夜雨聆风
夜雨聆风环境:Spring Boot 3.5.0
1. 简介
随着 AI 智能体连接的服务越来越多(如 Slack、GitHub、Jira、MCP 服务器等),工具库规模也在快速膨胀。一个典型的多服务器配置,在对话开始前就可能包含 50 多个工具,消耗超过55000 个 Token。更严重的是,当模型面对 30 多个名称相似的工具时,工具选择的准确率会显著下降。
由 Anthropic 首创的工具搜索工具(Tool Search Tool)模式,正是为了解决这一问题:模型不再一次性加载所有工具定义,而是按需发现工具。它初始仅接收一个搜索工具,在需要时查询工具能力,并将相关工具定义扩展到上下文当中。这种方式能在保持对数百个工具访问能力的同时,实现大幅 Token 节省。
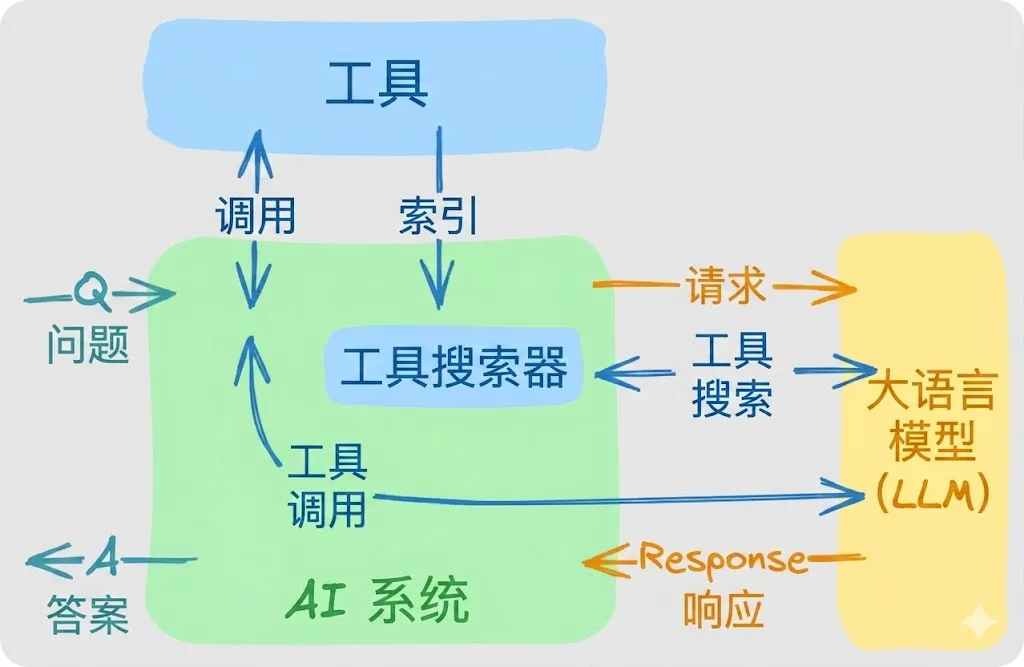
核心思路:虽然 Anthropic 是为 Claude 模型引入了这一模式,但我们可以借助 Spring AI 的递归顾问(Recursive Advisors),为任意大语言模型实现相同的方案。Spring AI 提供了一套可移植的抽象层,让动态工具发现能力能够适配 OpenAI、Anthropic、Gemini、Ollama、Azure OpenAI,以及所有其他 Spring AI 支持的大语言模型服务商。
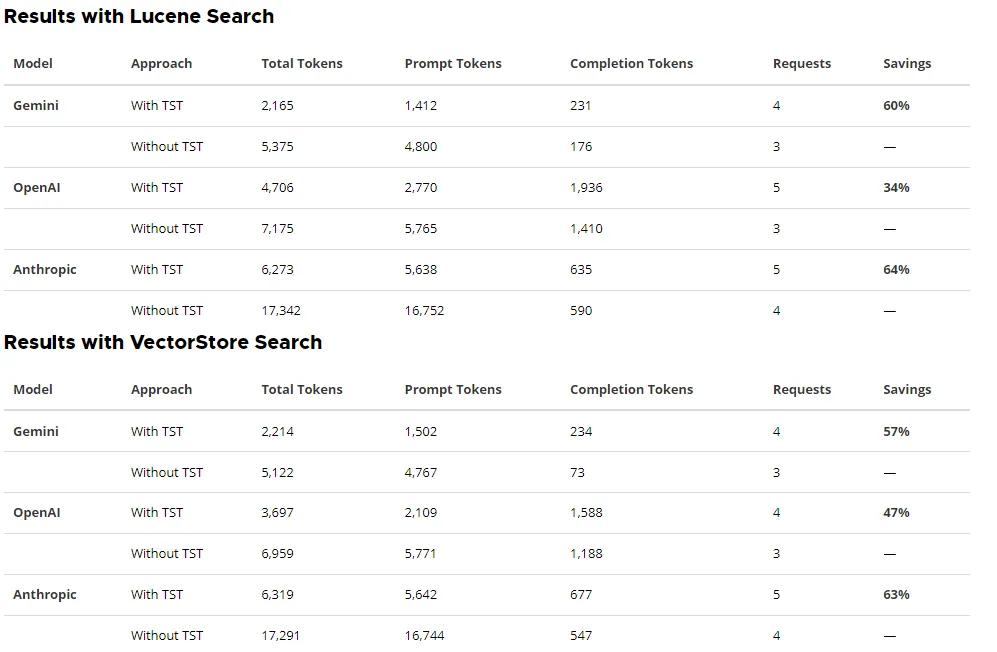
初步基准测试显示,Spring AI 实现的工具搜索工具,在 OpenAI、Anthropic 和 Gemini 模型上,均实现了34%-64% 的 Token 消耗降低,同时保持了对数百个工具的完整访问能力。
工作原理:
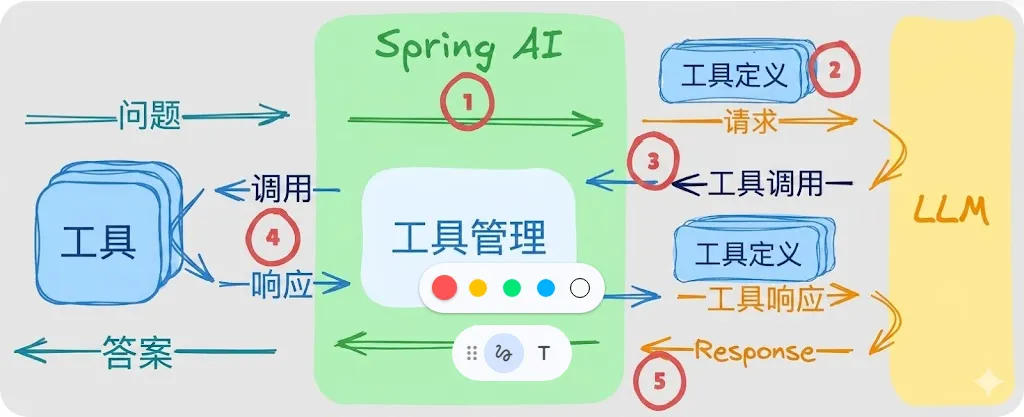
首先,让我们了解在使用 ToolCallAdvisor 时 Spring AI 的工具调用机制——这是一个特殊的递归顾问,它:
在请求到达 LLM 之前拦截 ChatClient 请求
将工具定义包含在发送给模型的提示词中 —— 涵盖所有已注册的工具
检测模型响应中的工具调用请求
使用 ToolCallingManager 执行请求的工具
循环带入工具结果,直到模型给出最终答案
该工具的执行是在一个递归循环中进行的——Advisor会不断调用大型语言模型,直到不再有工具调用请求为止。
这有什么问题呢?
标准工具调用流程(例如 ToolCallAdvisor)会预先向大语言模型发送所有工具定义。当工具集合规模较大时,这会引发三大主要问题:
上下文膨胀:对话开始前就产生大量 Token 消耗
工具混淆:面对 30 多个相似工具时,模型难以做出正确选择
成本升高:每次请求都要为未使用的工具定义付费
那么工具搜索工具解决方案
通过扩展 Spring AI 的 ToolCallAdvisor,创建了一个 ToolSearchToolCallAdvisor,实现了动态工具发现。它会拦截工具调用循环,根据模型发现自己需要什么,有选择地注入工具:
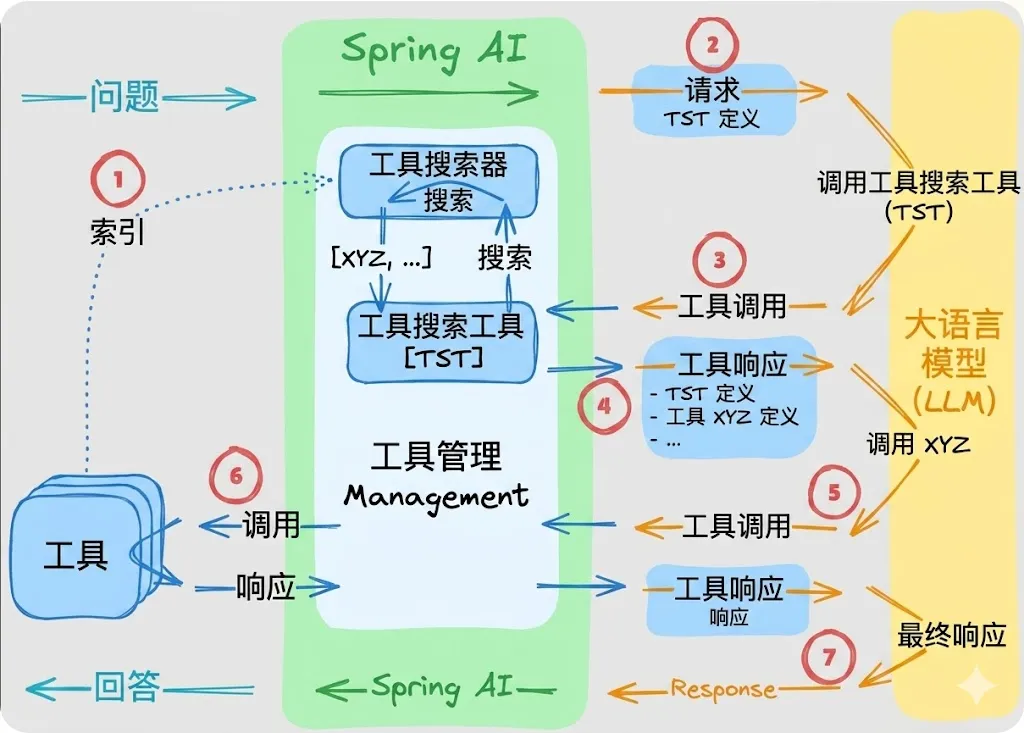
具体工作原理如下:
建立索引:对话开始时,所有已注册工具会在 ToolSearcher 中建立索引(但不会发送给大语言模型)
初始请求:仅将工具搜索工具(TST)的定义发送给大语言模型,节省上下文
发现调用:当大语言模型需要特定能力时,会使用搜索查询调用 TST
搜索与扩展:ToolSearcher 找到匹配的工具(例如 “Tool XYZ”),并将其定义添加到下一次请求中
工具调用:此时大语言模型可以同时看到 TST 和已发现工具的定义,即可调用实际工具
工具执行:执行已发现的工具,并将结果返回给大语言模型
生成响应:大语言模型根据工具执行结果生成最终答案
在代码中,这看起来是这样的:
var toolSearchToolCallAdvisor = ToolSearchToolCallAdvisor.builder().toolSearcher(toolSearcher).maxResults(5).build();ChatClient chatClient = chatClientBuilder// 数百个工具已注册,但最初不会发送给 LLM.defaultTools(new MyTools(), ...)// 激活 Tool Search Tool.defaultAdvisors(toolSearchToolCallAdvisor).build();
可插拔的搜索策略
ToolSearcher 接口对搜索实现进行了抽象,支持多种策略(具体实现请参考 tool-searchers):
VectorToolSearcher | ||
LuceneToolSearcher | ||
RegexToolSearcher | get_*_data) |
接下来,我们将介绍如何在Spring AI中使用。
<dependency><groupId>org.springaicommunity</groupId><artifactId>tool-search-tool</artifactId><version>1.0.1</version></dependency><dependency><groupId>org.springaicommunity</groupId><artifactId>tool-searcher-lucene</artifactId><version>1.0.1</version></dependency>
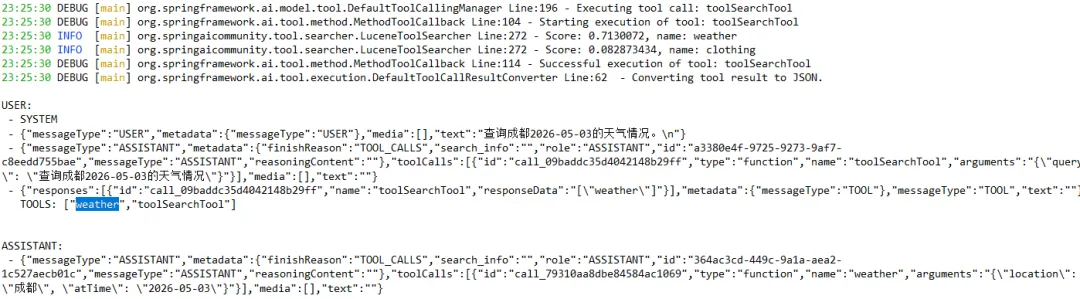
public class MyTools {@Tool(description = "获取指定地点在指定时间的天气")public String weather(@ToolParam(description = "地点") String location, @ToolParam(description = "YYYY-MM-DD") String atTime) {System.err.println("%s, %s 天气情况:xxx".formatted(location, atTime)) ;return "32℃,天气晴朗,紫外线弱" ;}@Tool(description = "获取指定地点正在营业的服装店")public List<String> clothing(@ToolParam(description = "地点") String location) {return List.of("劲霸男装", "恒源祥服装") ;}// 更多工具}
@Configurationpublic classToolsConfig{@BeanToolSearcher toolSearcher() {return new LuceneToolSearcher() ;}}
@Componentpublic class DynamicToolRunner implements CommandLineRunner {private final ChatClient chatClient ;public DynamicToolRunner(ChatClient.Builder builder, ToolSearcher toolSearcher) {var advisor = ToolSearchToolCallAdvisor.builder().toolSearcher(toolSearcher).build() ;this.chatClient = builder.defaultTools(new MyTools()).defaultAdvisors(advisor).build() ;}@Overridepublic void run(String... args) throws Exception {var answer = chatClient.prompt("""查询成都2026-05-03的天气情况。""").call().content();System.out.println(answer);}}


⚠️ 免责声明:这些是经过少量运行后得出的初步人工测量数据。它们未经过多次迭代取平均值,因此仅作演示用途,不具备普遍代表性。
为了量化 Token 节省效果,我们使用演示应用程序进行了初步基准测试,配置如下:
任务:“帮我规划一下今天在阿姆斯特丹穿什么,推荐几家现在营业的服装店。”
工具总数:28 个工具,包括 3 个相关工具(weather、clothing、currentTime)+ 25 个不相关的 “占位工具”(刻意与天气 / 服装任务无关,用于演示工具搜索如何在大量无关选项中高效发现所需工具)
搜索策略:Lucene(基于关键词)和 VectorStore(基于语义)
测试模型:Gemini(gemini-3-pro-preview)、OpenAI(gpt-5-mini-2025-08-07)、Anthropic(claude-sonnet-4-5-20250929)
测量数据通过自定义的 TokenCounterAdvisor 组件收集,该组件会跟踪并汇总 Token 使用量。
别再瞎拼 URL 了!Spring Boot 这套 URI 工具太香
千万级数据查询零 OOM:Spring Boot 流式查询终极实战方案
告别重启!Spring Boot 手写热更新,@Value实时刷新
强大!Spring Boot 通过6大核心技术,轻松实现请求数据修改
性能提升30倍!Jackson-Jr 高性能JSON序列化神器
Spring AI + LangGraph4j 多智能体开发,太强大了!
请一定记住!Spring Boot 执行初始化操作的 7 种王炸手段
强大!Spring Boot 巧妙利用 SpEL 实现复杂的规则运算