 夜雨聆风
夜雨聆风
作者:李媛媛 本文约5000字,建议阅读15分钟 本文介绍算法催生的数字沉默螺旋,剖析其风险并给出三维治理方案。
在人类舆论场中,“沉默的螺旋”是解释舆论极化、观点趋同的经典传播规律。但很多人不曾意识到,这场原本属于人类社会的舆论博弈,正在AI时代以更隐蔽、更强势的方式重演。如今大语言模型(LLM)深度渗透内容生产、检索问答、智能交互全场景,没有情绪感知、没有社交恐惧、没有从众心理的AI,却在底层算法与训练机制的驱动下,自发出现观点从众、小众真相失语、内容高度同质化、错误信息垄断的“沉默螺旋”现象。本文依托2024–2026年ACL顶会、Knowledge-Based Systems、arXiv前沿预印本等最新权威研究,系统梳理大模型沉默螺旋的理论迁移逻辑、真实实证表现、底层技术机制、潜在生态风险与落地治理方案,带你深度解读当下极易被忽视的AI信息生态危机。


01 从人类到AI:沉默螺旋,正在技术世界复刻
1.1 什么是经典“沉默的螺旋”?
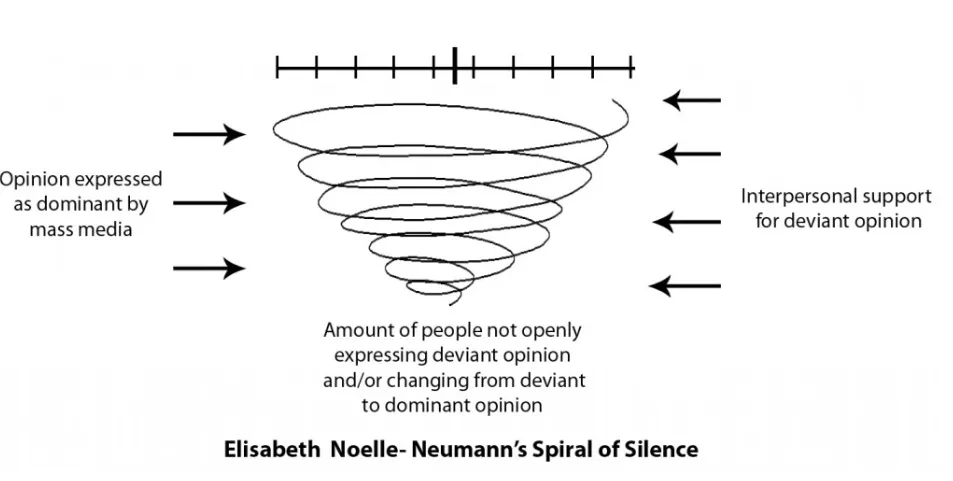
1974年,德国政治学家伊丽莎白·诺埃尔-诺伊曼提出经典传播学理论——沉默的螺旋,完美解释了人类社会的舆论极化现象。
简单来说,这套理论的核心逻辑只有三点:
孤立恐惧:人渴望社会认同,害怕因小众观点被孤立,预判自己观点属于少数时,会选择沉默;
准统计感官:人们不靠客观数据,而是通过媒体、社交环境主观判断主流舆论;
螺旋式循环:少数人沉默→主流观点看起来更权威→更多人不敢发声→最终形成观点垄断。
长期以来,学界与行业普遍认为,沉默螺旋的发生完全依托人类的心理特质与社交本能,是人类社会独有的舆论现象。AI作为纯工具性的技术产物,既没有被孤立的焦虑,也没有追逐群体认同的诉求,更不会主动规避小众观点,因此大家默认AI生成内容具备绝对的客观性与多元性,不会出现从众沉默的问题。
但近两年针对大模型舆论动力学的多组对照实验、长周期模拟研究,彻底推翻了这一固有认知,证实沉默螺旋早已跳出人文社会场景,深度扎根于大模型的技术逻辑之中。

1.2 大模型沉默螺旋:无需心理,算法即可催生
2024年起,学界正式定义了大模型沉默螺旋:
简单来说,在大模型自主生成、RAG检索迭代、多智能体协同交互的闭环运行场景中,大量具备事实正确性、具备创新价值,但不符合主流语料范式、大众固有认知的小众观点,会被模型系统性、持续性压制;反之,流传更广、频次更高的主流观点,哪怕存在片面性、事实偏差甚至低级错误,也会在反复生成与传播中不断强化、持续扩散,最终形成全网AI内容同质化、单一化的观点垄断格局。
最颠覆的核心结论来自2025–2026年最新实证研究:
最颠覆行业认知的核心结论来自2025–2026年最新实证研究:LLM无需任何人类心理动机、无需外部舆论干预,仅依靠自身纯统计语言生成机制,就能自发形成沉默螺旋效应。且相较于人类社会,AI沉默螺旋更隐蔽、迭代速度更快、压制效果更强,是GPT、Llama、通义千问、DeepSeek等所有主流大模型的通用系统性问题,不同模型仅存在效应强弱差异,无法完全天然规避。
02 两大核心实证场景:看懂AI沉默螺旋如何发生
经过两年集中攻关,全球学界对大模型沉默螺旋的研究已从现象初探走向机制深挖、量化实证阶段。目前核心研究场景高度聚焦两大落地赛道,也是普通人日常接触最多的AI应用场景:RAG检索增强生成场景,主打网络内容迭代与信息传播;多智能体LLM交互场景,主打AI对话、辩论、协同创作的观点博弈。所有核心实验均覆盖闭源商用模型与开源通用模型,贴合工业界真实落地环境,研究结论具备极强的真实性与落地参考价值。
2.1 RAG闭环:AI正在“杀死”人类原创内容
作为当前大模型落地企业、To C应用、行业知识库搭建的核心范式,RAG检索增强生成技术有效解决了大模型知识滞后、幻觉严重的问题。但随着海量AI生成文本持续涌入互联网,被各大搜索引擎收录、索引,互联网内容生态已然形成AI生成—全网索引—检索复用—再次AI生成的无限闭环迭代模式。这种全新的内容生产传播模式,正在悄然重塑全网信息结构,对内容多样性、真实性与原创性造成颠覆性影响。
这种闭环会对信息多样性造成什么影响?2024年ACL顶会研究给出了扎心答案。
实验设计
为真实还原互联网内容演化规律,研究团队搭建了高仿真的全网内容迭代模拟系统,模拟真实搜索引擎与AI生成链路。实验语料混合高质量人类原创文本与常规AI生成文本,以大众高频使用的开放域问答为核心测试任务,通过多轮连续迭代模拟网络内容长期更新过程,全程精准监测检索准确率、人类原创内容留存占比、全网观点多样性三大核心评价指标,完整还原RAG闭环下的信息生态变化。
核心实验结论
短期利好,长期崩塌:初期AI内容能小幅提升检索精度,但仅5轮迭代后,内容质量开始同质化,检索性能大幅下降;
搜索引擎偏爱AI内容:算法天然偏好排序更规整的AI生成文本,人类原创内容曝光量急剧锐减;
数字沉默螺旋彻底形成:迭代后人类原创内容占比从50%暴跌至15%以下,大量正确的小众观点被边缘化,AI同质化、甚至错误的内容彻底垄断信息场。
这一实验结果直击当下AI内容生态的核心痛点:长期依赖RAG闭环迭代,会彻底挤压人类原创内容的生存空间与曝光渠道,全网正在逐步进入“AI自我复制、人类原创失语、小众真相沉没”的单向信息固化时代,信息多元性被持续破坏。
2.2 多智能体交互:AI对话如何自发极化?
除了公开检索传播场景,当下火热的多AI智能体协作、多人机对话、模型辩论推演场景,是沉默螺旋效应的另一重高发阵地。多个大模型之间持续交互、观点碰撞、迭代输出的过程,会不断放大观点从众效应。2025年arXiv发布的前沿专项研究,通过多组严格对照实验,彻底拆解了多智能体场景下AI观点极化、小众观点沉默的核心诱因与作用逻辑。
实验设计
为规避单一模型实验偏差,本次研究采用多维度模型覆盖策略,涵盖轻量化闭源商用模型GPT-4o-mini,以及Llama3.1、Mistral、Qwen2.5、DeepSeek-V2等主流开源大模型,覆盖不同参数规模、训练数据体系与架构设计。研究创新性设置四大对照变量:无历史上下文无角色设定、仅保留历史对话、仅固定角色立场、历史上下文+角色设定双重叠加,通过量化指标精准测算不同条件下的观点极化程度与沉默效应强度。

核心实验结论
双信号叠加,螺旋效应最强:当历史对话上下文+固定角色设定同时存在时,主流观点占比突破80%,小众观点被完全压制,完美复刻人类舆论沉默螺旋;
历史是锚定器:仅依靠对话历史,模型会持续重复主流观点,内容单一但不会极端极化;
角色是分化器:仅设定角色立场,模型观点独立分散,无法形成主流与小众的对立;
小模型缺陷更明显:参数规模较小的轻量化开源模型,参数容量与泛化能力有限,高度依赖高频主流语义与历史上下文,对小众观点、低概率创新内容的容纳度极低,因此沉默螺旋效应远强于大参数模型、闭源高端模型;同时,中文大模型的训练数据具备更强的共识性语境与同质化特征,相较于语义更多元的英文模型,沉默压制效应显著更突出。
2.3 深挖底层:AI沉默螺旋的4大技术根源
不同于人类源于心理焦虑的沉默行为,大模型的沉默螺旋与情绪、认知、主观意愿无关,完全源自底层算法逻辑、预训练数据分布、训练对齐机制,是与生俱来的系统性技术缺陷,四大核心根源层层叠加、相互催化:
预训练统计偏好(底层基础):预训练数据中主流观点占绝对优势,模型天生倾向于生成高概率的大众内容,对小众、创新观点天然“沉默”;
历史上下文锚定(核心驱动):自回归生成机制让模型持续贴合对话历史主流观点,不断自我强化,形成正向闭环;
角色设定固化(催化加速):固定立场的角色设定放大观点对立,进一步压制小众立场输出;
RLHF对齐放大(固化诱因):当前工业界通用的安全去偏、人类反馈强化学习对齐方案,为了规避风险、统一输出范式,会主动压低模型token预测熵值,压缩模型的创作空间与表达自由度,让模型输出高度收敛于主流、安全、标准化的表达范式,主动规避小众视角、差异化观点与创新性内容,从训练层面直接固化内容同质化缺陷,大幅放大沉默螺旋效应。
03 学界共识、争议与未来研究空白
3.1 已达成的核心共识
经过2024–2026年多轮交叉验证、跨模型对照、多场景模拟研究,全球学界已针对大模型沉默螺旋形成多项统一核心结论,彻底夯实了该领域的理论基础:
沉默螺旋是大模型通用系统性问题,覆盖RAG、智能体交互、开放对话、AI推荐全场景;
无需人类心理,四大技术机制叠加即可触发效应;
直接造成信息单一、错误扩散、偏见固化、创新抑制四大危害;
小模型、中文模型、对齐后模型的沉默螺旋效应更显著。
3.2 行业核心争议
尽管核心现象与机制已被证实,但学界在效应细节与落地边界上仍存在明显分歧,也是目前行业研究的核心攻坚热点:
效应强度争议:部分研究认为仅极端场景下显著,顶会研究则证实少量迭代即可造成不可逆信息失衡;
可规避性争议:暂无统一结论,无法确定该效应可彻底消除,还是仅能弱化;
边界条件争议:不同参数、数据、场景下的触发阈值,尚未形成量化标准。
3.3 尚未填补的研究空白
整体来看,大模型沉默螺旋仍属于AI舆论动力学的新兴研究领域,整体处于现象验证、机制初探的早期阶段,大量核心关键问题尚未形成统一答案,存在明显研究空白:
无统一的沉默螺旋强度量化指标与测评体系;
缺乏互联网级长周期信息迭代演化研究;
多模态AI的沉默螺旋机制完全空白;
轻量化、低成本的规模化治理技术尚未成熟;
人机混合交互的双重沉默螺旋演化规律未知。
04 隐形风险爆发:AI沉默螺旋的四大危害
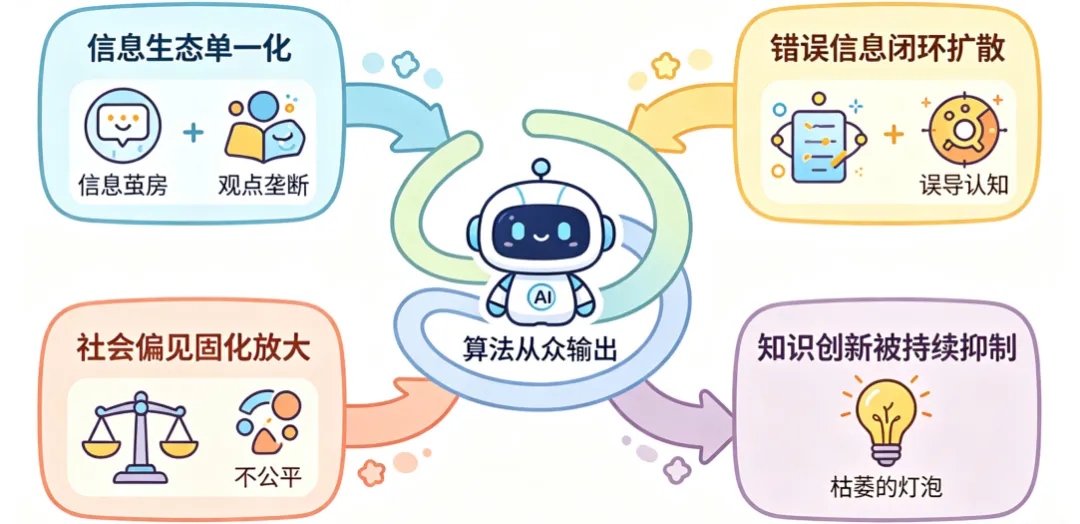
这种算法驱动的固定“从众输出”,看似只是内容风格单一,实则会渗透到信息传播、公共认知、产业决策、学术创新等各个领域,引发整个数字信息生态的连锁负面危机,长期危害不容小觑:
信息生态单一化:人类原创、小众创新、批判性思考持续消失,形成“信息茧房+观点垄断”双重困境;
错误信息闭环扩散:AI生成的偏差内容持续强化传播,小众真相被彻底边缘化,误导公众认知与产业决策;
社会偏见固化放大:训练数据中的性别、地域偏见,通过螺旋效应持续放大,加剧认知不公;
知识创新被持续抑制:前沿学术小众观点、颠覆性产业创新思路、批判性反思内容,大多属于低概率非主流表达,极易被模型压制。长期来看,AI的同质化输出会固化大众与行业认知,扼杀创新思维,阻碍各领域知识迭代与技术突破。

05 破局之道:技术、机制、研究三维治理方案
5.1 技术层:打破同质化闭环
针对大模型沉默螺旋的四大底层技术缺陷,行业已探索出多类落地性较强的优化手段,从生成、检索、训练全链路打破同质化闭环,针对性缓解观点压制问题:
优化采样策略:对小模型适配高温度采样、多候选择优生成,弱化主流观点权重;
历史去锚定:动态衰减上下文权重,定期重置对话约束,加入反主流观点兜底提示;
RAG检索优化:调整排序算法,均衡AI内容与人类原创内容曝光占比;
分层去偏训练:针对大小模型、中英文模型差异,定制均衡语料微调方案。
5.2 机制层:建立监管与透明体系
搭建螺旋效应实时监测系统,基于观点极化度、内容多样性衰减率、小众观点留存率等核心指标,搭建全模型适配的监测预警工具,实时捕捉、预判沉默螺旋生成趋势;
强制内容来源透明化,标注人类/AI生成内容,规避AI内容垄断;
引入跨领域专家参与模型训练对齐,规避单一数据视角的观点固化。
5.3 研究层:夯实理论与标准体系
制定统一的沉默螺旋量化评估标准、评级体系与标准化测试数据集,解决当前研究标准混乱、结果无法横向对比的问题,实现所有模型、场景研究成果可对比、可复现;
开展长周期、大规模模拟实验,还原真实互联网信息演化规律;
拓展多模态、人机混合交互场景研究,完善理论边界。
06 总结
大模型沉默螺旋,是AI技术高速发展过程中被长期忽视、极易被低估的系统性、底层性、长期性风险。它不同于直观的算法漏洞、内容错误,不会瞬间引发明显问题,却在日复一日的内容生成与传播中,潜移默化地消解全网信息多元性、固化社会认知偏见、桎梏行业知识创新。
目前学界已完整证实大模型沉默螺旋的客观存在、核心机制与差异化表现,但在统一量化评估、长周期演化规律、多模态场景适配、规模化轻量化治理、人机交互耦合机制等核心领域,仍存在显著研究短板。未来,必须依托AI技术、传播学、社会学的跨学科深度协作,在AI生成效率与信息多元性之间找到平衡,持续优化模型训练、检索部署、内容监管全链路,彻底打破AI的“沉默闭环”,构建真正开放、包容、健康、富有创新活力的智能信息生态。
参考文献:
[1] ACL2024. Spiral of Silence: How is Large Language Model Killing Information Retrieval?
[2] arXiv2025. Spiral of Silence in Large Language Model Agents
[3] Noelle-Neumann E. The Spiral of Silence: Public Opinion—Our Social Skin, 1984.
[4] arXiv2024. Creativity Has Left the Chat: The Price of Debiasing Language Models
[5] Knowledge-Based Systems2026. Quantifying and mitigating the spiral of silence in recommender systems
[6] 周葆华. 网络舆论过程与动态演化:基于计算传播研究的分析[J]. 西北师大学报(社会科学版), 2019.

欢迎在评论区留言与本文作者互动交流!
作者简介
作者简介
李媛媛,毕业于武汉大学信息管理学院,学术硕士,前中国移动全栈研发工程师。
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
关于我们
数据派THU作为数据科学类公众号,背靠清华大学大数据研究中心,分享前沿数据科学与大数据技术创新研究动态、持续传播数据科学知识,努力建设数据人才聚集平台、打造中国大数据最强集团军。

新浪微博:@数据派THU
微信视频号:数据派THU
今日头条:数据派THU
点击“阅读原文”拥抱组织
