 夜雨聆风
夜雨聆风⏱ 预计阅读:18 分钟,文章较长,可点击收听;PC端阅读更佳;关注不迷路,加星标更聚焦
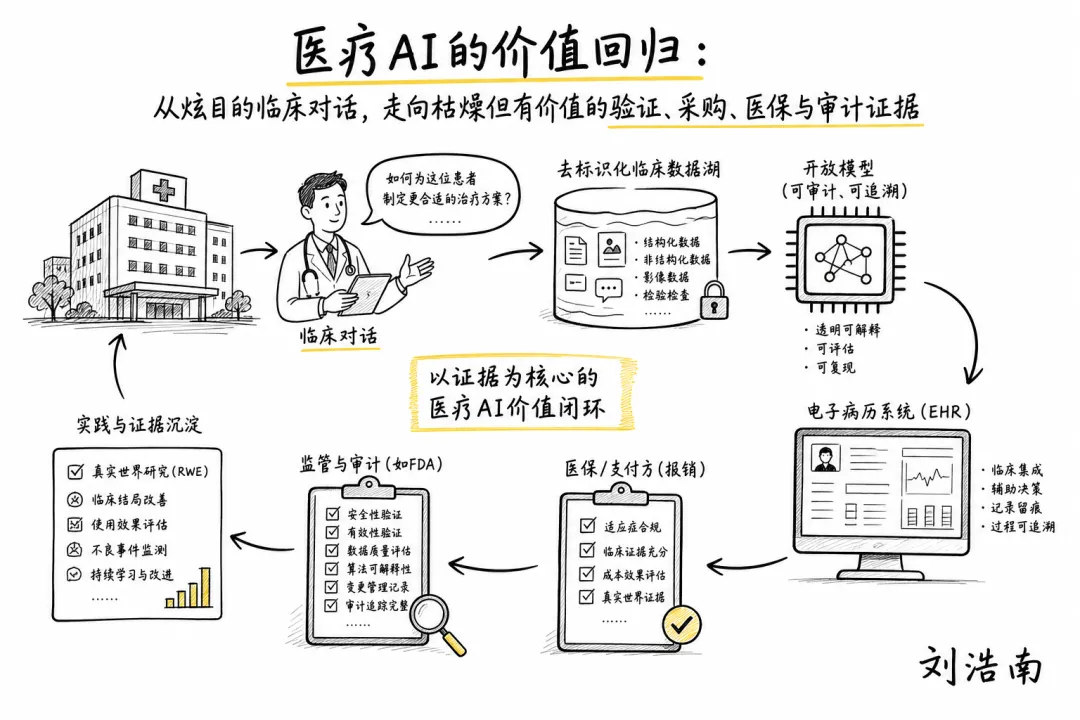
图注:本期手绘主线图,把临床对话、去标识化数据、院内验证、EHR(电子病历系统,医生每天真正使用的工作台)和采购审计连成一个闭环。
本期一句话: 临床对话、可穿戴数据和 AI 医疗器械正在被改造成可采购、可验证、可审计的医院基础设施。
本期速览
💡 新观点 1:大家以为 Abridge 与 NVIDIA 的重点是又训练一个医疗模型,其实更关键的是把真实临床对话沉淀成可控的专科模型层。
💡 新观点 2:大家以为 ambient scribe(环境式 AI 病历助手)只是少写病历,其实 Cleveland Clinic 的采纳数据说明,医院开始用“医生自愿使用率、患者同意、EHR 审阅”来检验 AI 是否真的能落地。
💡 新观点 3:大家以为 AI 医疗器械清单只是监管表格,其实 FDA 开始提到 foundation model(基础模型)标注后,医院采购会从“有没有 AI”追问到“用了哪类模型、会不会更新、谁来复核”。
本期精读产品清单:Abridge + NVIDIA 临床对话模型、Cleveland Clinic + Ambience ambient scribe、Oura Advisor + Counsel Health、An Empirical Study of Agent Skills for Healthcare、LLM-as-a-Judge in Healthcare、FDA AI-Enabled Medical Devices List、Aidoc 临床 AI 平台、Counsel Health AI+医生服务模式

本周医疗 AI 看点
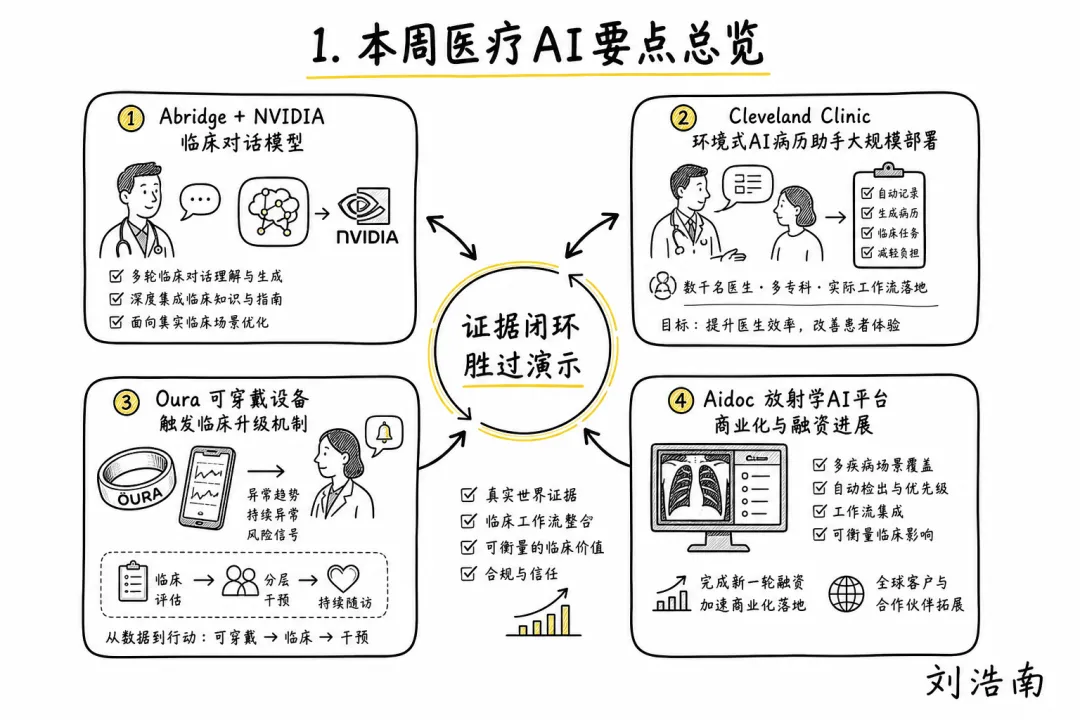
图注:本期手绘总览图,展示本期新看点如何围绕 EHR、医生审阅、患者同意和支付审计展开。
1.1 临床对话模型的价值,不在会聊天,而在能变成证据
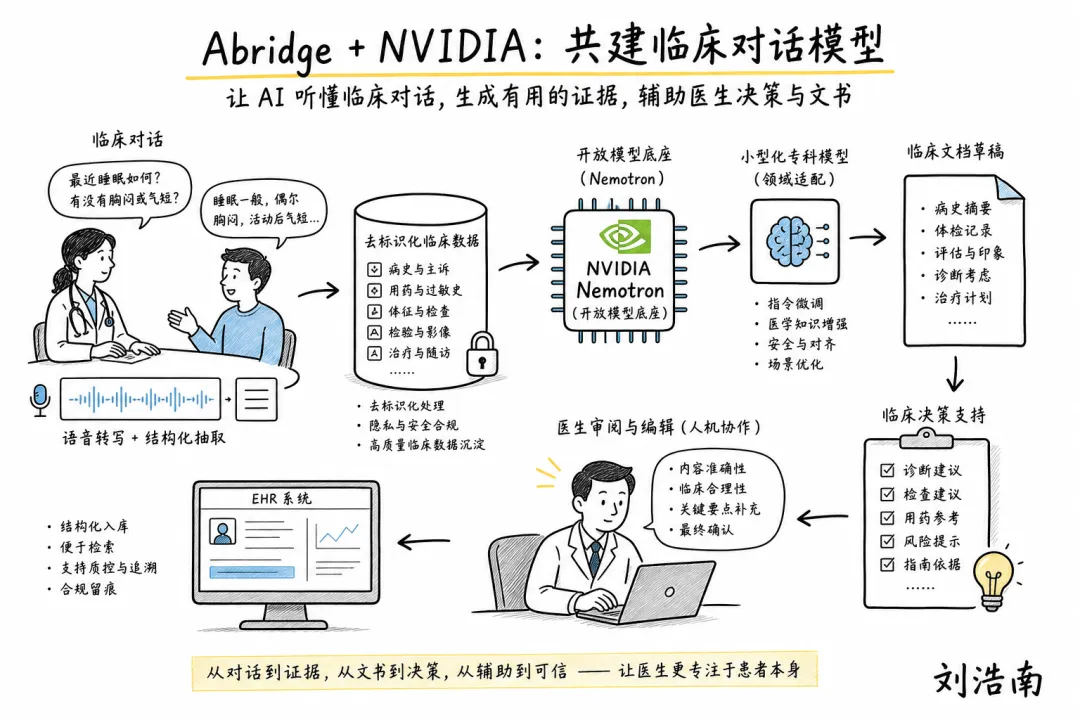
图注:根据 WSJ 披露、Abridge 产品信息与 NVIDIA Nemotron 方向整理的手绘解释图,展示临床对话如何经去标识化、专科训练、医生审阅后进入 EHR 和审计链路。
Abridge + NVIDIA 临床对话模型:Abridge 与 NVIDIA 的合作看起来像又一个“医疗大模型”故事,但真正的新意在于训练素材不是普通医学百科,而是 Abridge 平台积累的去标识化临床对话。模型计划基于 NVIDIA Nemotron(NVIDIA 的开放模型系列)定制,目标服务 Abridge 平台中的文书、临床决策支持和实时对话理解。
我的几个观点:
• 临床对话正在成为新的训练资产。 过去医疗模型的素材主要来自论文、指南和题库;Abridge 这类公司真正拿到的是医生和患者之间的真实表达、追问、犹豫、否认症状、用药细节和医生最后怎么落笔。这比“医学知识更多”更接近临床工作。
• 开放模型的商业意义不是免费,而是可控。 如果医疗公司能在自己的基础设施上定制小型专科模型,就可能降低推理成本、缩短延迟,并把模型行为锁在自己的安全策略里。对医院来说,这比把所有临床语音直接交给黑箱通用模型更容易被合规团队接受。
• 真实阻力会落在医生修改如何回流。 医生每天改 AI 草稿,如果这些修改不能被结构化记录,模型很难知道自己哪里错;但如果修改直接用于训练,又会碰到患者同意、数据最小化、HIPAA(美国健康隐私法)和模型版本审计问题。产品上必须把“可学习”和“可审计”同时设计出来。
值得借鉴的点:
• 做临床对话产品,不要只展示“听得准”,要展示医生改了什么、为什么改、修改是否会进入质量改进闭环。
• 面向医院销售时,可以把模型能力翻译成四个可采购指标:平均成稿时间、医生修改率、病历缺陷率、合规审计可追溯性。
• 如果采用开放模型底座,要提前说明模型部署位置、数据留存周期、是否用于再训练、出错后谁能回滚版本。
1.2 AI 病历助手的分水岭,是医生愿不愿意每天用
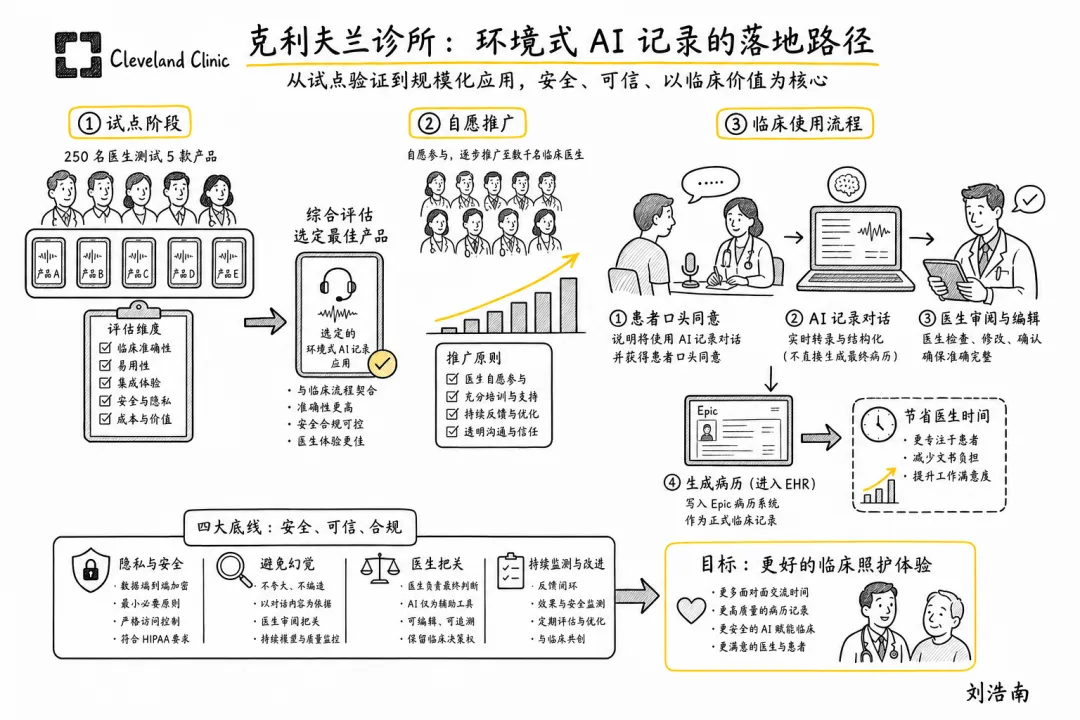
图注:根据 Business Insider 对 Cleveland Clinic 的报道整理的手绘解释图,展示从 250 名医生试点、5 款产品评估,到自愿使用、患者同意和 EHR 审阅的采纳路径。
Cleveland Clinic + Ambience ambient scribe:Business Insider 报道,Cleveland Clinic 曾让 250 名医生评估 5 款 ambient listening(环境式聆听)产品,最后选择 Ambience;推广后 15 周内约 4000 名临床人员自愿使用,到 2025 年 8 月记录和总结超过 100 万次患者就诊。这个案例的重点不是“AI scribe 又省时间”,而是它把医院内部采纳的关键变量暴露出来:医生不是被强制,而是愿意把它放进每天门诊。
我的几个观点:
• 医疗 AI 的真实 PMF(产品市场匹配)不是 demo 掌声,而是医生在没人强迫时继续用。 15 周 4000 名临床人员自愿使用,比“某模型医学考试高分”更接近商业落地信号。
• AI scribe 的下一轮竞争会从生成质量转向组织实施质量。 谁能把患者同意话术、录音留存、EHR 提交、医生签名、科室模板和错误反馈做细,谁才有机会跨科室扩张。
• 这里有一个反直觉:医生不一定拒绝 AI,医生拒绝的是把额外风险甩给自己。 如果 AI 草稿能让医生少打字、同时保留最终控制权,采纳阻力会小很多;如果系统让医生承担看不见的数据、隐私和幻觉风险,再强的模型也会卡住。
值得借鉴的点:
• 医院试点不要只问“准确率多少”,还要看每次就诊节省几分钟、医生使用频率、患者拒绝率、医生编辑比例。
• 临床产品上线时,把“暂停、删除、审阅、签名、追溯”做成一线用户可理解的按钮,而不是藏在合规文档里。
• 对创业公司来说,医生自愿使用率是比融资新闻更硬的指标。
1.3 可穿戴 AI 的新问题:健康建议什么时候该升级给医生
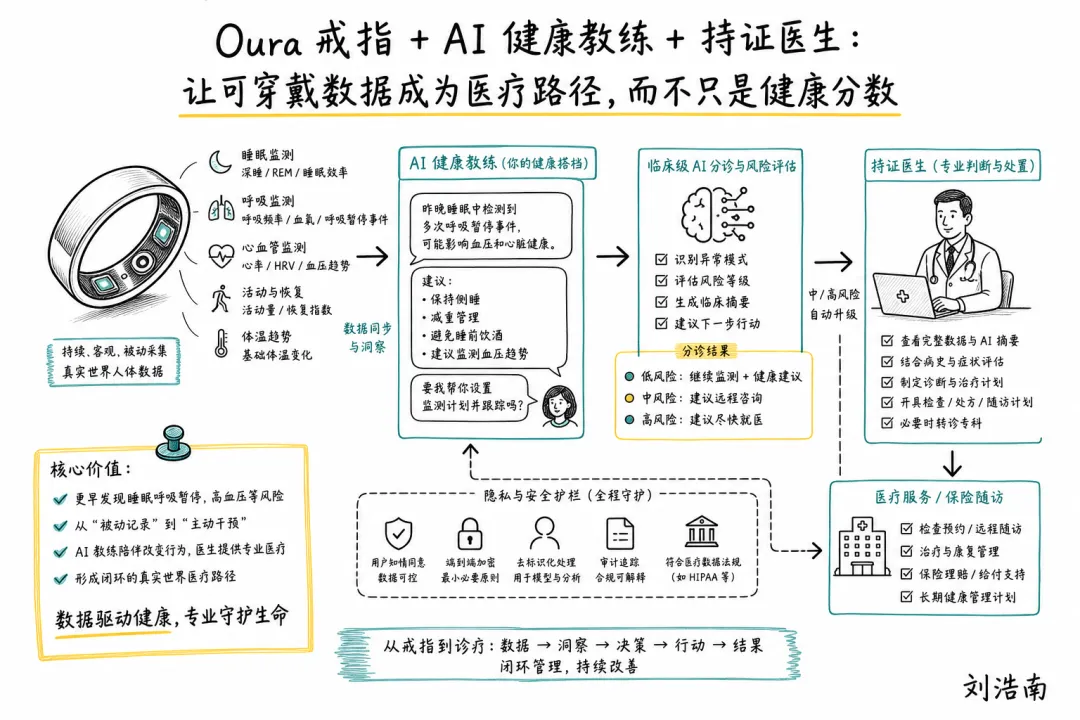
图注:根据 Oura Advisor、Counsel Health 和可穿戴健康设备趋势整理的手绘解释图,展示戒指数据、AI 健康建议、风险分诊、医生接入和医疗服务闭环。
Oura Advisor + Counsel Health:Oura Advisor 是 Oura 面向会员推出的 AI 健康伴侣,围绕睡眠、活动、恢复、压力等个人数据提供建议。Counsel Health 官网则把 AI 医疗问答、病历连接、医生加入对话、处方和实验室检查放在同一个服务路径里。两者不是一个联合产品,但放在一起看,指向同一个变化:可穿戴设备不再只输出“健康分数”,而是试图把连续数据推向医疗行动。
我的几个观点:
• 可穿戴 AI 的价值不在“更懂我”,而在“什么时候不应该继续只给建议”。 如果一个系统发现睡眠呼吸、心率、血压趋势异常,却不能把用户安全地导向医生或线下检查,它就仍然停留在 wellness(健康管理)层。
• 这里最难的是医疗责任边界。 AI 可以解释趋势,但不能把模糊风险包装成诊断;医生可以加入对话,但需要看到数据来源、采集质量、用户主诉和 AI 已经说过什么。否则医生接手时不是提高效率,而是在替前面的 AI 兜底。
• 业务上,消费者健康和医疗服务正在靠近。 订阅、按次医生咨询、雇主福利、保险导航可能会混在一起。下一轮竞争不是谁的戒指更小,而是谁能把连续数据变成可执行、可负责、可付费的医疗路径。
值得借鉴的点:
• 可穿戴产品要把“低风险建议、中风险远程咨询、高风险尽快就医”分层做清楚。
• 做 AI 健康助手时,不要只优化回答温柔度,要设计什么情况下必须停止回答并升级给真人。
• 医疗服务接入可穿戴数据时,要先解决数据可信度、患者授权和医生端信息过载。
这一节真正要看的是:医疗 AI 正在从“回答得像医生”转向“能不能安全进入医生每天工作的地方”。临床对话、环境式病历和可穿戴信号都只有在被同意、被审阅、被追溯之后,才可能变成医院愿意采购的能力。

新技术
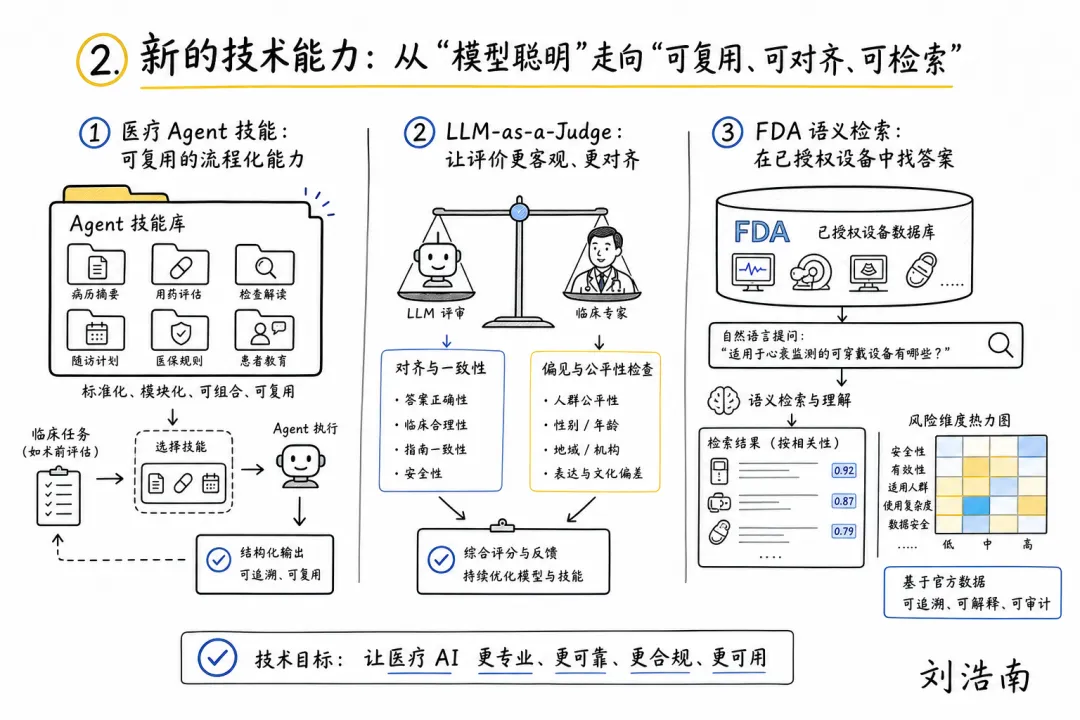
图注:本期手绘总览图,概括 Agent skills、LLM-as-a-Judge 和 FDA AI 医疗器械透明化三条技术变化。
2.1 医疗 Agent 的短板,不是工具少,而是缺少本地流程技能
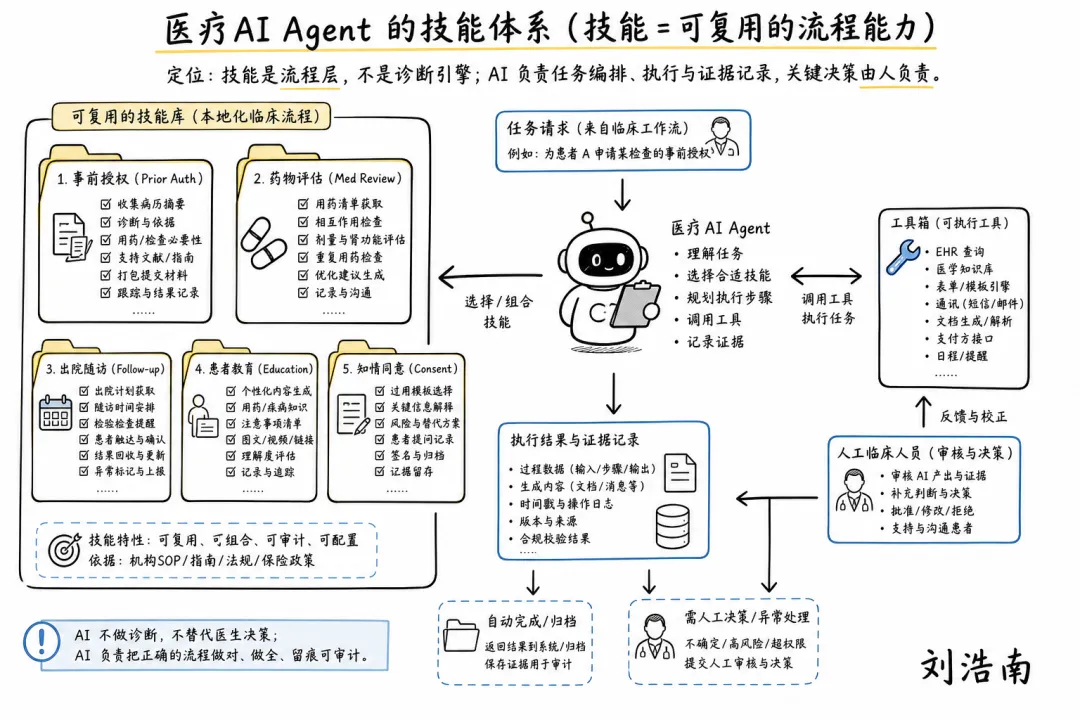
图注:根据 arXiv 论文 An Empirical Study of Agent Skills for Healthcare 整理的手绘解释图,展示医疗 Agent 如何调用可复用流程技能、保留证据槽位并升级给真人。
An Empirical Study of Agent Skills for Healthcare:这篇 2026 年 5 月发布的研究分析了 58159 个公开 skills 中筛选出的 557 个医疗相关 skills。作者把 agent skills(智能体技能,可复用的流程目录和操作说明)视为医疗 Agent 适配本地场景的中间层,而不是让模型靠一次提示词解决所有任务。
这类研究更适合作为“研发和治理趋势”的证据,而不是临床有效性证据:它能提示 Agent 应该如何组织流程,但不能证明某个具体医疗 Agent 已经可以安全替代人工执行。
我的几个观点:
• 医疗 Agent 的实用化会先发生在“本地流程技能”,不是泛用医生大脑。 预授权、随访提醒、检查前准备、出院后回访、慢病数据收集,这些任务医学难度不一定最高,但流程差异非常大。
• 技能目录可能成为医院自己的 AI 操作手册。 同一个 Agent 在 A 医院和 B 医院不能直接跑,是因为科室分工、EHR 字段、审批路径、患者教育材料、质控口径都不同。把这些做成可版本化的 skills,比单纯写 prompt 更接近工程化。
• 风险评估要从“模型是否危险”改成“任务链是否危险”。 一个看似简单的自动回复,如果误导患者延迟就医,就比一个封闭的医学知识问答更高风险。医疗 Agent 的风险不只在回答内容,也在它把人推向哪个下一步动作。
值得借鉴的点:
• 做 Agent 产品时,先从低风险、高摩擦、强规则的流程切入,而不是一上来做诊断建议。
• 每个 skill 都应带上输入要求、禁用条件、升级条件、日志字段和人工接管方式。
• 医院内部可以把优秀护士、个案管理师、编码员的 SOP 变成可审阅的 skills,而不是让 AI 自己猜流程。
2.2 用 LLM 评估医疗 LLM,正在从捷径变成治理问题
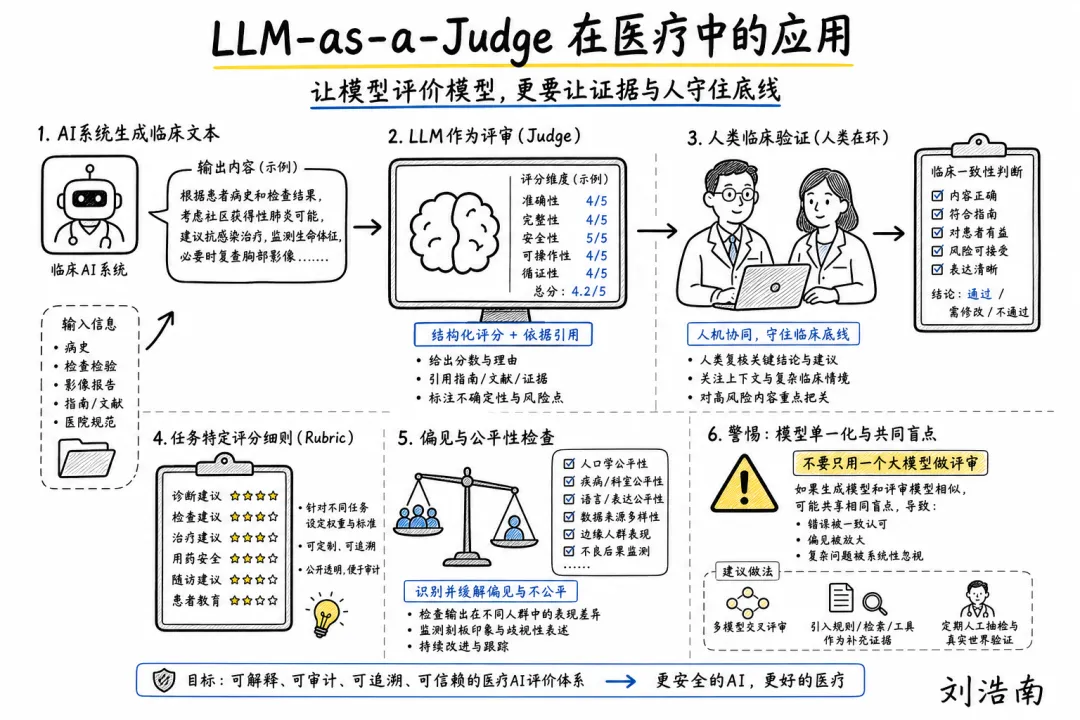
图注:根据两篇 LLM-as-a-Judge in Healthcare 综述整理的手绘解释图,展示 AI 评测、专家校准、偏倚检查和任务分层之间的关系。
LLM-as-a-Judge in Healthcare:LLM-as-a-Judge(让大模型充当评委来评估另一个模型输出)正在被用于临床文书、医学问答、诊疗推理和医学教育评测。2026 年两篇综述都把重点放在同一个问题:它能扩大评测规模,但在医疗场景里不能被当成专家审查的廉价替代品。
我的几个观点:
• 医疗 AI 评测最危险的捷径,是让一个模型给另一个模型背书。 这在研发阶段有用,但如果直接写进产品白皮书或采购材料,很容易把“自动评分”包装成“临床验证”。
• LLM-as-a-Judge 的正确位置应是分层筛查。 它可以先过滤明显差的输出、发现格式问题、追踪版本退化,但高风险结论仍要有人类专家、真实病例和任务后果来校准。
• 这会影响产品研发节奏。 过去团队可以每次模型升级后只跑内部 benchmark;未来医院会问:评委是谁、和被评模型是否同源、专家样本多少、是否测了偏倚、是否覆盖本院人群。医疗 AI 的评测会从“跑分”变成“评测体系是否可信”。
值得借鉴的点:
• 对外发布医疗 LLM 能力时,明确区分自动评测、专家评测、临床验证和真实世界使用数据。
•如果使用 LLM 评委,至少要设置人类抽检、任务分层、失败案例库和跨模型评委对照。
• 不要只追求平均分,要记录哪些人群、哪些病种、哪些表达方式容易被误判。
2.3 FDA 清单的新信号:未来采购会问“这个设备用了什么基础模型”
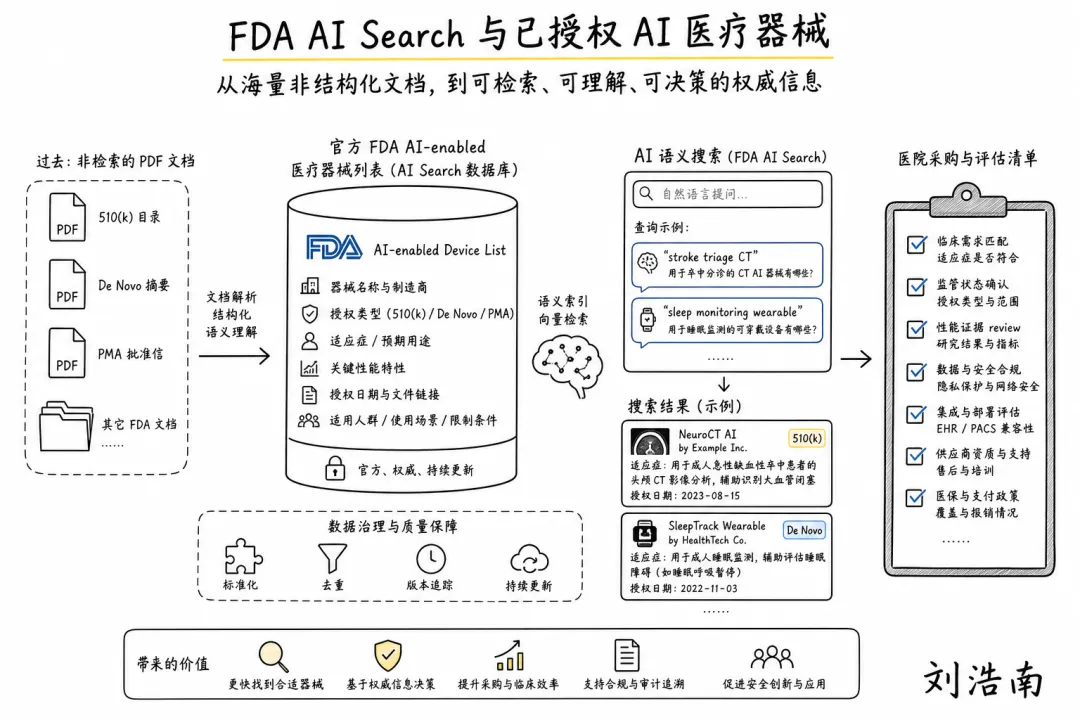
图注:根据 FDA AI-Enabled Medical Devices List 整理的手绘解释图,展示授权 AI 医疗器械、公开摘要、foundation model 标注和医院采购审查之间的关系。
FDA AI-Enabled Medical Devices List:FDA 的 AI-Enabled Medical Devices List(AI 医疗器械授权清单)本身不是新概念,但最新页面有一个值得关注的措辞:FDA 表示将探索识别和标注包含 foundation models 的医疗器械,范围从 LLM(大语言模型)到 multimodal architectures(多模态架构)。这意味着医院采购 AI 医疗器械时,问题会从“有没有 AI”,进一步变成“用了哪类模型、会不会更新、更新后谁来复核”。
我的几个观点:
• 医疗 AI 采购会越来越像“模型尽调”。 过去医院问的是适应证、准确率和注册证;未来还要问底座模型、训练数据、更新机制、PCCP(Predetermined Change Control Plan,预设变更控制计划)和输出可解释性。
• 这会倒逼厂商把 AI 结构写清楚。 如果一个影像、心电、病理或 EHR 插件用了 LLM 或多模态模型,不能只写“AI-powered”。医院信息科、医务部和合规团队需要知道它是否会生成文本、是否会随版本变化、是否可能跨任务输出。
• 对创业公司来说,透明度不是负担,而是进入医院采购的通行证。谁能把模型结构、适用边界、变更记录和失败处理讲清楚,谁更容易从试点走向规模采购。
值得借鉴的点:
• 产品说明书要提前准备模型来源、训练/验证数据边界、版本更新、人工复核和日志留存。
• 做多模态或 LLM 医疗器械时,不要等监管要求再补 foundation model 说明。
• 医院评估 AI 设备时,要把“模型是否会变”作为采购问题,而不是只看当前演示。
这一节真正要看的是:医疗 AI 技术正在从能力竞赛转向治理工程。Agent 要有本地技能,评测要能解释可信度,AI 医疗器械要暴露模型结构;这些都比单次性能提升更影响采购。

新模式
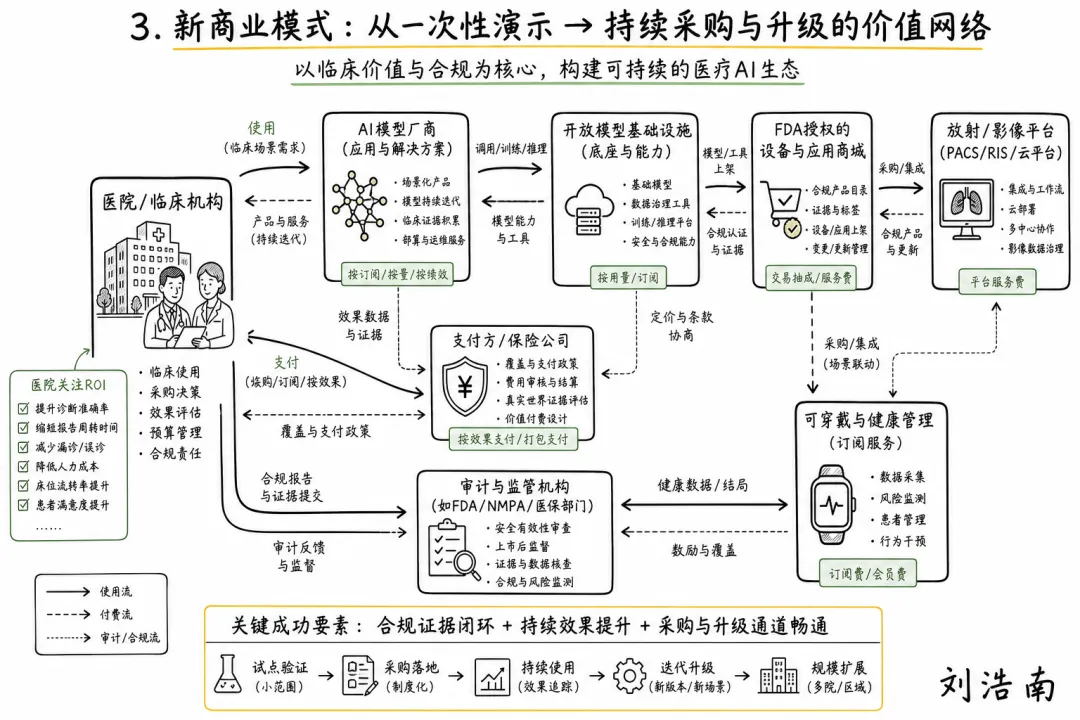
图注:本期手绘总览图,展示医院、厂商、算力平台、支付方、医生监督和 ROI 指标之间的商业闭环。
3.1 影像 AI 的商业化,开始从单点算法走向平台公司
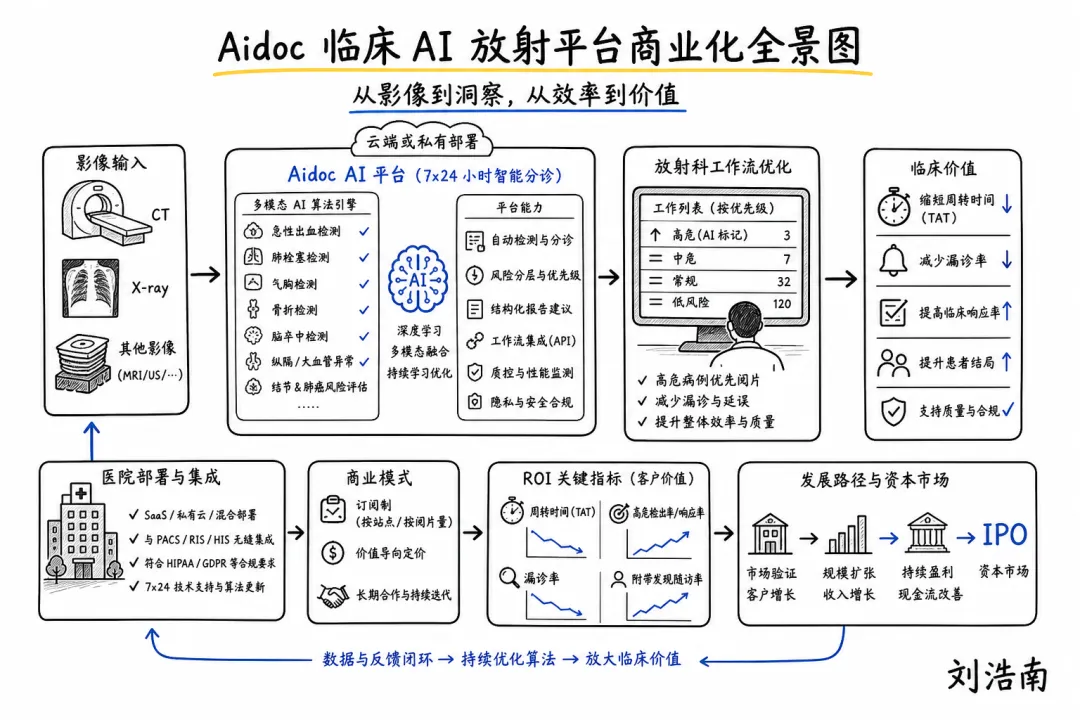
图注:根据 Axios 对 Aidoc 融资报道和 FDA 清单整理的手绘解释图,展示多算法、急诊分诊、医院部署、FDA cleared(获 FDA 许可)和 IPO 路径之间的关系。
Aidoc 临床 AI 平台:Axios 4 月披露,Aidoc 完成 1.5 亿美元 E 轮融资,投资方包括 Goldman Sachs Alternatives、General Catalyst、SoftBank Investment Advisors 和 NVIDIA 旗下 NVentures。这个融资本身不在本期窗口内,因此这里只把它作为平台化商业化的参照信号:结合本期 FDA 清单的采购透明化趋势看,影像 AI 至少在商业叙事上,正在从“卖一个算法”转向“卖一组可部署、可审计、可持续扩展的临床 AI 平台”。
我的几个观点:
• 影像 AI 可能最早走出“算法项目制”。 单个肺结节、脑出血、骨折模型很难支撑长期商业,但一个能接入 PACS/RIS(影像归档通信系统/放射信息系统)、覆盖多个急诊和常规场景的平台,才可能进入医院基础设施预算。
• 平台化也会带来新问题。 多个算法叠加后,谁管理告警优先级?谁处理假阳性?算法升级后历史结果是否可比?不同 FDA 许可适应证能否在同一个界面里清晰标注?这些都不是模型研发问题,而是临床运营问题。
• 采购指标会更偏运营。 医院会看 turnaround time(报告周转时间)、漏诊相关质量事件、急诊分诊速度、医生接受率、随访闭环,而不是只看论文 AUC(曲线下面积,常用性能指标)。
值得借鉴的点:
• 单点 AI 器械公司要尽早决定:做平台、接入平台,还是成为某个平台里的专科模块。
• 影像 AI 销售材料要少讲“我们模型更准”,多讲部署后哪类病例更快被处理、哪类漏项更容易被闭环。
• 医院采购时要要求厂商提供算法版本、适应症范围、告警阈值、人工复核和退出机制。
3.2 AI+医生服务的机会,不是替代医生,而是把医生放到正确时刻
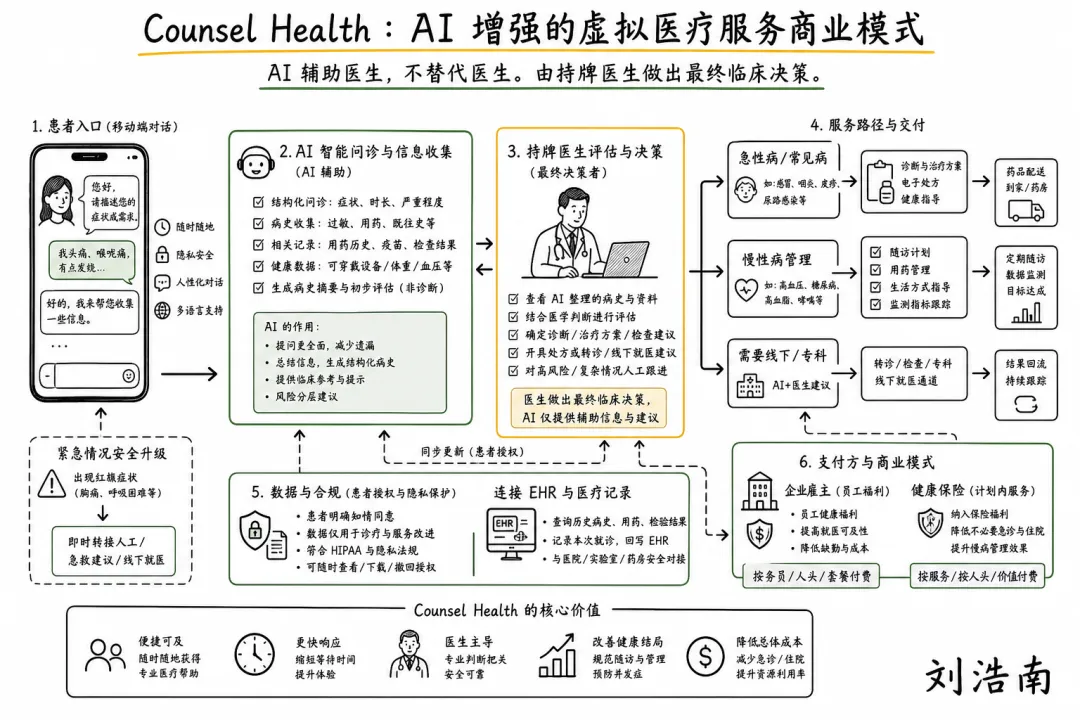
图注:根据 Counsel Health 官网整理的手绘解释图,展示患者先用 AI 收集问题和病史,再在需要治疗决策、处方或进一步评估时接入持证医生。
Counsel Health AI+医生服务模式:Counsel Health 的官网把产品说得很直白:用户可以先免费和 medical AI(医疗 AI)聊天,再用一次点击让医生加入对话;服务覆盖健康结果解读、可穿戴数据、用药、实验室检查、urgent care(急症/即时医疗)和雇主/健康计划合作。它值得看,不是因为 AI 能独立看病,而是因为它把 AI 放在“收集上下文、组织问题、持续记录”的前台,把医生放在需要判断和处置的节点。
我的几个观点:
• AI 医疗服务最现实的商业模式,可能不是“AI 医生”,而是“更便宜、更快把医生放到该出现的位置”。 用户最痛的往往不是没有医学知识,而是不知道该不该看医生、看哪个科、需要带什么信息、能不能续方或做化验。
• 雇主和健康计划会关心节省,而不是聊天体验。 如果 AI+医生模式能减少不必要急诊、缩短问题解决时间、提高慢病随访连续性、把员工导向合适资源,它才有可能进入企业福利或支付方采购。
• 最大风险是边界滑坡。 当 AI 回答越来越像医生,用户可能把它当成诊断;当医生加入太晚,风险已经发生;当医生加入太频繁,成本优势又消失。真正的产品能力是升级规则,而不是回答更像人。
值得借鉴的点:
• 做 AI+医生服务,要把“哪些情况必须转真人”写成产品逻辑,而不是客服话术。
• 医生端必须看到 AI 已经收集的信息、用户确认过的事实、未确认的推测和风险提示。
• 面向雇主和支付方,ROI 应该围绕响应时间、问题解决率、转诊合适率、线下资源使用和会员满意度。
这一节真正要看的是:医疗 AI 的商业化正在向“平台化”和“混合服务”两头分化。前者解决医院如何采购一组可审计算法,后者解决消费者什么时候需要真人医生。中间共同的难点,都是责任边界和可衡量结果。

风险与直觉
• 不要把“医生审阅”当成万能免责。 医生如果只是最后点确认,但看不到 AI 的依据、版本、置信边界和已省略信息,审阅会变成形式责任。医疗 AI 产品必须让医生真正能发现错误。
• 不要把“去标识化”当成可以随便训练。 临床对话里有大量可再识别线索、罕见病史和时间地点信息。越接近真实对话,越要认真设计同意、最小化和留存周期。
• 不要把“FDA 清单里有 AI”理解成所有 AI 功能都同等成熟。 清单覆盖的是获授权医疗器械,不等于所有医疗 AI 软件,也不代表每个功能都已经在真实世界证明 ROI。
• 不要把 LLM 评委的高一致性当作临床有效性。 一致性可能来自共同盲点。高风险医疗任务仍需要专家、真实病例、失败案例和上线后监测。

你怎么看?
如果你正在做医疗 AI 产品,今天最该复盘的不是“模型能不能再强一点”,而是:你们的产品里,哪一个关键输出已经能被医生复核、被医院审计、被采购部门解释、被支付方或管理层衡量?
这个问题很具体,也很残酷。因为医疗 AI 从 demo 到真实落地,最后总会回到同一张表:谁使用、谁负责、谁付费、谁验证、谁在出错时能追溯。
你现在接触的医疗 AI 项目里,最缺的是临床数据闭环、医生审阅机制、合规审计材料,还是能说服采购的 ROI 指标?

本期参考信息来源
临床对话模型与 AI scribe
• The Wall Street Journal|Nvidia Is Developing an AI Healthcare Model With Startup Abridge
• Abridge
• NVIDIA Nemotron
• Business Insider|Cleveland Clinic's chief digital officer says its AI scribe is giving some doctors 'joy' again
• Ambience Healthcare
可穿戴、AI+医生服务与消费者健康
• Oura|Introducing Oura Advisor
• Counsel Health
• MarketWatch|The latest Oura and Fitbit wearables are smarter and sleeker than ever
Agent、评测与监管
• arXiv|An Empirical Study of Agent Skills for Healthcare
• arXiv|LLM-as-a-Judge in Healthcare: A Scoping Analysis
• arXiv|A Scoping Review of LLM-as-a-Judge in Healthcare and the MedJUDGE Framework
• FDA|Artificial Intelligence-Enabled Medical Devices
商业化与平台化
• Axios|Clinical AI provider Aidoc raises $150M Series E

刘浩南丨医疗AI实战派
关注医疗 AI 从 demo 到真实落地,聚焦产品化、商业化与院内工作流效率提升,让医生把更多时间留给诊疗本身
12年医疗产研经验
大湾区头部医疗AI公司前产品总监
独立开发者
感谢关注,我在大湾区,下期见
