夜雨聆风
夜雨聆风
背景与问题
在 Android 应用安全测试中,对目标 App 私有目录(/data/data/<package>/)的审计是一项基础且高频的操作。
Android 系统从设计上严格隔离了各应用的私有数据空间,只有具备 Root 权限的进程才能直接访问。对安全测试人员而言,这意味着每一次查看 SharedPreferences 配置文件、检查数据库中的敏感存储、提取 Realm 或 SQLite 文件,都需要经过一套固定的手工流程:
adb shellsucd /data/data/com.target.app/ls -lacat shared_prefs/xxx.xml当审计的 App 数量增多、目录结构加深,这种操作模式的低效会被迅速放大。更严重的是,在纯终端环境下浏览文件树,缺乏可视化结构,很容易遗漏深层目录中的关键文件。
一个更理想的方案是:将 Android 设备的私有目录直接映射为本地可视化的文件浏览器,嵌入到测试人员的主工具——Burp Suite 中,在拦截和分析 HTTP 流量的同时,随时查看目标 App 的本地数据存储状态。
这就是本文要介绍的插件:Android Private Directory Browser。
Root 环境与 Root 检测绕过
插件的核心前提是设备具备 Root 权限。但在实际测试场景中,相当一部分目标 App 会实现 Root 检测机制(如检测 su 二进制文件、/system/app/Superuser.apk 存在性、调用 RootBeer 等第三方库),检测到 Root 后拒绝运行。
针对这一问题的常规解决方案是使用 Magisk 的 Root 隐藏(Root Hiding)能力:通过 MagiskHide 或 Magisk DenyList 机制,对目标应用隐藏 Root 痕迹,使其在正常启动后,再通过 ADB 以 Root 权限访问其私有目录。整个流程如下:
1. 设备刷入 Magisk,获取 Root 权限 2. 在 Magisk 设置中将目标 App 加入 DenyList,隐藏 Root 痕迹 3. 启动目标 App,此时 App 未被 Root 检测阻断 4. 通过 ADB + su访问该 App 的/data/data/目录,进行数据审计
这种方式使得即使是对 Root 敏感的生产环境 App,也可以在真实设备上完成完整的私有目录审计。
插件架构
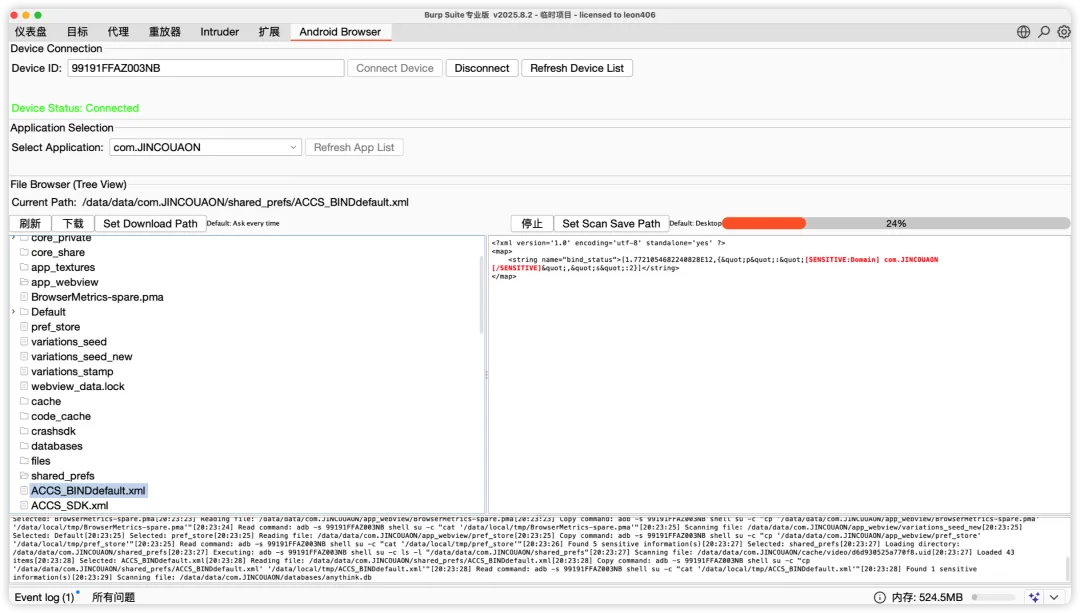
插件基于 Burp Suite Extender API 开发,以 Python(Jython)形式运行在 Burp 的插件容器中。插件成品使用预览:
接口实现
主类 BurpExtender 同时实现四个 Burp 原生接口:
IBurpExtender | callbacks 对象,注册所有回调 |
ITab | |
IHttpListener | |
IExtensionStateListener |
UI 架构
整个插件的 UI 层基于 Java Swing 构建,采用 BoxLayout(纵向) + BorderLayout(面板内部) + JSplitPane(分割视图)的组合布局策略:
主面板(BoxLayout,Y_AXIS 纵向排列)│├── Device Connection 面板(BorderLayout)│ ├── 输入区:Device ID 文本框 + Connect/Disconnect 按钮 + Refresh Device List 按钮│ └── 状态区:连接状态标签(红/绿色动态切换)│├── Application Selection 面板(BorderLayout)│ └── 应用下拉列表(JComboBox,按字母排序) + Refresh App List 按钮│└── File Browser 面板(BorderLayout) │ ├── 工具栏:当前路径显示 + Refresh + Download + Set Download Path 按钮 │ └── JSplitPane(VERTICAL_SPLIT,上下分割) │ ├── 上部:JSplitPane(HORIZONTAL_SPLIT,左右分割) │ ├── 左侧:JTree 文件树(JScrollPane 包裹,支持懒加载) │ └── 右侧:JTextPane 文件内容区(StyledDocument,支持彩色文本渲染) │ └── 下部:JTextArea 日志区(自动截断至 1000 行,防止内存溢出)线程模型
Burp Suite 的 UI 基于 Swing,所有 UI 操作必须在 EDT(Event Dispatch Thread) 上执行。插件中涉及 ADB 通信的操作(设备连接、文件列表获取、文件内容读取)均为阻塞 I/O,因此统一放在独立线程中执行,结果通过 SwingUtilities.invokeLater() 回写 UI。
核心模式:
def someUIAction(self): threading.Thread(target=self.worker).start()def worker(self): # 在子线程中执行 ADB 操作 result = subprocess.Popen(adb_cmd, ...) # 通过 invokeLater 回写 UI SwingUtilities.invokeLater(lambda: self.updateUI(result))log() 方法本身也通过 invokeLater 封装,确保多线程环境下日志写入不会触发 Swing 的线程安全异常。
核心功能详解
1. 设备连接与 Root 权限验证
连接流程分为两步:
第一步:设备可达性验证
执行 adb devices,解析输出。解析逻辑会跳过首行 List of devices attached 头信息,按 \tdevice 分隔符提取有效设备 ID。若设备未出现在列表中,提示用户检查 USB 调试是否开启。
此外,Refresh Device List 功能会在扫描前主动执行 adb start-server,解决 ADB 守护进程未启动导致的空列表问题——这是一个在实际使用中经常被忽略的细节。
第二步:Root 权限验证
执行 adb -s <deviceId> shell su -c "echo test"。若返回中包含 test,说明 su 提权成功,设备已 Root;若返回为空或包含 Permission denied,则说明 Root 不可用或 su 未被正确安装。
连接状态通过 JLabel 的 setForeground() 动态切换:未连接为红色,连接成功为绿色。同时,连接成功后自动启用应用列表下拉框和相关按钮,断开后自动禁用,保证 UI 状态与连接状态严格同步。
2. 应用列表获取
执行 adb shell pm list packages -3,获取设备上所有第三方安装应用(排除系统应用)。-3 参数至关重要——系统应用数量通常在上百个,而安全测试的目标几乎都是用户安装的应用。
输出格式为 package:com.xxx.yyy,解析后去掉前缀,按字母排序,填入 JComboBox。
选择应用后,插件自动拼接路径 /data/data/<package>,并触发文件树的首次构建。
3. 树形文件浏览器(懒加载架构)
这是插件最核心的 UI 能力。文件树基于 JTree + DefaultTreeModel 实现,有两个关键设计值得重点关注。
懒加载(Lazy Loading)
目录节点采用展开时加载策略:首次构建文件树时,只对当前目录执行 ls -l,每个子目录节点预先挂载一个 "Loading..." 占位子节点。当用户展开该目录节点时,TreeExpansionListener 捕获展开事件,判断该节点是否需要加载(检查子节点是否为占位节点),若需要则触发 loadDirectory()。
未展开的目录永远不会发起 ADB 请求。这对于 /data/data/ 下某些 App 的深层级目录结构(如 WebView 缓存、复杂嵌套的 files/ 目录)尤为重要——可以避免首次加载时的长时间阻塞。
自定义节点渲染(FileTreeCellRenderer)
通过继承 DefaultTreeCellRenderer 实现 FileTreeCellRenderer,根据节点 HashMap 中的 isDirectory 字段区分目录与文件:
• 目录:渲染为系统文件夹图标( Tree.openIcon/Tree.closedIcon,根据展开状态切换)• 文件:渲染为默认叶子节点图标
节点数据通过 HashMap 存储,每个节点携带三个字段:name(文件名)、path(完整路径)、isDirectory(是否目录),避免了通过节点文本反推路径的不可靠做法。
ls -l 解析
ADB 返回的文件列表通过 ls -l 获取,按空白字符分割后:
• 第 0 字段:权限位(如 drwxrwx--x),首个字符为d表示目录• 第 7 字段及之后:文件名(因为时间字段长度不固定,不能按固定索引截取)
这是一个在实际 ADB 输出解析中容易出错的细节,插件通过 '\n'.join(parts[7:]) 正确拼接文件名,支持包含空格的文件名。
4. 文件内容预览与二进制检测
选中文件节点后,readFileContent() 被触发。由于私有目录的权限限制,读取流程必须经过四步:
Step 1: su -c "cp <src> /data/local/tmp/<filename>" 将目标文件以 Root 权限复制到 tmp 目录Step 2: su -c "cat /data/local/tmp/<filename>" 读取 tmp 目录中的文件内容Step 3: 内容渲染到 JTextPane(StyledDocument) 若文件过大(>100KB),在此步截断Step 4: su -c "rm /data/local/tmp/<filename>" 清理 tmp 中的副本,避免残留二进制文件检测采用双重启发式策略:
1. 扩展名黑名单: .db、.sqlite、.sqlite3、.apk、.zip、.bin等直接判定为二进制,提示用户使用下载功能2. 内容采样:遍历文件内容的前 N 个字节,统计不可打印字符(ASCII < 32 且非空白字符)的占比,超过 10% 判定为二进制
单文件预览上限设为 100KB,超出部分自动截断。这个限制是经过权衡的:JTextPane 对大文本内容的渲染性能随文本长度非线性下降,100KB 是在渲染流畅性和内容完整性之间的一个合理平衡点。
文件内容展示使用 JTextPane 而非 JTextArea,原因是 JTextPane 基于 StyledDocument,支持富文本渲染(不同段落可以有不同的字体、颜色、背景),这为后续的敏感信息高亮提供了基础能力。
5. 敏感信息检测与高亮渲染
这是插件在安全测试场景中最具价值的能力。文件内容在 JTextPane 中展示时,highlightSensitiveInfo() 方法使用预定义的正则规则集对全文进行扫描,匹配到的内容以红色粗体 + 黄色背景在原文中直接标注,并在匹配内容前插入 [SENSITIVE:<类别>] 标签,使安全测试人员可以直观定位敏感数据。
检测规则集
api[_-]?key[_-]?=?\s*[a-zA-Z0-9]{20,} | ||
secret[_-]?=?\s*[a-zA-Z0-9]{20,} | ||
private[_-]?key[_-]?=?\s*[a-zA-Z0-9]{20,} | ||
access[_-]?key[_-]?=?\s*[a-zA-Z0-9]{20,} | ||
password[_-]?=?\s*[a-zA-Z0-9!@#$%^&*()_+]{6,} | ||
pass[_-]?=?\s*[a-zA-Z0-9!@#$%^&*()_+]{6,} | ||
pwd[_-]?=?\s*[a-zA-Z0-9!@#$%^&*()_+]{6,} | ||
token[_-]?=?\s*[a-zA-Z0-9_-]{15,} | ||
auth[_-]?=?\s*[a-zA-Z0-9_-]{15,} | ||
session[_-]?id[_-]?=?\s*[a-zA-Z0-9_-]{15,} | ||
\d{4}[- ]?\d{4}[- ]?\d{4}[- ]?\d{4} | ||
[1-9]\d{5}(19|20)\d{2}(0[1-9]|1[0-2])... | ||
1[3-9]\d{9} | ||
https?://[^\s]+ | ||
\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3} | ||
\d{10,20} | ||
AKIA[0-9A-Z]{16} | ||
eyJ[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+\.[a-zA-Z0-9_-]+ |
高亮渲染实现
高亮基于 StyledDocument(JTextPane 的底层文档模型)实现。具体流程:
1. 收集所有正则匹配的 (start, end, category)三元组2. 按 start位置排序3. 遍历三元组,分段插入文档: • [last_pos, start):插入普通文本,应用normalStyle• [start, end):插入[SENSITIVE:<category>] <匹配内容> [/SENSITIVE],应用sensitiveStyle(红色粗体 + 黄色背景)4. 最后插入剩余文本
StyledDocument 的 insertString() 方法每次写入时会附带一个 AttributeSet 参数,通过预初始化的 normalStyle 和 sensitiveStyle 两个 SimpleAttributeSet 对象实现不同段落的不同渲染样式。
所有 Style 对象在 __init__() 中预初始化,避免在 highlightSensitiveInfo() 被调用时因 StyledDocument 尚未初始化而触发 AttributeError。
6. 文件与目录下载
下载功能同样需要绕过私有目录权限限制,采用经典的四步中转方案:
Step 1: su -c "cp <src> /data/local/tmp/<filename>" 以 Root 权限复制到 tmp 目录Step 2: su -c "chmod 644 /data/local/tmp/<filename>" 修改文件权限,使 adb pull 可读Step 3: adb pull /data/local/tmp/<filename> <local_path> 拉取到本地Step 4: su -c "rm /data/local/tmp/<filename>" 清理 tmp 中的副本目录下载额外处理压缩打包:先将目录 cp -r 复制到 tmp,然后尝试执行 zip -r 打包;若设备未安装 zip 命令(部分精简 ROM 会移除),自动 fallback 到 tar -czf 生成 .tar.gz 压缩包。
下载路径支持两种模式:
• 默认路径模式:通过 JFileChooser(目录选择模式)预设下载目录,后续下载操作自动存入该目录,文件名冲突时自动追加_1、_2后缀• 每次选择模式:未设置默认路径时,每次下载都弹出 JFileChooser(文件选择模式),由用户指定保存位置
AI 辅助开发模式
本插件是采用 AI 辅助开发模式完成的系列安全工具中的一个。整体开发流程不依赖人工编写代码,而是通过将需求、架构设计和问题反馈以自然语言形式描述,由 AI 完成编码、调试和迭代。
以下是几个在实际操作中验证有效的关键做法。
需求描述需要精确到实现层
AI 生成代码的质量上限,取决于需求描述的精确程度。笼统的描述(如"帮我写一个 Burp 插件")通常只能得到骨架代码,且关键技术选型(如 Jython 环境下 Swing 线程模型、ADB 命令的具体格式)往往不准确。
有效的需求描述应当包含:
• 运行环境:明确是 Jython 2.7、Burp Extender API 的哪个版本 • 关键技术选型:明确使用 JTree而非JList、使用StyledDocument而非纯文本组件• ADB 命令格式:明确使用 su -c提权,而非假设 adb 本身具备 Root 权限• 边界条件:文件大小上限、二进制检测策略、日志行数上限等
这种描述方式的好处是:AI 的首次输出就已经在正确的技术路线上,后续修改量大幅减少。
利用错误日志驱动调试
Jython 环境下 Swing 的线程模型非常特殊——所有 UI 操作必须在 EDT 上执行,否则插件会静默崩溃或抛出 NullPointerException。这类问题在首次实现时几乎不可能完全规避。
实际做法是:在 Burp 的 Extender 面板中查看控制台输出,将完整报错复制给 AI,要求其分析原因并给出修复方案。AI 通常能准确识别 Swing 线程安全问题,并给出正确的 SwingUtilities.invokeLater() 封装方案。
不需要自己调试,错误日志就是最好的反馈。
分模块迭代
一次性要求 AI 实现所有功能,代码质量往往不稳定。更可控的节奏是分模块逐步交付:
迭代 1:设备连接 + 文件树骨架(跑通基本流程)迭代 2:文件内容预览 + 二进制检测迭代 3:敏感信息高亮渲染迭代 4:文件/目录下载(含 zip/tar.gz fallback)迭代 5:日志区优化、下载路径设置、异常处理完善每个迭代完成后验证功能,再进入下一个。出问题容易定位,整体进度可控。
AI Code Review
代码完成后,将完整源码提交给 AI,要求其从以下几个维度进行审查:
• Swing 线程安全性 • 内存泄漏风险(如日志列表无上限增长) • 异常处理完整性(ADB 命令执行失败的各种分支) • 潜在的安全问题(如 shell=True带来的命令注入风险)
在这个插件的 Review 过程中,AI 发现了几个实际问题:logMessages 列表无上限增长(修复:超过 1000 行自动截断)、StyledDocument 未初始化时调用 remove() 会触发 AttributeError(修复:在 __init__() 中预初始化所有 Style 对象)。
小结
本插件已经在实际 Android 安全测试工作中投入使用。将 AI 辅助开发模式应用于安全工具构建,核心优势不在于替代人工编码,而在于大幅降低了从需求到可用工具的转化成本。
对于一个需求明确、边界清晰的工具类项目,AI 可以独立完成从架构设计、编码实现到调试修复的全流程。对开发者而言,真正需要的能力是:
• 对目标领域有足够深的理解,能够判断 AI 输出的代码是否正确、是否存在遗漏 • 能够将模糊需求拆解为 AI 可以逐步完成的具体任务 • 能够通过错误日志、运行结果和代码 Review,持续驱动 AI 向正确方向迭代
本文介绍的插件为 AI 辅助开发实践的其中一个案例。更多安全工具的 AI 开发实践,将在后续文章中继续分享。