 夜雨聆风
夜雨聆风AI 科学家不再只是一个概念
AI 科学家这个词,终于从概念营销里落到了一条真实链路上。
OpenAI 这一周发了两件事:一个是 AI chemist 进高通量实验室,跑完 10,080 次化学反应;另一个是 LifeSciBench,把生命科学研发任务拆给模型做专家级评测。
这两个发布放在一起看,信号很清楚。
模型有没有“懂科学”,已经不是最有用的问题。更该问的是:它能不能进入文献、假设、实验设计、自动化实验、数据解释、复现实验这条链路,并且让每一环都留下可检查的证据。
AI 科研的拐点,不在模型说出一个漂亮答案,而在它把一个假设推进到可复现实验结果。
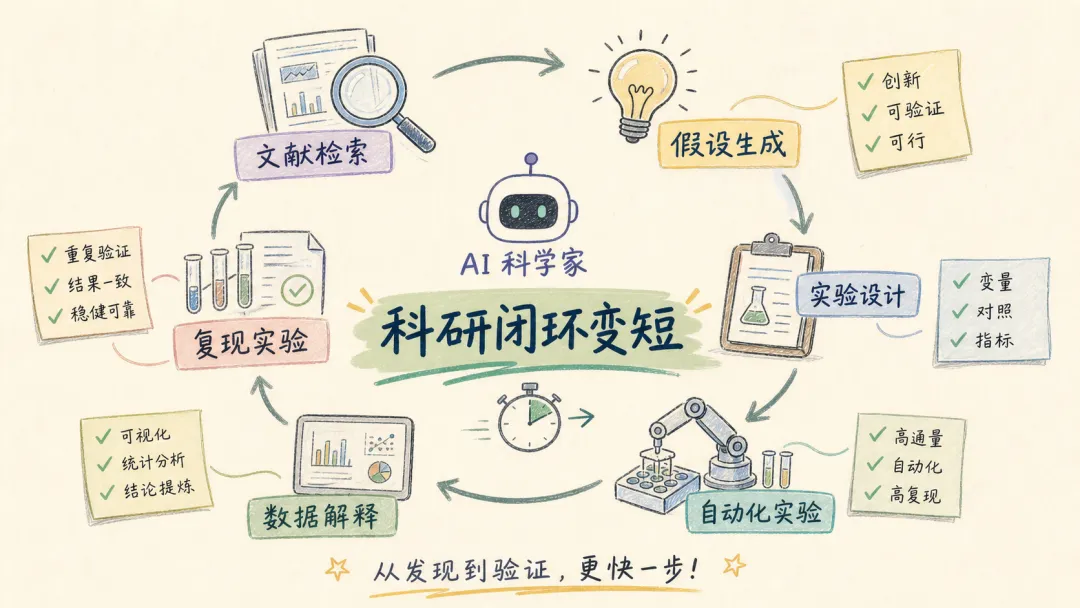
先看实验室
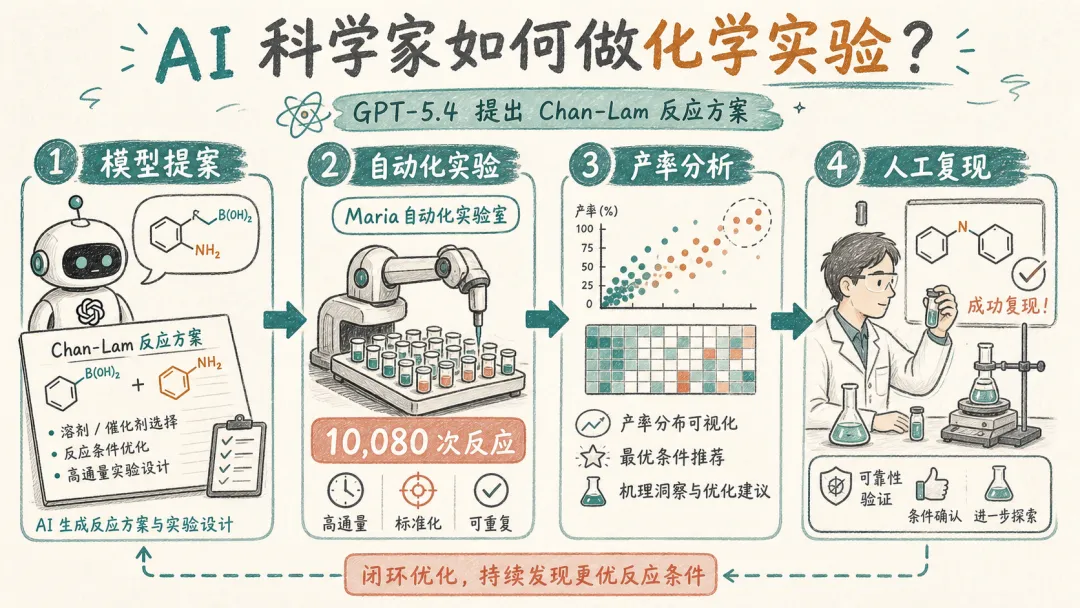
OpenAI 的 AI chemist 案例,研究的是 Chan-Lam coupling。
这是一类药物化学里常见、但条件优化很麻烦的反应。OpenAI 用 GPT-5.4 配合 Molecule.one 的 Maria 高通量实验室,在 OAI-M1-03 中运行了 10,080 次反应。
这里最关键的点,不是模型写了一段建议。
它参与的是一整套迭代:读文献,提出 proposal,设计反应条件,让自动化实验室执行,再根据实验数据安排下一轮 follow-up。
数字比口号扎实。
在优化条件下,88% 的 boronic acids 和 83% 的 sulfonamides 测试对象产率提升。平均产率从 16.6% 提到 25.2%,超过 30% 产率的反应占比从 15.6% 提到 37.5%。
OpenAI 还让人类化学家做了 bench scale 复现。14 对底物里,11 对产率提升,其中 8 对提升超过 2 倍。
10,080 次实验真正有冲击力的地方,是它把 AI 的输出从“文本建议”变成了“实验记录”。
当然,这不是一个人在办公室里打开聊天窗口就能复刻的能力。
它依赖专门的高通量实验室、化学家的 steering、proposal 选择、实验计划修正和独立验证。OpenAI 原文也用了 near-autonomous,而不是 fully autonomous。
这份克制反而重要。
如果 AI 科研要进入真实世界,它先要能在强约束、低风险、可重复的环境里证明自己。药物化学里的反应优化,就是一个很合适的入口。
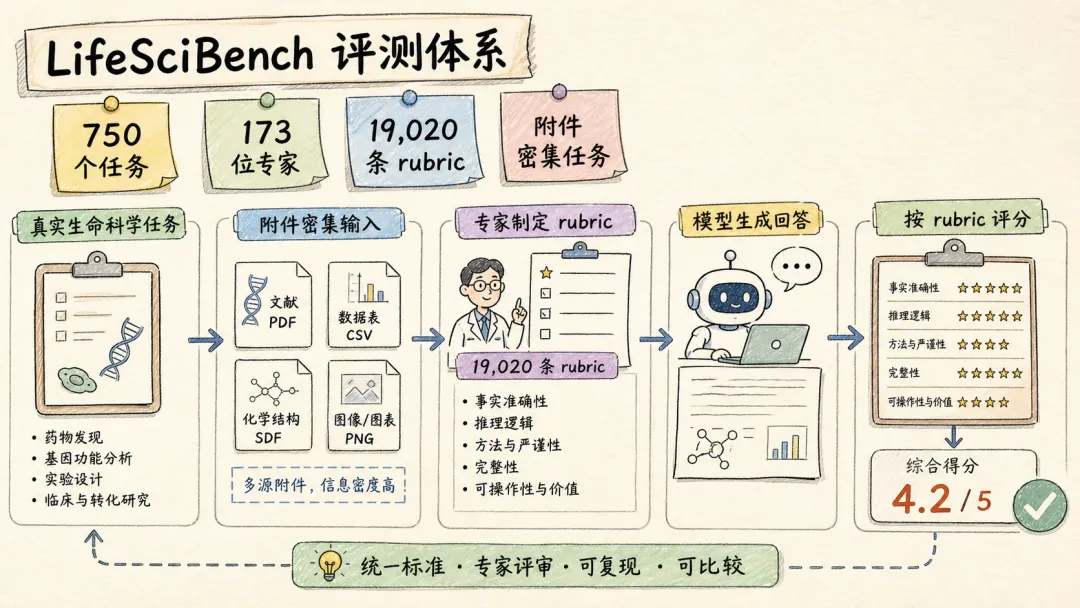
评测也变硬了
LifeSciBench 的价值,是把“模型会不会生物学”这个问题拆细了。
它不是普通问答题库。OpenAI 说,LifeSciBench 包含 750 个真实生命科学研发任务,由 173 位具备 Ph.D. 训练、并有生物技术或制药行业经验的专家科学家编写和评审。
这些任务的难点不在背概念。
79% 的任务需要多步推理或决策,平均每个任务 4 步。数据包里还有 1,062 个附件,包括图、PDF、表格、序列文件、结构或化学文件、网页引用等。
评价也不是一句“答对了”。
专家写了 19,020 条 rubric,平均每个任务 25 条评价标准。模型要处理证据、分析附件、解释实验、设计优化方案,还要在复杂材料里保持判断稳定。
这很接近真实研发里的麻烦:材料不干净,证据不完整,格式很杂,答案经常要跨文件、跨图表、跨实验条件拼出来。
OpenAI 给了一个很刺眼的数字:GPT-Rosalind 在 artifact-heavy 任务上的通过率,从 text-only 的 45.1% 降到 28.1%。
这说明科学工作里的“脏活”还很硬。读图、读表、读附件、对齐实验上下文,比在干净文本里推理难得多。
真正的科学能力,不只体现在模型会解释术语,还体现在它能处理那些又杂、又脏、又不能丢证据的研发材料。
闭环才是信号
把 AI chemist 和 LifeSciBench 合起来看,OpenAI 讲的不是一个“聪明模型”的故事。
它讲的是工作流。
过去我们讨论 AI 做科研,常常卡在两个极端:要么把它当搜索引擎和论文助手,要么想象它一夜之间发现新药、拿诺奖。
这两个说法都太粗。
真正会先发生变化的地方,是科研链路里那些高频、可验证、可自动化的环节。
读一批文献,整理候选假设;把假设翻译成实验矩阵;让自动化平台执行;从失败实验里找下一轮方向;再让人类专家挑出值得复现的结果。
这条链路跑得越短,研发反馈就越快。
AI 科学家的第一阶段,很可能还谈不上“替代科学家”,更现实的价值是把科学家的想法更快送到实验台上。
这里的差别很大。
如果模型只会给建议,科学家还要自己把建议改成实验计划,自己排条件,自己判断异常数据。链路很长,很多想法死在中间。
如果模型能接住文献、假设、实验设计和数据解释,科学家要做的就变成审题、设边界、挑方向、做复现。
人的位置没有消失,但人的工作重心变了。
别急着神化
这件事不能写成“AI 已经能独立做科学”。
OpenAI 的 AI chemist 从 2026-03-04 第一次 prompt,到 2026-06-04 把结果分享给外部专家,整个过程约 3 个月。中间有人类 steering,有专门实验平台,有独立复现。
LifeSciBench 也还只是 self-contained tasks。
它能测试模型在一组封闭任务里的表现,但不等于模型已经能长期推进一个真实研发项目。真实项目里会有预算、伦理、安全、设备排期、数据质量、专利边界和组织协作,这些都不会自动消失。
生物化学还有双用风险。
一个能优化反应、理解结构文件、提出实验设计的系统,也必须被放进严格的权限、审计和安全边界里。越接近真实实验室,越不能只看能力增长。
这也是为什么复现数字很关键。
在 AI chemist 案例里,人类化学家复现了 14 对底物,11 对产率提升。这种外部于模型文本的验证,才让结果站得住。
没有复现,漂亮曲线只是漂亮曲线。
科研里的 AI 不能只交一段答案,它必须交出实验日志、失败记录、复现证据和安全边界。
普通人该看什么
这件事对普通技术人也有提醒。
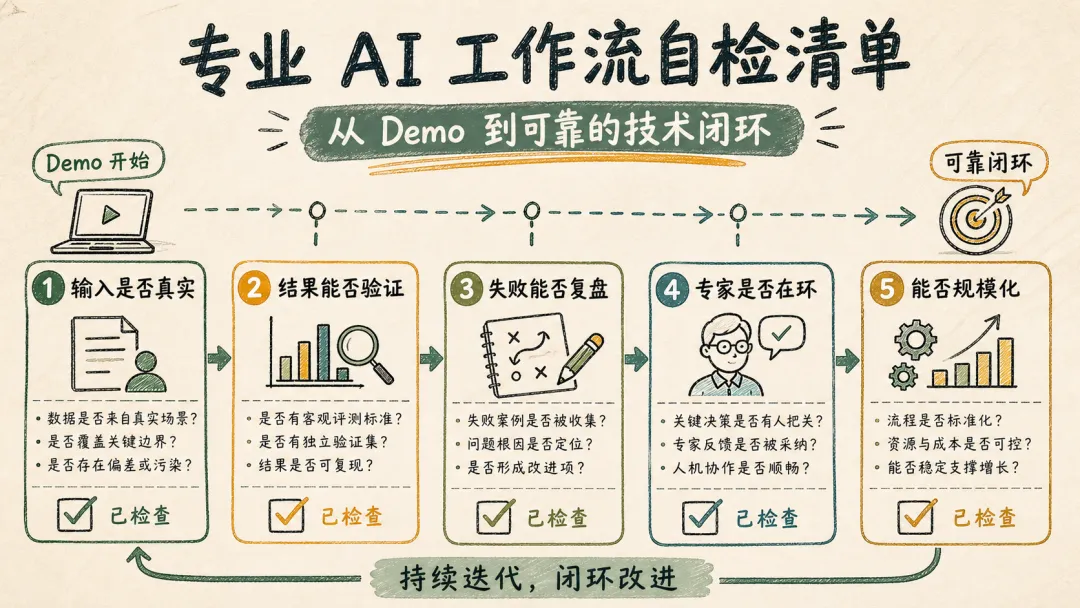
别只盯着模型参数、榜单分数和演示视频。更有价值的问题是:你的专业领域里,有没有一条类似的闭环?
比如:
• 输入是不是足够结构化,能被模型稳定读取; • 假设能不能被拆成可执行步骤; • 执行结果有没有客观指标; • 失败样本能不能回流; • 人类专家能不能做独立复核。
如果这些条件都没有,AI 再强也很容易停在“会说”这一层。
如果这些条件具备,变化会快很多。模型不需要一次性替代整个职业,它只要把一个关键循环压短,就会改变生产节奏。
我更关心的是后者。
AI 科学家第一次具体了,原因不在科幻电影式的研究员形象,而在它开始接触真实科研里最朴素的东西:证据、实验、失败、复现。
这些东西不性感,但它们决定一项能力能不能离开发布会。
