 夜雨聆风
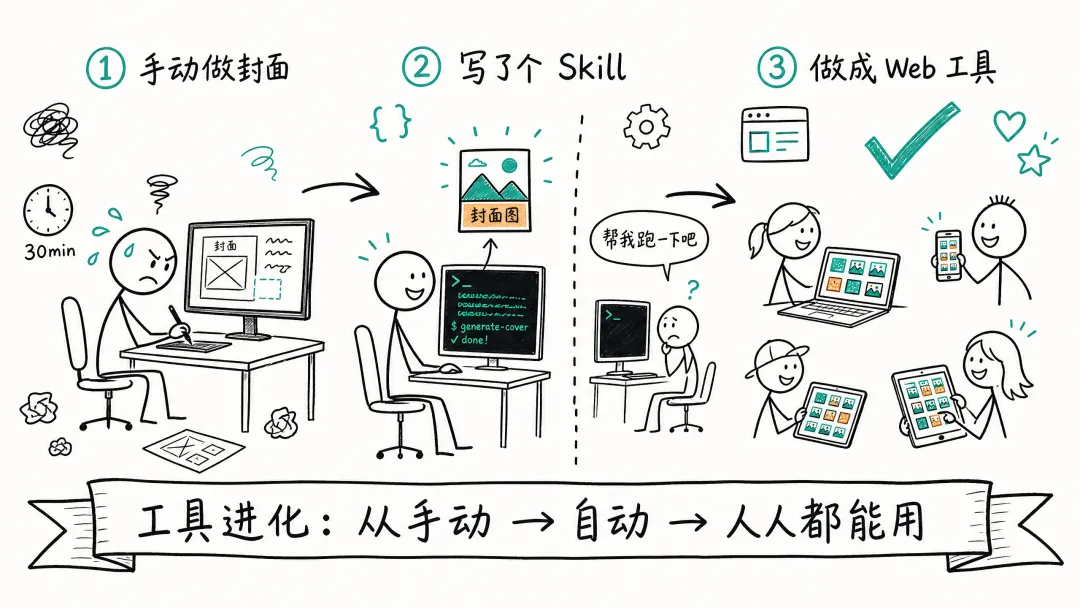
夜雨聆风做了快一年短视频,我发现一件挺尴尬的事:
花在做封面上的时间,快赶上写口播稿了。
不是夸张。每次视频录完,口播稿已经定好了,但封面这事儿就开始拧巴。选什么风格?标题怎么排?要不要加截图?上次用的那套布局,这次还能不能套?
后来我就写了一个 Skill,丢进去口播稿,它帮我自动分析内容要点,然后调 AI 生图接口,直接出一张封面。
效果确实不错。我自己用了好几个月,省了不少事。
但问题也来了。
一个人能用 ≠ 一个团队能用
我做内容不是一个人在干,团队里有小伙伴负责运营,有时候需要自己调封面、试不同方案。
这个 Skill 跑在 Agent 工具里,她试了一次之后说:"你直接帮我跑一下吧。"
这就尴尬了。工具是给人用的,如果只有我自己能用,那它就不是工具,它是我的私人助手。
还有个问题,之前的 Skill 只有一种封面风格。科技深色标题风,写代码教程的时候很搭,但如果是生活化的内容、产品测评、或者轻松的话题,那个风格就太硬了。
所以我想干两件事:
- 1.把封面风格从 1 种扩展到多种
- 2.把整套流程做成一个 Web 网站,不懂技术的人也能直接用
先别急着看怎么做的,我直接放一段最终效果的演示视频,你感受一下:
看完如果觉得"这东西我也想要",往下看怎么一步步搞出来的。
最近半个月我一直在 Qoder 上用 Qwen3.7-Max,写代码、调工作流、处理一些复杂任务,整体跑下来比较稳。所以这次升级封面系统,从识图分析到 Web 开发,全程也是用它来搞。
先解决风格问题:用 Qwen3.7-Max 的识图能力搞定
扩展封面风格这件事,听起来简单,做起来很容易翻车。
你想想,深色科技风、明亮 YouTuber 风、极简留白风、故障警示风……这些风格之间的差异,不是换个颜色就能搞定的。排版布局、文字层级、元素搭配、氛围感觉,全都不一样。
如果让模型凭空理解"明亮 YouTuber 风"是什么意思,大概率出来的东西跟你想的不一样。
所以我换了一种思路:给模型看参考图,让它自己总结风格特征。
不过在正式开干之前,我想先摸一下 Qwen3.7-Max 看图的底。毕竟识图和写代码是两码事,万一它看图看不出门道,后面都白搭。
我随手丢了一张我之前找的封面图进去,让它看看 references/styles/ 目录下现有的风格文件,然后分析这张图。

有意思的是,它不光看了风格文件,还自己跑去读了 brand_baseline 和 prompt_template——我没让它看这俩文件,它自己判断这些上下文对分析有用,主动去翻的。
然后输出了一张结构化的分析表:色调配色、文字排版、人物元素、背景处理、视觉情绪、适合内容,六个维度拆得很清楚。不是那种泛泛的"这是一张深色科技封面",而是具体到"标题占据画面中左部 40%""人物在右下角、手指向左下角气泡框"这种程度。
最后直接生成了一个 agent-hype.md,129 行,格式跟现有风格文件一致。
行,识图这块没问题。那就让它批量干活。
我的封面 Skill 里有一套风格定义体系——每种风格是一个 .md 文件,定义了色调、布局、字体、元素摆放、适用场景和 prompt 模板。在 Qoder 里模型可以直接读项目文件,所以思路很简单:丢一张参考图过去,让它自己去看现有风格文件的结构,然后按同样的格式输出一份新的风格定义。
我丢了一张新风格的参考图,给了这样一段 prompt:
看一下 references/styles/ 目录下现有的风格定义文件,学习它们的结构和字段格式。现在请分析我上传的这张参考图,重点关注以下维度:1. 整体色调和配色方案2. 文字排版布局(标题位置、字号层级、字体风格)3. 人物/元素的摆放方式4. 背景处理手法5. 视觉情绪关键词(3-5个)6. 适合什么类型的内容然后按照现有风格文件同样的结构,生成一份新的风格定义文件。要求:- 保持与现有风格文件完全一致的字段结构和格式- 从参考图中提取真实的配色、布局、字体、元素特征- prompt 模板部分要能直接用于 AI 生图- 风格名用英文 kebab-case 命名,适合做文件名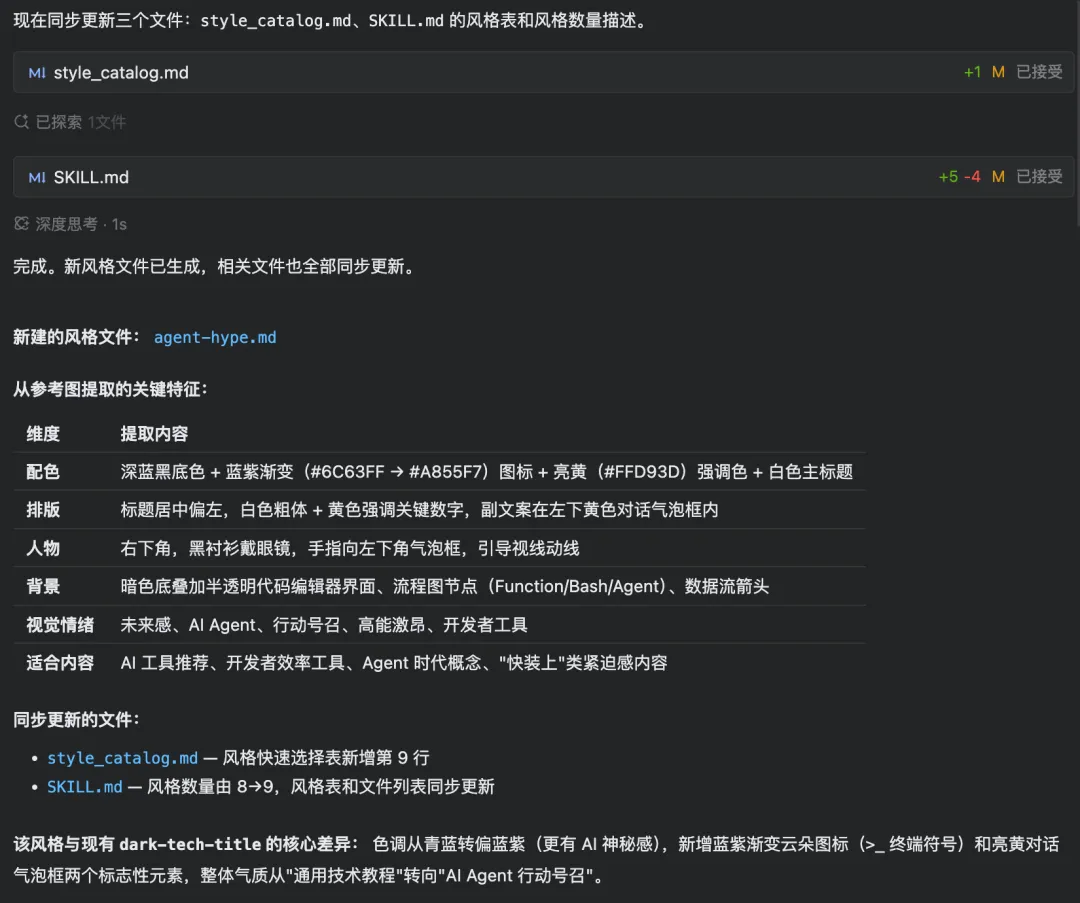
这里让我比较意外的是,之前测试的时候它只是主动读了几个配置文件。到正式扩写这一步,它做得更狠——分析完图、生成完风格定义文件之后,它自己发现新增一种风格不光要加 .md 文件,还要改注入脚本、更新 SKILL.md 里的风格列表,然后一口气把这些改动全做了。
这就省事了。我不用告诉它"你改完风格文件还要去改哪个脚本的第几行",它自己看完项目就知道了。
按这个方法,我一轮一轮喂参考图,每张图让模型分析一遍,然后跑一轮实际生图看效果,微调 prompt 模板,最终把风格库扩展到了 8 种。
直接看效果:








<<<左右滑动见更多>>>
到这步,风格扩展的问题算是解决了。
但你猜接下来我遇到了什么?
风格有了,问题还在:谁来用?
封面风格从 1 种变成 8 种之后,我自己用是更爽了。不同内容配不同风格,出片质感明显上了一个台阶。
但如果团队里其他人想用,他们得先装一个 Agent 工具,Claude Code、Codex、小龙虾,随便哪个。安装、配置、学基本操作,这个前置门槛对不搞技术的人来说就已经劝退了。
其实现在不管哪个 Agent 调 Skill,它都会提示你选风格的,不存在什么"搞不清楚参数"的问题。但前提是,你得先有一个 Agent 环境。
对于团队里负责运营的小伙伴来说,让她装一个命令行工具,本身就不现实。
所以真正的问题不是"Skill 难用",而是"Agent 工具的入口门槛太高"。
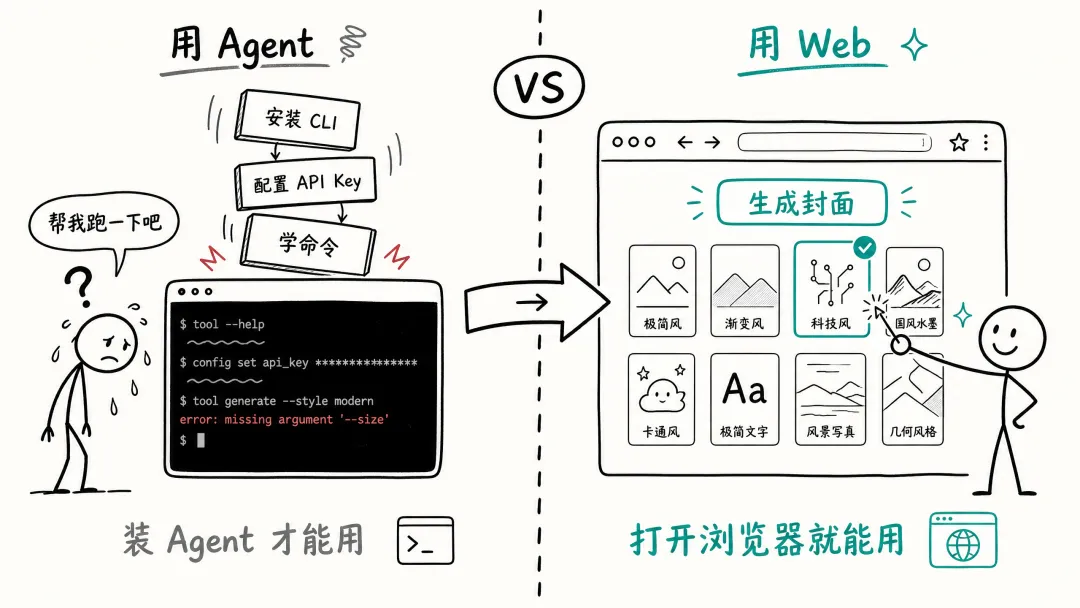
如果有一个 Web 界面,打开浏览器就能用,8 种风格直接用缩略图展示,点一下就选好了,粘贴口播稿、点生成——整个过程不需要知道什么是 Agent、什么是 Skill、什么是 prompt。
这才是我决定做 Web 版的真正原因。
需求很明确:
- 只需要粘贴口播稿,选个风格,点一下就能出图
- 每次生成的 prompt 要能看到(方便微调和复用)
- 要有历史记录,能找到之前跑过的结果做对比
- 要有收藏功能,好的封面一键收藏
- 模型和生图服务可以配置切换
- 所有数据要持久化存储,刷新了不会丢
这就不是改改 Skill 能搞定的事了。这得写一个完整的 Web 产品。
用 Qwen3.7-Max + Qoder 搓一个完整的 Web 工具
说实话,用 AI 辅助写代码这事我干了不少了。但这次的需求比之前复杂不少,不是一个单页面小工具,而是一个有状态管理、有持久化存储、有多个配置维度的完整应用。
我把整个需求拆成了几轮来跟模型沟通,不是一口气全丢进去,而是像跟一个开发搭档讨论一样,一步步打磨。
第一轮:基础框架
先把核心骨架搭起来。因为我已经有一套封面生成的 Skill 了,Web 版其实是给这套 Skill 加一个前端入口,所以第一步我需要让模型理解现有的项目:
我有一个视频封面生成的 Skill 项目(linyuebanzi-video-cover-generator),目前通过 Agent 命令行调用,现在要做一个 Web 前端。先看一下现有项目结构,特别是:- references/styles/ 下的风格定义文件- references/prompt_template.md(生图 prompt 模板)- references/brand_baseline.md(品牌视觉基线)基于这些已有资产,搭建一个 Web 应用:- 技术栈:React + TypeScript,暗色主题- 左侧:项目列表(历史项目、搜索、按文章/视频筛选)- 右侧上方:口播文案输入区- 右侧中间:风格选择器(读取 styles/ 目录下的风格,卡片展示,2行4列)- 右侧下方:生成结果展示区(每次出 2 张,支持复制/下载)- 顶部:模型选择下拉 + 生成按钮- 生成逻辑复用现有 Skill 的 prompt 模板和风格定义- 所有数据持久化到本地 SQLite(项目、生成记录、收藏、配置), 不用远程数据库,单机跑就行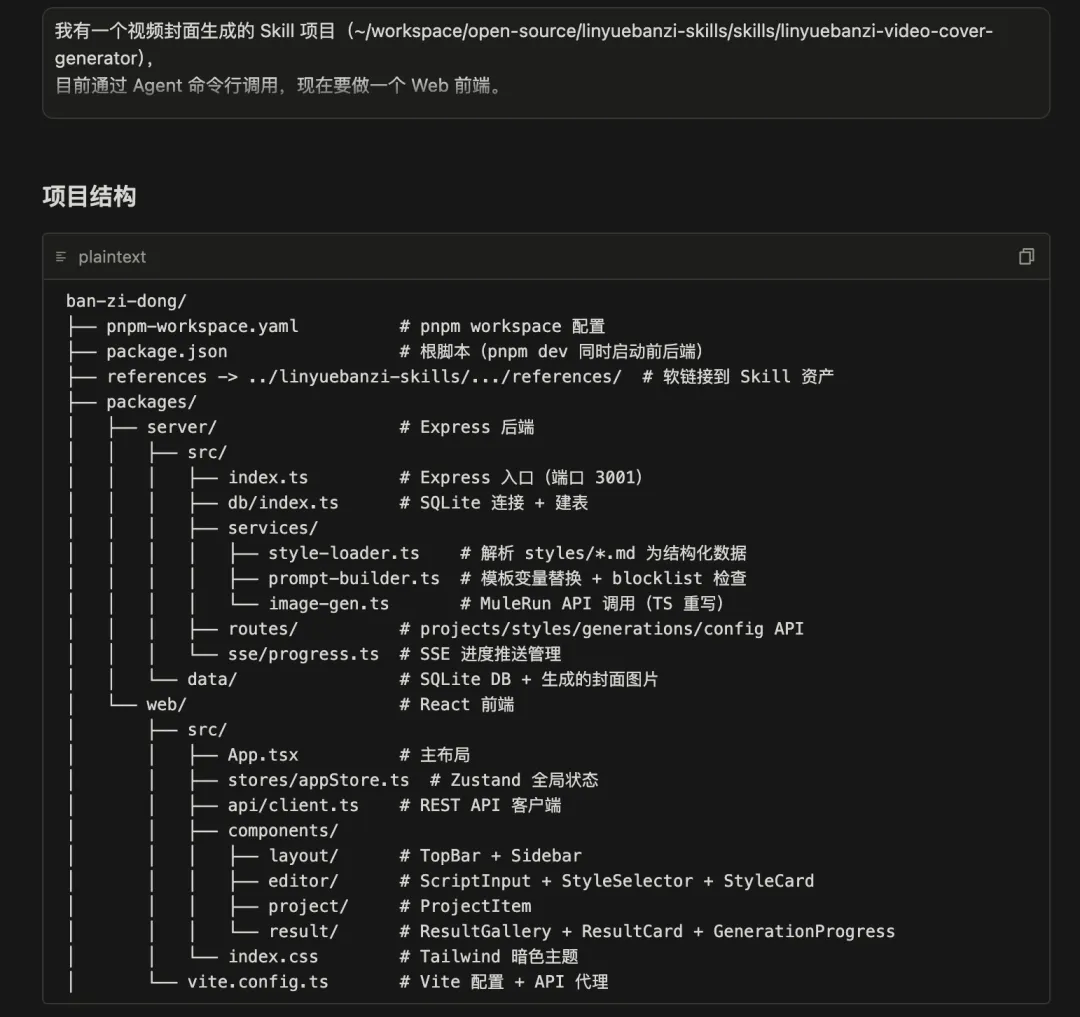
Qwen3.7-Max 第一轮就给了一个相当完整的项目结构。因为它读了现有的 Skill 文件,所以不是从零开始猜,组件拆分、数据模型、和现有风格文件的对接思路都有了。。
直接跑起来看看:
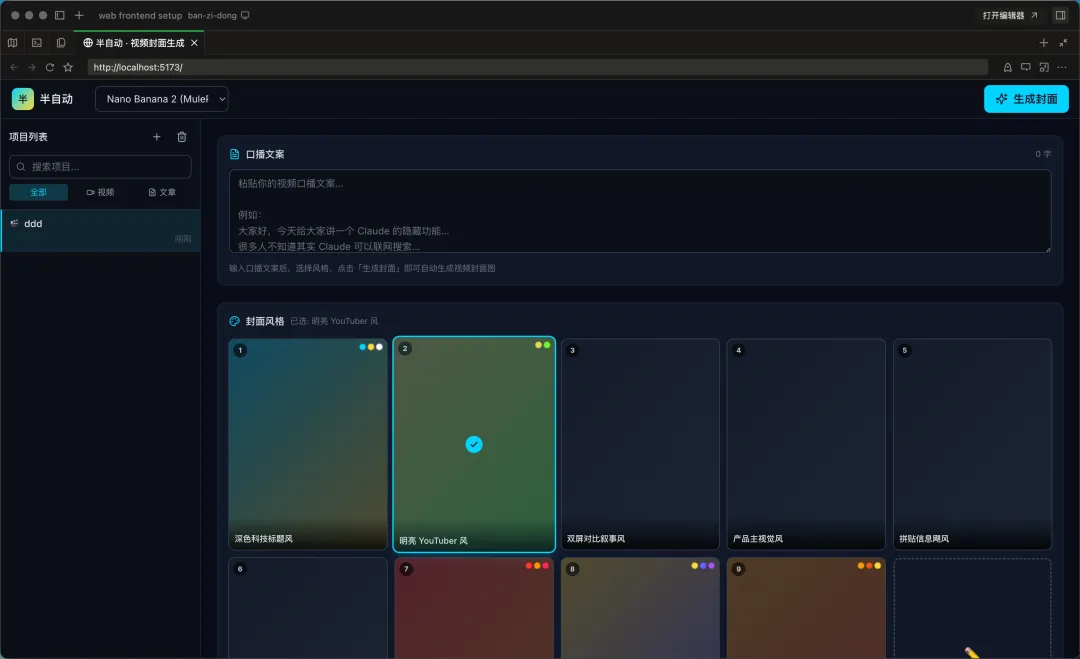
基本骨架已经有了。左侧项目列表、右侧口播文案输入区、风格卡片选择器、顶部模型切换和生成按钮,布局跟我预想的差不多。接下来就是一轮轮打磨细节。
但是,跑了一下生成,出来的封面标题全是 {{顶部主标题}}{{辅助小标题}} 这种占位符。
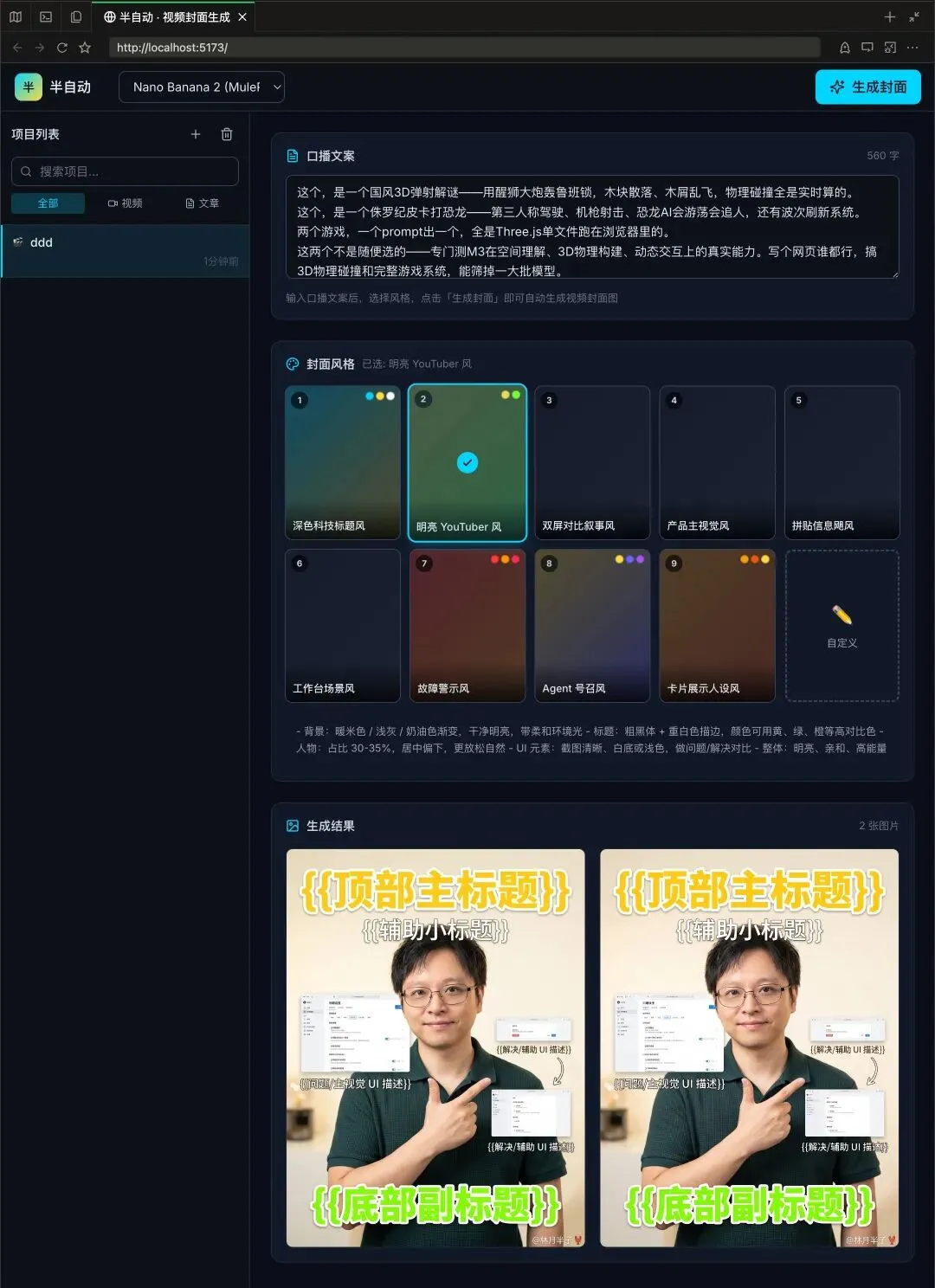
原因很明显:生成流程还没接 LLM,没有模型来读口播稿、提炼标题要点。封面模板是对的,但"往模板里填什么内容"这一步还是空的。
所以第二轮不是去调 UI 细节,而是先把模型配置搞定,让整个生成链路跑通。
第二轮:接入模型,让封面内容活起来
第一轮跑出来的封面,模板和风格都对,但标题全是占位符。原因很简单——还没有接 LLM 来分析口播稿。封面上该写什么标题、什么副标题、突出哪些关键词,这些都需要一个模型来从文案里提炼。
所以第二轮的重点是:搭一个模型配置面板,让用户选择用哪个 LLM 来做内容提取,然后把提取结果填进封面模板。
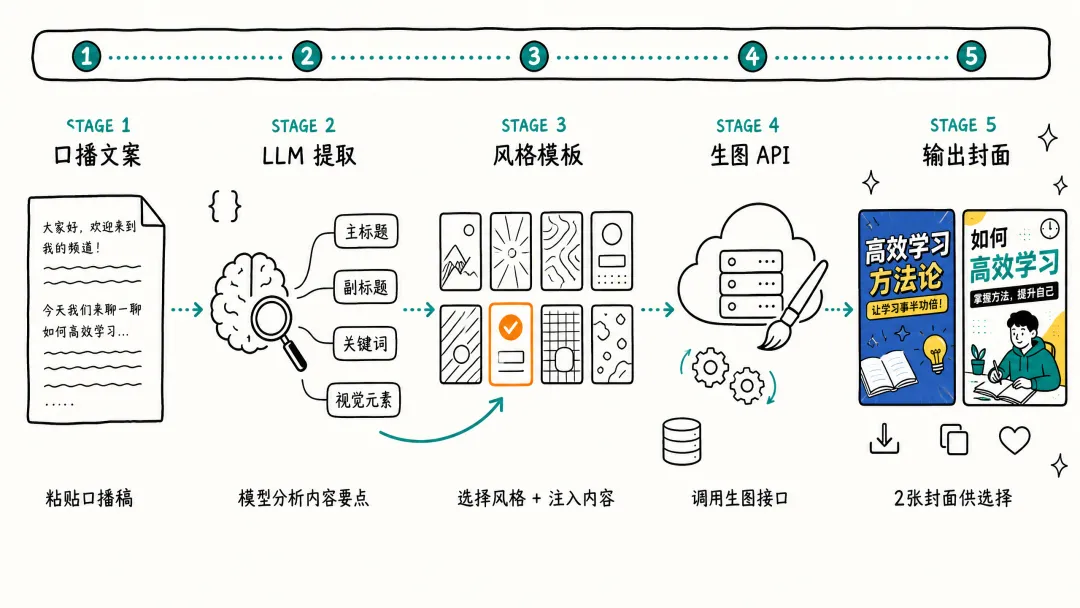
需要一个"模型与生图设置"面板:1. 内容提取模型配置: - Provider 下拉:Anthropic Claude / DeepSeek / MiniMax / Kimi / 千问 / OpenAI / 自定义 OpenAI 兼容 - 每个 Provider 自动填充默认的 Base URL - 模型名称输入框(如 deepseek-chat、qwen-max 等) - API Key 配置(密码形式,已配置的显示末四位)2. 生成流程:用户点"生成封面"时,先调这个模型分析口播稿, 提取主标题、副标题、核心卖点、视觉元素关键词, 再把提取结果注入风格 prompt 模板,最后调生图 API 出图3. 配置持久化到 SQLite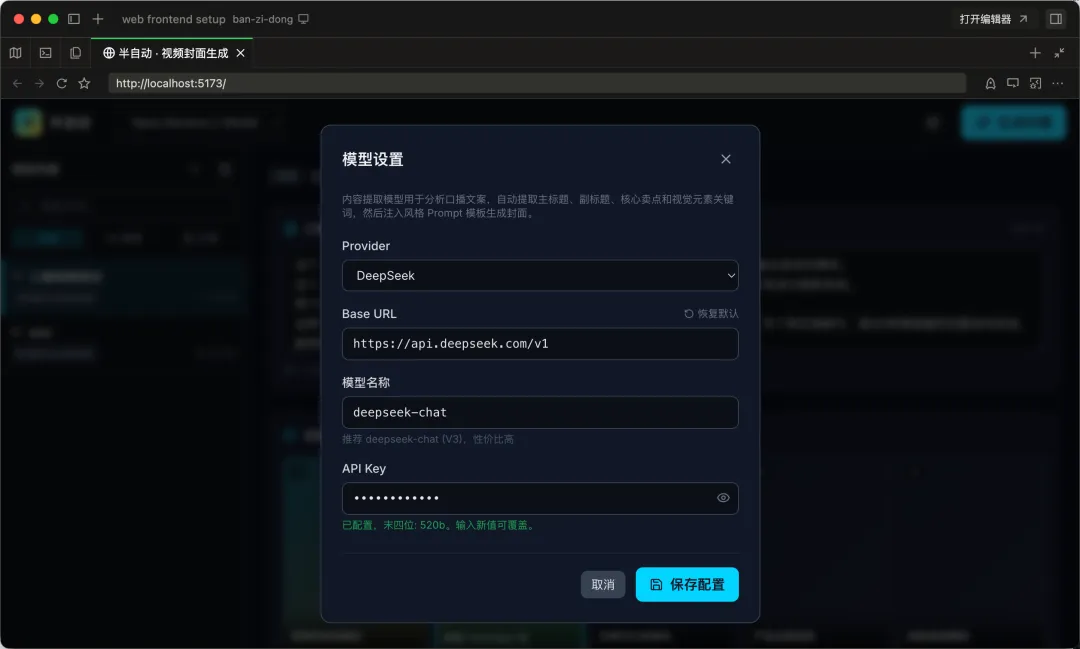
配好模型之后再跑一次,这回封面上的标题终于是从口播稿里提取出来的真实内容了。
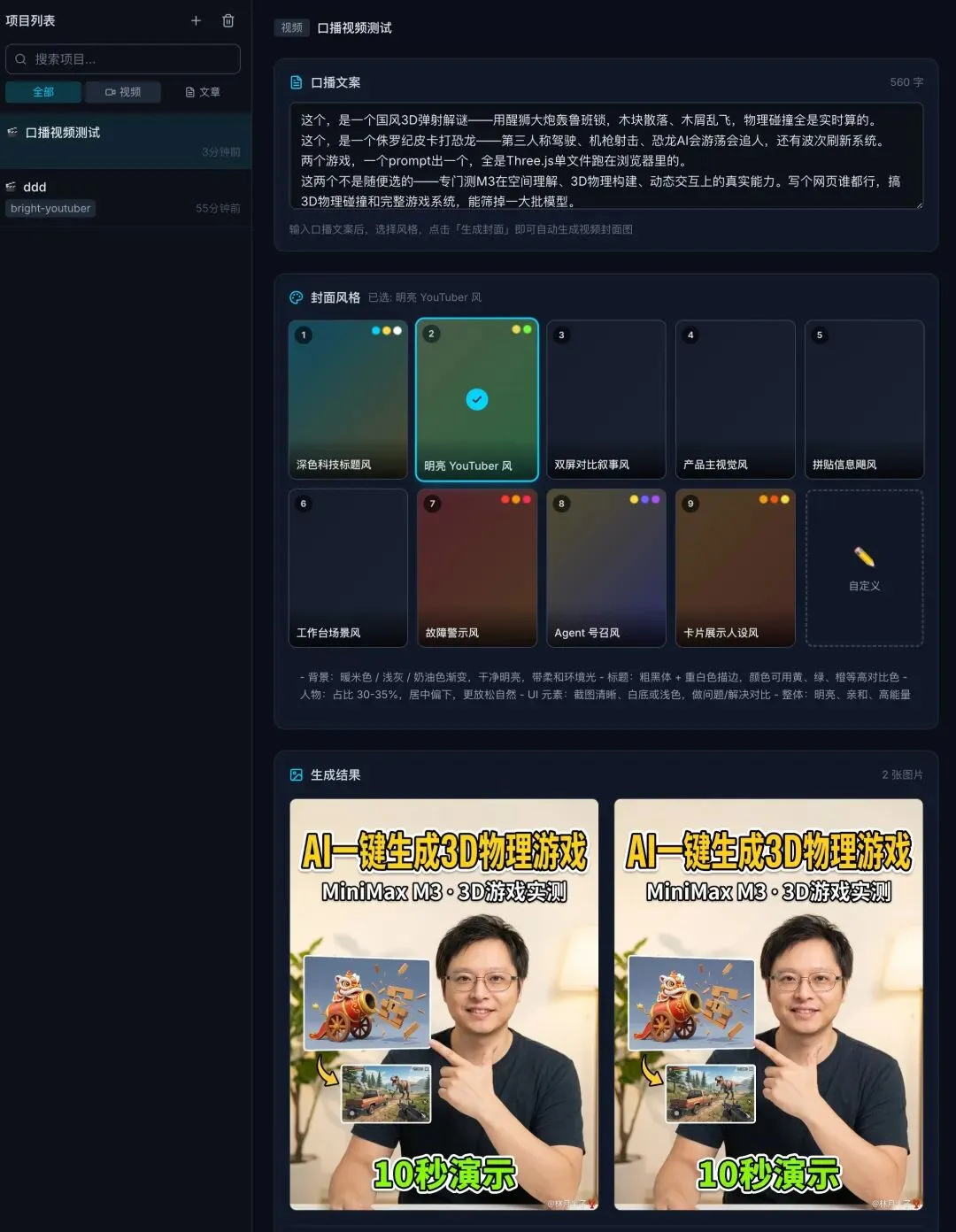
第三轮:历史记录和收藏系统
这是整个应用里最核心的功能之一。我希望每次生成的结果都不会丢失,而且能按时间线回溯、对比、收藏。
需要一个历史记录和收藏系统:1. 收藏列表: - 在生成结果区顶部设一个"我的收藏"板块 - 收藏的封面单独展示,带复制/下载按钮 - 跨项目收藏,所有项目的收藏汇总在一起2. 历史生成记录: - 按时间倒序展示,每条记录包含:序号、时间戳、耗时、 状态标签(完成/出错) - 每条记录下方展示该次生成的 2 张封面 - 可折叠查看该次使用的生图 prompt3. 数据走 SQLite,刷新不丢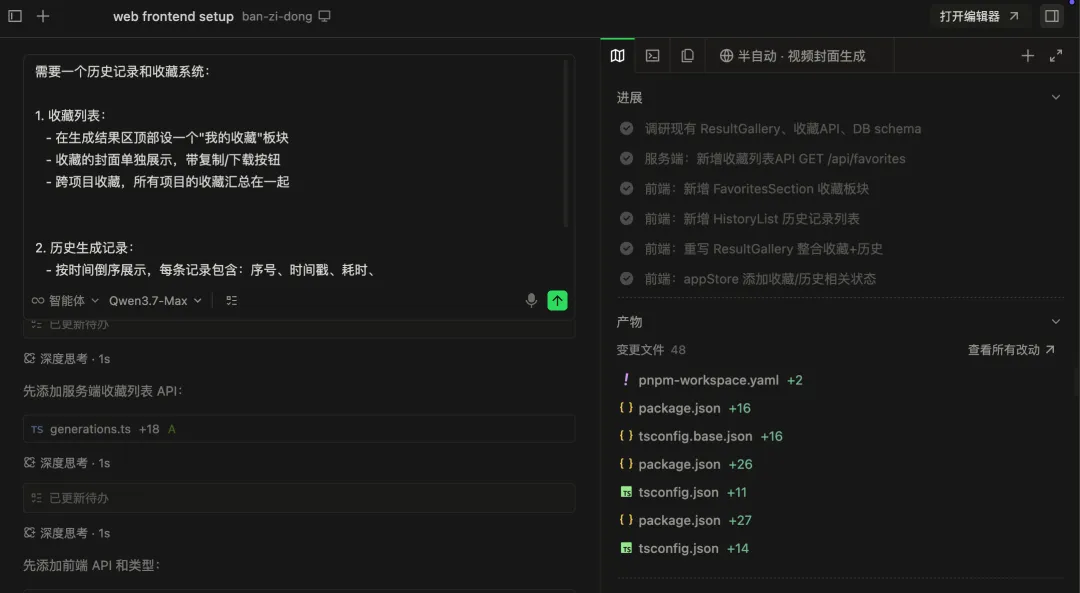
这里我要夸一下 Qwen3.7-Max 的一个能力:它在处理数据结构设计的时候,脑子是清楚的。
我的需求涉及到项目、生成记录、图片、收藏这四层嵌套关系,模型没有把数据结构搞混,每个层级的 CRUD 操作都接对了。这对于做过几年后端的人来说可能觉得理所当然,但对 AI 写代码来说,跨层级的状态管理是最容易翻车的地方。
跑起来看看效果:
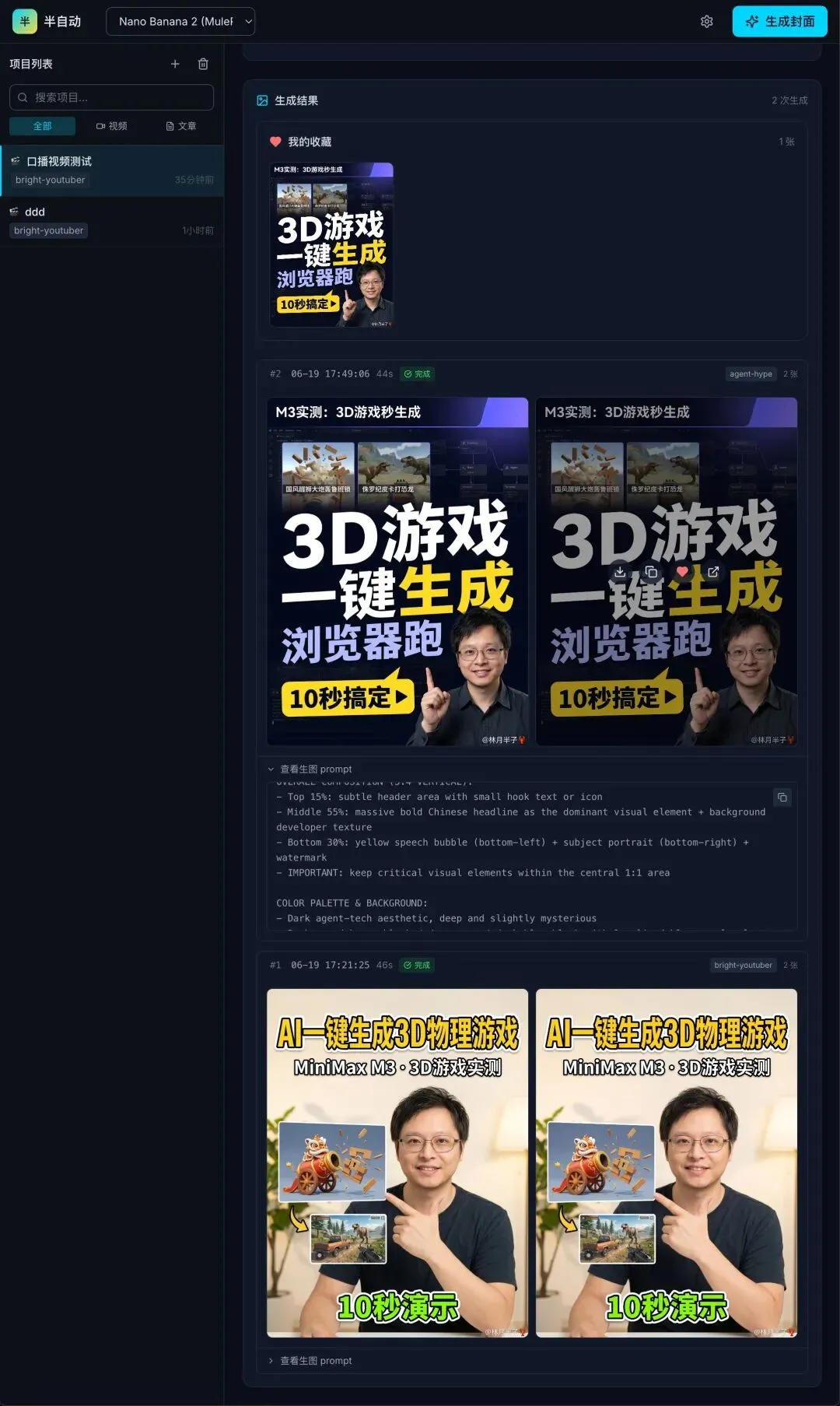
团队里的小伙伴试了一下,没问任何问题,直接上手了。
整个开发过程下来,我给 Qwen3.7-Max 的需求拆了大概 10+ 轮对话,从框架到组件到样式到 Bug 修复,全部在 Qoder 里完成。
中间有没有翻车的地方?肯定有。
说点真实感受
先说翻车的地方。
比如做完历史记录功能之后,我点击项目列表,页面直接白屏了。看报错,是 images.map() 炸了——API 返回的 images 字段是个 JSON 字符串,不是数组。原因是后端 SQLite 的 json_group_array() 返回的本来就是字符串,前端直接拿来 .map() 当然报错。
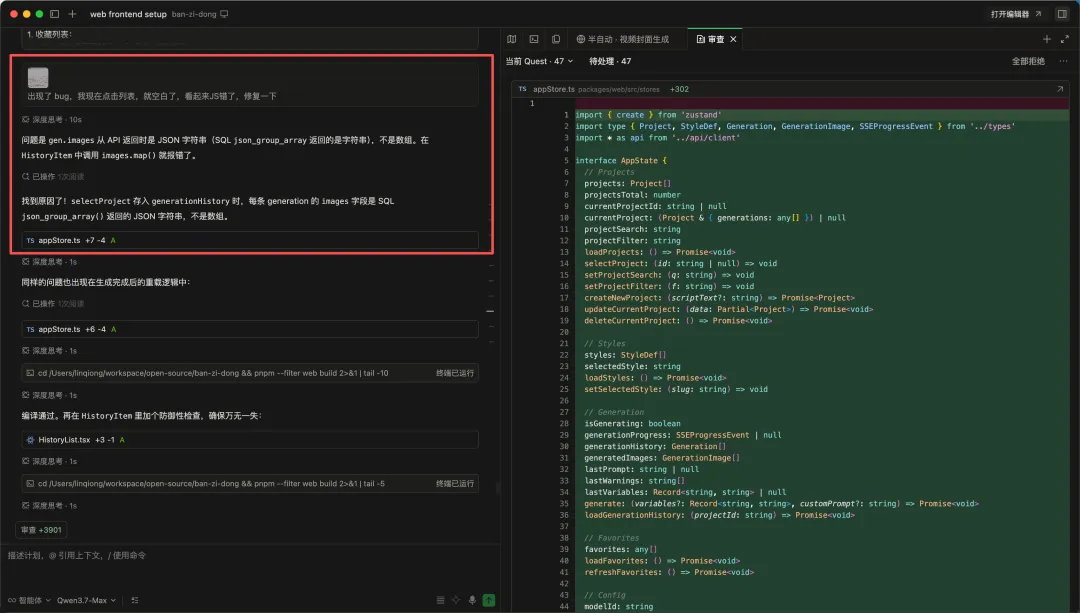
我把报错信息丢给 Qwen3.7-Max,它 10 秒就定位到了根因,改了 appStore.ts 里的解析逻辑,还主动在 HistoryList 组件里加了一层防御性检查。这种"不光修了眼前的 bug,还顺手把同类问题堵上"的习惯,挺好的。
但话说回来,这个 bug 本来就是它自己写出来的。前端后端都是它生成的代码,JSON 字符串和数组的类型没对齐,说明它在跨层数据流转的时候,偶尔还是会犯这种"两边各写各的"的错误。
再说好的地方。
理解需求的能力确实不错。 我上面那些需求,有些描述其实挺模糊的(比如"卡片式展示,2行4列,选中有高亮"),Qwen3.7-Max 基本上第一轮就能给出跟我脑子里想的差不多的方案,不需要来回拉扯。
数据结构和状态管理整体是稳的。 项目列表、生成记录、收藏标记、配置面板这四块的数据流转,虽然中间翻了一次车,但整体架构设计没出过方向性的问题。做过前端的应该知道,这种多层状态管理是最容易一改就崩的。
跑长任务的续航能力可以。 整个项目从框架到完成,前后十几轮对话,模型始终记得之前的设计决策和架构选择,不需要我每次重新交代上下文。Qoder 的会话机制在这方面帮了不少,上下文不会断,第十轮还知道第三轮做了什么决定。
写在最后
回头看整个过程,就是一条很典型的工具进化路径:最早是手动做封面,一张图花半小时;后来写了 Skill,自动化了,但只有自己能用、只有一种风格;现在用 Qwen3.7-Max 把风格扩展到了 8 种,又把整套流程做成了 Web 应用,团队里不懂技术的人也能直接用。
模型工程能力到这个水平之后,剩下的瓶颈基本都在人这边:想不想做、会不会拆需求。 只要需求说清楚、拆成合理的步骤,模型真的能把活干出来。
之前对国产模型写代码这事一直有点保留意见,做个小 demo 看着还行,但真要做一个有状态管理、有持久化、有多层数据流转的完整产品,总觉得差口气。这次做下来,我对 Qwen3.7-Max 的 coding 能力有了新的认知。不能说完美,CSS 细节还是得调,偶尔还是会犯一些一眼能看出来的错误,但整体完成度真的比我预期高。
如果你也有类似的需求,不是搓个小玩具,是做一个自己或团队真正要用的工具,可以在 Qoder 上试试 Qwen3.7-Max。别一口气把所有需求怼过去,像跟同事讨论一样一轮一轮来,效果最好。
如果觉得不错,随手点个「赞」和「在看」,转发给需要的朋友吧~
第一时间收到推送,记得给我个星标⭐
