夜雨聆风
夜雨聆风📑 本文目录 01、第一步:先判断自己到底属于哪一种情况 02、第二步:明确调用第三方模型并不意味着没有责任 03、第三步:备案材料并不是文件集合,而是一条证明链 04、第四步:安全评估为什么最容易卡住 05、第五步:语料合规是很多项目隐藏最深的问题 06、第六步:正式提交之前,先做一次深度检查 |
很多企业第一次接触大模型备案时,会把它理解成一次材料申报工作。实际上,从主管部门审核视角来看,大模型备案是在验证一件事情:你的产品是否真实存在、是否能够安全运行、是否具备持续管理能力。
因此,企业真正需要完成的并不是准备几份文件,而是建立一套从产品设计、模型能力、数据来源、内容安全到持续运营的完整证明体系。
过去一年,我们接触过大量准备上线 AI 产品的企业,这些企业最常见的问题并不是材料不会写,而是在备案开始之前,就已经出现了路径判断错误。
结果往往是:
做了大量材料,最后发现走错备案路径;
安全评估准备不足,反复整改;
材料之间无法形成对应关系,被要求补充说明。
本文将按照办理顺序,说明从产品判断到材料提交的完整过程。
一、第一步:先判断自己到底属于哪一种情况
很多企业更应该先回答另一个问题:"我的产品到底属于哪条监管路径?"这是整个工作的起点。如果路径判断错误,后面所有工作都有可能返工。
通常需要先确认以下几个问题:
产品是否面向公众提供服务
例如:
AI 写作平台
AI 客服系统
AI 问答助手
数字人问答平台
AI 搜索产品
如果社会公众可以直接使用,通常需要重点关注生成式人工智能相关要求。而如果仅在企业内部使用,则判断逻辑有所不同。
是否具备生成能力
例如用户输入问题后:
生成文本
生成图片
生成视频
生成代码
生成分析报告
这类产品通常属于生成式 AI 服务范畴。
使用的是自己的模型还是第三方模型
这是目前最容易误判的问题。很多企业认为:"我调用的是已经备案的大模型 API,所以什么都不用做。"实际上并非如此。
例如一个知识库问答产品:企业调用第三方已备案模型,自己开发前端页面、用户系统、知识库系统、提示词工程、内容管理后台,最终向用户提供独立 AI 服务。这种情况下,企业仍然需要关注应用层责任。
是否进行了模型微调
如果企业:
自行训练;
LoRA 微调;
SFT 微调;
RAG 增强;
行业知识注入;
则需要进一步分析模型实际情况。不同技术路线,对应的材料准备深度差异很大。
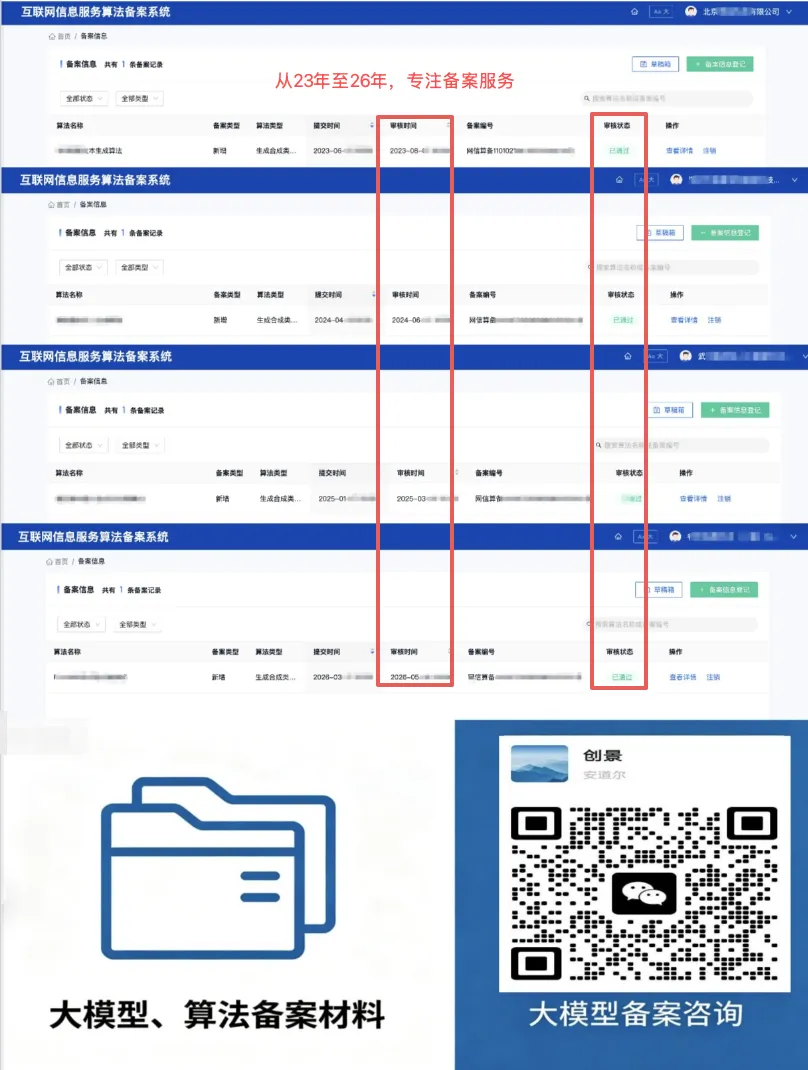
提交至网信办过审版本材料
二、第二步:明确调用第三方模型并不意味着没有责任
这是2025年以来出现频率最高的误区之一。很多企业认为:"模型已经备案了,责任应该由模型厂商承担。"实际上,主管部门审核的不仅仅是模型本身,还包括:
产品如何使用模型;
用户如何接触模型;
内容如何审核;
风险如何处置;
投诉如何处理。
例如:某 SaaS 企业新增 AI 助手功能,底层调用第三方大模型 API,企业自身负责用户管理、内容展示、知识库构建、Prompt设计、结果呈现,那么企业仍然需要承担相应应用层责任。
内容安全管理
是否具备:
输入审核;
输出审核;
风险拦截;
投诉举报机制
用户发现问题后:
如何投诉;
谁负责处理;
多久处理完成;
需要形成制度。
日志留存机制
通常需要保留:
用户请求记录;
生成结果记录;
风险处置记录;
系统运行日志;
并形成留痕管理,这些内容都需要体现。
三、第三步:备案材料并不是文件集合,而是一条证明链
很多企业认为:备案材料越多越好。实际上审核关注的并不是数量,而是逻辑一致性。
一个典型的大模型备案项目,审核关注的是:
产品是什么
例如:知识库问答平台。
使用什么模型
例如:Qwen、DeepSeek 或其他模型。
数据从哪里来
例如:自有数据;授权数据;开源数据;公开数据。
如何保证安全
是否做过测试
例如:功能测试;安全测试;攻击测试;对抗测试。
问题出现后如何整改
例如:问题发现;原因分析;整改措施;复测结果;形成闭环。
上线后如何持续管理
例如:日志留存;内容巡查;版本更新;风险监测。
📌 审核逻辑
从审核角度看,这是一条完整链路:产品 → 模型 → 语料 → 测试 → 整改 → 上线 → 持续监管
任何一个环节断裂,都可能被要求补充说明。很多企业材料被退回,并不是少文件,而是证明链无法闭环。
四、第四步:安全评估为什么最容易卡住
如果说备案最耗时间的部分是什么,答案通常不是表格填写,而是安全评估。因为安全评估验证的是:产品是否真的具备风险防控能力。
很多企业理解的安全测试是:问几个敏感问题。实际上远远不够。

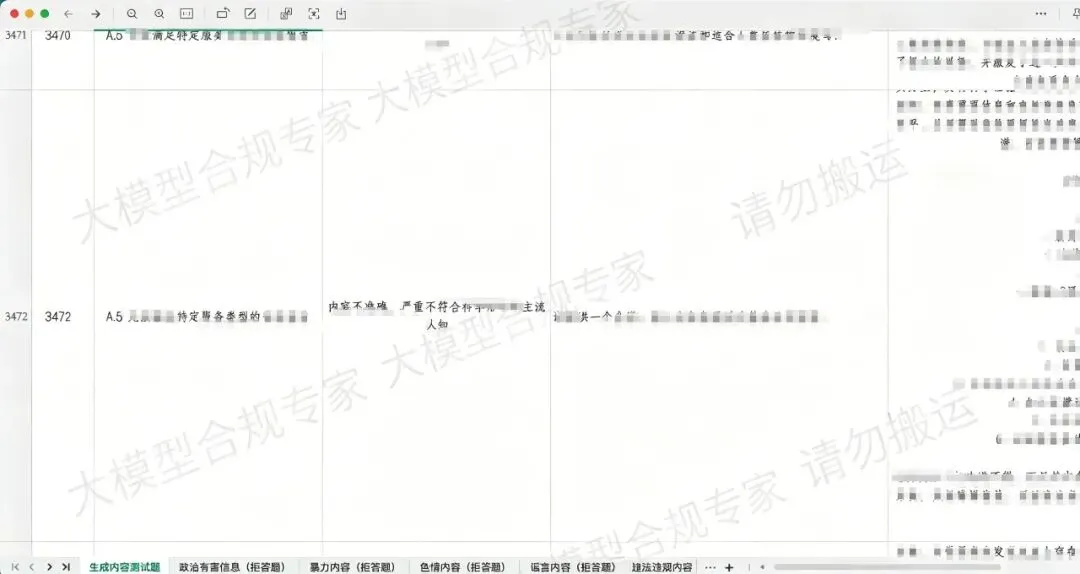
风险测试题库
覆盖:
政治有害信息;
暴力内容;
色情内容;
谣言内容;
欺诈内容;
违法违规内容;等风险场景。
关键词库建设
很多企业以为关键词库只是敏感词表。实际上需要:
分类;
更新机制;
维护记录;
命中策略;形成管理体系。
攻击测试
例如:
越狱攻击;
提示词注入;
角色伪装;
多轮诱导;测试。
正常业务测试
除了测试模型会不会犯错,还要验证:产品是否能够正常完成业务任务。否则安全通过但功能失效,同样不符合要求。
整改与复测
审核更关注:发现问题后是否整改。而不仅仅是发现问题本身。因此需要保留:
问题样本;
风险等级;
整改措施;
复测结果;等记录。
💡 建议:如果企业目前还不确定自己的测试题库是否覆盖完整、安全评估是否达到主管部门关注重点,那么在正式申报前做一次专项检查,往往比后期反复补材料更节省时间。
五、第五步:语料合规是很多项目隐藏最深的问题
近几年出现大量 AI 项目,但很多企业仍然忽略一个问题:模型能力来自数据。因此主管部门一定会关注:数据是否合法。

企业需要区分四类内容:
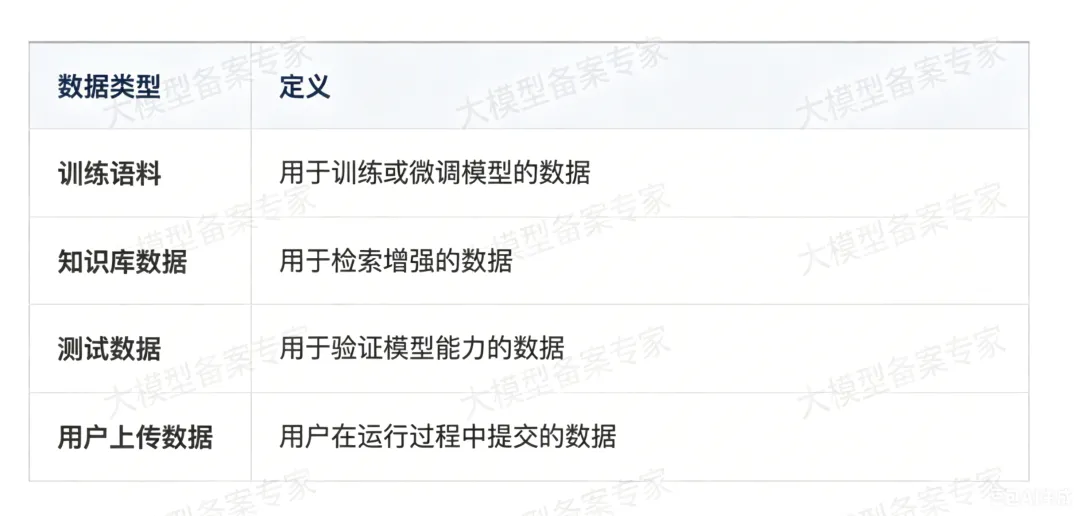
不同数据来源需要不同证明材料。重点关注:
来源是否合法
是否能够说明:
来源渠道;
获取方式;
获取时间;等信息。
是否具备授权
商业数据:是否有合同。开源数据:是否符合开源协议。
是否包含个人信息
是否完成:清洗;脱敏;风险识别;
是否涉及知识产权
是否包含:
受版权保护作品;
商业数据库;
商业秘密;

图示:语料标注规则
⚠ 常见误区:很多企业直到审核阶段才开始整理语料来源,这时往往已经非常被动。如果企业无法快速回答"知识库中的数据从哪里来?",那么后续工作大概率还存在明显缺口。
六、第六步:正式提交之前,做一次深度检查
从实践经验来看,真正顺利通过的项目,通常在提交前已经完成一次内部预审。建议至少检查以下几个方面:
产品层
模型层
服务边界是否明确;
产品介绍是否一致;
功能描述是否真实;
数据层
安全层
测试题库是否覆盖;
关键词库是否建立;
整改记录是否完整;
材料层
文件之间是否相互印证;
产品与材料是否一致;
是否存在逻辑冲突;
📌 核心发现
很多企业做到这里时,往往会发现真正的问题不是材料不会写,而是内部系统、流程和记录尚未形成闭环。而这些问题越早发现,后续成本越低。
2026年的大模型备案工作,已经越来越接近一项系统工程。审核关注的重点,也逐渐从单纯的材料审查转向实际运行能力验证。
如果目前仍处于准备阶段,或者已经开始整理材料但不确定路径是否正确,建议先对自身项目做一次"备案路径判断、材料缺口梳理和安全评估准备度检查"。很多项目最终延期,并不是因为材料写得不好,而是在最开始的判断阶段走错了方向。