 夜雨聆风
夜雨聆风最近,一只“雪山狐狸”刷屏了。古装男子、雪地里的狐狸、一只酱板鸭……。
如何用AI拆解、重组一个爆款视频?
很多人以为AI视频生成就是输入一段文字,点击生成。但实际上,要复刻“雪山狐狸”这种故事,需要一套完整工作流。
第一步:让AI“看懂”原视频
首先用多模态大模型(比如通义千问VL)对原始视频进行“阅读理解”。
Qwen3-VL 也适用于高精度的物体识别与定位(包括 3D 定位)、 Agent 工具调用、文档和网页解析、复杂题目解答、长视频理解等任务。系列内模型对比如下:qwen3-vl-plus:Qwen3-VL 系列中性能最强的模型。qwen3-vl-flash:速度更快,成本更低,是兼顾性能与成本的高性价比选择,适用于对响应速度敏感的场景。
它能自动识别出:
时间线:第几秒到第几秒发生了什么事件
角色:灰衣古装男子、狐狸、三名女子……
动作与对白:“给你一只酱板鸭”“希望你能熬过冬天”
情绪转折:从施救到困惑,再到愤怒开枪
这一步的输出是一个 JSON 格式的事件列表,就像电影的场记表。
json
{
"start_time": "00:00:00",
"end_time": "00:00:05",
"event": "灰衣男子在雪地中,从布袋里取出一只酱板鸭,对狐狸说话"
}
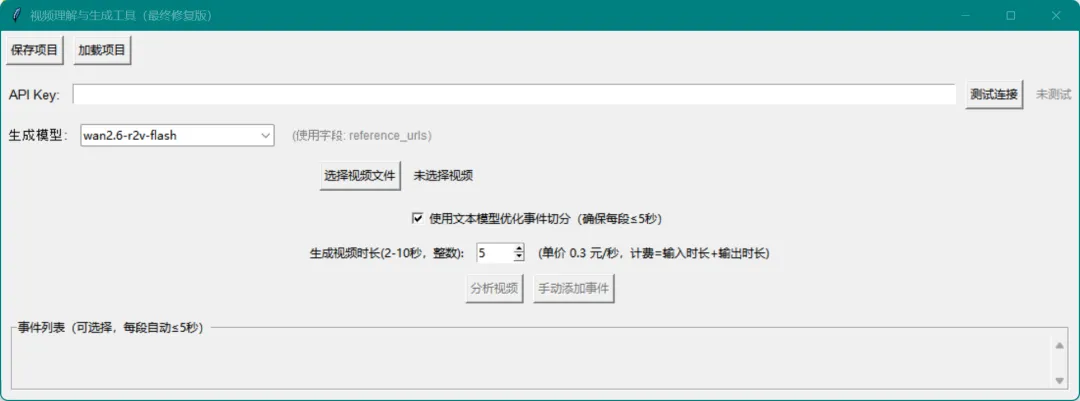
第二步:切分与改写
视频生成模型通常有时长限制(比如每次最多5秒)。所以我们用一个文本模型(如qwen-plus)把上面的事件列表重新切分,确保每个片段 ≤ 5 秒,并且语义完整。
我们可以修改提示词。这样一来,每个片段都有了新的“剧本”。
第三步:素材的基因提取
要让AI生成的视频保持原片的视觉风格(邵氏武侠风、雪景、古装),我们需要给它“参考素材”。程序会自动从原视频中:
剪辑对应时长的片段(≤5秒)
抽取3张关键帧(最具代表性的人物动作和表情)
然后上传,作为生成模型的视觉参考。
第四步:视频生成
最后,调用视频生成模型(如wan2.6-r2v-flash),对每一个片段独立生成新视频。
万相-参考生视频模型支持多模态输入(文本/图像/视频),可将人物或物体作为主角,根据提示词生成自然生动的表演视频。基础能力:设置整数级视频时长(2~10秒)、指定视频分辨率(720P/1080P)、添加水印。角色扮演:基于参考图像或视频还原角色形象;若参考素材为视频,还支持参考音色,支持单人表演或多角色互动。多镜头叙事:具备多镜头智能调度能力,支持自然对话与稳定互动,同时保持主体一致性。
你可以选择:
分别保存:得到小视频,适合短视频平台的分段发布
自动合并:把片段拼接成一个完整的“雪山狐狸”
为什么能引爆传播?
这种“换汤不换药”,隐藏着短视频传播的第一性原理:熟悉感加新鲜感带来病毒式传播。
1. 视觉的熟悉感:邵氏武侠”
“雪山狐狸”原片的视觉风格——灰蒙蒙的雪景、硬朗的布光、略带夸张的表演——完美复刻了80、90后记忆里的邵氏武侠片。这种风格不需要解释,观众一看就知道“这是讲江湖故事的”。
观众点开视频,第一反应是“哦,雪山狐狸”,而不是“这是什么玩意儿”。信任感瞬间建立。
2. 内容的新鲜感
在熟悉的视觉外壳下认知反差会让观众会心一笑。
3.技术模板
这个逻辑的启发是,任何热点视频,都可以被解构成视觉风格、叙事模板、可替换元素。
视觉风格:由参考视频锁定(雪景、古装、武侠)
叙事模板:由事件列表固定(报恩→反转→冲突→结局)
可替换元素:酱板鸭
回顾这个案例,你会发现:技术门槛已经降低,把技术、热点、地域文化缝合起来的创意更为宝贵。我们折服于代码执行的高效。但面对这样一段“赛博文旅”,真正的文化去哪儿了?
