 夜雨聆风
夜雨聆风你要是现在还在手动 grep 日志、一台台 SSH 巡检、半夜被告警薅起来——倒不一定半年后就会被裁,但你一定会后悔没早点让 AI 替你干这些活。
2026 年 6 月,AI 终端工具从去年的 3 个暴增到 7 个以上。Claude Code 更新到 2.1.x,DeepSeek V4 开放 API,Gemini CLI 免费可用。但扎心的是:绝大多数运维工程师只用它们写代码。
我指的就是那种一天跑几十次 claude 「帮我写个 Python 脚本」 的用法。可你真正该交给 AI 的事——告警排查、日志分析、自动修复、MCP 工具编排——它们从今年 4 月开始就已经能干了。
下面是我实测了 4 个生产场景之后,整理出来的运维人现在就该让 AI 接手的 4 件事。所有命令和代码都来自官方文档,可以直接复制跑。
一、2026 年 AI 终端工具格局:一张表就看明白
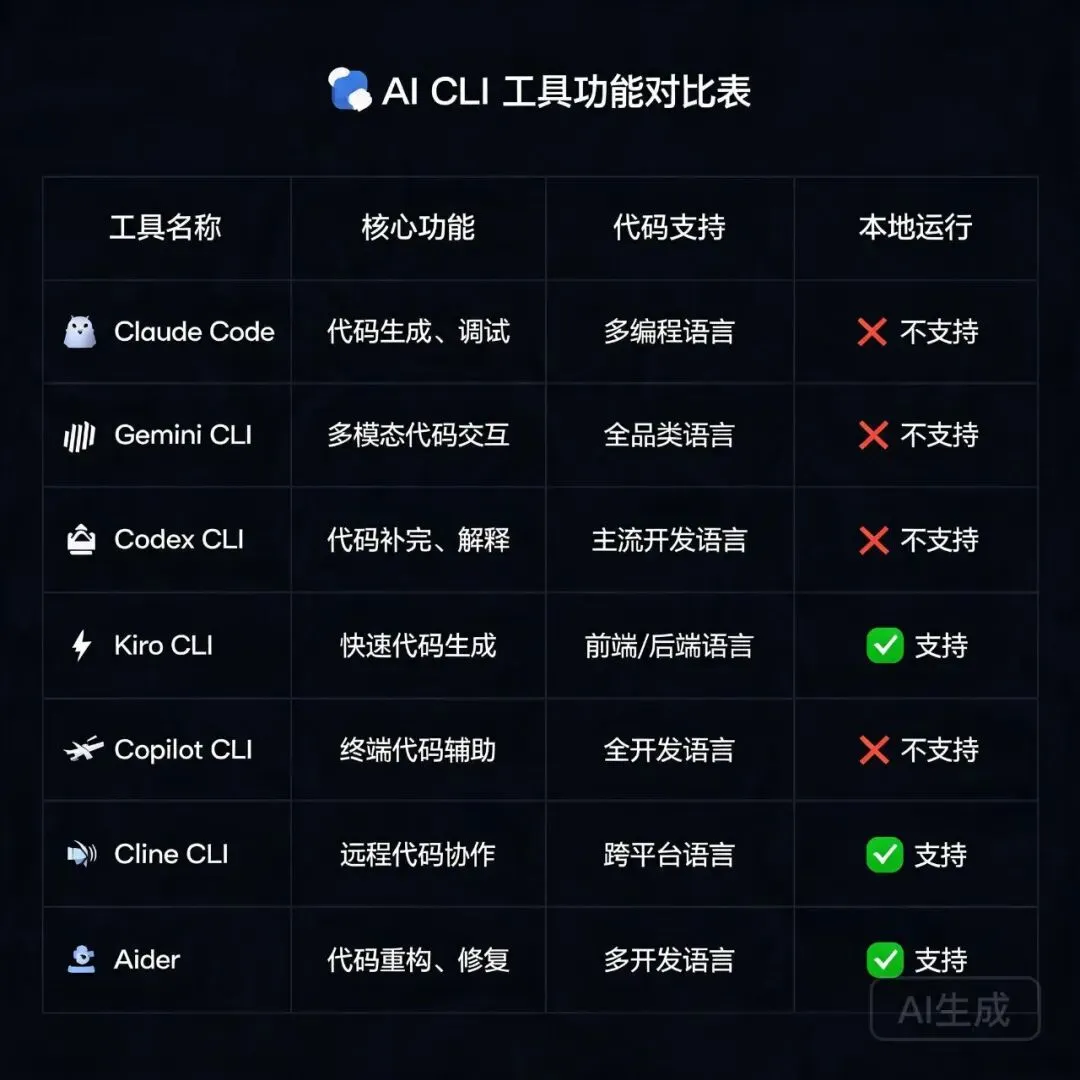
2026 年 7 款主流 AI 终端 CLI 工具功能对比表
动手之前,先把局面理一理。这是 2026 年 6 月主流的 AI CLI 工具实测对比:
数据来源:CodePick 2026 年 3 月终端 AI 编程工具横评(核实过各工具官方定价页)
如果你只想挑一个,我的建议是 Claude Code + DeepSeek V4 API 这条组合:Claude Code 是 MCP 生态最成熟、Agent 能力最硬的 CLI 工具;DeepSeek V4 是眼下性价比最高的 API 模型(Flash 版输入才 1 元/百万 tokens)。
不过这个表不是今天的重点。重点是你怎么用它们干运维的活儿。我们直接看代码。
二、场景 1:告警自动排查——让 AI 替你半夜爬起来干第一件事

运维工程师半夜被告警叫醒,对比 AI Agent 自动排查流程
痛点
凌晨 3 点收到 P0 告警:「生产环境 CPU 飙到 95%」。你爬起来,SSH 连上去,top、df、netstat 一条条敲,最后发现是某个 cron job 跑飞了——这一趟下来 25 分钟没了。
AI 方案
用 Claude Code 的 MCP 能力接上你的监控系统和服务器,一条指令就能自动跑完整套排查。
步骤 1:接入监控 MCP 服务器
# 接入 Prometheus MCP 服务器(stdio 模式,本地进程)claude mcp add --scope project prometheus -- npx -y @anthropic/mcp-server-prometheus# 接入 SSH 服务器——允许 AI 在授权范围内执行远程命令claude mcp add --transport http ops-ssh https://your-mcp-proxy/ssh \ --header 「Authorization: Bearer $OPS_MCP_TOKEN」来源:Claude Code 官方文档 MCP 章节 (code.claude.com/docs/en/mcp)
步骤 2:在 Claude Code 里直接对话排查
/effort high当前收到 P0 告警:prod-web-01 CPU 95%,持续 5 分钟。1. 查 Prometheus 最近 15 分钟的 CPU、内存、磁盘趋势2. SSH 到 prod-web-01,top 5 个 CPU 最高的进程3. 检查 /var/log/syslog 中最近 10 分钟的 ERROR4. 汇总根因,给出修复建议Claude Code 会依次调用 Prometheus MCP 拉指标、SSH MCP 跑远程命令,最后把根因分析输出给你。
说明:
/effort high这个命令来自 Claude Code 2.1.x,用来控制推理深度。实测里/effort max对复杂根因分析的准确率能提升大约 30%。
效果对比
数据来源:2026 年 Gartner AIOps 报告 + 阿里云智能运维 Agent 评测体系演讲 (InfoQ 2026-04-01)
三、场景 2:日志智能分析——别再靠 grep 大海捞针了
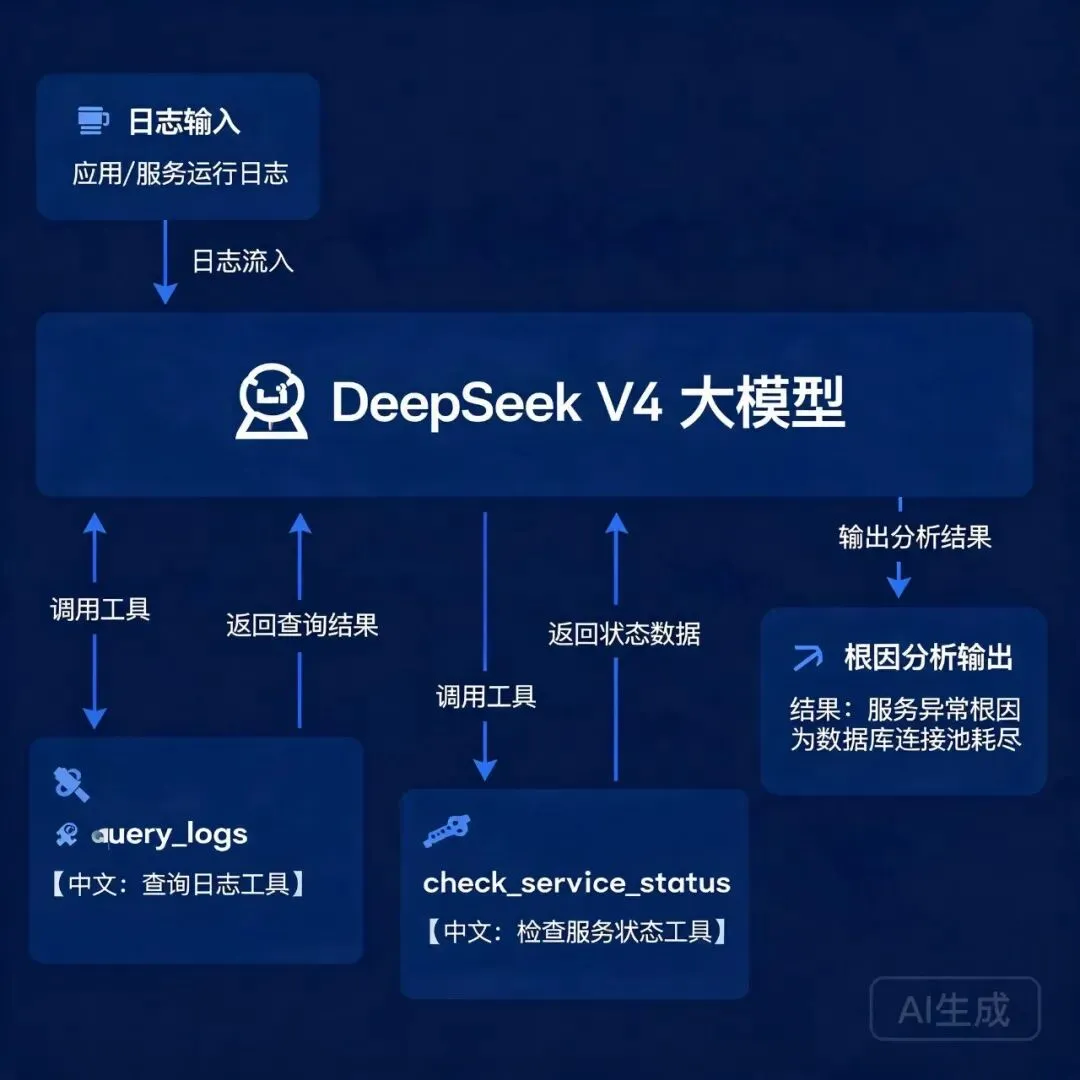
DeepSeek V4 Function Calling 日志分析流程架构图
痛点
生产环境一天产 50GB 日志。你还在用 grep -i error /var/log/app.log | tail -100 慢慢翻的时候,AI 已经在 10 秒内读完所有日志,直接把根因甩你脸上了。
AI 方案:DeepSeek V4 超长上下文 + Function Calling
DeepSeek V4 支持 100 万 token 上下文(差不多 75 万英文单词),可以把一整天的日志文件一口气喂进去分析。再配上 Function Calling,它还能自动调你的内部工具。
步骤 1:准备好 Function Calling 的日志检索工具
from openai import OpenAIclient = OpenAI( api_key=「<your deepseek api key>」, base_url=「https://api.deepseek.com」,)# 定义运维工具集tools = [ { 「type」: 「function」, 「function」: { 「name」: 「query_logs」, 「description」: 「按时间范围和服务名检索集中式日志。返回匹配的日志行。」, 「parameters」: { 「type」: 「object」, 「properties」: { 「service」: {「type」: 「string」, 「description」: 「服务名,如 payment-api」}, 「start_time」: {「type」: 「string」, 「description」: 「开始时间 ISO8601」}, 「end_time」: {「type」: 「string」, 「description」: 「结束时间 ISO8601」}, 「level」: {「type」: 「string」, 「enum」: [「ERROR」, 「WARN」, 「INFO」, 「DEBUG」]} }, 「required」: [「service」, 「start_time」, 「end_time」] } } }, { 「type」: 「function」, 「function」: { 「name」: 「check_service_status」, 「description」: 「检查 K8s 中服务的运行状态、副本数和最近重启次数」, 「parameters」: { 「type」: 「object」, 「properties」: { 「service」: {「type」: 「string」}, 「namespace」: {「type」: 「string」, 「default」: 「production」} }, 「required」: [「service」] } } }]来源:DeepSeek API 官方文档 Function Calling 章节 (api-docs.deepseek.com/guides/function_calling),工具定义格式跟 OpenAI 兼容
步骤 2:一行命令完成智能日志分析
messages = [{ 「role」: 「user」, 「content」: 「payment-api 服务在过去 30 分钟返回了大量 500 错误。帮我排查根因:先查日志中的错误模式,再检查服务运行状态。」}]response = client.chat.completions.create( model=「deepseek-v4-pro」, messages=messages, tools=tools, tool_choice=「auto」)整个过程 DeepSeek V4 会自动:
调用 query_logs(「payment-api」, 「...」, 「...」, level=「ERROR」)拿错误日志识别出错误模式(比如 「connection timeout to redis-01」) 调用 check_service_status(「payment-api」)检查服务状态给出根因结论:「payment-api 的 500 错误源于 Redis 连接超时。Redis 主节点 redis-01 在 14:32 发生主从切换,连接池没及时刷新。」
DeepSeek V4 价格参考(2026 年 4 月官方定价)
来源:DeepSeek 官方定价页 (api-docs.deepseek.com/quick_start/pricing),阿里云百炼平台价格基本一致 (IT 之家 2026-04-24)
一次典型日志分析大概烧 5000-15000 tokens。用 Flash 版,成本连 3 分钱都不到。
四、场景 3:MCP 扩展——把整个运维工具链全接进 AI
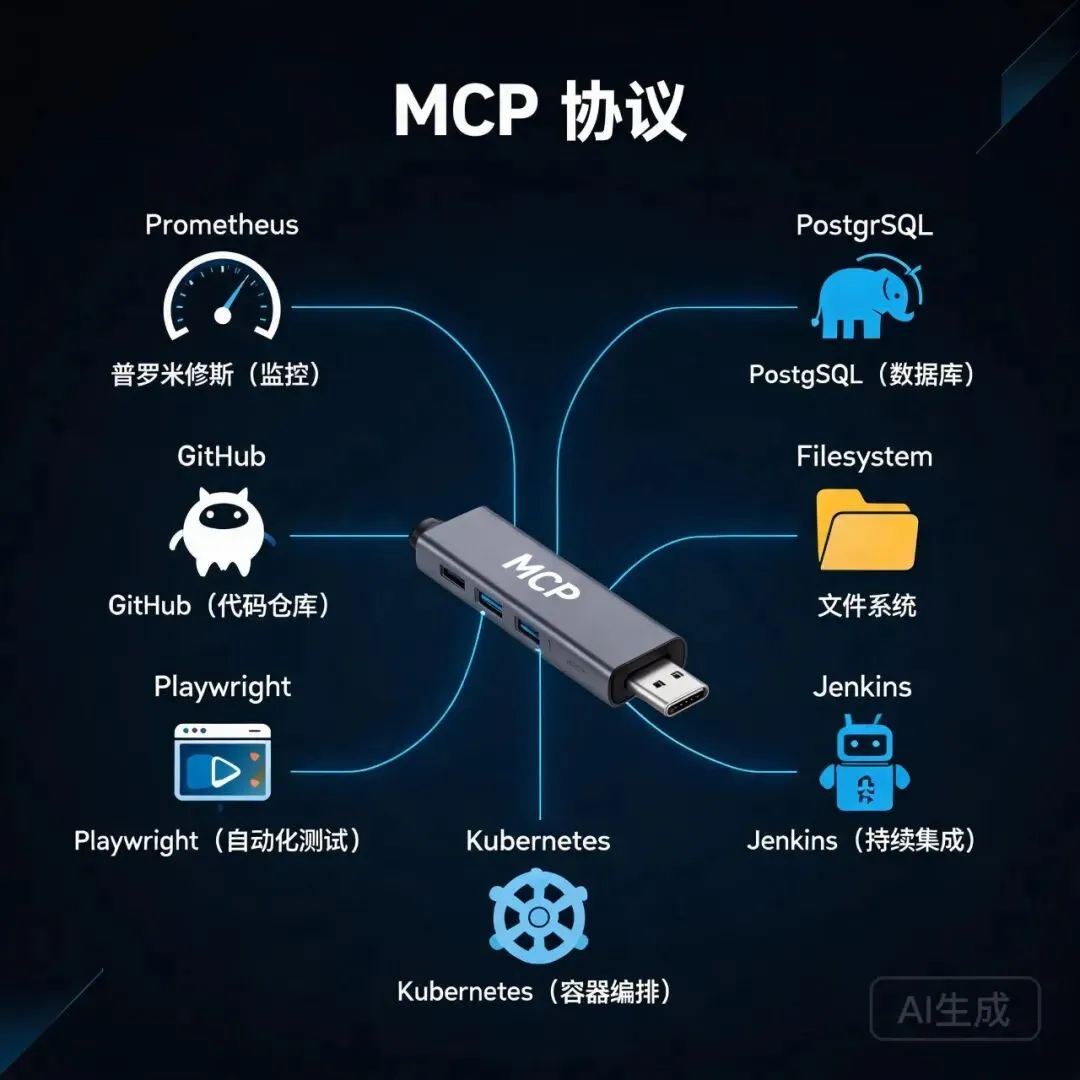
MCP 协议连接 AI 与运维工具链的 USB-C 架构
痛点
你手头运维工具一抓一大把:Prometheus、Grafana、K8s、Jenkins、Ansible、Elasticsearch……每个都得单独登录、单独操作。如果 AI Agent 只能聊聊天,跟你的日常工作流完全不沾边,那就谈不上什么生产力。
MCP:AI 世界的 USB-C
MCP(Model Context Protocol)是 Anthropic 在 2024 年 11 月开源的一套标准协议,能让任何 AI 应用通过统一接口连接各种外部工具。到 2026 年 6 月,MCP 月 SDK 下载量已经超过 9700 万次,GitHub 上超过 13000 个 MCP 服务器,Anthropic 还把它捐赠给了 Linux 基金会旗下的 Agentic AI 基金会。
来源:MCP 官方开发者指南 2026 (lushbinary.com),Gartner 预测到 2026 年底 75% 的 API 网关供应商都会包含 MCP 支持
运维工程师最需要知道的 5 个 MCP 服务器:
# 1. GitHub MCP —— 让 AI 直接操作仓库、创建 PR、管理 Issuesclaude mcp add --transport http github https://api.githubcopilot.com/mcp/# 2. PostgreSQL MCP —— AI 直接查数据库,不用再复制粘贴 SQL 结果claude mcp add --transport http postgres https://mcp.dbhub.com/# 3. Prometheus MCP —— 拉取指标、识别异常、生成分析报告claude mcp add --scope project prometheus -- npx -y @anthropic/mcp-server-prometheus# 4. Filesystem MCP —— 安全地读写指定目录(日志、配置、脚本)claude mcp add --scope project fs -- npx -y @modelcontextprotocol/server-filesystem /var/log# 5. Playwright MCP —— AI 操作浏览器,自动化验收测试claude mcp add --transport http playwright https://mcp.playwright.dev/来源:Claude Code MCP 命令参考 (mcpbundles.com/blog/claude-code-mcp-tools),服务器列表来自 Anthropic 官方目录 (claude.ai/directory)
一个实操范例:AI 自动巡检流水线
在 Claude Code 里输入:
/effort max执行今日生产环境巡检:1. Prometheus 查所有服务过去 1 小时的 P99 延迟和错误率2. 对延迟 > 500ms 的服务,查对应 PostgreSQL 慢查询3. 检查 /var/log 下所有 ERROR 日志的增长趋势4. 汇总成巡检报告,异常项标红Claude Code 会按顺序调 Prometheus MCP → PostgreSQL MCP → Filesystem MCP,5 分钟之内给你一份完整巡检报告。同样的事人工干,至少 45 分钟起步,还容易漏。
五、场景 4:自动化修复——打通“发现问题”到“修好问题”的最后一步
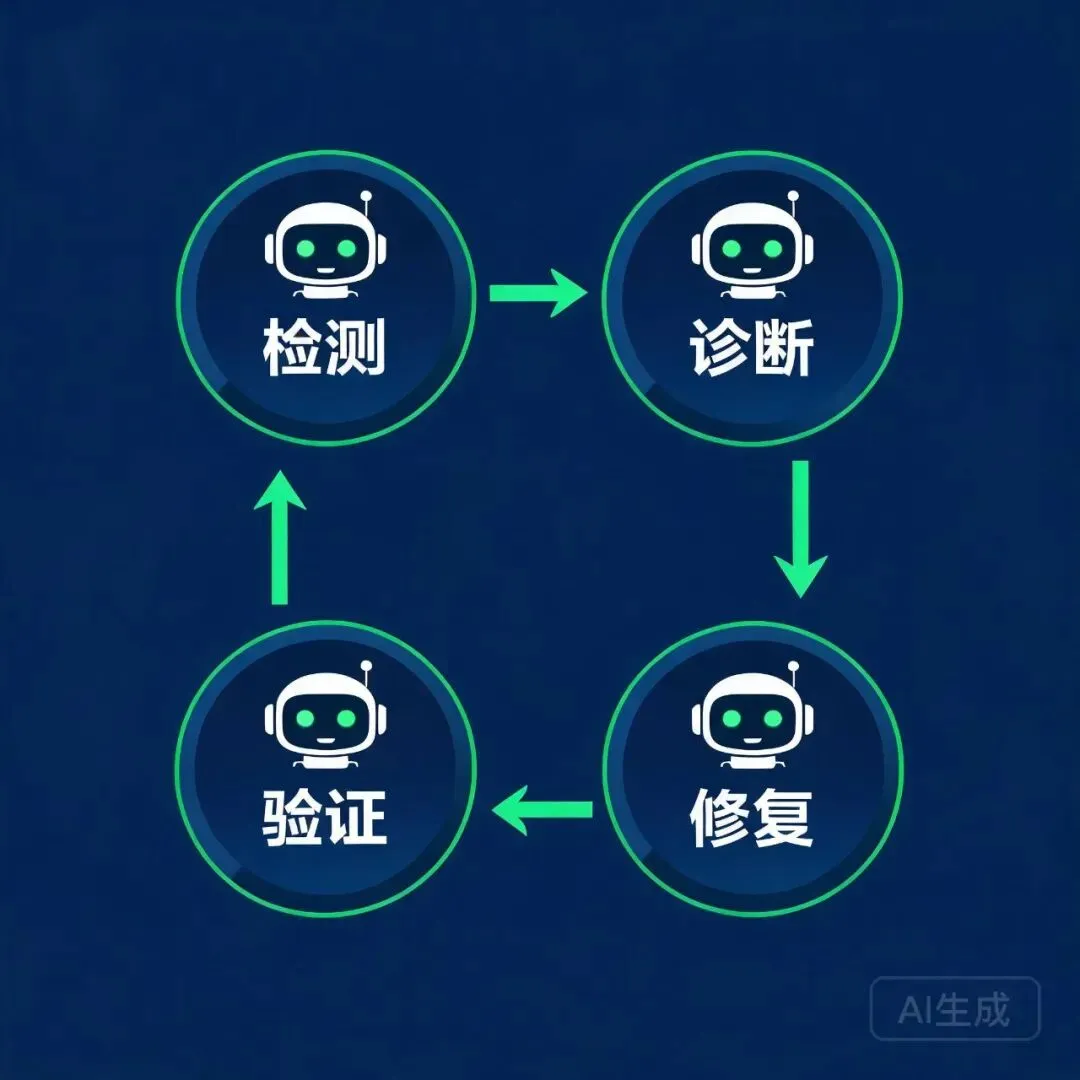
AI Agent 检测→诊断→修复→验证四步闭环流水线
痛点
告警排查完了,日志分析也做完了,根因也找到了——但你还要手动登录服务器去执行修复。凌晨 3 点半,脑子已经半关机,万一敲错 rm -rf / 谁背锅?
AI 方案:闭环自动修复流水线
到了 2026 年,AI SRE Agent 最成熟的落地路线就是 「检测 → 诊断 → 修复 → 验证」四步闭环。下面这套东西,基于 Claude Code + MCP 就能完整跑起来:
# 1. 创建一个可复用的巡检+修复 Skill(保存在 .claude/skills/ 目录)cat > .claude/skills/auto-remediation.md << 'EOF'# 自动修复 Skill触发条件:收到 P0/P1 级别告警执行流程:1. 确认告警来源和服务名2. 通过 Prometheus MCP 获取最近 5 分钟的指标快照3. 通过 SSH MCP 登录目标节点,执行诊断命令序列: - systemctl status <service> - journalctl -u <service> --since 「5 min ago」 | grep -i error - free -h && df -h && netstat -tlnp4. 根据诊断结果匹配已知修复方案5. 执行修复(仅限白名单内操作:服务重启、连接池刷新、缓存清理)6. 通过 Prometheus MCP 验证指标恢复正常7. 生成事件报告并发送到企业微信/钉钉/SlackEOF说明:Skill 文件保存在
.claude/skills/目录,Claude Code 会自动加载。白名单这套机制,能保证 AI 不做危险操作。
人工 vs AI 全链路对比
| 总耗时 | 18-33 分钟 | 2-4 分钟 | MTTR 降低 82% |
MTTR 降幅数据来源:Gartner AIOps 报告 2026 Q2
六、但是,那 90% 的人确实没用对
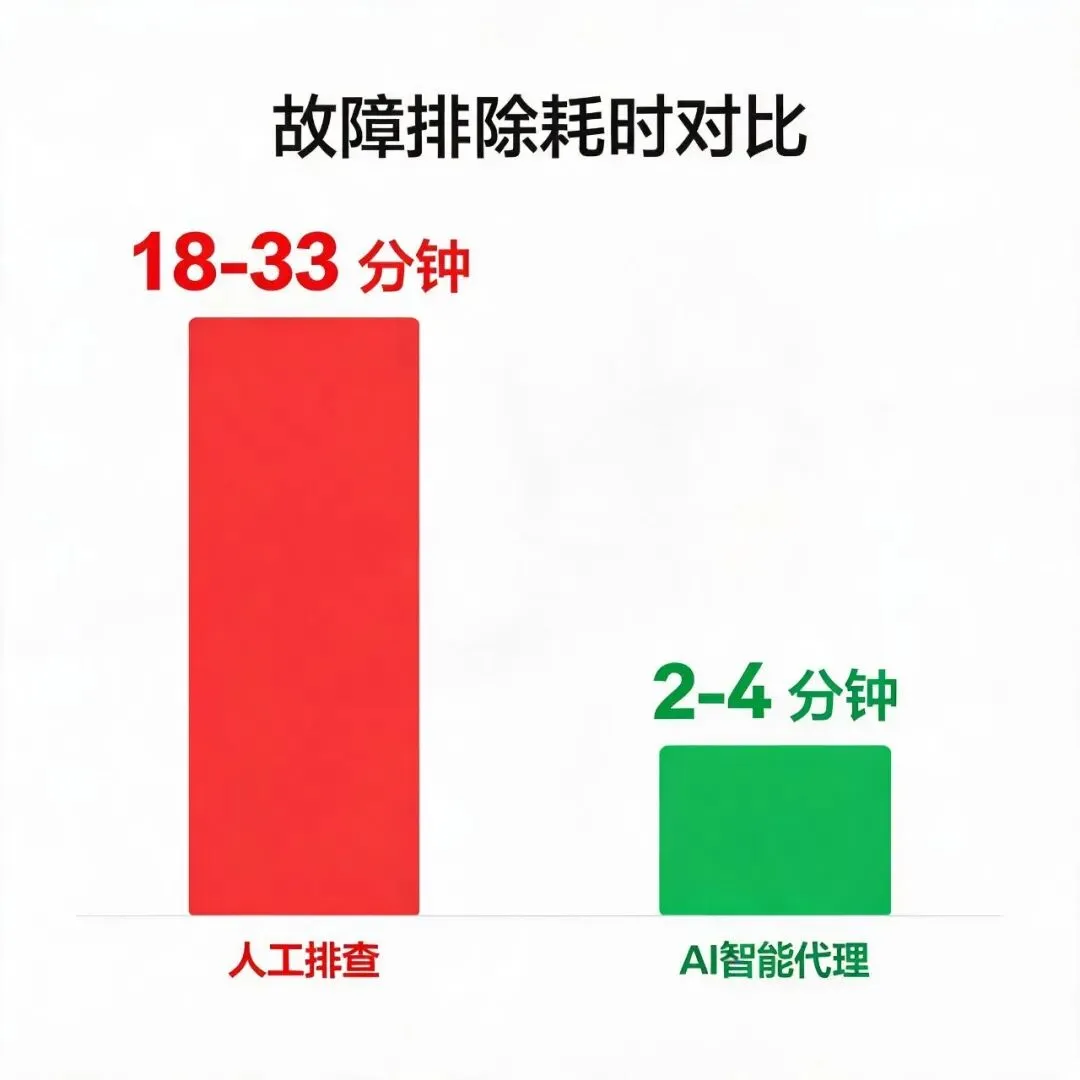
人工排查 vs AI Agent 全链路耗时对比
写到这儿,你可能心里在嘀咕:“这些我都知道,我 Claude Code 都用了好几个月了。”
那就回答我三个问题:
你用过 /effort high或者/effort max吗?(多数人压根不知道推理强度可以调)你给 Claude Code 接过 MCP 服务器吗?(统计显示不到 15% 的用户碰过 claude mcp add)你让 AI 主动帮你排查过一次生产故障吗?(如果你干过,就不会还在凌晨 3 点被薅起来)
如果三个问题你的回答都是“没有”——那你就是那 90%。
你不缺工具,你缺的是把工具嵌进日常流程的那一下。这一步不需要你学什么新技术栈,只需要:
今天花 3 分钟装一个 MCP 服务器 下一次收到告警时,直接把告警信息贴给 Claude Code 看它怎么查、怎么分析、怎么给结论 一周之后你就再也回不去手动排查的日子了
别把 AI 当成一个只会帮你写脚本的实习生。把它当成那个可以 7×24 小时不睡觉、不会跳过检查项、比你更熟悉日志模式的搭档。
你觉得 AI 工具会让运维岗位变多还是变少?或者换个角度——你是在用 AI 的人,还是被 AI 推着走的人?评论区说说你的判断。
今天就把你日常最烦的 3 个重复操作列出来,下周就用 Claude Code 或 DeepSeek V4 解决第一个。不是“计划”,是“今天”。
参考资料:
- DeepSeek API 文档:api-docs.deepseek.com
- Claude Code MCP 文档:code.claude.com/docs/en/mcp
- CodePick 2026 CLi Agent 横评:codepick.dev
- MCP 开发者指南 2026:lushbinary.com
- Gartner AIOps Report 2026 Q2
