夜雨聆风
夜雨聆风
📢本营圈社区邀您加入!
这里汇聚了资本市场的真实声音,每一位发言者,均通过严格身份认证。他们来自买方、卖方、行业专家、战略投资者、独立研究人。在这里,没有杂音,只有来自市场核心的专业洞察与深度思考。
微信扫码,即可限时免费体验🔽

智谱和 MiniMax 的对比,上一层是港股 AI 资产的交易分化,下一层则是模型能力排序的变化。
如果只讨论涨跌、锁定期和估值差,文章会停留在交易层面。更值得分析的是,为什么同样是中国大模型公司,市场阶段性更愿意给智谱更高的模型能力溢价,而对 MiniMax 保持更高折价。
答案不只在财务报表,也不只在产品发布节奏。模型公司进入商业化阶段后,核心变量会逐渐收敛到四件事:任务完成能力、推理成本、开发者可获得性和生态迁移成本。
OpenAI 与 Anthropic 的竞争已经提供了一个成熟参照。OpenAI 在 GPT-5.5 中强调复杂专业工作、coding、研究和工具调用;Anthropic 在 Claude Opus 4.8 中强调 coding、agentic tasks、professional work 和长周期任务一致性。两家公司领先地位的变化,不是因为单一参数或单一榜单,而是因为模型能力与企业工作流的结合方式不断变化。
智谱和 MiniMax 的分化,也应放在这个框架里看。
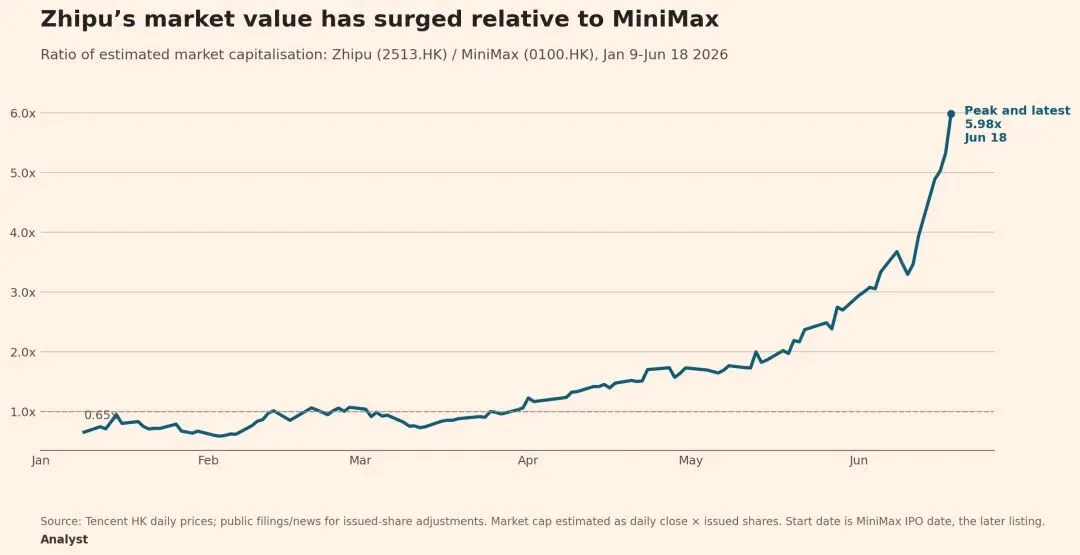
图表口径:起点为两家公司 IPO 较晚者上市后、两家公司共同可交易的首个港股交易日,即 2026 年 1 月 9 日;终点为当前可得的最新完整港股交易日,即 2026 年 6 月 18 日收盘。数值为“智谱估算市值 / MiniMax 估算市值”。估算市值按腾讯港股日 K 收盘价乘以当前总股本计算,股本口径为智谱 445,843,090 股、MiniMax 313,635,308 股,不是公司官方逐日披露市值。
这条曲线可以作为市场阶段性定价的观察指标,但不能被理解为模型能力或基本面的直接证明。按上述估算口径,智谱市值 / MiniMax 市值从 2026 年 1 月 9 日的约 0.65 倍,上升到 2026 年 6 月 18 日的约 5.98 倍。它更像市场对两家公司模型叙事、开发者可获得性、成本曲线和生态迁移前景的阶段性投票:智谱的强开源和长任务定位更容易被定价,MiniMax 的多模态路线仍需用使用留存、毛利率和企业级调用量继续验证。
一、模型股的定价锚,正在从通用能力转向长任务交付
大模型的资本市场叙事,已经从“谁拥有模型”进入“谁的模型能完成高价值任务”。
高价值任务有几个共同点:上下文很长,链路较复杂,失败成本较高,并且需要跨工具执行。典型场景包括全仓库代码理解、复杂代码改造、长文档分析、企业知识库问答、自动研究和多步骤 agent 工作流。
因此,模型能力的评估不再只看通用问答分数。市场会更重视 long-horizon tasks、coding benchmark、agent benchmark、上下文有效利用率、API 定价和部署灵活性。
OpenAI GPT-5.5 的官方材料将其定位为面向 complex professional work 的 frontier model,并列出 GDPval、OSWorld-Verified、Tau2-bench Telecom 等知识工作和工具执行指标。Anthropic Claude Opus 4.8 的官方材料则强调 coding、agentic tasks、professional work,以及长周期工作的一致性。
这些表述说明,前沿模型公司的竞争正在靠近企业生产场景。模型能否稳定完成任务,正在比模型是否“聪明”更重要。
同样逻辑可以解释智谱和 MiniMax。
智谱的 GLM-5.2 更容易被市场放进 coding/agent 和企业开发者框架。MiniMax M3 则更像一条兼顾长上下文、多模态和成本结构的路线。二者都具备技术看点,但现阶段市场更容易给前者定价。
二、GLM-5.2 的关键,不是开源本身,而是“强开源”进入开发者工作流
GLM-5.2 的市场催化,不能简单归因于开源。
开源模型很多,但能进入开发者工作流的开源模型并不多。对企业开发者而言,开源许可、权重可得性、上下文长度、coding 能力和推理成本必须同时成立,才具备迁移价值。
Z.ai 官方材料将 GLM-5.2 定位为面向 long-horizon tasks 的旗舰模型,支持 100 万 token 上下文,并采用 MIT 开源许可。Hugging Face 模型卡也显示,GLM-5.2 为 MIT license,模型权重已公开。
第三方评测进一步强化了这一叙事。Artificial Analysis 称,GLM-5.2 在 Intelligence Index v4.1 中成为领先 open weights 模型,得分 51,高于 MiniMax-M3、DeepSeek V4 Pro 和 Kimi K2.6。Artificial Analysis 同一篇评测中还列出,MiniMax-M3 在 Intelligence Index v4.1 得分为 44,低于 GLM-5.2 的 51。
Hugging Face 的 GLM-5.2 技术材料还列出多个 coding 和 long-horizon benchmark:SWE-bench Pro、Terminal-Bench 2.1、FrontierSWE、PostTrainBench 等。其中 GLM-5.2 相比 GLM-5.1 在长任务和 coding 指标上提升明显,并在若干指标上接近闭源前沿模型。
这组证据使智谱的叙事更像“企业级模型能力提升”,而不是单纯的国产模型情绪。
更重要的是,MIT 许可降低了企业采用门槛。对企业客户而言,许可友好意味着可部署、可微调、可做本地合规验证,也降低了被单一闭源供应商锁定的风险。
这解释了为什么 GLM-5.2 更容易成为资本市场关注的技术催化。它不是一个孤立模型更新,而是把开源许可、长上下文和开发者工作流放在同一个商业方向上。
三、MiniMax M3 的问题,不是没有技术点,而是技术点尚未转化为可定价优势
MiniMax M3 的技术路线有明确特色。
官方博客将 M3 描述为结合 coding、agent、100 万 token 长上下文和原生多模态能力的模型,并强调其 MiniMax Sparse Attention 架构。该架构目标是降低长上下文计算负担,使超长上下文和多模态输入具备更高推理效率。
从技术方向看,MiniMax M3 并不弱。多模态输入、视频理解、图像到代码、桌面操作和长上下文 agent,都是未来 agent 产品的重要入口。第三方基础设施公司对 M3 的评价,也集中在长上下文和多模态能力的组合价值上。
但资本市场更关注技术优势能否转化为定价权。
MiniMax 官方 Pay-as-you-go 页面显示,M3 标准档与长上下文档均标注 Permanent 50% off。官方 Token Plan 迁移指南强调既有用户权益保护,并将 M3 纳入统一 token 池。公司角度可以解释为降低使用门槛和扩大开发者采用;资本市场则更容易把价格调整解读为毛利率和竞争力压力。
因此,MiniMax 需要回答的问题不是“M3 有没有能力”,而是三项更财务化的问题。
第一,M3 的多模态与长上下文能力,是否能形成高频开发者使用,而不是发布期试用。
第二,稀疏注意力带来的推理效率,是否足以抵消价格调整对毛利率的压力。
第三,消费端产品和开放平台收入,能否沉淀为更高质量的企业级调用量。
如果这些指标改善,MiniMax 的多模态路线仍有重估基础。如果使用量主要依赖价格刺激,市场折价就会继续存在。
四、OpenAI 与 Anthropic 的竞争,说明模型领先是动态变量
OpenAI 与 Anthropic 的竞争提供了参照:前沿模型的领先地位并不是静态资产,但这种参照不能被简化为中美公司的直接对标。
OpenAI 的优势在于产品入口、API 生态和工具链整合。GPT-5.5 官方材料强调复杂专业工作、coding、研究、文档和跨工具执行,并在 API 模型页展示 100 万上下文窗口和较高推理档位。
Anthropic 的优势更集中在可靠 agent、专业工作和长周期任务完成。Claude Opus 4.8 官方材料强调 coding、agentic tasks 和 professional work,并将其作为 Opus 系列的能力升级。
这说明模型领先不是静态资产。一个模型实验室可以在通用能力上阶段性领先,另一个实验室也可能通过更强 agent 稳定性、更低 token 消耗、更好的企业部署和更清晰的开发者体验,重新获得客户和市场认知。
这也是智谱和 MiniMax 对比的核心。
智谱当前的优势,并不是“公司基本面已经胜出”。更准确的表述是,在这一轮模型能力验证中,GLM-5.2 更容易被市场识别为强开源、长任务和开发者工作流资产。
MiniMax 当前的压力,也不是“技术失败”。更准确的表述是,M3 的多模态和推理效率路线,需要更多外部验证,尤其需要把技术亮点转化为可持续使用量和毛利率改善。
五、后续验证路径应聚焦四个指标
重新理解智谱和 MiniMax 后,跟踪重点也应调整。
第一,看高价值任务占比。聊天流量不足以支撑高估值,coding agent、企业知识库、全仓库代码任务和长文档自动化更值得关注。GLM-5.2 的长任务定位,使其更容易进入这类付费场景。
第二,看开发者可获得性。Hugging Face 权重、MIT license、API 兼容性、本地部署支持和推理服务生态,都会影响企业迁移成本。开源模型只有在性能足够接近闭源前沿时,才会真正产生商业替代价值。
第三,看单位经济模型。长上下文和多模态都提高算力压力。MiniMax M3 强调稀疏注意力,本质上是在解决成本曲线问题。这个方向成立,但需要用毛利率、调用量和留存数据验证。
第四,看生态节奏。OpenAI 与 Anthropic 的竞争说明,模型领先会随产品节奏和企业部署反复换位。智谱如果后续模型更新放慢,优势可能被稀释;MiniMax 如果证明多模态 agent 场景有真实需求,折价也可能修复。
因此,这篇文章的结论不是“智谱已经赢,MiniMax 已经输”。更合适的判断是:在当前资本市场可验证的模型能力维度上,智谱的 GLM-5.2 更容易被定价;MiniMax M3 则处于技术路线等待商业化验证的阶段。
模型股未来的分层,大概率不再按“谁是大模型公司”划分,而会按“谁能把模型能力转化为企业工作流”划分。
第一层公司,只能发布模型。第二层公司,能把模型放进 API 和应用。第三层公司,能在性能、成本、许可和生态之间取得均衡,并持续获得开发者迁移。
智谱和 MiniMax 的分化,正是在测试谁能进入第三层。
这比单纯解释短期股价,更接近这组对比的研究价值。
图表口径
起点:2026-01-09,即 MiniMax 上市后、两家公司共同可交易的首个港股交易日。
终点:2026-06-18 收盘,即当前接口可得的最新完整港股交易日。
数据源:腾讯港股日 K 收盘价。
估算口径:估算市值 = 收盘价 × 当前总股本。
股本口径:智谱 445,843,090 股;MiniMax 313,635,308 股,来自腾讯行情快照字段。
整理自公开信息,不作为任何投资建议