提升空间。
持续学习:AI系统面临的真实挑战
当前LLM系统在部署中越来越多地需要"越用越聪明"的能力:软件工程 agent 在同一个代码库里工作数周后应该更高效,数据分析 agent 反复跟同一个数据集打交道应该学到门道,决策支持 agent 应该能从持续反馈中改进预测。这种能力被称为"持续学习"(continual learning)。
但问题在于:目前没有高质量的基准来评估AI系统是否真的在从经验中学习。 现有的评估要么测记忆检索的准确性,要么测上下文压缩后是否保留了信息,要么就是在预定义的技能分类上跑跑分——都没有直接测试一个系统能否通过在线经验发现环境中的隐藏结构,并利用这些发现提升后续表现。
[Figure 1: CL-BENCH评估框架] 以简化的数据库探索任务为例说明:agent按顺序完成一系列实例,积累经验和反馈以逐步提升。任务包含事先未知的可利用隐藏结构,例如混淆的数据库schema约定;学习型agent到第10个问题时可减少4倍查询量。第20个问题处发生数据库迁移(概念漂移),使部分已有知识失效。

六大领域、专家验证:CL-BENCH怎么设计的
论文提出的CL-BENCH横跨六个领域:软件工程、信号处理、疾病暴发预测、数据库查询、策略博弈和需求预测。每个任务都经过领域专家的结构化验证。
一个好的持续学习任务必须满足三个条件:(1) 有足够的提升空间(headroom),初始性能远低于可达上限,且隐藏结构不能靠预训练知识直接恢复;(2) 共享隐藏结构,跨实例存在可被发现并利用的规律,如代码库布局、对手策略、数据库schema;(3) 学习机制,前面实例产生的观察对后续实例有信息价值,环境提供可利用的反馈回路。
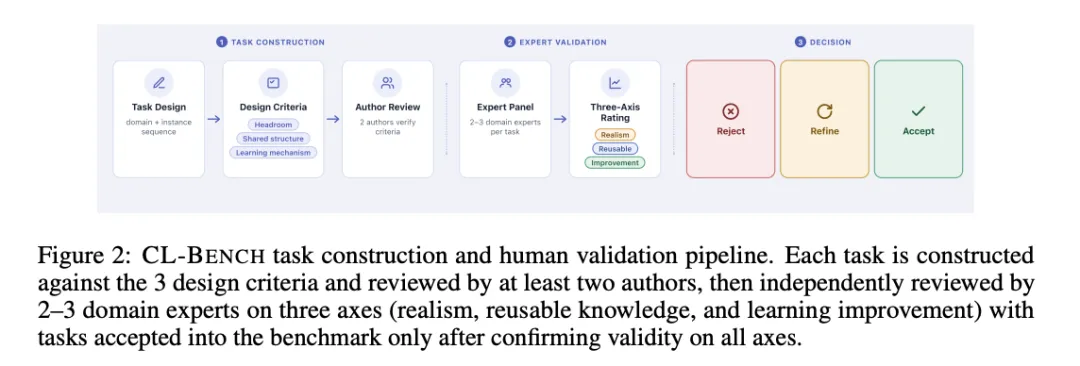
[Figure 2: CL-BENCH任务构建与人工验证流程] 每个任务按3项设计准则构建,经至少两位作者审核,再由2-3位领域专家从真实性、可复用知识和学习改进三个维度独立评审。专家平均每轮投入2.14小时进行验证。
论文特别强调,这些准则使得CL-BENCH无法通过简单串联现有基准的实例来构建——标准基准实例被设计为多样且独立的,一个足够强的模型不需要在线学习就能表现良好。
[Figure 3: CL-BENCH任务概览] 展示六个任务的实例数量、隐藏结构类型和奖励指标。交互方式从持久终端环境、结构化工具API到结构化输出各有不同。

怎么衡量"学没学到东西"
论文引入了一个关键指标——增益(gain)。直觉上,一个持续学习系统应该是"有状态的"(stateful),即它利用先前经验后的表现应该比从零开始(stateless)更好。增益的计算方式是:对每个实例,用有状态模式下的奖励减去同一系统在无状态模式下对同一实例的奖励。这样就能剔除实例本身难度的影响,只隔离出"从经验中学习"带来的性能提升。
[Figure 4: 增益指标概览] 计算有状态系统在任务实例上的表现与其独立处理每个实例时的表现之差,从而隔离出先前经验对性能的贡献。

为了跨任务比较,论文对增益做了归一化:除以系统自身的学习空间上限(最大可能奖励减去无状态基线),得到"已捕获学习空间的比例"。
前沿系统在持续学习任务上的表现
论文评测了多个前沿模型搭配不同 agent 架构的组合。学习系统包括:全上下文ICL(保留完整对话历史)、ICL Notepad(给agent一个持久记事本)、Mem0(自动语义提取和检索记忆,检索top-10条)、ACE(Adaptive Continual Experience,维护经验手册并在每个实例后更新),以及Claude Code和Codex等 agent 工具。所有系统在每个任务上跑5次取平均以减少随机性。
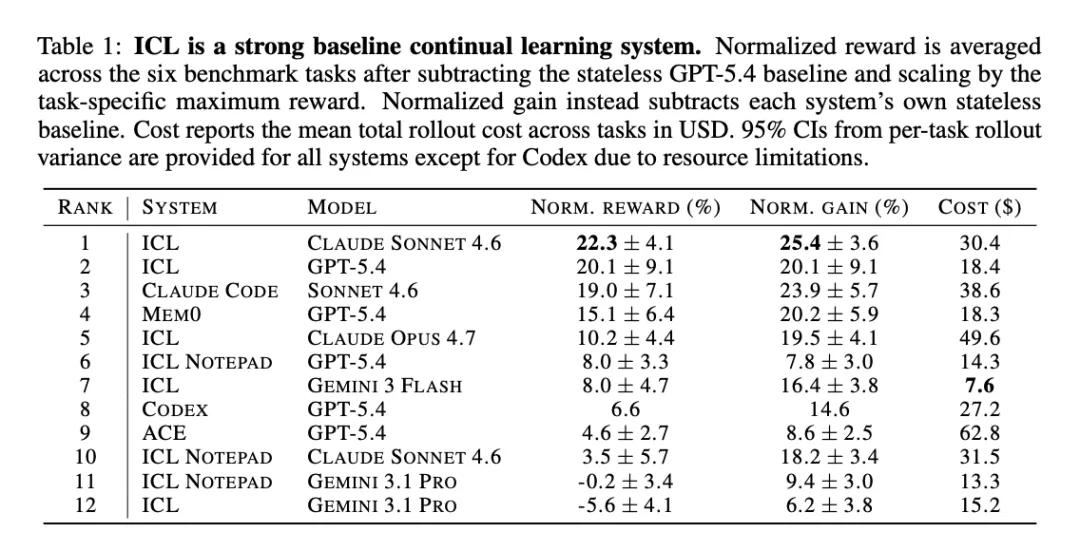
[Table 1: ICL是强基线持续学习系统] 展示各系统的归一化奖励、归一化增益和成本。ICL搭配Claude Sonnet 4.6以22.3%归一化奖励和25.4%归一化增益排名第一。ACE虽然每次运行成本最高($62.8),增益仅8.6%排第十。
几个核心发现值得注意:
朴素ICL在这组实验里是最强基线。 ICL搭配Claude Sonnet 4.6在归一化奖励和增益上都排名第一。ICL系统占据了增益排名前五中的三个位置。相比之下,使用同一模型的ICL Notepad增益明显更低,说明学习媒介的选择和底层模型同样重要。专门的记忆系统没有在该基准上稳定带来预期优势。
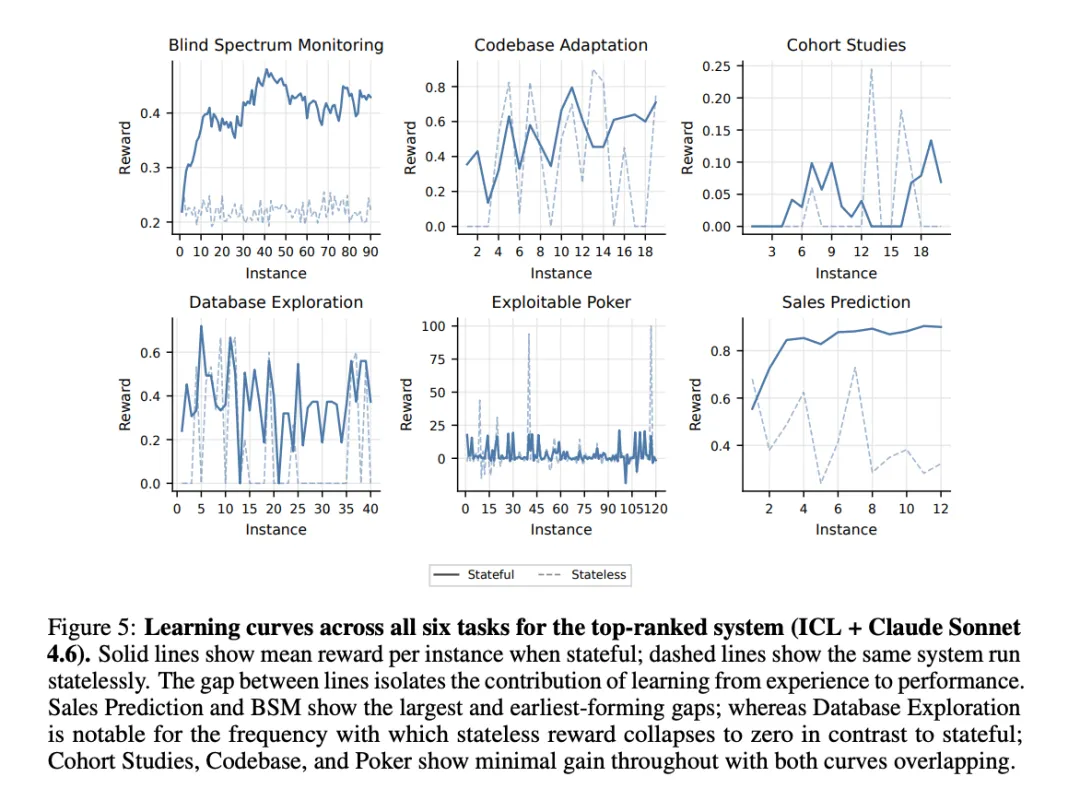
[Figure 5: 六个任务的学习曲线] 展示排名第一系统(ICL + Claude Sonnet 4.6)的逐实例表现。Sales Prediction和Blind Spectrum Monitoring表现出最清晰的学习信号;Cohort Studies几乎看不到学习效果,有状态和无状态曲线高度重叠。
成本效率同样偏向ICL。 ICL搭配Gemini Flash每次运行仅$7.6,增益达16.4%,性价比最优。而ACE花费$62.8、Claude Code花费$38.6,并未将高成本转化为更高增益。不过Claude Code在Sales Prediction(65.1%增益)和Database Exploration(43.6%增益)两个单项上表现突出。
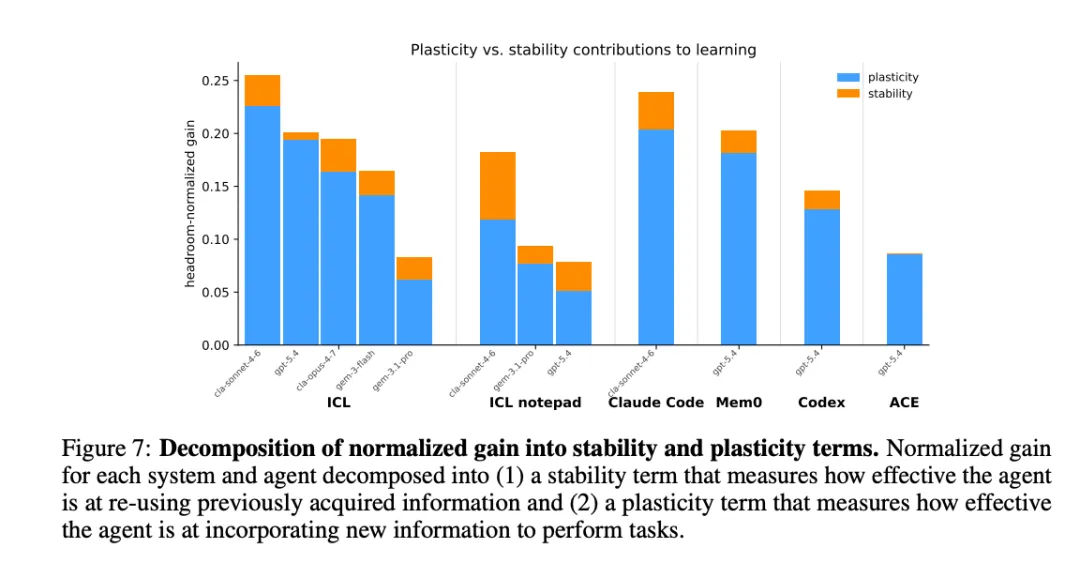
[Figure 7: 归一化增益的稳定性与可塑性分解] 将增益拆解为"稳定性"(跨变体保留知识的能力)和"可塑性"(在变体内快速适应新信息的能力)两个分量。ICL Notepad表现出最强的稳定性学习,而ICL和Claude Code在可塑性上领先。有些系统(如ACE)几乎没有稳定性学习,说明其增益主要来自同一变体的重复暴露。
具体失败case长什么样
论文给出了两类典型失败案例。稳定性失败:在Sales Prediction中,agent在上一轮得到0.945分的反馈后,判断纽约地区被过度预测,于是将某系列的预测拉平。结果分数降到0.936,agent又立刻认为自己预测不足——即时观察压过了对长期需求的先验认知。可塑性失败:在Cohort Studies中,agent已经在前面的研究中观察到了跨研究的证据,但到第15个实例时,对于当前数据集缺失的28个群组,agent直接以"这些群组定义来自不同研究的schema,不适用于这里"为由提交了默认值——早期积累的跨研究证据完全没有被调用。
持续学习仍是一个未解决的问题
CL-BENCH目前覆盖六个领域,任务序列在几十个实例的量级。论文承认这不能完全代表最长部署周期的场景,且当前评估聚焦于基于上下文的记忆范式,尚未评估参数化方法(如测试时训练)。
最好的系统也只捕获了25.4%的可用学习空间,累积的状态经常帮倒忙而非帮忙。 记忆模块引入虚假泛化和过时信念,更贵的系统未能将成本转化为性能。这些结果表明,LLM-based agent的持续学习仍然是一个开放问题——而CL-BENCH提供了追踪这一问题进展的基础设施。
📄 原文标题
Continual Learning Bench: Evaluating Frontier AI Systems in Real-World Stateful Environments
🔗 原文链接
https://arxiv.org/abs/2606.05661
