 夜雨聆风
夜雨聆风当 GPU 进入整柜级密度,AI Infra 的核心问题会从有没有卡,变成集群能不能稳定、经济、持续地运行。
一、为什么 GPU 之后,瓶颈会迁移
AI 集群建设的早期,最受关注的问题往往是 GPU 供应。谁能拿到更多高端 GPU,谁就更容易获得算力扩张的主动权。但当 GPU 数量持续增加,新的瓶颈会很快出现。因为训练和推理不是单卡问题,而是集群问题;集群不是单一硬件问题,而是网络、电力、散热、布线、运维和数据中心建设共同决定的系统问题。
瓶颈迁移有一个基本逻辑:当某个环节能力提升最快时,系统压力会传导到相邻环节。GPU 性能提升和数量增加,会带来更大的节点间通信压力,于是网络成为瓶颈;GPU 功耗上升,会带来更高单柜功率,于是供电和制冷成为瓶颈;集群规模上升,会带来更多链路、更多故障和更高运维复杂度,于是可观测性和自动化运维成为瓶颈。
这就是为什么 AI Infra 机会不会只停留在 GPU 上。GPU 是主线,但不是全部。真正长期的机会,往往出现在系统被迫升级的地方。网络要从 400G 走向 800G 和 1.6T,光互连要降低单 bit 功耗,电力要适应更高机柜功率,液冷要从试点走向工程化,数据中心选址要围绕电力和冷却重新规划。
看清瓶颈迁移,才能理解为什么 AI Infra 是连续多年的基础设施周期,而不是单一硬件周期。每一代模型和 GPU 平台都会把压力重新分配到网络、供电、散热和运维,产业链机会也会随之轮动。

二、网络瓶颈:AI Fabric 决定训练效率
大规模训练最怕 GPU 等待。只要通信不稳定,GPU 就会在同步阶段空转,昂贵算力变成等待成本。AI Fabric 的价值在于让大量 GPU 像一个更大的计算系统一样协同工作。这个目标对网络提出的要求远高于普通数据中心网络:低延迟、低抖动、高带宽、可预测拥塞控制、快速故障定位和作业级可观测。
Leaf-Spine 是常见拓扑,但真正的难点在端口速率、阻塞比、链路质量、路由策略和运维工具。400G 到 800G,再到 1.6T,不只是数字提升。端口速率上升会带来交换芯片、SerDes、光模块、散热、功耗和布线的一系列变化。光模块的功耗、误码率、良率和成本会直接影响网络部署。
协议路线也是关键。InfiniBand 在高端训练场景有性能和生态优势,RoCE/以太网在开放性、成本和多供应商生态上有吸引力,Ultra Ethernet 等方向试图为 AI 和 HPC 场景重新定义以太网能力。但研究时不能只看路线口号,要看真实产品、客户验证、作业完成时间、尾延迟、丢包恢复和运维复杂度。
网络层的产业机会包括交换芯片、高速交换机、NIC/DPU、光模块、硅光、DSP、AOC/DAC、网络操作系统、Fabric 控制器和可观测性平台。它们共同构成 AI Fabric,而不是某个单独部件就能解决所有问题。

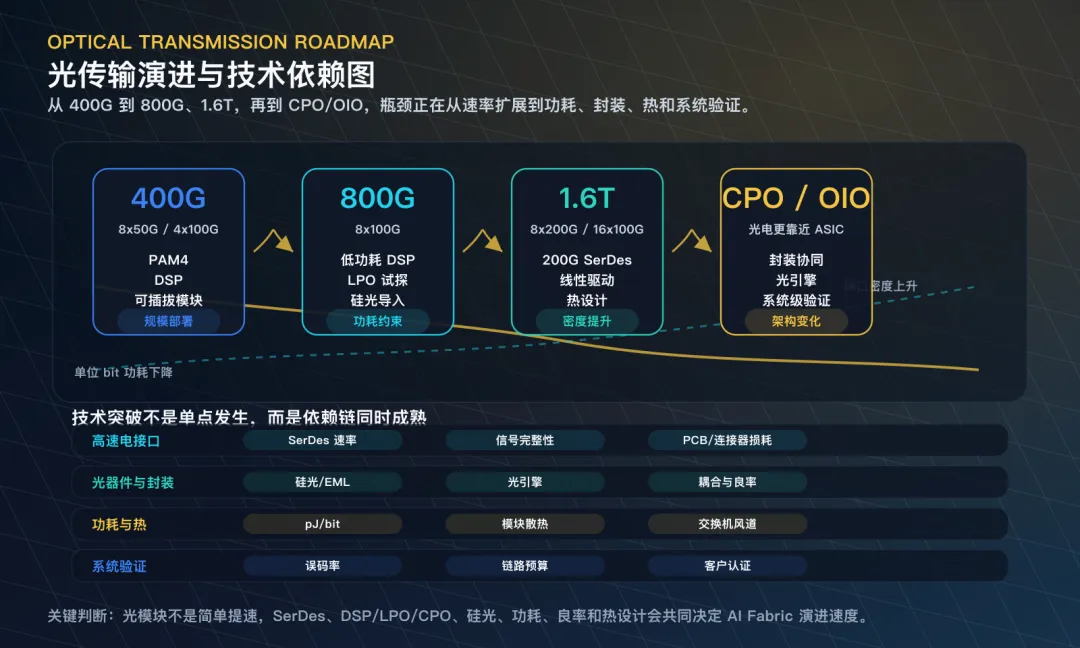
三、光互连瓶颈:800G/1.6T 背后的工程压力
光模块经常被当成一个独立方向讨论,但放在 AI Infra 里看,它是 AI Fabric 的物理载体。GPU 集群规模越大,Leaf 到 Spine、服务器到 Leaf、跨机柜和跨列的链路越多,光互连压力越大。800G 和 1.6T 的升级,本质上是在更高带宽、更低功耗、更高密度和可接受成本之间寻找平衡。
高速光模块的关键变量包括封装形态、传输距离、功耗、DSP、光引擎、良率、客户认证和散热。LPO、CPO、硅光等路线被关注,是因为传统方案在功耗和密度上会遇到边界。但路线切换也意味着不确定性:谁能通过大客户认证,谁能稳定量产,谁能控制良率和成本,谁能适应交换机和服务器平台变化。
光纤布线也会成为工程瓶颈。链路数量上升后,MPO/MTP 极性、弯曲半径、插损、标签、配线架、桥架和现场测试都会影响可靠性。一个链路异常可能导致训练任务性能波动,定位成本很高。因此,光模块之外,线缆、配线、测试仪表和资产管理也会有价值。
研究光互连时,需要把它放在网络架构里看。不是所有光模块公司都受益程度相同,关键要看产品代际、客户结构、海外大客户认证、800G/1.6T 出货占比、单 bit 功耗、良率、产能和价格趋势。
四、电力瓶颈:AI 数据中心的硬物理约束
电力是 AI 数据中心最硬的约束之一。GPU 可以采购,服务器可以交付,但电力接入、变压器、UPS、母线、PDU、并网周期和能耗指标并不能无限加速。一个 AI 园区如果没有足够电力容量,再多服务器也只是库存。很多项目真正的瓶颈会出现在电力指标、建设许可和上游电网扩容。
单柜功率提升会改变数据中心配电架构。传统机柜可能只需要几千瓦到十几千瓦,而高密 AI Rack 可能走向几十千瓦、上百千瓦甚至更高。这个变化会影响 PDU、母线、UPS、低压配电、线缆规格、开关设备、消防和维护流程。高压直流、800VDC、机柜级电源和更高效率功率器件之所以被讨论,是因为它们试图减少转换损耗、降低铜材压力并支持更高功率密度。
电力还会影响选址。过去数据中心选址常看土地、网络、政策和客户距离,AI 数据中心会更强调电力可得性、电价、绿电、并网周期、水资源和社区接受度。未来一些 AI 园区可能更像能源项目,而不只是 IT 项目。算力基础设施和能源基础设施的边界会越来越模糊。
产业机会包括 UPS、母线、智能 PDU、变压器、开关设备、功率半导体、储能、微电网、能源管理和工程总包。但风险也很实际:建设周期长、审批复杂、资本开支重、应收账款和项目验收周期长。电力方向适合用项目和订单跟踪,而不是只看主题热度。

五、液冷瓶颈:从可选项变成高密集群标配
液冷的核心驱动是热密度。GPU 功耗上升、单柜功率上升、PUE 要求提高,都会让传统风冷越来越吃力。冷板液冷通过更直接的换热路径降低热阻,提高高功率节点运行稳定性。但液冷进入数据中心以后,它就不再是服务器内部问题,而是机柜、CDU、冷冻水、管路、监控和运维共同参与的系统工程。
液冷链路包括芯片到冷板、冷板到快接、节点到机柜歧管、机柜到 CDU、CDU 到冷冻水或外部冷源。每一级都可能出问题。流量不足、压降过高、冷却液污染、材料腐蚀、快接失效、漏液检测不及时、运维流程不熟,都可能影响集群可用性。
液冷的产业机会不止温控设备。冷板、快接、泵、阀、传感器、CDU、管路、漏液检测、液冷机柜、冷源系统、维护服务和标准化工程能力都有价值。真正的壁垒不只是产品参数,而是平台认证、项目经验、可靠性数据和责任边界。
研究液冷时要特别警惕两个问题。第一,概念暴露不等于收入暴露,很多公司有液冷业务但规模很小。第二,液冷项目制特征明显,交付、验收和运维责任会影响利润质量。要看客户、项目、订单、验收、毛利和售后,而不是只看概念标签。

六、数据中心选址和能源协同:AI 园区的新逻辑
AI 数据中心和传统 IDC 的选址逻辑正在分化。传统 IDC 重视网络节点、客户距离、土地和政策;AI 数据中心尤其是训练集群,对电力、冷却、外联带宽和建设速度更加敏感。一个地方如果电力充足、绿电成本低、冷却条件好、并网周期短,就可能比传统核心城市更适合大规模训练园区。
能源协同会成为新主题。AI 负载具有一定可调度性,未来可能和储能、绿电、需求响应、热回收结合。数据中心不只是用电设备,也可能成为能源系统里的可调负载。这个方向短期商业化复杂,但长期会影响大型 AI 园区成本结构。
水资源和社区约束也不能忽视。液冷、冷却塔、噪音、土地、电网扩容都会引发本地约束。AI 数据中心越大,越需要和地方能源、环保和社区政策协同。建设速度不只取决于资本开支,也取决于许可和公共资源。
因此,IDC 运营商和算力服务商的研究要从机柜数扩展到签约电力、并网周期、PUE/WUE、上架率、客户结构、融资成本和长期电价。AI 时代的 IDC 不只是租机柜,而是在运营高资本开支、高能耗、高工程复杂度的基础设施资产。

七、运维瓶颈:规模越大,越需要作业级可观测
大规模 AI 集群里,运维瓶颈会被快速放大。一个坏 GPU、一个不稳定端口、一个异常光模块、一段光纤插损、一个温度热点,都可能拖慢训练作业。传统设备监控只能告诉你某个设备告警,AI 集群运维需要回答的是:这个告警是否影响作业,影响了哪些 GPU,是否应该迁移任务,是否需要隔离节点,是否会影响 SLA。
这要求把 GPU 遥测、网络遥测、存储指标、电力和热数据、作业队列、调度日志和资产信息打通。DCIM、Fabric 管理器、BMC、AIOps 和调度平台需要形成闭环。未来成熟的 AI Factory,应该能从作业视角看到底层基础设施状态,也能从设施异常反推出受影响的训练任务。
运维的价值可以用几个指标衡量:GPU 利用率、MTTR、作业失败率、Checkpoint 恢复时间、网络尾延迟、能耗效率和 SLA 违约率。只要集群规模足够大,任何一个指标的小幅改善都会对应可观经济价值。
产业机会包括 DCIM 升级、AIOps、网络可观测性、BMC 安全、测试仪表、资产管理和运维托管。它们不像 GPU 那样显眼,但会成为算力服务商和大型 IDC 的长期能力差异。

八、行业机会:越硬的瓶颈,越值得长期跟踪
从 GPU 到网络、电力和液冷的瓶颈迁移,意味着 AI Infra 的机会会分层展开。第一层是显性算力,包括 GPU、AI 加速器、HBM 和服务器平台。第二层是扩展能力,包括 AI Fabric、光模块、交换机、NIC/DPU 和网络软件。第三层是物理上限,包括电力、液冷、机柜、数据中心选址和能源协同。第四层是长期运营能力,包括 DCIM、AIOps、测试仪表和运维服务。
不同层的机会节奏不同。显性算力弹性最大,但竞争和估值波动也最大;网络和光模块与平台代际强相关,受客户认证和技术路线影响;电力和液冷更偏工程项目,兑现较慢但约束更硬;运维软件和服务可能更晚被市场重视,但一旦客户形成依赖,粘性会更强。
研究这些机会,要坚持三个问题。第一,它解决的瓶颈是否真实存在,并且会随 AI 集群规模放大?第二,公司是否有产品、认证、客户和交付证据,而不是只有概念标签?第三,这个环节的价值能否转化为收入、毛利和持续订单?如果三个问题都能回答,才值得进一步研究。
结论很清楚:AI 集群的瓶颈不会停在 GPU。随着算力进入整柜、整列和园区级建设,网络、电力、液冷和运维会越来越像主角。看懂这些瓶颈迁移,才能看懂 AI Infra 的行业机会。

九、如何把瓶颈迁移变成可跟踪的研究框架
第一步是建立容量模型。一个 AI 集群到底需要多少 GPU、多少高速端口、多少机柜、多少电力、多少冷量、多少光纤链路,不能只靠新闻和口号判断。容量模型会把 GPU 数量、端口速率、阻塞比、单柜功率、液冷能力和建设周期放在一起,让研究从定性讨论进入定量约束。
第二步是建立证据表。网络方向看 800G/1.6T 端口出货、光模块客户认证、交换机平台迭代和真实集群案例;电力方向看签约电力容量、变压器/UPS/母线订单、并网周期和项目验收;液冷方向看 CDU、冷板、快接、漏液检测、数据中心项目和售后能力;运维方向看 DCIM、Telemetry、AIOps 和作业级指标是否真正落地。
第三步是区分一次性建设和持续运营。一次性建设带来设备订单,持续运营决定客户复购和服务价值。AI Infra 的长期机会不一定只在硬件出货,也可能在能耗优化、故障定位、容量规划、备件管理和 SLA 服务里。越大的 AI Factory,越需要把工程建设能力转化为持续运营能力。
第四步是保留反向假设。模型效率提升可能降低部分硬件需求,客户自研可能压缩第三方供应商空间,技术路线切换可能改变光模块和网络设备格局,电力审批可能拉长项目周期。专业研究不是只讲景气,而是把正向机会和反向约束同时放在模型里。
持续跟踪 AI Infra 时,这套框架可以沉淀成表格:每个瓶颈对应一个技术指标、一个 BOM 环节、一组代表公司、若干证据来源和一个反向风险。这样做的好处是,判断会随着证据更新,而不是随着市场情绪摆动。
结语:先建立系统视角,再谈产业链和公司暴露
AI Infra 的研究不能停在概念和名单层。真正值得长期积累的,是把模型需求、硬件架构、网络拓扑、供电制冷、数据中心工程和公司业务暴露放在同一张图里。这样看,很多表面上分散的机会会连成链路,很多看似热闹的标签也会被证据过滤掉。
进一步研究 AI 服务器、AI Fabric、液冷、电力、光模块、国产算力和数据中心建设时,关键仍然是把每一层的技术约束、产业链位置和可验证证据对应起来。
研究重点在于技术架构、工程约束与可验证证据。
