 夜雨聆风
夜雨聆风

文章概览
文章字数:约 2800 字 预计阅读时间:约 7 分钟 内容摘要:自媒体创作者和知识工作者在抖音上刷到优质内容,往往收藏即吃灰。本文介绍 obsidian-content-capture-backend,一套完全本地的抖音内容提取流水线,配合 Obsidian 插件实现从分享链接解析、无水印下载、Whisper 本地语音转写到结构化笔记生成的全流程。全文覆盖项目架构、Web/CLI/API 三种使用方式、Whisper 模型选型建议及 Obsidian 插件集成说明。帮助读者判断这套方案能否成为自己的内容采集基础设施。
[💬] 说实话,我做自媒体这两年,最头疼的问题一直不是「写不出东西」,而是「素材找不到在哪」。
抖音里刷到一条讲 AI 工具的好内容,脑子一热点了收藏。隔两周要写相关选题了,翻半个小时收藏夹,愣是找不到那条视频。或者更气人的——找到了,但视频太长不想重看,又没文案可以快速扫。
[📝] 我之前试过手动截屏文字转存,试过复制粘贴到备忘录,试过在线解析网站。都不行。截屏没法搜索,备忘录越堆越乱,在线网站三天两头挂。
后来我换了个思路:不收藏平台里的内容,只搬自己本地的东西。 短链接复制 → 后端自动解析下载 → Whisper 转写 → Obsidian 结构化归档。一条链路走到底,内容变成 Vault 里的一条笔记。
这个链路,从一个开源项目说起。
抖音真正缺的不是内容,是沉淀机制
Obsidian 用户都知道一句话:东西搬进 Vault,才算你的。
能搬进 Vault 的东西有不少:网页用 Markdownload 剪藏,微信文章用简悦存,PDF 标注也能导入。但抖音不行。
抖音不给你批量导出,不给你文案下载,你存下来的只是收藏夹里的一个链接——本质上跟存了个书签没区别。
[💬] 说白了,现在 Obsidian 的输入链条里,缺了国内最大短视频内容池这一环。这个缺口今天聊的项目,刚好能补上。
obsidian-content-capture-backend 是什么
先贴项目基本信息——来自 GitHub 用户 lyxdream,本周刚发布,还在活跃迭代中:
一句话说清楚定位:输入一条抖音分享链接,输出一个结构完整的内容文件夹。
它解决了几个关键问题
最关键的是:不需要抖音 Cookie,不需要硅基流动等付费语音 API,没有任何云端依赖。
视频和图文两种处理流程
视频作品的流水线:
分享链接 → 解析 SSR 数据 → CDN 下载无水印视频 →
FFmpeg 抽 16kHz 音频 → faster-whisper 转写 →
zhconv 繁体转简体 → 完整输出到独立文件夹
输出结构:
output/{作品ID}_{标题}/
├── video.mp4 # 无水印视频
├── audio.wav # 提取的音频
├── transcript.txt # 简体文案,带元数据头
├── transcript_segments.json # 分段时间戳
├── download_url.txt # 下载链接记录
└── meta.json # 作品元数据
图文作品的流水线更简单——不需要抽音频和转写,直接从分享页拿 desc 配文,批量下载配图,几秒完成:
output/{作品ID}_{标题}/
├── images/01.jpg … # 全部配图
├── image_urls.txt
├── transcript.txt # desc 配文
└── meta.json
Github 仓库的提交记录也能看出项目迭代方向:
d53924f | ||
3cb6b32 | ||
ef02783 | ||
3fd175f |
最后那次「仅下载视频跳过转写」的更新很实用——有时候你只想先把视频扒下来存着,文案后面再说。
三种使用方式,总有一种适合你
方式一:Web 界面(推荐入门)
git clone https://github.com/lyxdream/obsidian-content-capture-backend.git
cd obsidian-content-capture-backend
python3 -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install -r requirements.txt
python web/app.py
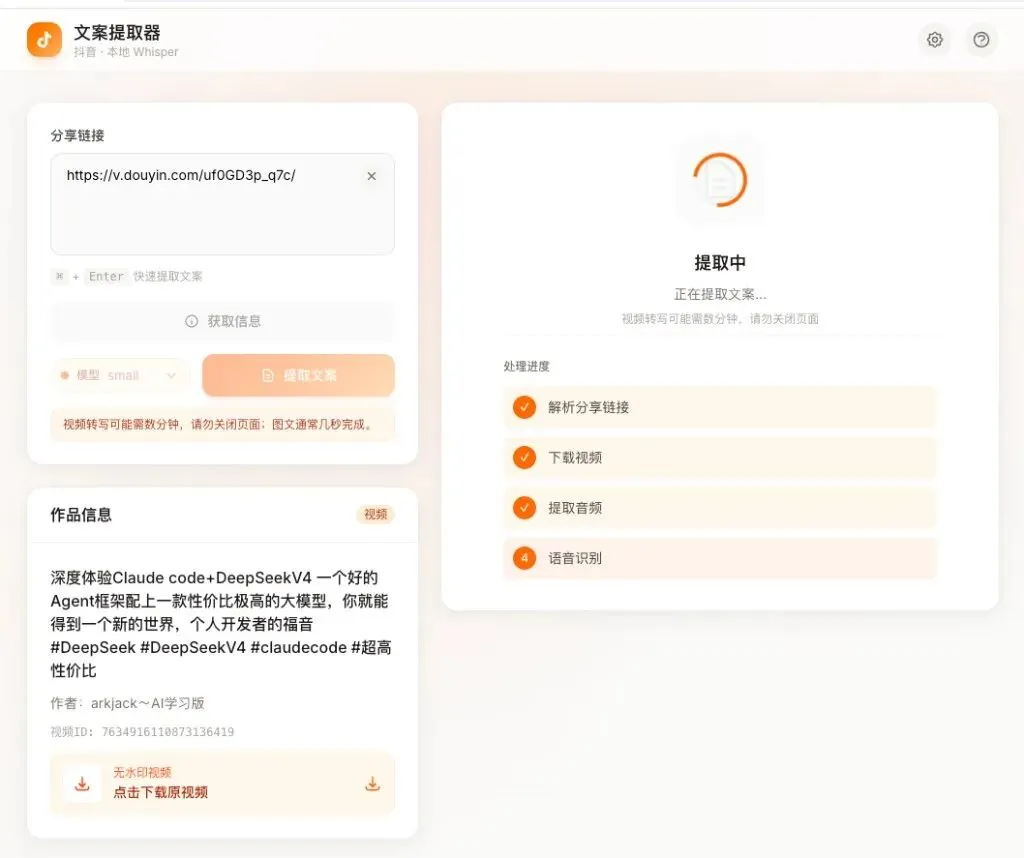
浏览器打开 http://127.0.0.1:5050,界面分几个区域:
支持 ⌘ + Enter(Windows:Ctrl + Enter)快捷提交。端口被占用了?PORT=8080 python web/app.py。
[📝] 我自己的习惯是先用 Web 界面跑通一次,确认链接能解析、转写正常,再考虑上插件。
方式二:命令行
适合批量操作或不想开浏览器的场景:
# 视频
python main.py "https://v.douyin.com/xxxxx/"
# 图文
python main.py "https://www.douyin.com/note/7640701464617132402"
# 整段分享文案(内含短链即可)
python main.py "7.48 复制打开抖音… https://v.douyin.com/xxxxx/ …"
# 交互模式(无参数时从 stdin 读)
python main.py
# 指定 Whisper 模型
python main.py --model base "https://v.douyin.com/xxxxx/"
可选参数还有 --output、--device、--compute-type,跑 python -m script --help 看全量。
方式三:HTTP API(供开发者集成)
GET | /api/health | |
POST | /api/video/info | |
POST | /api/video/extract | |
GET | /api/video/download | |
GET | /files/<path> |
代码里调用示例:
from script.config import Settings
from script.pipeline import process_douyin_share
out_dir = process_douyin_share(
"https://v.douyin.com/xxxxx/",
settings=Settings(whisper_model="small"),
)
跟 Obsidian 插件配合,效果翻倍
这是最值得讲的部分。
项目作者同步开发了配套插件 **obsidian-douyin-capture**,已上架 Obsidian 社区插件市场,在obsidian第三方插件市场里搜索Douyin Capture,然后安装并启用即可。插件本身不做任何抖音解析——它只负责调用后端 API,把结果搬进 Vault,生成结构化 Markdown 笔记。
架构非常清晰:
Obsidian 插件 → HTTP POST (localhost:5050) → Python 后端
(解析/下载/Whisper/返回结果)
↓
插件把 media 复制进 Vault + 写 .md 笔记
插件的核心能力
![[video]] 嵌入 | |
怎么用
侧边栏:点击左侧 Ribbon 的摄像机图标 → 弹窗中粘贴链接 → 选「提取文案」或「提取视频」。
命令面板:
Douyin Capture: 从抖音链接创建笔记— 打开导入弹窗Douyin Capture: 从剪贴板创建笔记— 读完剪贴板直接跑提取Douyin Capture: 检查后端连接— 测试服务是否运行
生成的笔记结构
路径:Douyin/{日期}-{作者}-{标题关键词}.md
笔记正文:
一级标题(与 #话题自动分离)话题标签引用块 ![[video.mp4]]视频嵌入(可关闭)## 文案正文区域Frontmatter:type、content_type、douyin_id、author、source、tags
插件设置项
http://127.0.0.1:5050 | python web/app.py 一致 | |
页面顶部还会显示后端连接状态(● 已连接 / ● 未连接),不用猜服务挂了没。
[💬] 坦白讲,插件这个连接状态提示是贴心设计——之前用其他本地工具,最怕的就是服务崩了还不知道,在那傻等。
Whisper 模型怎么选
faster-whisper 有多个模型可选,直接给结论:
模型越大,内存占用越高。large-v3 在 CPU 上跑约需 6GB 内存。
适合谁,不适合谁
✅ 推荐给:
自媒体创作者:需要拆解抖音爆款文案做素材库 Obsidian 知识管理者:补齐抖音这个输入渠道的缺口 教程/课程制作者:批量收集行业案例 对数据隐私敏感的人:所有处理本地完成
❌ 不太适合:
需要批量高速采集(目前无队列机制,单次处理) 图文题本在图片里(项目不做 OCR,只提取 desc 配文) 只用手机(插件仅支持桌面版 Obsidian) 完全不想碰命令行(虽然 Web 界面够用,但安装阶段还是需要终端的)
几个注意事项
从 GitHub Issues 和 README 的 FAQ 部分整理几个常见问题:
解析失败:检查链接格式, note/video页面需能被解析为iesdouyin.com/share/...格式视频很慢:CPU + small 模型下正常;长视频可改为 base 或 tiny 加速 CPU 上 float16 → float32:ctranslate2 自动降级提示,可忽略 Web 长时间无响应:同步处理中,转写完成前页面不会刷新 配图无文字:题本在图片里就在图片里,当前不做 OCR
[💬] 说句实在的,最后一条的 OCR 支持如果后面能加上,这工具的实用性会再上一个台阶。毕竟很多抖音精华内容是以文字卡片形式存在的。
总结
obsidian-content-capture-backend 不是什么大项目——6 个 Star,刚起步一周。
但它的切入点特别好:把抖音接入 Obsidian 知识库体系。
复制链接 → 自动解析 → 无水印下载 → 本地 Whisper 转写 → 结构化笔记。这些现在用这套工具链都能走通。不需要付费 API,不需要 Cookie,不需要上传任何数据到云端。
收藏不是拥有。能随时搜索、引用、二次加工,才算你的。
你不妨想想:过去三个月刷到的优质内容,如果每一条都这样沉淀到 Vault 里了,你现在的内容资产有多厚?
剩下的,交给工具。
参考资料
obsidian-content-capture-backend(GitHub 仓库) — https://github.com/lyxdream/obsidian-content-capture-backend obsidian-douyin-capture(配套 Obsidian 插件) — https://github.com/lyxdream/obsidian-douyin-capture
