 夜雨聆风
夜雨聆风AI 编程助手正在把“写代码”变得越来越快,但移动端开发里最容易被忽略的一步,依然是:代码到底有没有在真实设备上跑对?
一个页面能否打开、登录是否成功、弹窗有没有挡住按钮、列表滚动后状态是否还在——这些问题,光看代码回答不了。过去,开发者通常需要在模拟器或真机上手动点一遍;而 AI Agent 即使生成了改动,也常常只能根据代码推断结果。
开源项目 agent-device 想补上的,正是这段断层。它提供了一个面向 AI Agent 的设备自动化 CLI,让 Agent 能打开真实应用、读取当前界面、操作可见元素,并在必要时抓取调试证据。项目将自己定位为“移动应用的 AI Agent 验证层”。
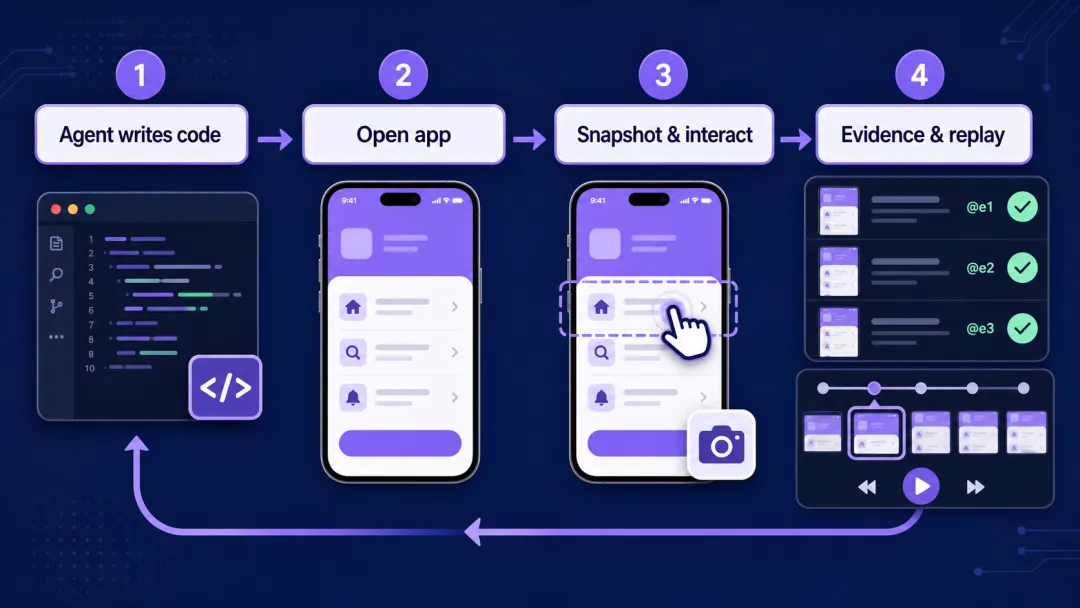
它解决的不是“怎么点”,而是“怎么确认真的发生了”
传统自动化测试并不缺工具:Appium、Detox、Maestro 都很成熟。但它们的典型前提是,测试工程师先把流程和断言写好,再让机器稳定地执行。
Agent-device 的设计起点不同:让一个正在开发的 AI Agent,像开发者一样探索设备、理解当前状态、完成操作,并把过程转成可验证的事实。
它会把界面转换成结构化的无障碍快照,并为可交互元素分配类似 @e1、@e2 的引用。Agent 不必从整张截图里猜“登录按钮大概在哪”;它可以先读取当前页面的元素,再对指定引用执行点击、输入、滚动等动作。页面变化后重新获取快照,继续下一步。
这种交互模型有两个实际价值:
●减少上下文消耗:优先给 Agent 结构化元素和语义引用,而不是反复传输大图、依赖视觉猜测。
●让操作可追溯:每一步都基于当前页面状态。遇到滚动、跳页或弹窗后重新快照,能降低“引用已经过期却还在盲点”的风险。
换句话说,它把“我觉得改好了”变成一条可执行的闭环:打开 App → 查看 UI → 操作 → 断言或留证 → 关闭会话。
一套 CLI,覆盖的不只是 iOS 和 Android
从 README 给出的能力看,agent-device 覆盖 iOS 模拟器、Android 模拟器和实体设备,也支持 tvOS、Android TV、macOS、Linux 桌面环境。只要目标应用能跑在其支持的设备或环境中,原生 iOS/Android、React Native、Expo、Flutter 应用都在其适用范围内。
这很重要。今天的移动团队往往不是只维护一个客户端:开发机上跑模拟器,CI 里跑 Android Emulator,验收时又落到实体机。工具链一旦分裂,Agent 的执行逻辑也会被迫分裂。agent-device 试图提供的是同一层命令接口,而不是要求团队按平台换一套“Agent 语言”。
最小的使用过程并不复杂:
终端 · 命令
$ # 安装并查看工作流帮助
$ npm install -g agent-device@latest
$ agent-device help workflow
$ # 找到目标应用并开启会话
$ agent-device apps --platform ios
$ agent-device open SampleApp --platform ios
$ # 读取可交互元素,再执行操作
$ agent-device snapshot -i
$ agent-device fill @e3 "test@example.com"
$ agent-device screenshot ./artifacts/settings.png
$ agent-device close
其中 snapshot -i 用来返回可交互元素。对于 Agent 而言,真正关键的不是命令数量,而是每条命令都能把“当前设备发生了什么”继续交还给它。
截图只是结果,证据链才是工程能力
移动端问题经常不是“页面看起来不对”这么简单。一次失败的登录,背后可能是请求异常、崩溃、渲染抖动、内存压力,或者某个系统弹窗打断了流程。
agent-device 除了截图和视频,还将日志、trace、网络流量、性能采样、崩溃上下文,以及 React Profile 纳入可采集的证据。需要时,它还能记录 .ad 工作流脚本,用于本地重放、CI 执行和可重复的端到端检查;也支持导出严格的 Maestro YAML。
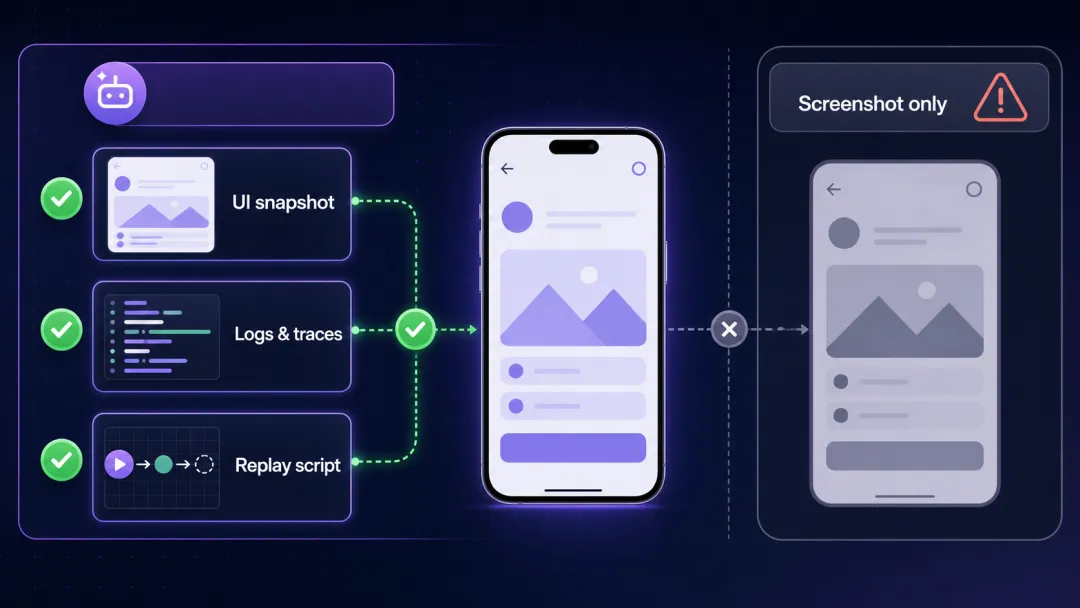
这意味着 Agent 不只是报告“测试失败”,还可以把失败现场交给人:当时屏幕长什么样、日志里有什么、流程走到了哪一步。对于 Code Review 或线上回归定位,这比一句模糊的“我试过了”有价值得多。
它会改变谁的工作方式?
第一类是使用 Codex、Claude Code、Cursor 等工具做移动端迭代的开发者。以前 Agent 的职责大多止于提交一份改动;现在可以把“启动应用、走一遍关键路径、附上证据”纳入同一任务。
第二类是 React Native、Expo、Flutter 的跨端团队。界面和业务代码改动频繁,人工冒烟测试容易变成最后一道瓶颈。把高频探索流程沉淀为可回放脚本,能让一次 Agent 的探索成为未来 CI 的资产。
第三类是需要把 AI 纳入质量流程的工程团队。前提是不要把它当成“自动化测试的替代品”。更合适的定位是:让 Agent 负责开发过程中的探索、验证和证据采集;关键业务、稳定回归和发布门禁,仍应保留明确的测试用例与质量标准。
上手前,需要看清三个边界
一是环境准备。 项目要求 Node.js 22+;iOS、tvOS、macOS 目标需要 Xcode,Android 依赖 Android SDK 与 ADB,macOS 桌面自动化还需要开启辅助功能权限。设备控制不是纯 npm 安装能完成的事。
二是可访问性质量。 语义化快照依赖应用暴露的无障碍信息。按钮名称、输入框标签、组件层级越清楚,Agent 的操作越可靠。这也是一个很直接的提醒:无障碍做好了,自动化与 AI 可用性会一起变好。
三是验证策略。 AI Agent 适合承担探索式验证,但不要把它包装成“无需测试工程”的捷径。稳定的 CI 仍需要明确的测试数据、断言、隔离策略和失败归因机制。
真正的变化:让 Agent 获得设备反馈回路
从代码仓库到真实设备,过去是一段需要人来补的链路。agent-device 的价值,在于把这段链路暴露成 Agent 能理解、能操作、能留证的接口。
当 AI 能写代码、能读日志、也能亲自打开 App 走一遍流程时,开发闭环才更接近完整。它未必会取代现有测试框架,却很可能成为移动端 AI 编程工作流里那个越来越基础的组件:让 Agent 不只会“写”,还能够“验”。
