 夜雨聆风
夜雨聆风
OpenSpec 表面上是在让你多写几份 Markdown。
这说法没错,但太浅。它做的事,是把一句聊天里的需求,拆成 proposal、spec、design、tasks,再让 CLI 去校验这些文件有没有成形。
对 AI Coding 来说,这比“文档规范”重要得多。Agent 最怕的不是不会写代码,而是一路写下去以后,需求漂了、边界丢了、验收标准变成了上一轮聊天里的半句话。
强 Agent 也怕一句话需求
AI Coding 很多失败,不是模型不会写。
而是它写着写着,已经不知道自己在兑现哪个需求。
真实项目里,一个需求通常不是一句“加个暗色模式”那么简单。它会慢慢膨胀成:
为什么要做?影响哪些能力?现有行为怎么改?哪些行为不能动?怎么验收?如何迁移?哪些任务可以并行?什么时候算完成?如果这些东西只在聊天历史里,Agent 就会依赖上下文窗口。
上下文一长,噪声上来。
中途 compact 一次,细节丢一截。
换一个会话,前面的判断基本没了。
OpenSpec 要解决的就是这个问题。
它的 README 把项目定义成一个 spec-driven development 工具,但我更愿意把它说成:
给 AI Coding 加一层规格合同。合同这个词比“文档”更准确。
文档可以只负责记录。合同会约束后续动作。
OpenSpec 不是让你多写几个 Markdown 文件给领导看,而是把需求、规格、设计、任务变成 Agent 可以读取、更新、校验、归档的工程 artifact。
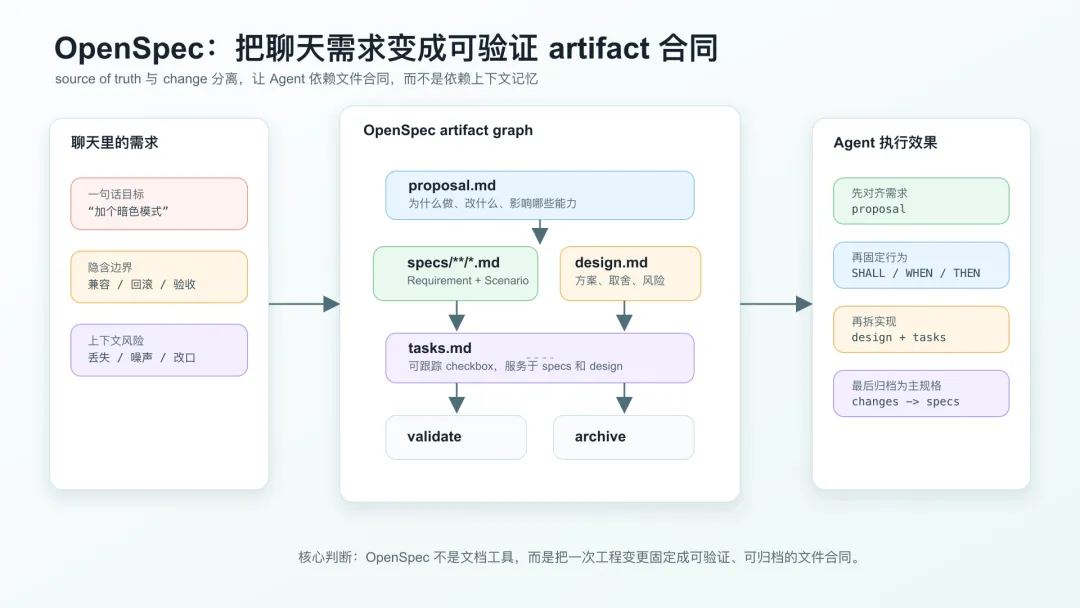
OpenSpec 默认在项目里创建一个 openspec/ 目录:
openspec/ config.yaml specs/ changes/ archive/这个结构比 README 里的宣传语更重要。
specs/ 是当前系统行为的 source of truth。
changes/ 是还没合并进主规格的变更。
这两个目录的分离,是 OpenSpec 的设计重心。
它不是让 Agent 直接改一份“大需求文档”,而是把“现在是什么样”和“这次要怎么改”分开:
当前系统规格:openspec/specs/*本次变更提案:openspec/changes/<change>/*这和 Git 分支的思想很像。
主规格是主线。
change 是变更分支。
archive 是合并记录。
需求不再漂在聊天里,而是进入一个可追踪的目录结构。
schema.yaml 才是流程入口
OpenSpec 默认 schema 在 schemas/spec-driven/schema.yaml。
它定义了四类 artifact:
proposal.mdspecs/**/*.mddesign.mdtasks.md每个 artifact 都有自己的职责。
proposal.md 回答为什么要做、改什么、影响什么能力。
specs/**/*.md 回答系统应该表现出什么行为。
design.md 回答怎么实现、为什么这么设计、风险怎么处理。
tasks.md 回答实际执行步骤,且要求用可追踪 checkbox。
更值得看的是依赖关系:
proposal -> specsproposal -> designspecs + design -> taskstasks -> apply这不是普通目录约定。
这是一个 artifact graph。
Agent 如果跳过 proposal,后面的 specs 就缺少“为什么”和“影响范围”。
Agent 如果跳过 specs,tasks 就容易只服务实现,而不是服务行为合同。
Agent 如果跳过 design,复杂变更就会变成边写边猜。
这个 graph 的价值在于:让需求推进有结构,而不是靠模型自觉。
如果把 OpenSpec 当成状态机看,它的流程更像这样:
idea -> proposal -> delta spec -> design -> tasks -> implementation -> validate -> archive -> updated specs这个状态机不是为了让流程显得正规,而是为了把“需求还在讨论”和“需求已经变成系统行为”分开。
很多 AI Coding 失败就卡在这件事上。用户刚说一个想法,Agent 立刻开始改代码;改到一半发现影响面没想清楚,又在聊天里补解释;最后代码、需求、验收标准散在不同消息里。OpenSpec 的做法更慢一点,但它把中间状态落到了文件系统里。
慢的这一步,换来的是后面可恢复、可审查、可归档。
CLI 的 init 流程:先识别宿主,再生成技能和命令
src/cli/index.ts 是 OpenSpec CLI 入口。
初始化走 openspec init,最后会调用 src/core/init.ts 里的 InitCommand。
这个类做了几件很明确的事:
1. 校验目标目录是否可写2. 检查 legacy artifact 并清理3. 检测项目里有哪些 AI 工具目录4. 让用户选择或用 --tools 指定工具5. 创建 openspec/specs 和 openspec/changes6. 给选中的工具生成 skills 和 commands7. 写入 openspec/config.yaml这里有一个细节很值得看。
OpenSpec 并没有只支持 Claude Code。src/core/config.ts 里维护了一个 AI_TOOLS 列表,里面有 Claude Code、Codex、Cursor、OpenCode、Cline、Gemini CLI、Kiro、Continue、GitHub Copilot 等很多工具。
每个工具有自己的 skillsDir:
{ name: "Claude Code", value: "claude", skillsDir: ".claude" }{ name: "Codex", value: "codex", skillsDir: ".codex" }{ name: "OpenCode", value: "opencode", skillsDir: ".opencode" }{ name: "Cline", value: "cline", skillsDir: ".cline" }OpenSpec 没有把自己做成某个 IDE 的插件,而是把 spec workflow 投递到多个 AI Coding Harness。
它交付的不是 UI,而是:
工具能加载的 skills工具能识别的 slash commands项目里的 openspec artifact这和 Superpowers、ECC 的思路很接近:能力外置,宿主适配。
skill 和 command 生成:同一套流程,投递到不同宿主
InitCommand.generateSkillsAndCommands() 里有一个很清楚的分支:
const shouldGenerateSkills = delivery !== "commands";const shouldGenerateCommands = delivery !== "skills";const skillTemplates = shouldGenerateSkills ? getSkillTemplates(workflows) : [];const commandContents = shouldGenerateCommands ? getCommandContents(workflows) : [];然后它会对每个选中的工具生成对应文件:
<tool.skillsDir>/skills/<workflow>/SKILL.md<tool command path>/<command>.md背后的设计很现实:
OpenSpec 不假设所有宿主都有同一种能力入口。有的宿主更适合 skills。有的宿主更适合 slash commands。有的两者都支持。同一个 propose workflow,在 Claude Code、Codex、OpenCode 里可能落盘路径不同,但语义应该一致。
跨工具生态难就难在这里。
不是写一个 Markdown 模板难。
难的是让同一套语义,在不同 Harness 的加载机制里保持一致。
spec 不是说明书,是可验证结构
OpenSpec 的 spec 格式很严格。
schema 里要求 requirement 和 scenario:
### Requirement: User can export dataThe system SHALL allow users to export their data in CSV format.#### Scenario: Successful export- **WHEN** user clicks "Export" button- **THEN** system downloads a CSV file with all user data这几个词别忽略:
RequirementSHALL / MUSTScenarioWHEN / THEN这些不是为了显得正式。
它们让需求具备可验证性。
如果你只写:
导出功能要好用。Agent 没法判断“好用”是什么。
如果你写:
WHEN 用户点击导出THEN 系统下载包含全部用户数据的 CSV这就开始接近测试用例。
OpenSpec 押的是这件事:
AI Coding 不是缺代码生成,而是缺可执行的行为合同。没有合同,Agent 只会围绕最近的聊天内容补代码。
有合同,Agent 至少知道它要满足哪些场景。
delta spec:它面向 brownfield,而不是只面向新项目
README 里强调 OpenSpec 是 brownfield-first。
源码里也能看到对应实现。
Validator.validateChangeDeltaSpecs() 会读取 openspec/changes/<change>/specs/<capability>/spec.md,解析 delta section:
## ADDED Requirements## MODIFIED Requirements## REMOVED Requirements## RENAMED Requirements很多 spec 工具只适合新项目,因为它默认你从零描述整个系统。
但真实工程大部分都是改旧系统。
旧系统已经有行为,需求通常是:
新增一个行为修改一个旧行为删除一个废弃行为重命名一个能力OpenSpec 把这四类变化变成 delta。
所以它很适合 AI Coding 的 brownfield 场景。
Agent 不需要重写全量系统说明,只需要在 change 里写清楚这次变更对主规格的影响。
归档时再合并回 specs/。
这比“把所有需求都写在一个 README 里”靠谱得多。
validate:把“格式建议”变成失败条件
OpenSpec 的 Validator 在 src/core/validation/validator.ts。
它不只是检查文件存在,还会验证:
ADDED / MODIFIED requirement 是否有正文是否包含 SHALL / MUST是否至少有一个 scenario同一 section 是否重复不同 delta section 是否冲突主 spec 里是否出现不该出现的 delta header这层验证对 AI Coding 很实用。
模型很容易写出“看起来对”的 Markdown:
### Requirement: Export dataUsers can export data.### Scenario: Export CSVWhen user clicks export, CSV downloads.人看得懂,但机器校验可能失败。
OpenSpec 要求 scenario 用 ####,要求 requirement 用 SHALL / MUST,要求格式可解析。
这看起来有点吹毛求疵,但工程上是必要的。
因为后续 archive、apply、validate、自动化脚本,都不能靠“差不多能读懂”运行。
AI 写作最容易的问题就是“语义像对,结构不对”。
OpenSpec 用 validator 把这件事变成硬失败。
validate 的意义还不只是“防止格式写错”。
对 Agent 来说,它像一个外部裁判。模型可以解释自己为什么这么写,但 validator 只关心 artifact 是否满足结构约束。AI Coding 里最容易出问题的地方,往往不是语义完全错,而是“看起来像对”。
比如:
Requirement 写了,但没有 SHALL / MUSTScenario 写了,但层级不对,解析器识别不到ADDED 和 MODIFIED 同时改了同一项能力change 里写了 delta header,主 specs 里也混进了 delta header这些问题人肉审稿能看懂,但自动化链路接不住。
OpenSpec 的取舍很明确:宁愿让 Agent 多修一次 spec,也不要让一份不可解析的需求合同进入实现阶段。
再往执行层看,OpenSpec 不是只有“写规格”这一条路。
apply-change workflow 会先跑 openspec status --change "<name>" --json,再跑 openspec instructions apply --change "<name>" --json。返回结果里有 contextFiles、任务进度、剩余任务和动态指令。Agent 不是凭聊天记忆去实现,而是先读 proposal、specs、design、tasks,再按 tasks 推进。
这一步有两个细节值得看。
第一,任务完成不是嘴上说完,而是把 tasks.md 里的 checkbox 从 - [ ] 改成 - [x]。也就是说,状态推进被写回 artifact。
第二,如果 status 发现是 workspace-planning 且 allowedEditRoots 为空,workflow 要求停止编辑,把 linked repo / folder 当只读上下文。这说明 OpenSpec 已经意识到“规划”和“执行”不是同一个权限边界。
还有另一条路径叫 sync-specs。它不是归档 change,而是让 Agent 读取 delta spec 和 main spec,把 ADDED / MODIFIED / REMOVED / RENAMED 合并到主规格里。这里的设计很有意思:OpenSpec 没有完全用程序做机械 merge,而是把“智能合并”交给 Agent,同时给出明确规则,比如 MODIFIED 可以只加 scenario,但要保留 delta 没提到的既有内容。
这就把 OpenSpec 的定位讲清楚了:
schema 负责结构validator 负责硬失败apply 负责任务状态推进sync/archive 负责规格归并Agent 负责理解和合并意图它不是把 Agent 赶出流程,而是把 Agent 关进一个有 artifact、有状态、有校验的流程里。
一个真实场景:分页 bug 该怎么走
假设我们在后台系统里修一个分页 bug。
现象是:
订单列表按创建时间倒序分页。如果两条订单创建时间相同,翻页时会重复或漏数据。如果只让 Agent 直接修,它可能会改 SQL:
ORDER BY created_at DESC, id DESC这个修复可能对,但需求没有被固定下来。
下次别人改排序,bug 可能回来。
按 OpenSpec 的方式,应该先创建 change:
openspec change create stabilize-order-pagination然后 proposal 写清楚:
## Why订单列表分页在相同 created_at 下不稳定,用户翻页时可能看到重复订单或漏订单。## What Changes- 订单列表分页排序必须使用稳定排序键。- 主排序字段相同的时候,必须使用唯一字段作为 tie-breaker。## Impact- Order query- Pagination API- Existing order-list specdelta spec 可以这样写:
## MODIFIED Requirements### Requirement: Order list pagination is stableThe system MUST return a stable order list across pages when multiple orders share the same created time.#### Scenario: Orders with same created time- **WHEN** two orders have the same `created_at`- **THEN** pagination MUST use `id` as a deterministic tie-breaker- **AND** no order appears on two pages for the same querytasks 再拆:
- [ ] 1.1 Add failing test for duplicate created_at pagination- [ ] 1.2 Update query ordering to created_at desc, id desc- [ ] 1.3 Add regression test for page boundary- [ ] 1.4 Run API test suite这时候 Agent 写代码只是后半段。
收益在于:bug 被转成了行为合同。
未来代码怎么改,都要满足这个 spec。
它不会替你思考
OpenSpec 也不是银弹。
它解决的是需求和过程漂移,不解决所有工程问题。
如果 proposal 写错,后面会稳定地沿着错误方向执行。
如果 spec 场景太少,Agent 仍然可能漏边界。
如果 design 只是空话,tasks 仍然会变成机械清单。
所以使用 OpenSpec 时,我会盯三件事:
proposal 有没有说清楚为什么做;spec 有没有落到可测试场景;tasks 有没有变成可验收动作。不是文件齐了就行。
OpenSpec 让“缺什么”变得更容易看见,但它不会自动替你思考。
和 Prompt、AGENTS.md、Skill 的关系
OpenSpec 容易和几类东西混在一起。
Prompt 解决的是单次输入表达。
AGENTS.md 解决的是项目级常驻规则。
Skill 解决的是某类任务的工作流。
OpenSpec 解决的是一次工程变更的 artifact 合同。
可以这样分:
Prompt:这次你要做什么AGENTS.md:这个项目长期怎么做事Skill:遇到这类任务该走什么流程OpenSpec:这次变更的需求、规格、设计、任务和归档记录是什么四者不是替代关系。
它们刚好处在不同生命周期。
如果一个团队已经有 AGENTS.md 和 skills,再引入 OpenSpec,重点不是重复写规范,而是把“本次变更”从聊天里拿出来。
我看重的是这套分层
OpenSpec 最值得借鉴的不是工具本身,是它的分层:
source of truth:当前系统行为change:本次变更proposal:为什么做spec:做成什么行为design:怎么做tasks:怎么落地validate:结构是否合格archive:变更如何进入主规格这套模型对 AI Coding 很有用。
人类开发者可以靠脑子和会议纪要补很多缺口。
Agent 不行。
Agent 需要稳定的外部状态。它需要把聊天变成文件,把“好像说过”变成“可以读取和校验”。
规格合同的意义就在这里。
不是为了仪式感。
是为了让 Agent 不靠记忆工作。
资料来源
• Fission-AI/OpenSpec,源码快照:1b06fddd59d8e592d5b5794a1970b22867e85b1f,2026-06-03。• README.md:OpenSpec 定位、quick start、workflow 示例。• docs/concepts.md:specs/与changes/的分离模型、workspace 说明。• schemas/spec-driven/schema.yaml:proposal、specs、design、tasks artifact graph。• src/cli/index.ts:CLI 命令入口。• src/core/init.ts:初始化、工具检测、skills/commands 生成。• src/core/config.ts:AI tools 与 skillsDir 适配表。• src/core/validation/validator.ts:spec / change delta 校验逻辑。• src/utils/change-utils.ts:change name、schema、metadata 创建逻辑。
